Recognition: no theorem link
GEAR: Granularity-Adaptive Advantage Reweighting for LLM Agents via Self-Distillation
Pith reviewed 2026-05-13 06:37 UTC · model grok-4.3
The pith
GEAR reshapes LLM agent advantages by using self-distillation divergence spikes to set adaptive segment boundaries for credit assignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GEAR compares an on-policy student with a ground-truth-conditioned teacher to obtain a reference-guided divergence signal for identifying adaptive segment boundaries and modulating local advantage weights. The signal spikes at the onset of semantic deviation; GEAR therefore treats such spikes as anchors, preserving token-level resolution where the student stays aligned and grouping the continuation into an adaptive segment whose advantage is reweighted by the departure-point divergence.
What carries the argument
The divergence signal between on-policy student and ground-truth-conditioned teacher, used both to locate semantic deviation onsets and to modulate segment-level advantage weights within trajectory-level GRPO.
If this is right
- GEAR delivers consistent gains over GRPO and over token-level or turn-level credit assignment on mathematical reasoning and tool-use tasks.
- The largest improvements appear on benchmarks where standard GRPO baseline accuracy is lowest, reaching up to around 20 percent relative gain.
- Adaptive segments combine fine token resolution in aligned regions with coarser modulation in deviated regions, improving policy updates on long-horizon trajectories.
- The same self-distillation comparison supplies both the boundary signal and the weighting factor without requiring extra human annotations.
Where Pith is reading between the lines
- The divergence-based segmentation could be tested as a drop-in module inside other outcome-level RL algorithms for language models beyond GRPO.
- If the same teacher-student divergence pattern holds in longer or more open-ended agent trajectories, GEAR-style reweighting might reduce the sample inefficiency that currently limits scaling of agent training.
- The method implicitly shows that internal model disagreement can substitute for external reward shaping in credit-assignment problems.
Load-bearing premise
The divergence between the on-policy student and the ground-truth-conditioned teacher reliably marks the exact points where semantic deviations begin and therefore supplies suitable boundaries for adaptive segments.
What would settle it
A controlled ablation on one of the eight benchmarks in which divergence spikes are replaced by random or fixed boundaries and performance gains over GRPO disappear.
Figures


read the original abstract
Reinforcement learning has become a widely used post-training approach for LLM agents, where training commonly relies on outcome-level rewards that provide only coarse supervision. While finer-grained credit assignment is promising for effective policy updates, obtaining reliable local credit and assigning it to the right parts of the long-horizon trajectory remains an open challenge. In this paper, we propose Granularity-adaptivE Advantage Reweighting (GEAR), an adaptive-granularity credit assignment framework that reshapes the trajectory-level GRPO advantage using token- and segment-level signals derived from self-distillation. GEAR compares an on-policy student with a ground-truth-conditioned teacher to obtain a reference-guided divergence signal for identifying adaptive segment boundaries and modulating local advantage weights. This divergence often spikes at the onset of a semantic deviation, while later tokens in the same autoregressive continuation may return to low divergence. GEAR therefore treats such spikes as anchors for adaptive credit regions: where the student remains aligned with the teacher, token-level resolution is preserved; where it departs, GEAR groups the corresponding continuation into an adaptive segment and uses the divergence at the departure point to modulate the segment' s advantage. Experiments across eight mathematical reasoning and agentic tool-use benchmarks with Qwen3 4B and 8B models show that GEAR consistently outperforms standard GRPO, self-distillation-only baselines, and token- or turn-level credit-assignment methods. The gains are especially strong on benchmarks with lower GRPO baseline accuracy, reaching up to around 20\% over GRPO, suggesting that the proposed adaptive reweighting scheme is especially useful in more challenging long-horizon settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Granularity-adaptivE Advantage Reweighting (GEAR), an adaptive credit-assignment method for RL post-training of LLM agents. GEAR reshapes trajectory-level GRPO advantages by deriving token- and segment-level signals from the divergence between an on-policy student policy and a ground-truth-conditioned teacher obtained via self-distillation. Divergence spikes are used to define adaptive segment boundaries, preserving token-level resolution where the student aligns with the teacher and modulating segment-level advantage weights at departure points. Experiments on eight mathematical reasoning and agentic tool-use benchmarks with Qwen3 4B/8B models report consistent gains over GRPO, self-distillation baselines, and fixed-granularity credit assignment methods, with improvements reaching ~20% on lower-baseline tasks.
Significance. If the adaptive-granularity mechanism proves robust, GEAR could meaningfully advance credit assignment for long-horizon LLM agent training by providing a reference-guided way to group tokens without manual turn-level annotations. The self-distillation signal supplies an external anchor that is cheap to obtain at training time, and the reported gains on harder benchmarks suggest practical utility where outcome-level rewards are especially coarse.
major comments (3)
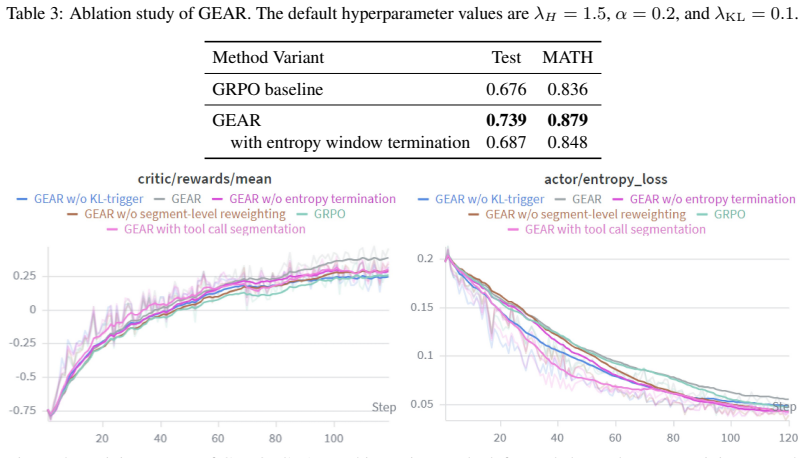
- [§3.2] §3.2 (Divergence-based segmentation): The central claim that divergence 'often spikes at the onset of a semantic deviation' and thereby supplies reliable adaptive boundaries is load-bearing for attributing gains to the granularity-adaptive component rather than to self-distillation alone. No quantitative validation is supplied—e.g., no alignment statistics with human-annotated error locations, no ablation replacing divergence spikes with random or fixed-length segments, and no sensitivity analysis on the spike-detection threshold. Without such checks the observed improvements could arise from any local reweighting or from the teacher signal itself.
- [§4.1–4.2] §4.1–4.2 (Experimental tables): The reported gains (up to ~20% over GRPO on low-baseline tasks) are presented without error bars, number of random seeds, or statistical significance tests. This makes it impossible to determine whether the advantage of GEAR over token-level and turn-level baselines is robust or could be explained by variance in the GRPO baseline runs.
- [§3.3] §3.3 (Advantage modulation formula): The precise mapping from divergence value at a spike to the segment-level weight multiplier is not derived or shown to be parameter-free; if the modulation depends on additional hyperparameters (e.g., scaling factors or thresholds), the method loses the claimed advantage of being driven purely by the self-distillation signal.
minor comments (2)
- [Abstract / §1] The abstract and §1 use 'around 20%' without specifying the exact benchmark or baseline accuracy; a precise table reference would improve clarity.
- [§3] Notation for the divergence signal (e.g., D(s,t) or similar) should be introduced once in §3 and used consistently; occasional informal phrasing ('spikes', 'anchors') could be replaced by the formal definition.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating planned revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Divergence-based segmentation): The central claim that divergence 'often spikes at the onset of a semantic deviation' and thereby supplies reliable adaptive boundaries is load-bearing for attributing gains to the granularity-adaptive component rather than to self-distillation alone. No quantitative validation is supplied—e.g., no alignment statistics with human-annotated error locations, no ablation replacing divergence spikes with random or fixed-length segments, and no sensitivity analysis on the spike-detection threshold. Without such checks the observed improvements could arise from any local reweighting or from the teacher signal itself.
Authors: We agree that direct validation of the divergence-spike mechanism is needed to attribute gains specifically to adaptive granularity. In the revised manuscript we will add an ablation replacing divergence-based segmentation with both random segments and fixed-length segments, reporting performance deltas to isolate the adaptive component. We will also include sensitivity analysis across a range of spike-detection thresholds. Human-annotated error locations are not available for the benchmarks used; we will instead add qualitative trajectory examples in the appendix showing divergence spikes at clear semantic deviation points. These changes will clarify that improvements exceed those from self-distillation or generic local reweighting alone. revision: yes
-
Referee: [§4.1–4.2] §4.1–4.2 (Experimental tables): The reported gains (up to ~20% over GRPO on low-baseline tasks) are presented without error bars, number of random seeds, or statistical significance tests. This makes it impossible to determine whether the advantage of GEAR over token-level and turn-level baselines is robust or could be explained by variance in the GRPO baseline runs.
Authors: We concur that the absence of error bars, seed counts, and significance testing limits assessment of robustness. We will rerun all experiments with at least three random seeds, report means and standard deviations in the tables, and add paired t-tests (or equivalent) between GEAR and each baseline to establish statistical significance of the observed gains. revision: yes
-
Referee: [§3.3] §3.3 (Advantage modulation formula): The precise mapping from divergence value at a spike to the segment-level weight multiplier is not derived or shown to be parameter-free; if the modulation depends on additional hyperparameters (e.g., scaling factors or thresholds), the method loses the claimed advantage of being driven purely by the self-distillation signal.
Authors: The segment-level multiplier is obtained by normalizing the divergence value at each detected spike so that the weighted sum of advantages across the full trajectory equals the original GRPO advantage; this normalization uses only the divergence signal itself and introduces no external scaling factors or thresholds. We will revise §3.3 to present the exact derivation and formula explicitly, confirming that the modulation remains driven solely by the self-distillation divergence. revision: yes
Circularity Check
No significant circularity detected in GEAR derivation
full rationale
The paper presents GEAR as a method that computes a divergence signal between an on-policy student and a ground-truth-conditioned teacher (via self-distillation) to identify adaptive segment boundaries and modulate GRPO advantages. No equations, fitted parameters, or self-citations are shown that reduce the claimed adaptive reweighting, segment boundaries, or performance gains to quantities defined by the same inputs by construction. The divergence signal is introduced as an external reference signal rather than a self-referential fit, and the central claims rest on empirical comparisons rather than any load-bearing self-citation chain or ansatz smuggling. This is the most common honest outcome for a method paper whose core contribution is a new combination of existing signals.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Divergence between on-policy student and ground-truth-conditioned teacher reliably marks the onset of semantic deviations suitable for segmenting credit regions
Reference graph
Works this paper leans on
-
[1]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[2]
Saikat Barua. Exploring autonomous agents through the lens of large language models: A review.arXiv preprint arXiv:2404.04442, 2024
-
[3]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
React: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023
work page 2023
-
[5]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. Toolrl: Reward is all tool learning needs.arXiv preprint arXiv:2504.13958, 2025
work page internal anchor Pith review arXiv 2025
-
[6]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[8]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
work page 1998
-
[10]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[11]
Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment
Siliang Zeng, Quan Wei, William Brown, Oana Frunza, Yuriy Nevmyvaka, Yang Katie Zhao, and Mingyi Hong. Reinforcing multi-turn reasoning in llm agents via turn-level credit assignment. InICML 2025 Workshop on Computer Use Agents, 2025
work page 2025
-
[12]
Empowering llm tool invocation with tool-call reward model
Da Ma, Ziyue Yang, Hongshen Xu, Haotian Fang, Kai Yu, and Lu Chen. Empowering llm tool invocation with tool-call reward model. InThe F ourteenth International Conference on Learning Representations
-
[13]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning, 2025
work page 2025
-
[15]
Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, and Zhenzhe Ying. Information gain-based policy optimization: A simple and effective approach for multi-turn llm agents.arXiv preprint arXiv:2510.14967, 2025
-
[16]
Group-in-group policy optimization for llm agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 10
-
[17]
Jiangweizhi Peng, Yuanxin Liu, Ruida Zhou, Charles Fleming, Zhaoran Wang, Alfredo Garcia, and Mingyi Hong. Hiper: Hierarchical reinforcement learning with explicit credit assignment for large language model agents.arXiv preprint arXiv:2602.16165, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 9426–9439, 2024
work page 2024
-
[19]
Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment. 2024
work page 2024
-
[20]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Process reward model with q-value rankings.arXiv preprint arXiv:2410.11287, 2024
Wendi Li and Yixuan Li. Process reward model with q-value rankings.arXiv preprint arXiv:2410.11287, 2024
-
[23]
Jialun Zhong, Wei Shen, Yanzeng Li, Songyang Gao, Hua Lu, Yicheng Chen, Yang Zhang, Wei Zhou, Jinjie Gu, and Lei Zou. A comprehensive survey of reward models: Taxonomy, applications, challenges, and future.arXiv preprint arXiv:2504.12328, 2025
-
[24]
Agentprm: Process reward models for llm agents via step-wise promise and progress
Zhiheng Xi, Chenyang Liao, Guanyu Li, Zhihao Zhang, Wenxiang Chen, Binghai Wang, Senjie Jin, Yuhao Zhou, Jian Guan, Wei Wu, et al. Agentprm: Process reward models for llm agents via step-wise promise and progress. InProceedings of the ACM Web Conference 2026, pages 4184–4195, 2026
work page 2026
-
[25]
Quan Wei, Siliang Zeng, Chenliang Li, William Brown, Oana Frunza, Wei Deng, Anderson Schneider, Yuriy Nevmyvaka, Yang Katie Zhao, Alfredo Garcia, et al. Reinforcing multi-turn reasoning in llm agents via turn-level reward design.arXiv preprint arXiv:2505.11821, 2025
-
[26]
Zhen Zhang, Kaiqiang Song, Xun Wang, Yebowen Hu, Weixiang Yan, Chenyang Zhao, Henry Peng Zou, Haoyun Deng, Sathish Reddy Indurthi, Shujian Liu, et al. Cm2: Rein- forcement learning with checklist rewards for multi-turn and multi-step agentic tool use.arXiv preprint arXiv:2602.12268, 2026
-
[27]
Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, and Shuang Qiu. Segment policy optimization: Ef- fective segment-level credit assignment in rl for large language models.arXiv preprint arXiv:2505.23564, 2025
-
[28]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled rlvr.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, et al. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning.arXiv preprint arXiv:2504.20073, 2025
work page internal anchor Pith review arXiv 2025
-
[30]
Yanfei Zhang. Agent-as-tool: A study on the hierarchical decision making with reinforcement learning.arXiv preprint arXiv:2507.01489, 2025
-
[31]
Shuo Yang, Soyeon Caren Han, Yihao Ding, Shuhe Wang, and Eduard Hoy. Tooltree: Efficient llm agent tool planning via dual-feedback monte carlo tree search and bidirectional pruning. arXiv preprint arXiv:2603.12740, 2026
-
[32]
Tips: Turn-level information-potential reward shaping for search-augmented llms
Yutao Xie, Nathaniel Thomas, Nicklas Hansen, Yang Fu, Li Erran Li, and Xiaolong Wang. Tips: Turn-level information-potential reward shaping for search-augmented llms. InThe F ourteenth International Conference on Learning Representations. 11
-
[33]
arXiv preprint arXiv:2408.07199 , year=
Pranav Putta, Edmund Mills, Naman Garg, Sumeet Motwani, Chelsea Finn, Divyansh Garg, and Rafael Rafailov. Agent q: Advanced reasoning and learning for autonomous ai agents.arXiv preprint arXiv:2408.07199, 2024
-
[34]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning acting and planning in language models.arXiv preprint arXiv:2310.04406, 2023
-
[35]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms.arXiv preprint arXiv:2504.11536, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
Yunpeng Zhai, Shuchang Tao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Yu, Jiaji Deng, Zouying Cao, et al. Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
-
[37]
Scaling environments for llm agents: Fundamentals, approaches, and future directions
Yuchen Huang, Sijia Li, Zhiyuan Fan, Minghao LIU, Wei Liu, and Yi R Fung. Scaling environments for llm agents: Fundamentals, approaches, and future directions. InWorkshop on Scaling Environments for Agents, 2025b. URL https://openreview. net/forum, 2025
work page 2025
-
[38]
Agentic reinforced policy optimization
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, et al. Agentic reinforced policy optimization. arXiv preprint arXiv:2507.19849, 2025
-
[39]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[41]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, et al. Toolsandbox: A stateful, conversational, inter- active evaluation benchmark for llm tool use capabilities. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1160–1183, 2025
work page 2025
-
[42]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InF orty-second International Conference on Machine Learning, 2025
work page 2025
-
[43]
arXiv preprint arXiv:2501.12851 , year=
Chen Chen, Xinlong Hao, Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Yuefeng Huang, et al. Acebench: Who wins the match point in tool usage? arXiv preprint arXiv:2501.12851, 2025
-
[44]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025. 12 Algorithm 1Granularity-AdaptivE Advantage Reweighting (GEAR) Require: Initial policy πθ, r...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.