Recognition: 3 theorem links
· Lean TheoremPRISM: : Planning and Reasoning with Intent in Simulated Embodied Environments
Pith reviewed 2026-05-13 01:49 UTC · model grok-4.3
The pith
PRISM benchmark shows implicit intent resolution is the main bottleneck for LLM embodied agents, not spatial perception, with long-horizon tasks exposing a sharp capability cliff.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
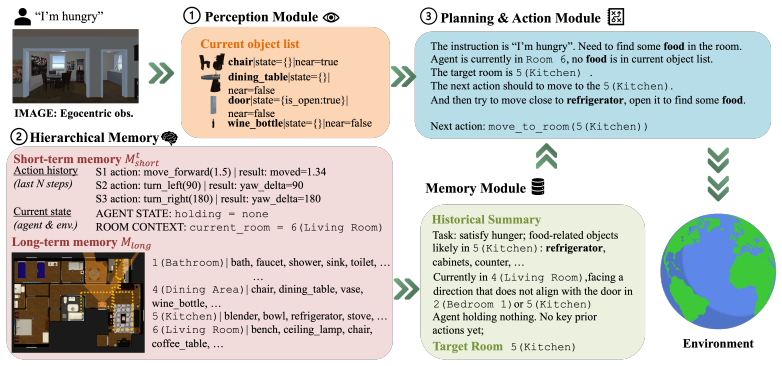
PRISM reframes embodied agent evaluation by asking which capability is responsible for failure instead of only whether the agent succeeded. It builds five photorealistic apartments with 300 human-verified tasks divided into Basic Ability for perception-to-action grounding, Reasoning Ability for implicit intent resolution, and Long-horizon Ability for sustained multi-step coordination. The benchmark supplies an executable action API usable by any agent type and optional probes for perception, memory, and planning. Tests on seven LLMs show explicit spatial grounding is not the main issue under oracle perception, implicit intent is a bottleneck for all families, and long-horizon coordination is
What carries the argument
PRISM's three capability tiers isolating perception-to-action grounding, implicit intent resolution, and long-horizon coordination, together with its agent-agnostic executable action API.
If this is right
- Developers can target intent resolution modules specifically without altering perception components.
- Long-horizon tasks require planning strategies beyond current LLM reasoning to prevent performance collapses.
- Optional probes allow verification of whether memory or planning failures drive coordination issues.
- The observed failure hierarchy suggests scaling model size alone will not resolve intent bottlenecks across families.
- Lightweight models' excess token use on hard tasks indicates inefficient compensatory strategies that could be optimized.
Where Pith is reading between the lines
- Hybrid LLM and symbolic planner systems could reduce the long-horizon performance cliff by delegating coordination.
- Applying PRISM to physical robots would test whether the simulation results persist when perception noise returns.
- Benchmarks reporting only aggregate success rates may hide the value of modular agent designs that address intent separately.
- Training with explicit intent statements might reduce the bottleneck identified in the reasoning tier.
Load-bearing premise
The three capability tiers and optional probes isolate perception-to-action grounding, implicit intent resolution, and sustained multi-step coordination without substantial overlap or confounding effects from task design or human verification.
What would settle it
An experiment where long-horizon tasks are rephrased to state all intents explicitly, after which the success gap between lightweight and frontier models disappears and token consumption equalizes.
Figures


read the original abstract
When an LLM-based embodied agent fails at a household task, the culprit could be misidentified objects, forgotten sub-goals, or poor action sequencing -- yet existing benchmarks report only a single success rate, making it impossible to tell which cognitive module is responsible. We present PRISM, a diagnostic benchmark that reframes this problem: rather than asking only \textit{did the agent succeed?}, PRISM asks \textit{which capability is most likely responsible for failure?} Built on five photorealistic multi-room apartments (4--8 rooms each), PRISM structures 300 human-verified tasks into three capability tiers -- \textit{Basic Ability}, \textit{Reasoning Ability}, and \textit{Long-horizon Ability} -- that isolate perception-to-action grounding, implicit intent resolution, and sustained multi-step coordination respectively. PRISM exposes an agent-agnostic executable action API that allows arbitrary agents: LLM agents, VLM agents, symbolic planners, RL policies, and hybrid systems, to be evaluated end-to-end under the same benchmark protocol. To support deeper diagnosis, optional probes for perception, memory, and planning can be adopted, replaced, or bypassed entirely, enabling controlled component-level analysis when desired. Experiments on seven contemporary LLMs establish a clear hierarchy: explicit spatial grounding is not the dominant failure source under oracle perception, implicit intent resolution is a significant bottleneck for all model families, and long-horizon coordination exposes a stark capability cliff -- lightweight models collapse to as low as 20.0\% success while simultaneously consuming more tokens than their frontier counterparts, a signature of compensatory over-reasoning rather than genuine planning capability. Project page: \href{https://sj-li.com/PROJ/PRISM}{link}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PRISM, a diagnostic benchmark for LLM-based embodied agents operating in five photorealistic multi-room simulated apartments. It structures 300 human-verified tasks into three tiers—Basic Ability (perception-to-action grounding under oracle perception), Reasoning Ability (implicit intent resolution), and Long-horizon Ability (sustained multi-step coordination)—and supplies an agent-agnostic executable action API plus optional probes for perception, memory, and planning. Experiments across seven contemporary LLMs are used to establish a performance hierarchy: spatial grounding is not the dominant failure mode, implicit intent is a shared bottleneck, and long-horizon tasks produce a sharp capability cliff for lighter models that also exhibit higher token consumption.
Significance. If the tiered task design demonstrably isolates the claimed cognitive modules without substantial overlap, PRISM would supply a much-needed diagnostic instrument that moves embodied-agent evaluation beyond single aggregate success rates. The agent-agnostic API and modular probes constitute clear strengths that could support reproducible comparisons across LLM, VLM, symbolic, and hybrid systems. The reported empirical hierarchy, once properly validated, would usefully direct attention toward intent resolution and long-horizon planning as priority research targets.
major comments (3)
- [Task Tiers] Task Tiers section: The central claim that the three tiers cleanly isolate perception-to-action grounding, implicit intent resolution, and sustained coordination rests on human verification of the 300 tasks, yet no quantitative evidence (e.g., inter-tier overlap statistics, ablation removing coordination elements from Reasoning tasks, or correlation of failure modes across tiers) is supplied to confirm separation. Overlap would confound attribution of the reported bottlenecks.
- [Experimental Results] Experimental Results section: The performance hierarchy and token-consumption observations are presented without per-tier task counts, statistical significance tests, error bars, or explicit controls for task selection and human-verification bias, rendering the abstract's specific claims (20.0% success for lightweight models, compensatory over-reasoning) unverifiable from the reported data.
- [Experiments] §4 (or equivalent Experiments section): The interpretation that higher token usage by lightweight models on Long-horizon tasks signals 'compensatory over-reasoning' rather than other factors (prompt formatting, decoding strategy, or inefficient search) lacks supporting controls or auxiliary metrics; this attribution is load-bearing for the capability-cliff narrative.
minor comments (2)
- [Title] Title contains a typographical double colon ('PRISM: : Planning...') that should be corrected.
- [Abstract] Abstract and Task Distribution: A breakdown table showing how the 300 tasks are allocated across the five apartments and three tiers would clarify balance and reduce potential confounding from apartment-specific layout effects.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and planned revisions to improve the manuscript's rigor and verifiability.
read point-by-point responses
-
Referee: [Task Tiers] Task Tiers section: The central claim that the three tiers cleanly isolate perception-to-action grounding, implicit intent resolution, and sustained coordination rests on human verification of the 300 tasks, yet no quantitative evidence (e.g., inter-tier overlap statistics, ablation removing coordination elements from Reasoning tasks, or correlation of failure modes across tiers) is supplied to confirm separation. Overlap would confound attribution of the reported bottlenecks.
Authors: We agree that additional quantitative evidence would strengthen the separation claim. Tasks were assigned to tiers based on explicit design criteria (e.g., presence of implicit intent only in Reasoning tier, multi-step coordination only in Long-horizon) followed by human verification. In the revision we will add per-tier task counts, inter-annotator agreement statistics on tier assignment, and an analysis of cross-tier performance correlations to quantify potential overlap. revision: yes
-
Referee: [Experimental Results] Experimental Results section: The performance hierarchy and token-consumption observations are presented without per-tier task counts, statistical significance tests, error bars, or explicit controls for task selection and human-verification bias, rendering the abstract's specific claims (20.0% success for lightweight models, compensatory over-reasoning) unverifiable from the reported data.
Authors: We acknowledge the need for more granular reporting. The 20.0% figure is the observed minimum success rate for lightweight models on Long-horizon tasks. In the revised manuscript we will include a table with exact task counts per tier, add error bars to all performance plots, report appropriate statistical tests for model comparisons, and briefly describe the task curation and human verification protocol to address selection bias. revision: yes
-
Referee: [Experiments] §4 (or equivalent Experiments section): The interpretation that higher token usage by lightweight models on Long-horizon tasks signals 'compensatory over-reasoning' rather than other factors (prompt formatting, decoding strategy, or inefficient search) lacks supporting controls or auxiliary metrics; this attribution is load-bearing for the capability-cliff narrative.
Authors: The higher token usage by lighter models is a direct empirical observation. We interpret it as compensatory over-reasoning given the lack of corresponding success improvement. We agree that without explicit controls this remains an interpretation rather than a controlled conclusion. In the revision we will present per-tier token statistics with variance, qualify the claim accordingly, and discuss alternative explanations including prompt formatting and decoding effects. revision: partial
Circularity Check
No circularity: empirical benchmark with direct evaluations
full rationale
The paper introduces PRISM as a new diagnostic benchmark that structures 300 human-verified tasks into three capability tiers and reports direct success rates from LLM evaluations under oracle perception. No mathematical derivations, fitted parameters, self-referential predictions, or load-bearing self-citations exist; the hierarchy claims rest on empirical measurements against the task set rather than any reduction to prior inputs by construction. The work is fully self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearPRISM structures 300 human-verified tasks into three capability tiers—Basic Ability, Reasoning Ability, and Long-horizon Ability—that isolate perception-to-action grounding, implicit intent resolution, and sustained multi-step coordination respectively.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe reference diagnostic pipeline decomposes agent behavior into three independently substitutable probes—Perception, Memory, and Planning—connected through standardized interfaces.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearExperiments on seven contemporary LLMs establish a clear hierarchy: explicit spatial grounding is not the dominant failure source under oracle perception...
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Anthropic. Claude opus 4.6 system card. Technical report, Anthropic, 2025. URL https: //www.anthropic.com/system-cards
work page 2025
- [3]
- [4]
-
[5]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
- [7]
-
[8]
C. Li, F. Xia, R. Martín-Martín, M. Lingelbach, S. Srivastava, B. Shen, K. Vainio, C. Gokmen, G. Dharan, T. Jain, et al. igibson 2.0: Object-centric simulation for robot learning of everyday household tasks
-
[9]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Martín-Martín, C. Wang, G. Levine, M. Lingelbach, J. Sun, et al. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. InConference on Robot Learning, pages 80–93, 2023
work page 2023
-
[10]
M. Li, S. Zhao, Q. Wang, K. Wang, Y . Zhou, S. Srivastava, C. Gokmen, T. Lee, L. E. Li, R. Zhang, W. Liu, P. Liang, L. Fei-Fei, J. Mao, and J. Wu. Embodied agent interface: Bench- marking llms for embodied decision making. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
- [11]
-
[12]
X. Ma, S. Yong, Z. Zheng, Q. Li, Y . Liang, S.-C. Zhu, and S. Huang. Sqa3d: Situated question answering in 3d scenes. InThe Eleventh International Conference on Learning Representations
-
[13]
MemGPT: Towards LLMs as Operating Systems
C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual ACM symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[15]
X. Puig, K. Ra, M. Boben, J. Li, T. Wang, S. Fidler, and A. Torralba. Virtualhome: Simulating household activities via programs. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8494–8502, 2018
work page 2018
- [16]
- [17]
-
[18]
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020
work page 2020
-
[19]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
G. Team, A. Zeng, B. Xu, B. Wang, C. Zhang, D. Yin, D. Zhang, D. Rojas, G. Feng, H. Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research
-
[22]
Z. Wang, B. Yu, J. Zhao, W. Sun, S. Hou, S. Liang, X. Hu, Y . Han, and Y . Gan. Karma: Augmenting embodied ai agents with long-and-short term memory systems. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 1–8, 2025
work page 2025
-
[23]
R. Yang, H. Chen, J. Zhang, M. Zhao, C. Qian, K. Wang, Q. Wang, T. Koripella, M. Movahedi, M. Li, et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. InForty-second International Conference on Machine Learning, 2025
work page 2025
- [24]
-
[25]
Pick up the apple and place it on the table
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024. A Dataset Diversity and Scalability A.1 Apartment-Level Scene Design PRISMcomprises five distinct apartment scenes, each featuring an independ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.