Recognition: 2 theorem links
· Lean TheoremOffline Policy Evaluation for Manipulation Policies via Discounted Liveness Formulation
Pith reviewed 2026-05-13 02:10 UTC · model grok-4.3
The pith
A discounted liveness Bellman operator produces a conservative fixed-point value function for offline evaluation of manipulation policies that remains accurate under finite rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that incorporating a discounted liveness property into the Bellman operator allows policy evaluation to treat the problem as determining whether a task will eventually complete. This produces a conservative value function whose fixed point remains stable under finite-horizon truncation and captures non-monotonic progress without requiring auxiliary labels or monotonicity assumptions.
What carries the argument
The liveness-based Bellman operator that augments the standard backup with a term encoding task-completion progress.
If this is right
- Value estimates remain conservative and monotonically related to true task success even when rollouts are truncated.
- The operator converges under the same conditions as standard discounted Bellman updates because it is a contraction.
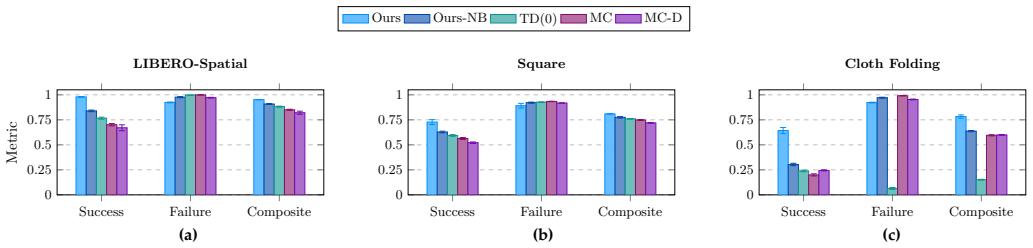
- Evaluation accuracy improves for policies that exhibit recovery behaviors, as shown on vision-language-action models and diffusion policies.
- The same formulation applies to human demonstration data without modification, as demonstrated on cloth folding.
Where Pith is reading between the lines
- The approach could be combined with existing offline RL datasets to rank policies before real-world deployment without lengthening simulations.
- It suggests a route to conservative safety checks in manipulation where overestimating progress is costly.
- Extensions to multi-task settings would require only redefining the liveness predicate for each task.
Load-bearing premise
Task completion can be expressed as a liveness property that fits directly inside the Bellman operator without extra progress labels or assumptions that fail during recovery.
What would settle it
Compare the learned values against ground-truth completion rates on rollouts long enough to reach success or clear failure; the estimates should stay below true rates yet increase toward them as horizon length grows, unlike standard methods that oscillate or drop sharply near truncation.
Figures





read the original abstract
Policy evaluation is a fundamental component of the development and deployment pipeline for robotic policies. In modern manipulation systems, this problem is particularly challenging: rewards are often sparse, task progression of evaluation rollouts are often non-monotonic as the policies exhibit recovery behaviors, and evaluation rollouts are necessarily of finite length. This finite length introduces truncation bias, breaking the infinite-horizon assumptions underlying standard methods relying on Bellman equations/principle of optimality. In this work, we propose a framework for offline policy evaluation from sparse rewards based on a liveness-based Bellman operator. Our formulation interprets policy evaluation as a task-completion problem and yields a conservative fixed-point value function that is robust to finite-horizon truncation. We analyze the theoretical properties of the proposed operator, including contraction guarantees, and show how it encodes task progression while mitigating truncation bias. We evaluate our method on two simulated manipulation tasks using both a Vision-Language-Action model and a diffusion policy, and a cloth folding task using human demonstrations. Empirical results demonstrate that our approach more accurately reflects task progress and substantially reduces truncation bias, outperforming classical baselines such as TD(0) and Monte Carlo policy evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a liveness-based Bellman operator for offline policy evaluation of robotic manipulation policies under sparse rewards. It reframes evaluation as a task-completion problem to produce a conservative fixed-point value function that is robust to non-monotonic recovery behaviors and finite-horizon truncation bias. The work analyzes contraction properties of the operator, shows how it encodes task progression without extra labels, and reports empirical outperformance versus TD(0) and Monte Carlo baselines on two simulated tasks (using VLA and diffusion policies) plus a real cloth-folding task with human demonstrations.
Significance. If the contraction analysis and empirical robustness hold, the approach offers a practical advance for policy evaluation in manipulation domains where standard infinite-horizon assumptions fail. Credit is due for the parameter-light formulation (only a liveness discount factor), the explicit handling of non-monotonic progress, and the multi-policy-class evaluation that includes both simulated and real data.
major comments (2)
- Abstract and theoretical analysis section: the contraction guarantees and uniqueness of the conservative fixed point are asserted as central results, yet the provided manuscript summary contains no derivation steps, conditions on the liveness discount factor, or proof sketch; this is load-bearing for the claim that the operator remains a contraction under non-monotonic recovery.
- Experimental section: the reported outperformance on the real cloth-folding task and reduction in truncation bias are key to the practical contribution, but without details on rollout lengths, how task progress is quantified, or statistical tests against baselines, the strength of the empirical support cannot be fully assessed.
minor comments (2)
- Abstract: the phrasing 'task progression of evaluation rollouts are often non-monotonic' contains a subject-verb agreement issue that should be corrected for clarity.
- The liveness discount factor is identified as the sole free parameter; a brief sensitivity analysis or default selection guideline would strengthen reproducibility even if not required for the core theory.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify the presentation of our theoretical and empirical contributions. We address each major comment below.
read point-by-point responses
-
Referee: Abstract and theoretical analysis section: the contraction guarantees and uniqueness of the conservative fixed point are asserted as central results, yet the provided manuscript summary contains no derivation steps, conditions on the liveness discount factor, or proof sketch; this is load-bearing for the claim that the operator remains a contraction under non-monotonic recovery.
Authors: The full manuscript contains a dedicated theoretical analysis (Section 3) deriving the contraction properties. To address the concern directly, we will revise the main text to include an explicit outline of the derivation steps, the precise condition that the operator is a contraction for any liveness discount factor γ_l ∈ (0,1), and a short proof sketch showing uniqueness of the conservative fixed point even when recovery behaviors are non-monotonic. The full proof will remain in the appendix. This change makes the central claim self-contained in the main body without altering the underlying results. revision: yes
-
Referee: Experimental section: the reported outperformance on the real cloth-folding task and reduction in truncation bias are key to the practical contribution, but without details on rollout lengths, how task progress is quantified, or statistical tests against baselines, the strength of the empirical support cannot be fully assessed.
Authors: We agree that these specifics are needed for rigorous evaluation. In the revised manuscript we will add: rollout lengths (maximum 200 steps in simulation, 100 steps on the real robot), the exact liveness-based quantification of task progress (implicit stage completion without auxiliary labels), and statistical reporting (means, standard deviations over 5 seeds, and paired t-test p-values versus TD(0) and Monte Carlo). These additions will strengthen the evidence for outperformance and truncation-bias reduction. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a new liveness-based Bellman operator from first principles to reinterpret policy evaluation as task completion, then separately proves its contraction mapping property and fixed-point existence. No equation reduces the claimed conservative value function or truncation robustness to a fitted quantity, renamed empirical pattern, or self-citation chain; the derivation chain is self-contained and does not invoke prior results by the same authors as load-bearing uniqueness theorems or ansatzes.
Axiom & Free-Parameter Ledger
free parameters (1)
- liveness discount factor
axioms (1)
- domain assumption Policy evaluation in manipulation can be reframed as a task-completion liveness problem whose fixed point remains conservative under finite truncation.
invented entities (1)
-
Liveness-based Bellman operator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose a framework for offline policy evaluation from sparse rewards based on a liveness-based Bellman operator... ˜Vπ(s) = (1−γ) + γ min{l(s), ˜Vπ(s′)}
Reference graph
Works this paper leans on
-
[1]
Ralph A Alexander and Diane M Govern. A new and simpler approximation for ANOV A under variance het- erogeneity.Journal of Educational Statistics, 19(2):91– 101, 1994. URL https://www.jstor.org/stable/1165140
-
[2]
Somil Bansal, Mo Chen, Sylvia Herbert, and Claire J. Tomlin. Hamilton-jacobi reachability: A brief overview and recent advances. In2017 IEEE 56th Annual Con- ference on Decision and Control (CDC), pages 2242– 2253, 2017. doi: 10.1109/CDC.2017.8263977. URL https://arxiv.org/abs/1709.07523
-
[3]
Yoav Benjamini and Yosef Hochberg. Controlling the false discovery rate: a practical and powerful approach to multiple testing.Journal of the Royal Statistical Society: Series B (Methodological), 57(1):289–300, 1995. URL https://www.jstor.org/stable/2346101?seq=1
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. URL https://arxiv.org/ abs/2503.14734
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A vi...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yev- gen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022. URL https://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Dif- fusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Dif- fusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems (RSS), 2023. URL https://diffusion-policy.cs. columbia.edu/
work page 2023
-
[8]
The convergence oftd(λ)for generalλ
Peter Dayan. The convergence oftd(λ)for generalλ. Machine Learning, 8(3-4):341–362, 1992. URL https: //link.springer.com/article/10.1007/BF00992701
-
[9]
Jaime F. Fisac, Neil F. Lugovoy, Vicenc Rubies-Royo, Shromona Ghosh, and Claire J. Tomlin. Bridging hamilton-jacobi safety analysis and reinforcement learn- ing. In2019 International Conference on Robotics and Automation (ICRA), pages 8550–8556. IEEE. ISBN 978- 1-5386-6027-0. doi: 10.1109/ICRA.2019.8794107. URL https://ieeexplore.ieee.org/document/8794107/
-
[10]
Howard.Dynamic Programming and Markov Processes
Ronald A. Howard.Dynamic Programming and Markov Processes. The Technology Press of MIT and John Wiley & Sons, Cambridge, MA and New York, NY , 1960. ISBN 9780262080095. URL https://gwern.net/doc/statistics/decision/ 1960-howard-dynamicprogrammingmarkovprocesses. pdf
work page 1960
-
[11]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ash- win Balakrishna, Kevin Black, Ken Conley, Grace Con- nors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al.π ∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025. URL https://arxiv.org/ abs/2511.14759
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. URL https://arxiv.org/abs/2504.16054
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ash- win Balakrishna, Sudeep Dasari, Siddharth Karam- cheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. URL https://arxiv.org/ abs/2403.12945
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776– 44791, 2023. URL https://arxiv.org/abs/2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
On reachability and minimum cost optimal control.Automatica, 40(6):917–927, 2004
John Lygeros. On reachability and minimum cost optimal control.Automatica, 40(6):917–927, 2004. ISSN 0005-
work page 2004
-
[16]
doi: https://doi.org/10.1016/j.automatica.2004.01
-
[17]
URL https://www.sciencedirect.com/science/article/ pii/S0005109804000263
-
[18]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Mart ´ın-Mart´ın. What matters in learning from offline human demon- strations for robot manipulation. InarXiv preprint arXiv:2108.03298, 2021. URL https://arxiv.org/abs/2108. 03298
work page internal anchor Pith review arXiv 2021
-
[19]
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. Steering your generalists: Improving robotic foundation models via value guidance.arXiv preprint arXiv:2410.13816, 2024. URL https://arxiv.org/ abs/2410.13816
-
[21]
URL https://arxiv.org/abs/2304.07193
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. URL https://proceedings.mlr.press/v139/ radford21a/rad...
work page 2021
-
[23]
Reuven Y . Rubinstein and Dirk P. Kroese. Simulation and the Monte Carlo Method. John Wiley & Sons, Hoboken, NJ, 3rd edition,
-
[24]
ISBN 978-1-118-63216-1. URL https: //www.wiley.com/en-us/Simulation+and+the+Monte+ Carlo+Method%2C+3rd+Edition-p-9781118632161
-
[25]
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay.arXiv preprint arXiv:1511.05952, 2015. URL https://arxiv.org/abs/1511. 05952
-
[26]
Satinder P. Singh and Richard S. Sutton. Reinforce- ment learning with replacing eligibility traces.Ma- chine Learning, 22(1-3):123–158, 1996. doi: 10.1007/ BF00114726. URL http://www.incompleteideas.net/ papers/singh-sutton-96.ps
work page 1996
-
[27]
Richard S. Sutton. Learning to predict by the methods of temporal differences. 3(1):9–44. ISSN 1573-0565. doi: 10.1007/BF00115009. URL https://doi.org/10.1007/ BF00115009
-
[28]
Richard S Sutton, Andrew G Barto, et al.Reinforce- ment learning: An introduction, volume 1. MIT press Cambridge, 1998. URL http://incompleteideas.net/book/ the-book-2nd.html
work page 1998
-
[29]
Gemini Robotics Team, Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gonzalez Arenas, Ashwin Balakrishna, Nathan Batchelor, Alex Bewley, Jeff Bingham, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342...
-
[30]
Thomas, Georgios Theocharous, and Moham- mad Ghavamzadeh
Philip S. Thomas, Georgios Theocharous, and Moham- mad Ghavamzadeh. High-confidence off-policy evalua- tion. InProceedings of the Twenty-Ninth AAAI Confer- ence on Artificial Intelligence (AAAI), volume 29, pages 3000–3006, 2015. URL https://ojs.aaai.org/index.php/ AAAI/article/view/9541
work page 2015
-
[31]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision- language encoders with improved semantic understand- ing, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. URL https://arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. URL https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Bridgedata v2: A dataset for robot learning at scale, 2024
Homer Rich Walke, Kevin Black, Tony Z Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, An- dre Wang He, Vivek Myers, Moo Jin Kim, Max Du, et al. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning, pages 1723–1736. PMLR, 2023. URL https://arxiv.org/abs/2308.12952
-
[34]
Bernard L Welch. The generalization of ‘Student’s’ problem when several different population variances are involved.Biometrika, 34(1/2):28–35, 1947. URL https: //www.jstor.org/stable/2332510?seq=1
-
[35]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language- action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. URL https://arxiv.org/abs/2307.15818. APPENDIXA PROOF OFPROPOSITION1 Proof:We use a s...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.