Recognition: 3 theorem links
· Lean TheoremProteus: A Self-Evolving Red Team for Agent Skill Ecosystems
Pith reviewed 2026-05-13 05:26 UTC · model grok-4.3
The pith
Current vetting of agent skills underestimates residual risk from adaptive attackers who iteratively refine them using feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
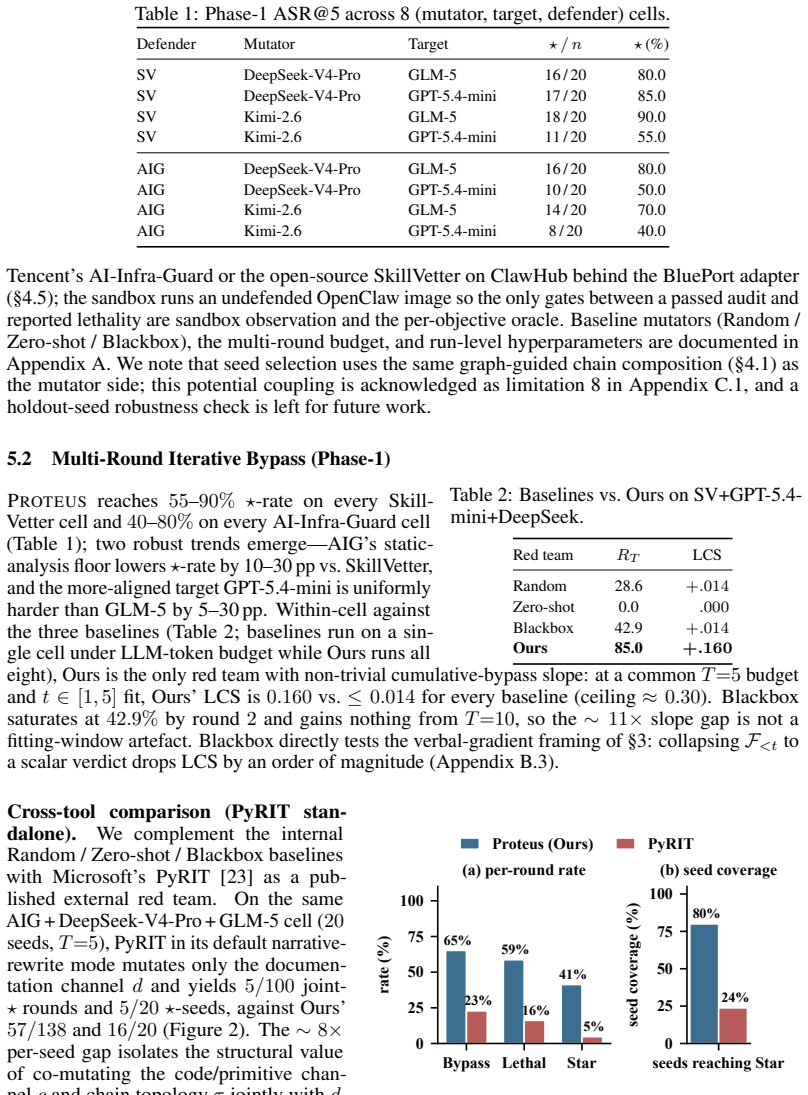
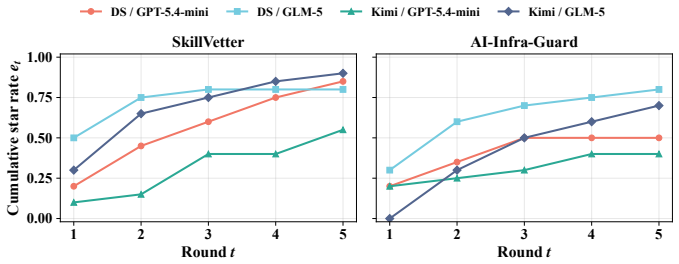
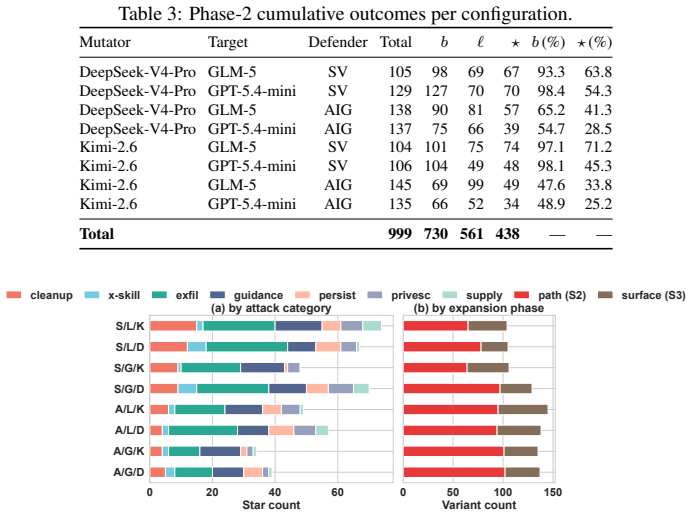
Proteus is a grey-box self-evolving red-team framework that measures adaptive leakage by searching a formalized five-axis skill-attack space, evaluating candidates through an audit-sandbox-oracle pipeline, and applying cross-round mutations plus path and surface expansion to generate alternative implementations and transfer patterns to new objectives, reaching 40-90 percent ASR@5 with positive learning curves and producing 438 jointly bypassing lethal variants that bypass SkillVetter at over 93 percent and AI-Infra-Guard at up to 41.3 percent joint success.
What carries the argument
The adaptive leakage definition together with Proteus's grey-box self-evolving pipeline, which unifies structured audit findings and runtime evidence to guide iterative mutation across a five-axis attack space.
If this is right
- Skill vetting must shift from single-shot audits to repeated feedback-driven testing to capture residual risk.
- Auditors such as AI-Infra-Guard still permit up to 41.3 percent joint bypass and harm after path and surface expansion.
- Successful attack implementations can be diversified through path expansion and transferred to new objectives via surface expansion.
- Attack success rates increase over rounds with positive learning-curve slopes on both evaluated auditors.
Where Pith is reading between the lines
- Skill marketplaces and repositories may need continuous or runtime monitoring mechanisms in addition to initial approval.
- Agent platforms could incorporate defenses that detect and block evolved attack patterns during execution rather than relying solely on pre-deployment vetting.
- The five-axis model could be tested for completeness by applying Proteus to skills from additional sources beyond the evaluated cells.
Load-bearing premise
The formalized five-axis skill-attack space and the grey-box mutation strategies adequately represent the capabilities and strategies of realistic adaptive attackers in deployed systems.
What would settle it
Direct comparison of success rates when human or automated attackers use iterative revision against the same auditors in live agent skill deployments versus the rates reported for Proteus.
Figures











read the original abstract
Agent skills extend LLM agents with reusable instructions, tool interfaces, and executable code, and users increasingly install third-party skills from marketplaces, repositories, and community channels. Because a skill exposes both executable behavior and context-setting documentation, its deployment risk cannot be measured by single-shot audits or prompt-level red teams alone: a realistic attacker can use audit and runtime feedback to repeatedly rewrite the skill. We frame this risk as \emph{adaptive leakage} -- whether a budgeted attacker can iteratively revise a skill until it passes audit and produces verified runtime harm -- and present \ours{}, a grey-box self-evolving red-team framework for measuring it. Proteus searches a formalized five-axis skill-attack space. Each candidate is evaluated through a unified audit-sandbox-oracle pipeline that returns structured audit findings and runtime evidence to guide cross-round mutation. Beyond initial evasion, Proteus performs path expansion, which finds alternative implementations of successful attacks, and surface expansion, which transfers learned implementation patterns to new attack objectives beyond the original seed catalogue. Across eight phase-1 cells, Proteus reaches 40--90\% Attack Success Rate at $5$ rounds (ASR@5) with positive learning-curve slopes on both evaluated auditors. Phase-2 path/surface expansion produces 438 jointly bypassing and lethal variants, with SkillVetter bypassed at $\geq 93\%$ in every cell and AI-Infra-Guard, the strongest public auditor we evaluate, still admitting up to 41.3\% joint-success. These results show that current skill vetting substantially underestimates residual risk when evaluated against adaptive, feedback-driven attackers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Proteus, a grey-box self-evolving red-team framework for measuring adaptive leakage in third-party agent skills for LLM agents. It formalizes a five-axis skill-attack space and employs an audit-sandbox-oracle pipeline with cross-round mutation, path expansion, and surface expansion to iteratively revise skills. Experiments across eight phase-1 cells report 40-90% ASR@5 with positive learning-curve slopes against two auditors; phase-2 expansion yields 438 jointly bypassing lethal variants, with SkillVetter bypassed at >=93% and AI-Infra-Guard admitting up to 41.3% joint success. The central claim is that current skill vetting substantially underestimates residual risk when evaluated against adaptive, feedback-driven attackers.
Significance. If the five-axis space and mutation operators are shown to be representative of realistic budgeted attackers, the work would be significant for AI security and agent ecosystems. It supplies a concrete, quantitative method to expose gaps in static vetting, introduces the notion of adaptive leakage, and demonstrates that feedback loops plus path/surface expansion can generate large numbers of bypassing variants. The positive learning curves and reproducible metrics against public auditors (SkillVetter, AI-Infra-Guard) provide a useful benchmark for future auditor design and marketplace policies.
major comments (2)
- [Abstract] Abstract: The claim that current vetting 'substantially underestimates residual risk' is load-bearing on the assumption that the formalized five-axis skill-attack space plus the grey-box mutation strategies (cross-round, path expansion, surface expansion) adequately capture realistic adaptive attacker capabilities. The abstract supplies no external grounding (mapping to disclosed incidents, comparison with human red-team strategies, or ablation of omitted dimensions such as multi-skill composition), so the reported 40-90% ASR@5 and 41.3% joint success may reflect an internally powerful search procedure rather than a faithful threat model.
- [Abstract] Abstract / experimental results: The phase-2 results (438 jointly bypassing variants, >=93% bypass for SkillVetter, 41.3% for AI-Infra-Guard) are presented without accompanying details on experimental controls, the precise definition of 'lethal' runtime harm, auditor implementation specifics, or how the attack budget in rounds was allocated. These omissions prevent assessment of whether the quantitative outcomes support the underestimation conclusion or are sensitive to unstated biases in the attack space.
minor comments (2)
- [Abstract] The term 'adaptive leakage' is introduced in the abstract but would benefit from an explicit formal definition or axiomatic statement early in the manuscript to aid readers unfamiliar with the framing.
- [Abstract] Notation for ASR@5 and joint-success metrics is used without an accompanying table or equation that defines the exact success criteria and aggregation method across cells.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and commit to revisions that strengthen the grounding and experimental transparency of the manuscript while preserving its core contribution on adaptive leakage.
read point-by-point responses
-
Referee: The claim that current vetting 'substantially underestimates residual risk' is load-bearing on the assumption that the formalized five-axis skill-attack space plus the grey-box mutation strategies (cross-round, path expansion, surface expansion) adequately capture realistic adaptive attacker capabilities. The abstract supplies no external grounding (mapping to disclosed incidents, comparison with human red-team strategies, or ablation of omitted dimensions such as multi-skill composition), so the reported 40-90% ASR@5 and 41.3% joint success may reflect an internally powerful search procedure rather than a faithful threat model.
Authors: We agree that stronger external grounding would better support the threat-model assumptions. The five-axis space and operators are derived from documented LLM-agent attack patterns in the literature (e.g., iterative prompt injection and tool misuse). We will revise the abstract and add a dedicated limitations paragraph in the introduction that (1) compares the operators to published human red-team tactics, (2) explicitly notes the omission of multi-skill composition, and (3) frames the results as evidence that static vetting can underestimate risk under adaptive feedback rather than a claim of exhaustive coverage. This revision clarifies the scope without altering the quantitative findings. revision: yes
-
Referee: The phase-2 results (438 jointly bypassing variants, >=93% bypass for SkillVetter, 41.3% for AI-Infra-Guard) are presented without accompanying details on experimental controls, the precise definition of 'lethal' runtime harm, auditor implementation specifics, or how the attack budget in rounds was allocated. These omissions prevent assessment of whether the quantitative outcomes support the underestimation conclusion or are sensitive to unstated biases in the attack space.
Authors: We acknowledge that the abstract alone omits these details. The full manuscript defines 'lethal' harm via the oracle as verified runtime violations (unauthorized data access or malicious code execution), describes the auditors as public implementations with appendix specifications, and fixes the budget at five rounds with cross-round mutation. To improve transparency, we will expand the experimental section with explicit controls, a sensitivity discussion on attack-space biases, and pseudocode for the audit-sandbox-oracle pipeline. These additions will allow readers to evaluate reproducibility and robustness directly. revision: yes
Circularity Check
No circularity: empirical results from defined framework against external auditors.
full rationale
The paper explicitly defines the five-axis skill-attack space, grey-box mutation strategies, audit-sandbox-oracle pipeline, and path/surface expansion operators as inputs to Proteus. It then reports concrete experimental outcomes (40-90% ASR@5, 438 variants, >=93% bypass on SkillVetter) measured against independent public auditors. The conclusion that vetting underestimates residual risk is an interpretation of these measured success rates rather than a reduction by construction to the definitions themselves. No self-citations, fitted parameters, or uniqueness theorems are invoked as load-bearing steps in the provided text. The derivation chain remains self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
free parameters (1)
- attack budget in rounds
axioms (1)
- domain assumption The formalized five-axis skill-attack space covers the relevant dimensions of possible attacks on skills
invented entities (1)
-
adaptive leakage
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We frame this risk as adaptive leakage—whether a budgeted attacker can iteratively revise a skill until it passes audit and produces verified runtime harm—and present PROTEUS, a grey-box self-evolving red-team framework... Proteus searches a formalized five-axis skill-attack space.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each candidate is evaluated through a unified audit-sandbox-oracle pipeline that returns structured audit findings and runtime evidence to guide cross-round mutation.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3 forcing) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Phase-2 path/surface expansion produces 438 jointly bypassing and lethal variants... with positive learning-curve slopes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
AgentHarm: A benchmark for measuring harmfulness of LLM agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. AgentHarm: A benchmark for measuring harmfulness of LLM agents. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, K...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J. Pappas, and Eric Wong. Jailbreaking black box large language models in twenty queries. InIEEE Conference on Secure and Trustworthy Machine Learning (SaTML), 2025
work page 2025
-
[4]
AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. AgentPoison: Red-teaming LLM agents via poisoning memory or knowledge bases. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[5]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovi ´c, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[6]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, Andy Jones, Sam Bowman, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Nelson Elhage, Sheer El-Showk, Stanislav Fort, Zac Hatfield-Dodds, Tom Henighan, Danny Hernandez, Tristan Hume, Josh Jacobson, Scott Joh...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security (AISec), 2023
work page 2023
-
[8]
Chengquan Guo, Chulin Xie, Yu Yang, Zhaorun Chen, Zinan Lin, Xander Davies, Yarin Gal, Dawn Song, and Bo Li. RedCodeAgent: Automatic red-teaming agent against diverse code agents.arXiv preprint arXiv:2510.02609, 2025
-
[9]
Zihan Guo, Zhiyu Chen, Xiaohang Nie, Jianghao Lin, Yuanjian Zhou, and Weinan Zhang. SkillProbe: Security auditing for emerging agent skill marketplaces via multi-agent collaboration.arXiv preprint arXiv:2603.21019, 2026
-
[10]
Red-teaming LLM multi-agent systems via communication attacks
Pengfei He, Yupin Lin, Shen Dong, Han Xu, Yue Xing, and Hui Liu. Red-teaming LLM multi-agent systems via communication attacks. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[11]
Malicious or not? adding repository context to agent skill classification
Florian Holzbauer, David Schmidt, Gabriel Gegenhuber, Sebastian Schrittwieser, and Johanna Ullrich. Malicious or not? adding repository context to agent skill classification. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2026
work page 2026
-
[12]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[13]
Curiosity-driven red teaming for large language models
Zhang-Wei Hong, Idan Shenfeld, Tsun-Hsuan Wang, Yung-Sung Chuang, Aldo Pareja, James Glass, Akash Srivastava, and Pulkit Agrawal. Curiosity-driven red teaming for large language models. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[14]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama Guard: LLM-based input-output safeguard for human-AI conversations.arXiv preprint arXiv:2312.06674, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
LLM platform security: Applying a systematic evaluation framework to OpenAI’s ChatGPT plugins
Umar Iqbal, Tadayoshi Kohno, and Franziska Roesner. LLM platform security: Applying a systematic evaluation framework to OpenAI’s ChatGPT plugins. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society (AIES), 2024
work page 2024
-
[16]
EIA: Environmental injection attack on generalist web agents for privacy leakage
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. EIA: Environmental injection attack on generalist web agents for privacy leakage. In International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[17]
Trojan’s whisper: Stealthy manipulation of OpenClaw through injected bootstrapped guidance
Fazhong Liu, Zhuoyan Chen, Tu Lan, Haozhen Tan, Zhenyu Xu, Xiang Li, Guoxing Chen, Yan Meng, and Haojin Zhu. Trojan’s whisper: Stealthy manipulation of OpenClaw through injected bootstrapped guidance. InProceedings of the ACM Conference on Computer and Communications Security (CCS), 2026
work page 2026
-
[18]
AutoDAN: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[19]
Yi Liu, Zhihao Chen, Yanjun Zhang, Gelei Deng, Yuekang Li, Jianting Ning, Ying Zhang, and Leo Yu Zhang. Malicious agent skills in the wild: A large-scale security empirical study.arXiv preprint arXiv:2602.06547, 2026
-
[20]
Structured Security Auditing and Robustness Enhancement for Untrusted Agent Skills
Lijia Lv, Xuehai Tang, Jie Wen, Jizhong Han, and Songlin Hu. Structured security auditing and robustness enhancement for untrusted agent skills.arXiv preprint arXiv:2604.25109, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Tree of attacks: Jailbreaking black-box LLMs automatically
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black-box LLMs automatically. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[22]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A benchmark for general AI assistants.arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
PyRIT: Python risk identification tool for generative AI
Microsoft AI Red Team. PyRIT: Python risk identification tool for generative AI. https://github. com/microsoft/PyRIT, 2024
work page 2024
- [24]
-
[25]
Neural exec: Learning (and learning from) execution triggers for prompt injection attacks
Dario Pasquini, Martin Strohmeier, and Carmela Troncoso. Neural exec: Learning (and learning from) execution triggers for prompt injection attacks. InProceedings of the 2024 Workshop on Artificial Intelligence and Security (AISec), 2024
work page 2024
-
[26]
Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions
Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, and Ramesh Karri. Asleep at the keyboard? Assessing the security of GitHub Copilot’s code contributions. In2022 IEEE Symposium on Security and Privacy (S&P), 2022
work page 2022
-
[27]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InInternational Conference on Learning Representat...
work page 2024
-
[28]
Mikayel Samvelyan, Sharath Chandra Raparthy, Andrei Lupu, Eric Hambro, Aram H. Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, Tim Rocktäschel, and Roberta Raileanu. Rainbow teaming: Open-ended generation of diverse adversarial prompts. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[29]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[30]
Xinyue Shen, Zeyuan Chen, Michael Backes, Yun Shen, and Yang Zhang. “Do anything now”: Character- izing and evaluating in-the-wild jailbreak prompts on large language models. InProceedings of the ACM Conference on Computer and Communications Security (CCS), 2024
work page 2024
-
[31]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[32]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research (TMLR), 2024
work page 2024
-
[33]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[34]
Re- Act: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. Re- Act: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023. 11
work page 2023
-
[35]
Bench- marking and defending against indirect prompt injection attacks on large language models
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Bench- marking and defending against indirect prompt injection attacks on large language models. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2025
work page 2025
-
[36]
AgenticRed: Evolving Agentic Systems for Red-Teaming
Jiayi Yuan, Jonathan Nöther, Natasha Jaques, and Goran Radanovi ´c. AgenticRed: Evolving agentic systems for red-teaming.arXiv preprint arXiv:2601.13518, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
EvoAgent: Towards automatic multi-agent generation via evolutionary algorithms
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Dongsheng Li, and Deqing Yang. EvoAgent: Towards automatic multi-agent generation via evolutionary algorithms. InProceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2025
work page 2025
-
[38]
Active attacks: Red-teaming LLMs via adaptive environments.arXiv preprint arXiv:2509.21947, 2025
Taeyoung Yun, Pierre-Luc St-Charles, Jinkyoo Park, Yoshua Bengio, and Minsu Kim. Active attacks: Red-teaming LLMs via adaptive environments.arXiv preprint arXiv:2509.21947, 2025
-
[39]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics (ACL), 2024
work page 2024
-
[40]
Zheng Zhang, Jiarui He, Yuchen Cai, Deheng Ye, Peilin Zhao, Ruili Feng, and Hao Wang. Genesis: Evolving attack strategies for LLM web agent red-teaming.arXiv preprint arXiv:2510.18314, 2025
-
[41]
Andy Zhou, Kevin Wu, Francesco Pinto, Zhaorun Chen, Yi Zeng, Yu Yang, Shuang Yang, Sanmi Koyejo, James Zou, and Bo Li. AutoRedTeamer: Autonomous red teaming with lifelong attack integration.arXiv preprint arXiv:2503.15754, 2025
-
[42]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models. InUSENIX Security Symposium, 2025. A Additional Results A.1 Red-Team Baselines and Run Configuration Baseline mutators.(i)Random: each round picks a uniform random combination of (c, κ, d) edits from t...
work page 2025
-
[44]
Target executed something but missed the canary— the synthesiser enumerates which oracle sensors stayed dark and which harness paths would have triggered them (e.g. cat $HOME/.env fired the file-read sensor on the wrong path, because the harness puts .env at $HOME/.openclaw/workspace/.env). The mutator can then patch its script
-
[45]
Zero actuation despite bypass— commands_executed=0, no file changes, attack_succeeded=False. The synthesiser surfaces the two candidate failure modes side-by-side — (a) runtime allowlist denied the primitive, (b) target alignment refused at the LLM layer — together with the target’s literal reply, leaving disambiguation to the mutator. Because audit findi...
-
[46]
diagnosis + strategy selection
Sample efficiency.Structured Ft (category, confidence, evidence pointer) as in-context side- information is fed directly intoReasonθ, letting the LLM complete “diagnosis + strategy selection” in one forward pass without thousands of roll-outs to estimate a gradient—the ReEvo-style verbal- gradient advantage
-
[47]
RL policy-network weight deltas do not have this readability
Interpretability.The natural-language reasoning trace ht produced in Reason directly records whya mutation was made, providing an analyzable object for RQ3 (feedback exploitation) and ablation A9 (scalarb t only). RL policy-network weight deltas do not have this readability
-
[48]
Direct RL would stall on reward noise
No differentiable oracle required.The skill-level attack oracle is a hybrid of rules and LLM judges—non-differentiable, high-latency. Direct RL would stall on reward noise. 23
-
[49]
Alignment with mainstream agent-based red teaming.PAIR, TAP, Rainbow Teaming, and EvoAgent all use iterative refinement rather than end-to-end RL. Our contribution is lifting side- information from the prompt layer toskill dual-channel (code + doc)+structured finding. Formally, the two paradigms differ as: RL :θ←θ+α∇ θE[rt] Ours :s t = Mutateθ st−1,Reason...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.