Recognition: 2 theorem links
· Lean TheoremUnderstanding and Preventing Entropy Collapse in RLVR with On-Policy Entropy Flow Optimization
Pith reviewed 2026-05-13 01:38 UTC · model grok-4.3
The pith
Token-level entropy flow imbalance causes collapse in RLVR, which On-Policy Entropy Flow Optimization corrects by rescaling updates proportionally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Entropy collapse in RLVR stems from a severely imbalanced entropy flow at the token level, where entropy-decreasing tokens consistently outweigh entropy-increasing ones. This perspective explains the shortcomings of prior methods and motivates an adaptive balancing mechanism that rescales updates according to their entropy contributions without leaving the on-policy regime.
What carries the argument
On-Policy Entropy Flow Optimization (OPEFO), which rescales entropy-increasing and entropy-decreasing updates proportionally to their contributions to overall entropy change.
If this is right
- Training stability improves as entropy no longer collapses prematurely.
- Final performance on mathematical reasoning benchmarks increases.
- The approach remains strictly on-policy, avoiding the need for approximate sampling.
- A unified explanation accounts for entropy issues across multiple RLVR algorithms like GRPO.
- Entropy dynamics can be controlled in a fine-grained, token-specific manner.
Where Pith is reading between the lines
- Similar entropy imbalances may appear in reinforcement learning settings beyond verifiable rewards, such as in general dialogue or code generation tasks.
- The token-level flow analysis could be applied to diagnose issues in other optimization algorithms for language models.
- Combining OPEFO with existing entropy regularization might yield even stronger stability guarantees.
Load-bearing premise
That the observed imbalance in token entropy contributions is the root cause of collapse and that rescaling updates based on those contributions will restore balance without diluting the reinforcement learning signal or introducing new instabilities.
What would settle it
Training multiple models with and without the rescaling mechanism in OPEFO and measuring whether entropy levels stabilize and performance improves specifically when the balancing is applied, or fails to do so when it is not.
Figures



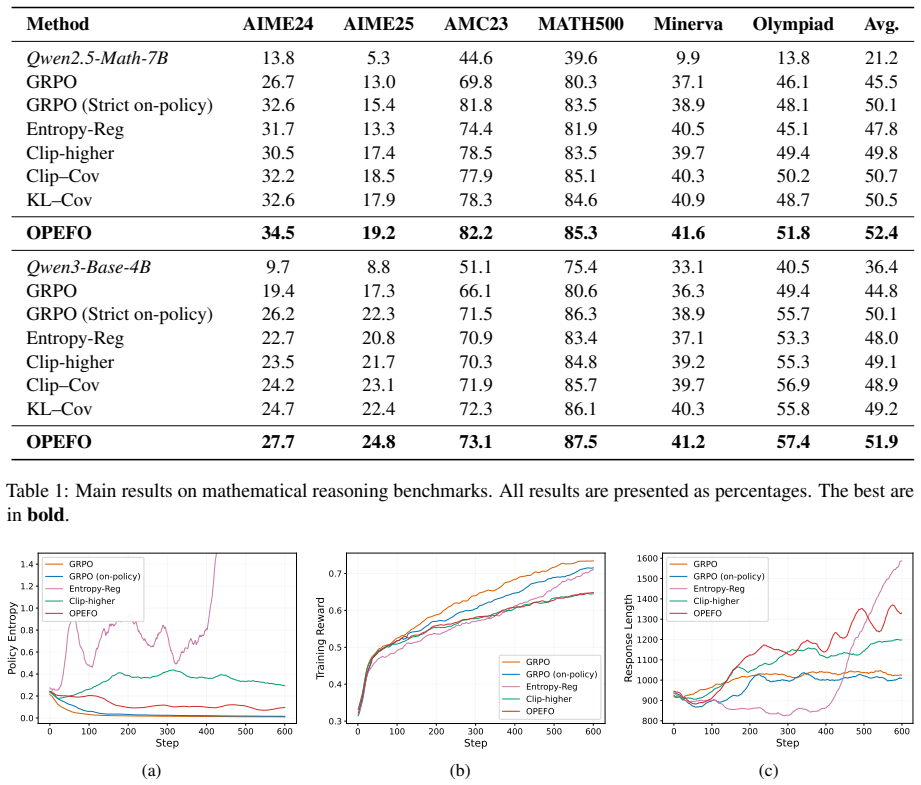
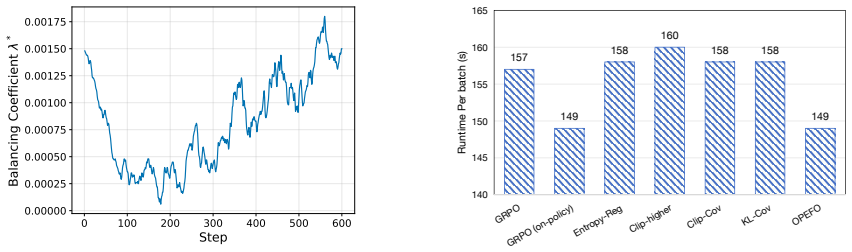
read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become an effective paradigm for improving the reasoning ability of large language models. However, widely used RLVR algorithms, such as GRPO, often suffer from entropy collapse, leading to premature determinism and unstable optimization. Existing remedies, including entropy regularization and ratio-based clipping heuristics, either control entropy in a coarse-grained manner or rely on approximate on-policy training. In this paper, we revisit entropy collapse from a token-level entropy flow perspective. Our analysis reveals that entropy-decreasing tokens consistently outweigh entropy-increasing ones, resulting in a severely imbalanced entropy flow. This perspective provides a unified explanation of entropy collapse in existing RLVR algorithms and highlights the importance of balancing entropy dynamics. Motivated by this analysis, we propose On-Policy Entropy Flow Optimization (OPEFO), an adaptive entropy flow balancing mechanism that rescales entropy-increasing and entropy-decreasing updates according to their contributions to entropy change, while remaining strict on-policy. Experiments on six mathematical reasoning benchmarks demonstrate that OPEFO improves training stability and final performance. We will release the code and models upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes entropy collapse in RLVR algorithms such as GRPO from a token-level entropy flow perspective, observing that entropy-decreasing tokens consistently outweigh entropy-increasing ones and create an imbalanced flow that drives premature determinism. Motivated by this, the authors introduce On-Policy Entropy Flow Optimization (OPEFO), an adaptive mechanism that rescales the contributions of entropy-increasing versus entropy-decreasing updates proportionally to their realized entropy-change magnitudes while asserting that the procedure remains strictly on-policy. Experiments on six mathematical reasoning benchmarks are claimed to demonstrate improved training stability and final performance over standard RLVR baselines.
Significance. If the central claims hold, the work supplies a fine-grained, token-level diagnostic for entropy collapse that unifies several existing heuristics and offers a balancing rule that avoids both coarse entropy bonuses and explicit off-policy corrections. The insistence on remaining strictly on-policy is a methodological strength, and the promised release of code and models would enable direct verification. The significance is tempered by the absence of a demonstrated unbiasedness proof for the rescaled estimator and by the lack of quantitative results in the provided abstract.
major comments (2)
- [OPEFO formulation (method section)] The abstract and method description assert that OPEFO 'remains strict on-policy.' However, the rescaling coefficients are functions of the realized per-token entropy deltas computed from the current policy logits on sampled trajectories. This introduces a multiplicative, trajectory-dependent factor into the gradient estimator. No derivation is supplied showing that the expectation of this factor equals one (or that an importance-sampling correction restores unbiasedness) with respect to the original on-policy objective. This point is load-bearing for the central claim that OPEFO improves stability without altering the learning signal.
- [Experiments] The experimental section reports improvements on six benchmarks but, consistent with the abstract, supplies no numerical values, baseline comparisons, ablation results, or statistical details. Without these data it is impossible to assess whether the observed stability gains are attributable to the entropy-flow balancing or to other unstated hyper-parameter changes.
minor comments (2)
- The abstract would benefit from a single-sentence quantitative summary of the reported gains (e.g., average accuracy lift or entropy-maintenance metric) to allow readers to gauge effect size immediately.
- Notation for the entropy-flow terms (e.g., how 'contribution to entropy change' is exactly defined per token) should be introduced with an equation early in the method section to avoid ambiguity when the rescaling rule is later stated.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the on-policy properties of OPEFO and the experimental reporting. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [OPEFO formulation (method section)] The abstract and method description assert that OPEFO 'remains strict on-policy.' However, the rescaling coefficients are functions of the realized per-token entropy deltas computed from the current policy logits on sampled trajectories. This introduces a multiplicative, trajectory-dependent factor into the gradient estimator. No derivation is supplied showing that the expectation of this factor equals one (or that an importance-sampling correction restores unbiasedness) with respect to the original on-policy objective. This point is load-bearing for the central claim that OPEFO improves stability without altering the learning signal.
Authors: We appreciate the referee's precise identification of this issue. The rescaling coefficients are computed solely from entropy deltas on trajectories sampled from the current policy using its own logits, with no reference to prior policies. We will add a formal derivation in the revised method section establishing that the expectation of the rescaling factor equals one under the current policy distribution, confirming that the estimator remains unbiased and strictly on-policy. revision: yes
-
Referee: [Experiments] The experimental section reports improvements on six benchmarks but, consistent with the abstract, supplies no numerical values, baseline comparisons, ablation results, or statistical details. Without these data it is impossible to assess whether the observed stability gains are attributable to the entropy-flow balancing or to other unstated hyper-parameter changes.
Authors: We apologize for the insufficient quantitative detail in the reviewed version. The full experimental section contains tables with exact performance numbers on all six mathematical reasoning benchmarks, direct comparisons to GRPO and other baselines, ablation studies on the entropy-flow components, and results with standard deviations over multiple seeds. These will be prominently included and expanded in the revision. revision: yes
Circularity Check
No significant circularity; analysis motivates independent method
full rationale
The paper begins with an empirical token-level analysis showing imbalanced entropy flow (more decreasing than increasing tokens) in standard RLVR methods like GRPO. This observation directly motivates the design of OPEFO as an adaptive rescaling mechanism that balances contributions while claiming to preserve strict on-policy properties. No equations or steps reduce the proposed rescaling rule to the input observations by construction, nor does the central claim rely on self-citations, imported uniqueness theorems, or ansatzes smuggled from prior work. The derivation chain remains self-contained: observation informs a new balancing rule, which is then validated experimentally on external benchmarks. This is the standard non-circular pattern of empirical diagnosis followed by algorithmic response.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropy contribution rescaling coefficients
axioms (1)
- domain assumption Entropy-decreasing tokens outweigh entropy-increasing tokens during RLVR training, producing net entropy collapse.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe propose On-Policy Entropy Flow Optimization (OPEFO), an adaptive entropy flow balancing mechanism that rescales entropy-increasing and entropy-decreasing updates according to their contributions to entropy change, while remaining strict on-policy
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclearΔHt =−ηE a∼πkθ(·|st)[At(1−πkθ(a|st))2(logπkθ(a|st)+H(πkθ|st))]
Reference graph
Works this paper leans on
-
[1]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
The entropy mechanism of reinforcement learning for reasoning language models , author=. arXiv preprint arXiv:2505.22617 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective
Rethinking Entropy Interventions in RLVR: An Entropy Change Perspective , author=. arXiv preprint arXiv:2510.10150 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2510.08141 , year=
Arbitrary Entropy Policy Optimization: Entropy Is Controllable in Reinforcement Finetuning , author=. arXiv preprint arXiv:2510.08141 , year=
-
[5]
Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
Reasoning with exploration: An entropy perspective , author=. arXiv preprint arXiv:2506.14758 , year=
-
[6]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
arXiv preprint arXiv:2510.18927 , year=
BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping , author=. arXiv preprint arXiv:2510.18927 , year=
-
[8]
Simple statistical gradient-following algorithms for connectionist reinforcement learning , author=. Machine learning , volume=. 1992 , publisher=
work page 1992
-
[9]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Skywork open reasoner 1 technical report
Skywork open reasoner 1 technical report , author=. arXiv preprint arXiv:2505.22312 , year=
-
[17]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Hugging Face repository , volume=
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions , author=. Hugging Face repository , volume=. 2024 , url=
work page 2024
-
[19]
Proceedings of the Twentieth European Conference on Computer Systems , pages=
Hybridflow: A flexible and efficient rlhf framework , author=. Proceedings of the Twentieth European Conference on Computer Systems , pages=. 2025 , url=
work page 2025
-
[20]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=. 2023 , url=
work page 2023
-
[21]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
On entropy control in llm-rl algorithms , author=. arXiv preprint arXiv:2509.03493 , year=
-
[25]
How does rl policy entropy converge during iteration , author=. Zhihu Zhuanlan , year=
-
[26]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Importance sampling in reinforcement learning with an estimated behavior policy , author=. Machine Learning , volume=. 2021 , publisher=
work page 2021
-
[28]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=. 2022 , url=
work page 2022
-
[29]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , url=
work page 2024
-
[30]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[31]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[32]
Dcpo: Dynamic clipping policy optimization.arXiv preprint arXiv:2509.02333, 2025
Dcpo: Dynamic clipping policy optimization , author=. arXiv preprint arXiv:2509.02333 , year=
-
[33]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model , author=. arXiv preprint arXiv:2503.24290 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [34]
-
[35]
The surprising effectiveness of negative reinforcement in LLM reasoning , author=. arXiv preprint arXiv:2506.01347 , year=
-
[36]
arXiv preprint arXiv:2508.04349 , year=
Gtpo and grpo-s: Token and sequence-level reward shaping with policy entropy , author=. arXiv preprint arXiv:2508.04349 , year=
-
[37]
arXiv preprint arXiv:2507.15778 , year=
Stabilizing knowledge, promoting reasoning: Dual-token constraints for rlvr , author=. arXiv preprint arXiv:2507.15778 , year=
-
[38]
Decomposing the entropy-performance exchange: The missing keys to unlocking effective reinforcement learning , author=. arXiv preprint arXiv:2508.02260 , year=
-
[39]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour , author=. 2017 , url=
work page 2017
-
[41]
On-policy rl with optimal reward baseline.arXiv preprint arXiv:2505.23585, 2025
On-Policy RL with Optimal Reward Baseline , author=. arXiv preprint arXiv:2505.23585 , year=
-
[42]
Prosperity before Collapse: How Far Can Off-Policy RL Reach with Stale Data on LLMs? , author=. arXiv preprint arXiv:2510.01161 , year=
-
[43]
arXiv preprint arXiv:2506.05615 , year=
When Maximum Entropy Misleads Policy Optimization , author=. arXiv preprint arXiv:2506.05615 , year=
-
[44]
Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models , author=. arXiv preprint arXiv:2505.24864 , year=
-
[45]
Proceedings of the twelfth international conference on machine learning , pages=
Residual algorithms: Reinforcement learning with function approximation , author=. Proceedings of the twelfth international conference on machine learning , pages=. 1995 , url=
work page 1995
-
[46]
Advances in neural information processing systems , volume=
Policy gradient methods for reinforcement learning with function approximation , author=. Advances in neural information processing systems , volume=. 1999 , url=
work page 1999
-
[47]
arXiv preprint arXiv:1710.06451 , year=
A bayesian perspective on generalization and stochastic gradient descent , author=. arXiv preprint arXiv:1710.06451 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.