Recognition: 2 theorem links
· Lean TheoremFrom Generic Correlation to Input-Specific Credit in On-Policy Self Distillation
Pith reviewed 2026-05-13 01:20 UTC · model grok-4.3
The pith
Self-distillation token rewards sum exactly to the pointwise mutual information between response and feedback given the input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a posterior-compatibility interpretation of feedback conditioning, standard in the implicit-reward literature, we show that the self-distillation token reward is a Bayesian filtering increment whose trajectory sum is exactly the pointwise mutual information between the response and the feedback given the input. This pMI can be raised by input-specific reasoning or by input-generic shortcuts, so we further decompose the teacher log-probability along the input axis. Based on this analysis, we propose CREDIT (Contrastive REward from DIsTillation), which isolates the input-specific component with a batch-contrastive baseline. At the sequence level, CREDIT is a teacher-side surrogate for a
What carries the argument
Posterior-compatibility interpretation of feedback conditioning, under which the token reward becomes a Bayesian filtering increment that sums to pointwise mutual information between response and feedback, isolated by CREDIT's batch-contrastive baseline on the input axis.
If this is right
- Accumulated token rewards equal the pointwise mutual information between the response and the feedback given the input.
- CREDIT penalizes responses that remain likely under unrelated inputs in the same batch.
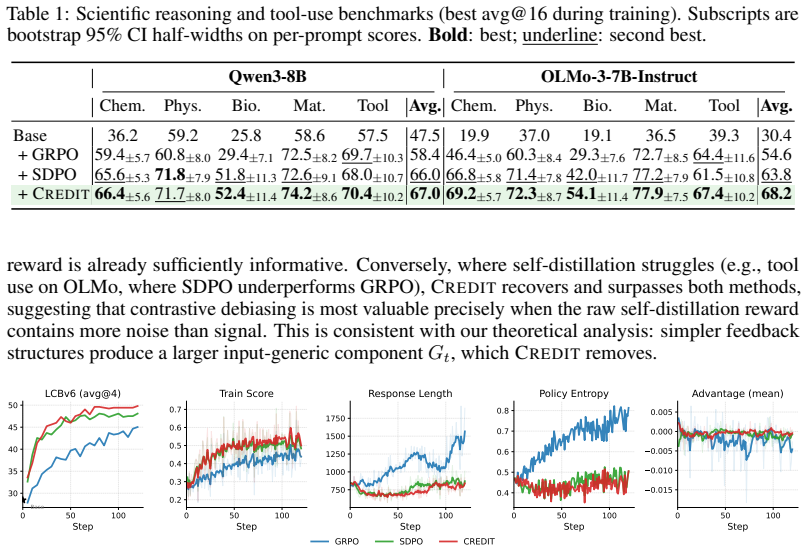
- The method improves aggregate performance on coding, scientific reasoning, and tool-use benchmarks.
- CREDIT requires negligible extra compute beyond standard self-distillation.
- At sequence level the objective serves as a teacher-side surrogate for contrastive pointwise mutual information.
Where Pith is reading between the lines
- The input-axis decomposition may extend to other dense-reward methods in reinforcement learning from human feedback to reduce generic correlation noise.
- Similar contrastive baselines could be tested in offline or off-policy distillation settings to check whether input-specific credit remains beneficial.
- The pointwise mutual information framing suggests connections to other information-theoretic objectives already used in language-model alignment.
- Empirical gains imply that generic shortcuts are a measurable source of reward dilution in current self-distillation practice.
Load-bearing premise
Feedback conditioning in self-distillation admits a posterior-compatibility interpretation that treats each token reward as a Bayesian filtering increment.
What would settle it
Directly estimate the pointwise mutual information from the joint distribution of sampled responses and observed feedbacks for a collection of inputs, then check whether the estimate equals the sum of token rewards accumulated along each response trajectory.
Figures












read the original abstract
On-policy self-distillation has emerged as a promising paradigm for post-training language models, in which the model conditions on environment feedback to serve as its own teacher, providing dense token-level rewards without external teacher models or step-level annotations. Despite its empirical success, what this reward actually measures and what kind of credit it assigns remain unclear. Under a posterior-compatibility interpretation of feedback conditioning, standard in the implicit-reward literature, we show that the self-distillation token reward is a Bayesian filtering increment whose trajectory sum is exactly the pointwise mutual information between the response and the feedback given the input. This pMI can be raised by input-specific reasoning or by input-generic shortcuts, so we further decompose the teacher log-probability along the input axis. Based on this analysis, we propose CREDIT (Contrastive REward from DIsTillation), which isolates the input-specific component with a batch-contrastive baseline. At the sequence level, CREDIT is a teacher-side surrogate for a contrastive pMI objective that also penalizes responses remaining likely under unrelated inputs. Across coding, scientific reasoning, and tool-use benchmarks on two model families, CREDIT delivers the strongest aggregate performance at negligible additional compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes on-policy self-distillation for language models, arguing that under a posterior-compatibility view of feedback conditioning the per-token reward is a Bayesian filtering increment whose sum equals the pointwise mutual information (pMI) between response and feedback given the input. It decomposes teacher log-probabilities along the input axis to separate generic correlations from input-specific credit, then introduces CREDIT (a batch-contrastive baseline) as a teacher-side surrogate for a contrastive pMI objective. Experiments across coding, scientific reasoning, and tool-use benchmarks on two model families report that CREDIT yields the strongest aggregate performance at negligible extra cost.
Significance. If the central identity holds, the work supplies a parameter-free information-theoretic grounding for self-distillation rewards and motivates a simple, low-overhead method that focuses credit on input-specific reasoning rather than generic correlations. The clean derivation of the pMI equality from the reward definition (without invented entities or free parameters) is a notable strength, as is the explicit contrastive construction that penalizes responses likely under unrelated inputs.
major comments (1)
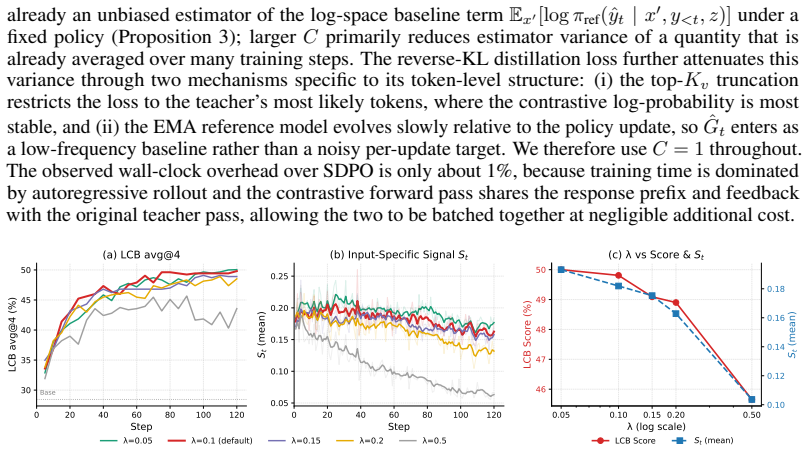
- §5 (Experiments): Performance tables report mean improvements for CREDIT but provide neither error bars, standard deviations across random seeds, nor statistical significance tests. This makes it difficult to evaluate whether the claimed 'strongest aggregate performance' is robust, especially given that the central empirical claim concerns consistent gains over standard self-distillation and contrastive baselines.
minor comments (3)
- §3: Although the pMI identity follows immediately from the definitions of the token reward and conditional probability, the manuscript would benefit from an explicit one-paragraph derivation (log P(response|input,feedback) − log P(response|input) = log[P(response,feedback|input)/(P(response|input)P(feedback|input))]) to make the posterior-compatibility step transparent to readers.
- Notation: The abbreviation 'pMI' is introduced without an explicit equation reference in the early sections; adding 'pMI(response; feedback | input) ≜ log [P(response,feedback|input)/(P(response|input)P(feedback|input))]' at first use would improve clarity.
- Related work: The discussion of implicit-reward literature could cite one or two additional recent works on contrastive objectives in RLHF to better situate the CREDIT baseline.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the work and for the constructive recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: §5 (Experiments): Performance tables report mean improvements for CREDIT but provide neither error bars, standard deviations across random seeds, nor statistical significance tests. This makes it difficult to evaluate whether the claimed 'strongest aggregate performance' is robust, especially given that the central empirical claim concerns consistent gains over standard self-distillation and contrastive baselines.
Authors: We agree that reporting variability and statistical significance strengthens the evaluation of robustness. In the revised manuscript we will expand the tables in §5 to include standard deviations across random seeds for all reported metrics and will add paired statistical significance tests (e.g., Wilcoxon signed-rank) comparing CREDIT against the self-distillation and contrastive baselines. These additions will be presented alongside the existing mean improvements without changing the experimental protocol or conclusions. revision: yes
Circularity Check
pMI identity follows directly from reward definition
specific steps
-
self definitional
[Abstract (and corresponding derivation section)]
"Under a posterior-compatibility interpretation of feedback conditioning, standard in the implicit-reward literature, we show that the self-distillation token reward is a Bayesian filtering increment whose trajectory sum is exactly the pointwise mutual information between the response and the feedback given the input."
The token reward is defined as log P(token_t | prefix, input, feedback) − log P(token_t | prefix, input). Its trajectory sum therefore equals log P(response | input, feedback) − log P(response | input) by telescoping. By the definition of pointwise mutual information this is exactly pMI(response; feedback | input). The equality is therefore true by construction from the reward definition; the Bayesian-filtering language and 'we show' framing do not add independent content.
full rationale
The paper's central identity—that the summed token rewards equal pMI(response; feedback | input)—is an immediate consequence of defining the per-token reward as the difference in conditional log-probabilities. This holds by the chain rule and definition of conditional mutual information with no further derivation required. The posterior-compatibility interpretation supplies framing but is not needed for the equality. The subsequent input-axis decomposition and CREDIT contrastive baseline introduce independent modeling choices that go beyond the identity, so the paper retains non-circular content despite the definitional core of the claimed result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Feedback conditioning admits a posterior-compatibility interpretation under which token rewards act as Bayesian filtering increments.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearUnder Assumption 1, ... rt(ŷt) = log π(ŷt|x,y<t,z)/π(ŷt|x,y<t) = log Pπ(z|x,y<t,ŷt)/Pπ(z|x,y<t) = Qzt(ŷt,x)−Vzt−1(x)
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[4]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[6]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
work page 2024
-
[7]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Free process rewards without process labels.arXiv preprint arXiv:2412.01981, 2024
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels.arXiv preprint arXiv:2412.01981, 2024
-
[9]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[10]
arXiv preprint arXiv:2602.12125 , year=
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
-
[11]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review arXiv 2026
-
[12]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, et al. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
-
[15]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. Crisp: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
work page 2023
-
[19]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as probabilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909, 2018
work page internal anchor Pith review arXiv 2018
-
[20]
Policy invariance under reward transforma- tions: Theory and application to reward shaping
Andrew Y Ng, Daishi Harada, and Stuart Russell. Policy invariance under reward transforma- tions: Theory and application to reward shaping. InIcml, volume 99, pages 278–287. Citeseer, 1999
work page 1999
-
[21]
Rl with kl penalties is better viewed as bayesian inference
Tomasz Korbak, Ethan Perez, and Christopher Buckley. Rl with kl penalties is better viewed as bayesian inference. InFindings of the Association for Computational Linguistics: EMNLP 2022, pages 1083–1091, 2022
work page 2022
-
[22]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Sciknoweval: Evaluating multi-level scientific knowledge of large language models
Kehua Feng, Xinyi Shen, Weijie Wang, Xiang Zhuang, Yuqi Tang, Qiang Zhang, and Keyan Ding. Sciknoweval: Evaluating multi-level scientific knowledge of large language models. arXiv preprint arXiv:2406.09098, 2024
-
[24]
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases, 2023 b
Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases.arXiv preprint arXiv:2306.05301, 2023
-
[25]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, et al. 2 olmo 2 furious.arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
work page 2025
-
[28]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[29]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[30]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022. 11
work page 2022
-
[31]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020, 2024
work page internal anchor Pith review arXiv 2024
-
[32]
Vladimir Vapnik and Akshay Vashist. A new learning paradigm: Learning using privileged information.Neural networks, 22(5-6):544–557, 2009
work page 2009
-
[33]
Learning by distilling context.arXiv preprint arXiv:2209.15189, 2022
Charlie Snell, Dan Klein, and Ruiqi Zhong. Learning by distilling context.arXiv preprint arXiv:2209.15189, 2022
-
[34]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025
work page 2025
-
[35]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015. 12 From Generic Correlation to Input-Specific Credit in On-Policy Self Distillation Supplementary Material Table of Contents A Training Hyperparameters . . . . ....
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[36]
The differences between consecutive elements in `copy`are the same as those in ` original`. That is, [...] Python solution: ```python from typing import List def count Arrays(original: List [int], bounds :List [List[int]])-> int : MOD = 10**9+ 7 n = len (original) # Calculate the required difference between consecutive elements diff = original [1] - origi...
-
[37]
For each unique value in [...] ### Python Code: ```python frombis ect import bis ect_left from typing import List def solve Queries(nums: List [int], queries :List [int])-> List [int]: from collections import defaultdict pos = defaultdict (list) for idx ,num in enumerate (nums): pos +12 0 -12 Figure 11: Per-query minimum-distance lookup on a circular arra...
-
[38]
** Output:**For all `Type 2` queries ,we collect and print the popped values in the order they are popped . We can use Python 's built-in ` list`to simulate the stack , where `append()` is used for pushing and ` pop +10 0 -10 Figure 12: Stack simulation with push and pop queries on 100 cards. St concentrates on problem- specific vocabulary ( stack, simula...
-
[39]
**Subarray S +12 0 -12 Figure 13: Same problem as Figure 9, evaluated at training step 20 (earlier checkpoint). The input- specific signal St is weaker and less concentrated than at the later checkpoint, suggesting that the model’s input-specific signal sharpens during training. 23 (a) Problem (b) ΔVₜ(x) reward on response (c) Sₜ(x) reward on response Giv...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.