Recognition: 2 theorem links
· Lean TheoremHide to See: Reasoning-prefix Masking for Visual-anchored Thinking in VLM Distillation
Pith reviewed 2026-05-14 21:06 UTC · model grok-4.3
The pith
Masking salient reasoning prefixes during distillation encourages compact VLMs to anchor their thinking on visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that replacing the standard causal attention mask with a reasoning-prefix mask in the distillation process blocks both future tokens and salient reasoning cues, compelling the student to utilize visual evidence as an alternative information source and thereby improving its visual-anchored thinking capabilities on multimodal tasks.
What carries the argument
The salient reasoning-prefix mask, applied token-wise to high-influence prefixes in the student's reasoning trace, which substitutes for the causal mask to enforce visual reliance.
If this is right
- The distilled student outperforms recent open-source VLMs, VLM distillation, and self-distillation methods on multimodal reasoning benchmarks.
- Further analyses confirm increased visual utilization throughout the student's thinking process.
- Self-paced masking budget scheduling raises the masking scale in line with measured teacher-student distribution discrepancies.
- Token-wise masking targets only the most influential reasoning prefixes for each next-token prediction.
Where Pith is reading between the lines
- The same prefix-masking logic could be tested in audio-language or text-only distillation to force grounding in non-text modalities.
- Controlling which textual cues are visible during training may prove useful for reducing hallucinations by design in any multi-input model.
- The technique might scale differently across VLM sizes, suggesting a follow-up experiment that varies student capacity while holding masking fixed.
- Similar hiding of high-influence prefixes could be tried in pure language-model distillation to promote factual rather than pattern-based reasoning.
Load-bearing premise
Selectively masking high-influence reasoning prefixes will reliably increase the student's reliance on visual evidence without causing the reasoning trace to lose quality or coherence.
What would settle it
If applying the masking produces no measurable increase in visual grounding metrics or benchmark scores relative to a standard-distillation baseline, or if reasoning quality collapses, the central claim does not hold.
Figures






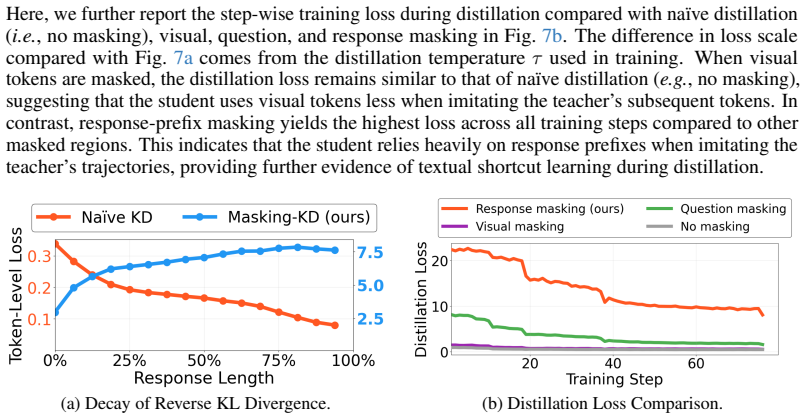





read the original abstract
Recent think-answer approaches in VLMs, such as Qwen3-VL-Thinking, boost reasoning performance by leveraging intermediate thinking steps before the final answer, but their high computational cost limits real-world deployment. To distill such capabilities into compact think-answer VLMs, a primary objective is to improve the student's ability to utilize visual evidence throughout its reasoning trace. To this end, we introduce a novel think-answer distillation framework that encourages the student to anchor its thinking on visual information by masking the student's salient reasoning prefixes. To compensate for such masked textual cues, the student is encouraged to rely more on visual evidence as an alternative source of information during distillation. Our masking strategies include: 1) token-wise salient reasoning-prefix masking, which masks high-influence reasoning prefixes selectively for each next-token prediction, and 2) self-paced masking budget scheduling, which gradually increases the masking scale according to distillation difficulty, {measured by discrepancy between teacher--student distributions. In the distillation phase, the student is guided by our salient reasoning-prefix mask, which blocks both future tokens and salient reasoning cues, in place of the standard causal mask used for auto-regressive language modeling. Experimental results show that our approach outperforms recent open-source VLMs, VLM distillation, and self-distillation methods on multimodal reasoning benchmarks, while further analyses confirm enhanced visual utilization along the student thinking process.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a think-answer distillation framework for VLMs that introduces token-wise salient reasoning-prefix masking (to block high-influence textual cues per next-token prediction) together with self-paced masking budget scheduling (driven by teacher-student distributional discrepancy). The central claim is that this forces the student to increase visual token utilization throughout its reasoning trace, yielding outperformance over recent open-source VLMs, VLM distillation, and self-distillation baselines on multimodal reasoning benchmarks, with supporting analyses of enhanced visual anchoring.
Significance. If the empirical claims hold, the work would provide a practical, training-only modification for distilling complex reasoning into compact VLMs while addressing the known tendency of think-answer models to over-rely on textual coherence. The self-paced discrepancy schedule is a sensible adaptive mechanism that avoids fixed masking budgets. The focus on visual-anchored thinking directly targets a deployment-relevant limitation of current high-cost VLMs.
major comments (2)
- [Abstract] Abstract: the central claim of outperformance on multimodal reasoning benchmarks and enhanced visual utilization is stated without any quantitative results, baseline names, ablation numbers, or metric values, rendering the claim unverifiable from the provided text and load-bearing for acceptance.
- [Method] Method (token-wise salient reasoning-prefix masking): the load-bearing assumption that selectively masking high-influence reasoning prefixes (identified per next-token prediction) will increase visual evidence reliance without trace collapse is unvalidated; no ablation isolates the visual-anchoring effect from generic prefix masking regularization, and the influence computation (gradient, attention, or logit difference) is unspecified.
minor comments (1)
- [Abstract] Abstract: the self-paced scheduling description contains a formatting artifact and appears truncated: 'according to distillation difficulty, {measured by discrepancy between teacher--student distributions.'
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve verifiability and methodological clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of outperformance on multimodal reasoning benchmarks and enhanced visual utilization is stated without any quantitative results, baseline names, ablation numbers, or metric values, rendering the claim unverifiable from the provided text and load-bearing for acceptance.
Authors: We agree that the abstract would be stronger with explicit quantitative support. In the revised version we will insert key results (e.g., absolute gains on MathVista and MMStar versus the strongest open-source VLM and distillation baselines) together with brief references to the main baselines and the visual-anchoring ablations. revision: yes
-
Referee: [Method] Method (token-wise salient reasoning-prefix masking): the load-bearing assumption that selectively masking high-influence reasoning prefixes (identified per next-token prediction) will increase visual evidence reliance without trace collapse is unvalidated; no ablation isolates the visual-anchoring effect from generic prefix masking regularization, and the influence computation (gradient, attention, or logit difference) is unspecified.
Authors: The manuscript computes influence via logit-difference impact on the immediate next-token prediction; this is stated in Section 3.2. Existing experiments already report increased visual-token attention weights under the proposed masking (Section 5.2), which supports the anchoring claim and shows no trace collapse. We nevertheless accept that an explicit comparison against random (non-salient) prefix masking of matched budget is missing; we will add this ablation in the revised experiments section. revision: partial
Circularity Check
No circularity: empirical training modification with independent benchmark validation
full rationale
The paper introduces a distillation framework using token-wise salient reasoning-prefix masking and self-paced discrepancy scheduling to encourage visual anchoring in student VLMs. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; the masking is an explicit training intervention whose effects are measured via external multimodal reasoning benchmarks. Claims rest on comparative experiments rather than self-definitional loops, self-citation chains, or renamed known results. The derivation chain is self-contained as a proposed algorithmic change whose validity is assessed empirically outside the method definition itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- masking budget schedule parameters
axioms (1)
- domain assumption Knowledge distillation can transfer intermediate reasoning capabilities from a large teacher VLM to a compact student.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
token-wise salient reasoning-prefix masking... self-paced masking budget scheduling... salient reasoning-prefix mask ˜M
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
response-to-response attention map Aresp... token-wise reverse KL divergence r
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In ICLR, 2024. 3, 14, 16
2024
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 5, 8, 13, 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Llava-kd: A framework of distilling multimodal large language models
Yuxuan Cai, Jiangning Zhang, Haoyang He, Xinwei He, Ao Tong, Zhenye Gan, Chengjie Wang, Zhucun Xue, Yong Liu, and Xiang Bai. Llava-kd: A framework of distilling multimodal large language models. In ICCV, 2025. 1, 3, 6, 7, 9, 13, 14
2025
-
[5]
Move-kd: Knowledge distillation for vlms with mixture of visual encoders
Jiajun Cao, Yuan Zhang, Tao Huang, Ming Lu, Qizhe Zhang, Ruichuan An, Ningning Ma, and Shanghang Zhang. Move-kd: Knowledge distillation for vlms with mixture of visual encoders. InCVPR, 2025. 9
2025
-
[6]
Lin Chen, Xiaoke Zhao, Kun Ding, Weiwei Feng, Changtao Miao, Zili Wang, Wenxuan Guo, Ying Wang, Kaiyuan Zheng, Bo Zhang, et al. Beyond next-token alignment: Distilling multimodal large language models via token interactions.arXiv preprint arXiv:2602.09483, 2026. 1, 3, 6, 7, 9, 13, 14
-
[7]
Align-kd: Distilling cross-modal alignment knowledge for mobile vision-language model.CVPR, 2025
Qianhan Feng, Wenshuo Li, Tong Lin, and Xinghao Chen. Align-kd: Distilling cross-modal alignment knowledge for mobile vision-language model.CVPR, 2025. 1, 9
2025
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InICLR, 2021. 9
2021
-
[10]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. InNeurIPS Datasets and Benchmarks, 2021. 9
2021
-
[11]
The curious case of neural text degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. InICLR, 2020. 4, 18
2020
-
[12]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Hel- yar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Compodistill: Attention distillation for compositional reasoning in multimodal llms.ICLR, 2026
Jiwan Kim, Kibum Kim, Sangwoo Seo, and Chanyoung Park. Compodistill: Attention distillation for compositional reasoning in multimodal llms.ICLR, 2026. 1, 3, 6, 7, 8, 9, 13, 14
2026
-
[14]
Recursive think-answer process for llms and vlms
Byung-Kwan Lee, Youngchae Chee, and Yong Man Ro. Recursive think-answer process for llms and vlms. CVPR Findings, 2026. 1
2026
-
[15]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InICLR, 2024. 1, 5
2024
-
[16]
Inter- gps: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song-Chun Zhu. Inter- gps: Interpretable geometry problem solving with formal language and symbolic reasoning. InACL, 2021. 5
2021
-
[17]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. 2022. 1
2022
-
[18]
Shiyin Lu, Yang Li, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Han-Jia Ye. Ovis: Structural embedding alignment for multimodal large language model, 2024.arXiv preprint arXiv:2405.20797, 2024. 5, 6
-
[19]
Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning, 2025
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Tiancheng Han, Botian Shi, Wenhai Wang, Junjun He, et al. Mm-eureka: Exploring the frontiers of multimodal reasoning with rule-based reinforcement learning, 2025. 5 10
2025
-
[20]
Introducing gpt-5.4
OpenAI. Introducing gpt-5.4. https://openai.com/index/introducing-gpt-5-4/, 2026. 1
2026
-
[21]
We-math: Does your large multimodal model achieve human-like mathematical reasoning? InACL, 2025
Runqi Qiao, Qiuna Tan, Guanting Dong, MinhuiWu MinhuiWu, Chong Sun, Xiaoshuai Song, Jiapeng Wang, Zhuoma Gongque, Shanglin Lei, Yifan Zhang, et al. We-math: Does your large multimodal model achieve human-like mathematical reasoning? InACL, 2025. 5
2025
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Switch-kd: Visual-switch knowledge distillation for vision-language models.CVPR Findings, 2026
Haoyi Sun, Xiaoxiao Wang, Ning Mao, Qian Wang, Lifu Mu, Wen Zheng, Tao Wei, and Wei Chen. Switch-kd: Visual-switch knowledge distillation for vision-language models.CVPR Findings, 2026. 1, 9
2026
-
[24]
Gemini 3.1 pro: A smarter model for your most complex tasks, 2026
The Gemini Team. Gemini 3.1 pro: A smarter model for your most complex tasks, 2026. 1
2026
-
[25]
More thought, less accuracy? on the dual nature of reasoning in vision-language models
Xinyu Tian, Shu Zou, Zhaoyuan Yang, Mengqi He, Fabian Waschkowski, Lukas Wesemann, Peter Tu, and Jing Zhang. More thought, less accuracy? on the dual nature of reasoning in vision-language models. ICLR, 2026. 2, 8
2026
-
[26]
Attention is all you need.NeurIPS, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.NeurIPS, 2017. 3
2017
-
[27]
Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl-rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. InNeurIPS, 2025. 1, 5, 9, 19
2025
-
[28]
Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning. InNeurIPS, 2025. 2
2025
-
[29]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 5, 6, 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Perception-aware policy optimization for multimodal reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, et al. Perception-aware policy optimization for multimodal reasoning. InICLR, 2026. 1, 2
2026
-
[31]
Sdrt: Enhance vision- language models by self-distillation with diverse reasoning traces, 2025
Guande Wu, Huan Song, Yawei Wang, Qiaojing Yan, Yijun Tian, Lin Lee Cheong, and Panpan Xu. Sdrt: Enhance vision-language models by self-distillation with diverse reasoning traces.arXiv preprint arXiv:2503.01754, 2025. 9
-
[32]
Logicvista: Multimodal llm logical reasoning benchmark in visual contexts
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts. InICLR, 2025. 5
2025
-
[33]
Mimo-vl technical report.arXiv preprint arXiv:2506.03569, 2025
LLM-Core-Team Xiaomi. Mimo-vl technical report.arXiv preprint arXiv:2506.03569, 2025. 5, 6
-
[34]
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization. InICCV, 2025. 1, 9
2025
-
[35]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InACL, 2025. 1, 5
2025
-
[36]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InECCV, 2024. 1, 5
2024
-
[37]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self- distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. R1-zero’s" aha moment" in visual reasoning on a 2b non-sft model.arXiv preprint arXiv:2503.05132, 2025. 1
-
[39]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 5, 6 11 Hide to See: Reasoning-prefix Masking for Visual-anchored Thinking in VLM Distillation -App...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Guidelines: • The answer [NA] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.