Recognition: no theorem link
Behavioral Integrity Verification for AI Agent Skills
Pith reviewed 2026-05-13 05:51 UTC · model grok-4.3
The pith
Behavioral integrity verification shows 80% of AI agent skills deviate from declared capabilities, mostly due to oversight.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that behavioral integrity verification can be formalized as a typed set comparison between declared and actual capabilities over a shared taxonomy. The framework pairs deterministic code analysis with LLM-assisted capability extraction to generate structured evidence. On 49,943 skills, this reveals 80.0% deviation from declared behavior, four novel compound-threat categories, root causes split as 81.1% oversight and 18.9% adversarial intent, and 5.0% of skills with predicted multi-stage attack chains. Malicious skill detection reaches an F1 of 0.946 on 906 skills, outperforming rule-based and single-pass LLM baselines.
What carries the argument
The BIV framework, which performs a typed set comparison between declared and actual capabilities over a shared taxonomy by pairing deterministic code analysis with LLM-assisted capability extraction.
If this is right
- The deviation taxonomy surfaces four novel compound-threat categories for classifying complex risks.
- Root-cause classification shows the majority of issues trace to oversight and can be addressed through improved development practices.
- 5.0% of skills carry predicted multi-stage attack chains that warrant targeted scrutiny.
- Malicious skill detection achieves an F1 of 0.946 and outperforms existing rule-based and single-pass LLM baselines.
Where Pith is reading between the lines
- Agent skill platforms could require BIV checks before publishing tools to reduce unsafe capabilities reaching users.
- The taxonomy could inform developer guidelines that minimize accidental description-implementation gaps.
- Adapting the extraction approach to monitor skills at runtime might catch behavioral changes after initial approval.
- Repeating the audit on skills from other registries would indicate whether the 80% deviation rate is widespread.
Load-bearing premise
The LLM-assisted capability extraction accurately and consistently identifies actual skill capabilities from code, instructions, and metadata without substantial errors or biases that would invalidate the deviation taxonomy or detection results.
What would settle it
A large-scale manual review of extracted capabilities on a random sample of skills from the registry that shows frequent mismatches with the automated taxonomy would falsify the deviation rates and detection performance.
Figures

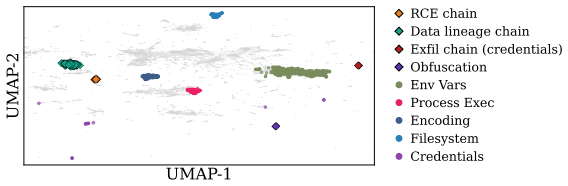
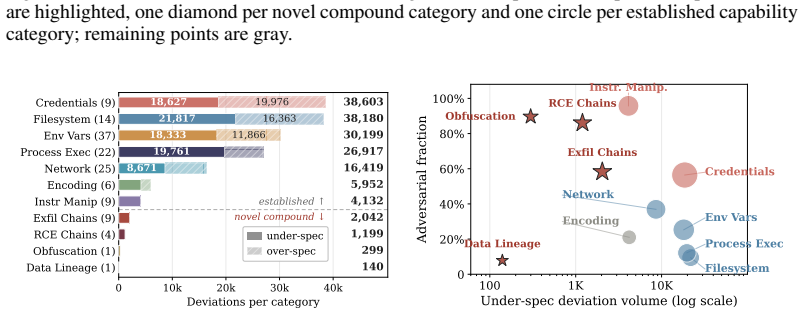



read the original abstract
Agent skills extend LLM agents with privileged third-party capabilities such as filesystem access, credentials, network calls, and shell execution. Existing safety work catches malicious prompts and risky runtime actions, but the skill artifact itself goes unverified. We formalize this as the behavioral integrity verification (BIV) problem: a typed set comparison between declared and actual capabilities over a shared taxonomy that bridges code, instructions, and metadata. The BIV framework instantiates this comparison by pairing deterministic code analysis with LLM-assisted capability extraction. The resulting structured evidence supports three downstream analyses: deviation taxonomy, root-cause classification, and malicious-skill detection. On 49,943 skills from the OpenClaw registry, the deviation taxonomy reveals a pervasive description-implementation gap: 80.0% of skills deviate from declared behavior, with four novel compound-threat categories surfaced. Root-cause classification finds that deviations are mostly oversight, not malice: 81.1% trace to developer oversight and 18.9% to adversarial intent, with 5.0% of skills carrying predicted multi-stage attack chains. On a 906-skill malicious-skill detection benchmark, BIV reaches an F1 of 0.946, outperforming state-of-the-art rule-based and single-pass LLM baselines. These results demonstrate behavioral integrity auditing for agent skills at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the behavioral integrity verification (BIV) problem for AI agent skills, formalizing it as a typed set comparison between declared and actual capabilities using a shared taxonomy. It instantiates BIV via deterministic code analysis paired with LLM-assisted capability extraction, then applies the framework to three analyses: a deviation taxonomy on 49,943 OpenClaw skills (reporting 80.0% deviation with four novel compound-threat categories), root-cause classification (81.1% oversight vs. 18.9% adversarial intent, 5.0% multi-stage chains), and malicious-skill detection on a 906-skill benchmark (F1=0.946, outperforming rule-based and single-pass LLM baselines).
Significance. If the extraction step holds, the work provides the first large-scale empirical audit of the description-implementation gap in agent skills, demonstrating that most deviations stem from oversight rather than malice and offering a practical detection method that improves on existing baselines. The scale (nearly 50k skills) and concrete metrics are strengths; the framework could support ongoing registry auditing if validated.
major comments (1)
- [Methods/Evaluation] Methods and Evaluation sections: the LLM-assisted capability extraction step that produces the 'actual' capability sets is central to all headline results (80.0% deviation rate, 81.1%/18.9% split, 5.0% multi-stage chains, and F1=0.946), yet no large-scale human ground-truth validation, inter-annotator agreement, or error-rate measurement is reported on the OpenClaw corpus. Systematic extraction errors (e.g., missed implicit calls or metadata misclassification) would directly propagate into the taxonomy and detection claims without being detectable from the reported numbers.
minor comments (2)
- [Abstract/§4] Abstract and §4: clarify how the 906-skill malicious-skill benchmark was constructed and labeled, including any overlap with the 49,943-skill corpus.
- [Results] Figure 3 or equivalent: add error bars or confidence intervals to the reported percentages and F1 scores.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and recommendation. We address the major comment below and will revise the manuscript accordingly to strengthen the validation of our methods.
read point-by-point responses
-
Referee: [Methods/Evaluation] Methods and Evaluation sections: the LLM-assisted capability extraction step that produces the 'actual' capability sets is central to all headline results (80.0% deviation rate, 81.1%/18.9% split, 5.0% multi-stage chains, and F1=0.946), yet no large-scale human ground-truth validation, inter-annotator agreement, or error-rate measurement is reported on the OpenClaw corpus. Systematic extraction errors (e.g., missed implicit calls or metadata misclassification) would directly propagate into the taxonomy and detection claims without being detectable from the reported numbers.
Authors: We agree that the reliability of the LLM-assisted capability extraction is central to all reported results and that the absence of large-scale human validation is a limitation. The original manuscript focused on the deterministic code analysis component for grounding but did not report human ground-truth metrics on the full corpus. In the revised manuscript, we will add a new subsection in the Evaluation section describing a human validation study on a stratified sample of 500 skills. This will report inter-annotator agreement, extraction error rates, and an analysis of potential systematic issues such as missed implicit calls. We will also expand the description of the LLM prompt engineering and few-shot examples used. revision: yes
Circularity Check
No significant circularity; empirical results derive from external registry and separate benchmark without reduction to self-referential definitions or fitted inputs.
full rationale
The paper defines BIV as a typed set comparison between declared and actual capabilities, instantiated via deterministic code analysis plus LLM-assisted extraction. Headline statistics (80% deviation rate, root-cause splits, 5% multi-stage chains, F1=0.946) are computed directly from applying this comparison to the external OpenClaw registry (49,943 skills) and a separate 906-skill benchmark. No equations or steps reduce a claimed prediction or taxonomy to quantities defined in terms of the same fitted parameters or self-citations. The LLM extraction step is a methodological component whose accuracy is assumed rather than derived from the results themselves; this is a validation gap, not a circular reduction. The derivation chain remains self-contained against the stated external data sources.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A shared taxonomy exists that can bridge code, instructions, and metadata for capability comparison.
Reference graph
Works this paper leans on
-
[1]
Re- Act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- Act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[2]
Toolformer: Language models can teach them- selves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess `ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach them- selves to use tools. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023), 2023
work page 2023
-
[3]
Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N
William Enck, Peter Gilbert, Seungyeop Han, Vasant Tendulkar, Byung-Gon Chun, Landon P. Cox, Jaeyeon Jung, Patrick McDaniel, and Anmol N. Sheth. TaintDroid: An information-flow tracking sys- tem for realtime privacy monitoring on smartphones. InProceedings of the 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 393–407. US...
work page 2010
-
[4]
DREBIN: Effective and explainable detection of Android malware in your pocket
Daniel Arp, Michael Spreitzenbarth, Malte Hubner, Hugo Gascon, and Konrad Rieck. DREBIN: Effective and explainable detection of Android malware in your pocket. InProceedings of the 2014 Network and Distributed System Security Symposium (NDSS). Internet Society, 2014
work page 2014
-
[5]
Trends and lessons from three years fighting malicious extensions
Nav Jagpal, Eric Dingle, Jean-Philippe Gravel, Panayiotis Mavrommatis, Niels Provos, Moheeb Abu Rajab, and Kurt Thomas. Trends and lessons from three years fighting malicious extensions. In24th USENIX Security Symposium, pages 579–593. USENIX Association, 2015
work page 2015
-
[6]
Hulk: Eliciting malicious behavior in browser extensions
Alexandros Kapravelos, Chris Grier, Neha Chachra, Christopher Kruegel, Giovanni Vigna, and Vern Paxson. Hulk: Eliciting malicious behavior in browser extensions. In23rd USENIX Security Symposium, pages 641–654. USENIX Association, 2014
work page 2014
-
[7]
Small world with high risks: A study of security threats in the npm ecosystem
Markus Zimmermann, Cristian-Alexandru Staicu, Cam Tenny, and Michael Pradel. Small world with high risks: A study of security threats in the npm ecosystem. In28th USENIX Security Symposium, pages 995–1010. USENIX Association, 2019
work page 2019
-
[8]
Towards measuring supply chain attacks on package managers for interpreted languages
Ruian Duan, Omar Alrawi, Ranjita Pai Kasturi, Ryan Elder, Brendan Saltaformaggio, and Wenke Lee. Towards measuring supply chain attacks on package managers for interpreted languages. InProceedings of the 2021 Network and Distributed System Security Symposium (NDSS). Internet Society, 2021
work page 2021
-
[9]
Tensor Trust: Interpretable prompt injection attacks from an online game
Sam Toyer, Olivia Watkins, Ethan Adrian Mendes, Justin Svegliato, Luke Bailey, Tiffany Wang, Isaac Ong, Karim Elmaaroufi, Pieter Abbeel, Trevor Darrell, Alan Ritter, and Stuart Russell. Tensor Trust: Interpretable prompt injection attacks from an online game. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[10]
WHYPER: Towards automating risk assessment of mobile applications
Rahul Pandita, Xusheng Xiao, Wei Yang, William Enck, and Tao Xie. WHYPER: Towards automating risk assessment of mobile applications. In22nd USENIX Security Symposium, pages 527–542. USENIX Association, 2013
work page 2013
-
[11]
Checking app behavior against app descriptions
Alessandra Gorla, Ilaria Tavecchia, Florian Gross, and Andreas Zeller. Checking app behavior against app descriptions. InProceedings of the 36th International Conference on Software Engineering (ICSE), pages 1025–1035. ACM, 2014
work page 2014
-
[12]
SoK: Taxonomy of attacks on open-source software supply chains
Piergiorgio Ladisa, Henrik Plate, Matias Martinez, and Olivier Barais. SoK: Taxonomy of attacks on open-source software supply chains. In2023 IEEE Symposium on Security and Privacy (SP), pages 1509–1526. IEEE, 2023. 11
work page 2023
-
[13]
Ad injection at scale: Assessing deceptive advertisement modifications
Kurt Thomas, Elie Bursztein, Chris Grier, Grant Ho, Nav Jagpal, Alexandros Kapravelos, Damon McCoy, Antonio Nappa, Vern Paxson, Niels Provos, Moheeb Abu Rajab, and Giovanni Vigna. Ad injection at scale: Assessing deceptive advertisement modifications. In2015 IEEE Symposium on Security and Privacy, pages 151–167. IEEE, 2015
work page 2015
-
[14]
You’ve changed: Detecting malicious browser extension updates
Nikolaos Pantelaios, Nick Nikiforakis, and Alexandros Kapravelos. You’ve changed: Detecting malicious browser extension updates. InProceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 477–491. ACM, 2020
work page 2020
-
[15]
Data exposure from llm apps: An in-depth investigation of openai’s gpts,
Yuhao Wu, Evin Jaff, Ke Yang, Ning Zhang, and Umar Iqbal. An in-depth investigation of data collection in LLM app ecosystems. InProceedings of the ACM Internet Measurement Conference (IMC), 2025. arXiv preprint arXiv:2408.13247
-
[16]
A measurement study of model context protocol (MCP) ecosystem.arXiv preprint arXiv:2509.25292, 2025
Hechuan Guo, Yongle Hao, Yue Zhang, Minghui Xu, Peizhuo Lv, Jiezhi Chen, and Xiuzhen Cheng. A measurement study of model context protocol (MCP) ecosystem.arXiv preprint arXiv:2509.25292, 2025
-
[17]
Parasites in the Toolchain: A Large-Scale Analysis of Attacks on the MCP Ecosystem
Shuli Zhao, Qinsheng Hou, Zihan Zhan, Yanhao Wang, Yuchong Xie, Yu Guo, Libo Chen, Shenghong Li, and Zhi Xue. Parasites in the toolchain: A large-scale analysis of attacks on the MCP ecosystem.arXiv preprint arXiv:2509.06572, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Zhihao Li, Boyang Ma, Xuelong Dai, Minghui Xu, Yue Zhang, Biwei Yan, and Kun Li. Don’t believe everything you read: Understanding and measuring MCP behavior under misleading tool descriptions. arXiv preprint arXiv:2602.03580, 2026
-
[19]
Yiheng Huang, Zhijia Zhao, Bihuan Chen, and Susheng Wu. From component manipulation to system compromise: Understanding and detecting malicious MCP servers.arXiv preprint arXiv:2604.01905, 2026
-
[20]
SkillSieve: A Hierarchical Triage Framework for Detecting Malicious AI Agent Skills
Yinghan Hou and Zongyou Yang. SkillSieve: A hierarchical triage framework for detecting malicious AI agent skills.arXiv preprint arXiv:2604.06550, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Shenao Wang, Junjie He, Yanjie Zhao, Yayi Wang, Kan Yu, and Haoyu Wang. “elementary, my dear watson.” detecting malicious skills via neuro-symbolic reasoning across heterogeneous artifacts.arXiv preprint arXiv:2603.27204, 2026
-
[22]
Varun Pratap Bhardwaj. Formal analysis and supply chain security for agentic AI skills.arXiv preprint arXiv:2603.00195, 2026
-
[23]
Modeling and discovering vulnerabilities with code property graphs
Fabian Yamaguchi, Nico Golde, Daniel Arp, and Konrad Rieck. Modeling and discovering vulnerabilities with code property graphs. In2014 IEEE Symposium on Security and Privacy, pages 590–604. IEEE, 2014
work page 2014
-
[24]
Steven Arzt, Siegfried Rasthofer, Christian Fritz, Eric Bodden, Alexandre Bartel, Jacques Klein, Yves Le Traon, Damien Octeau, and Patrick McDaniel. FlowDroid: Precise context, flow, field, object-sensitive and lifecycle-aware taint analysis for Android apps. InProceedings of the 35th ACM SIGPLAN Confer- ence on Programming Language Design and Implementat...
work page 2014
-
[25]
Benjamin Livshits and Monica S
V . Benjamin Livshits and Monica S. Lam. Finding security vulnerabilities in Java applications with static analysis. In14th USENIX Security Symposium, pages 271–286. USENIX Association, 2005
work page 2005
-
[26]
BadAgent: Inserting and activating backdoor attacks in LLM agents
Yifei Wang, Dizhan Xue, Shengjie Zhang, and Shengsheng Qian. BadAgent: Inserting and activating backdoor attacks in LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9811–9827. Association for Computational Linguistics, 2024
work page 2024
-
[27]
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. Andriushchenko. Skill-Inject: Measuring agent vulnerability to skill file attacks.arXiv preprint arXiv:2602.20156, 2026
-
[28]
AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[29]
Prompt injection attack to tool selection in llm agents.arXiv preprint arXiv:2504.19793, 2025
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. Prompt injection attack to tool selection in LLM agents. InNetwork and Distributed System Security Symposium (NDSS), 2026. arXiv preprint arXiv:2504.19793
-
[30]
Juhee Kim, Woohyuk Choi, and Byoungyoung Lee. Prompt flow integrity to prevent privilege escalation in LLM agents.arXiv preprint arXiv:2503.15547, 2025. 12
-
[31]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InProceedings of the 2023 Workshop on Artificial Intelligence and Security (AISec), co-located with ACM CCS, pages 79–90. ACM, 2023
work page 2023
-
[32]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi ´c, Luca Beurer-Kellner, Marc Fischer, and Florian Tram`er. AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), Datasets and Bench- marks Track, 2024
work page 2024
-
[33]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM- as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[34]
R-Judge: Benchmarking safety risk awareness for LLM agents
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, Rui Wang, and Gongshen Liu. R-Judge: Benchmarking safety risk awareness for LLM agents. InFindings of the Association for Computational Linguistics (EMNLP), 2024
work page 2024
-
[35]
Llama Guard: LLM-based input-output safeguard for human-AI conversations, 2023
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama Guard: LLM-based input-output safeguard for human-AI conversations, 2023
work page 2023
-
[36]
Watch out for your agents! investigating backdoor threats to LLM-based agents
Wenkai Yang, Xiaohan Bi, Yankai Lin, Sishuo Chen, Jie Zhou, and Xu Sun. Watch out for your agents! investigating backdoor threats to LLM-based agents. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[37]
SecGPT: An execution isolation architecture for LLM-based systems
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. IsolateGPT: An execu- tion isolation architecture for LLM-based agentic systems. InNetwork and Distributed System Security Symposium (NDSS), 2025. arXiv preprint arXiv:2403.04960; originally titled SecGPT
-
[38]
Alexander Robey, Eric Wong, Hamed Hassani, and George J. Pappas. SmoothLLM: Defending large language models against jailbreaking attacks.Transactions on Machine Learning Research (TMLR),
-
[39]
arXiv preprint arXiv:2310.03684
work page internal anchor Pith review arXiv
-
[40]
Towards automating data access permissions in AI agents
Yuhao Wu, Ke Yang, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. Towards automating data access permissions in AI agents. In2026 IEEE Symposium on Security and Privacy (SP), 2026. arXiv preprint arXiv:2511.17959
-
[41]
Jerome H. Saltzer and Michael D. Schroeder. The protection of information in computer systems.Pro- ceedings of the IEEE, 63(9):1278–1308, 1975
work page 1975
-
[42]
Sentence-BERT: Sentence embeddings using siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3982–3992. Association for Computational Linguistics, 2019
work page 2019
-
[43]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. UMAP: Uniform manifold approximation and projec- tion for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Ricardo J. G. B. Campello, Davoud Moulavi, and J ¨org Sander. Density-based clustering based on hi- erarchical density estimates. InAdvances in Knowledge Discovery and Data Mining (PAKDD), pages 160–172. Springer, 2013
work page 2013
-
[45]
Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, Ying Zhang, and Leo Yu Zhang. Malicious agent skills in the wild: A large-scale security empirical study.arXiv preprint arXiv:2602.06547, 2026. Dataset athttps://huggingface.co/datasets/ProtectSkills/ MaliciousAgentSkillsBench
-
[46]
Xiaojun Jia, Jie Liao, Simeng Qin, Jindong Gu, Wenqi Ren, Xiaochun Cao, Yang Liu, and Philip Torr. SkillJect: Automating stealthy skill-based prompt injection for coding agents with trace-driven closed- loop refinement.arXiv preprint arXiv:2602.14211, 2026
-
[47]
Messaging integration: post messages and notify users from the agent
Cisco AI Defense. Cisco AI defense skill scanner.https://github.com/cisco-ai-defense/ skill-scanner, 2025. Apache 2.0 License. 13 A Hallucination-Control Filters The two LLM-based extractors (Semantic Extractor on the declared track and Instruction Analyzer on the actual track; §3) apply three filters to control hallucination risk:Taxonomy-echo rejection ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.