Recognition: no theorem link
Missing Old Logits in Asynchronous Agentic RL: Semantic Mismatch and Repair Methods for Off-Policy Correction
Pith reviewed 2026-05-13 05:55 UTC · model grok-4.3
The pith
Asynchronous RL pipelines for LLM agents lose historical training logits, entangling discrepancy repair with staleness correction and breaking PPO off-policy semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
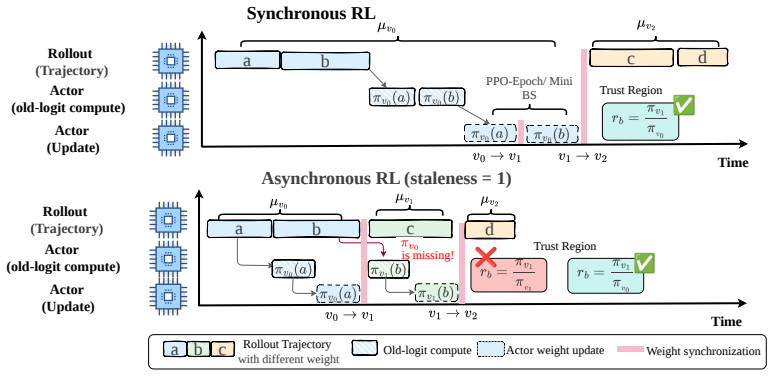
The central claim is that practical asynchronous pipelines with delayed updates and partial rollouts lose the historical training-side logits required for the intended decomposition of the total importance ratio into a training-inference discrepancy term and a policy-staleness term; this loss breaks the semantics of decoupled correction. Exact acquisition strategies restore the decomposition directly, while an approximate policy revision preserves its benefits without added overhead.
What carries the argument
Decomposition of the total importance ratio into a training-inference discrepancy term and a policy-staleness term, which requires historical training-side logits to stay separable under delayed and partial rollout conditions.
If this is right
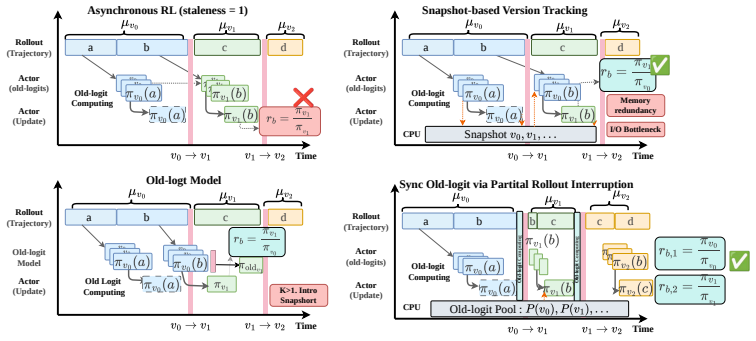
- Snapshot-based version tracking supplies exact old logits at the cost of memory for policy checkpoints.
- A dedicated old-logit model recovers the missing values without interrupting rollouts.
- Partial rollout interruption synchronizes logits exactly but reduces effective throughput.
- Revised PPO-EWMA approximates the missing term while retaining decoupled-correction advantages and zero extra system cost.
Where Pith is reading between the lines
- Version-tracking mechanisms may become standard infrastructure in any high-throughput async RL system to prevent silent degradation of off-policy signals.
- The approximate route could be applied to other importance-sampling algorithms that face similar delayed-logit problems.
- Varying the length of partial rollouts in experiments would quantify how delay severity scales the severity of the entanglement.
- Restoring the decomposition may allow tighter clipping ranges without stability loss, improving sample efficiency in agent training.
Load-bearing premise
The importance ratio remains cleanly separable into a discrepancy factor and a staleness factor even when updates are delayed and rollouts are partial.
What would settle it
A controlled comparison in an async PPO run that supplies old logits versus the same run that withholds them, checking whether the interaction between clipping thresholds and update stability disappears once the logits are restored.
Figures







read the original abstract
Asynchronous reinforcement learning improves rollout throughput for large language model agents by decoupling sample generation from policy optimization, but it also introduces a critical failure mode for PPO-style off-policy correction. In heterogeneous training systems, the total importance ratio should ideally be decomposed into two semantically distinct factors: a \emph{training--inference discrepancy term} that aligns inference-side and training-side distributions at the same behavior-policy version, and a \emph{policy-staleness term} that constrains the update from the historical policy to the current policy. We show that practical asynchronous pipelines with delayed updates and partial rollouts often lose the required historical training-side logits, or old logits. This missing-old-logit problem entangles discrepancy repair with staleness correction, breaks the intended semantics of decoupled correction, and makes clipping and masking thresholds interact undesirably. To address this issue, we study both exact and approximate correction routes. We propose three exact old-logit acquisition strategies: snapshot-based version tracking, a dedicated old-logit model, and synchronization via partial rollout interruption, and compare their system trade-offs. From the perspective of approximate correction, we focus on preserving the benefits of decoupled correction through a more appropriate approximate policy when exact old logits cannot be recovered at low cost, without incurring extra system overhead. Following this analysis, we adopt a revised PPO-EWMA method, which achieves significant gains in both training speed and optimization performance. Code at https://github.com/millioniron/ROLL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that asynchronous RL for LLM agents introduces a missing-old-logit problem in PPO-style off-policy correction: delayed updates and partial rollouts cause loss of historical training-side logits, entangling the training-inference discrepancy term with the policy-staleness term in the importance ratio, breaking decoupled correction semantics, and causing undesirable interactions between clipping and masking. The authors propose three exact old-logit acquisition strategies (snapshot-based version tracking, dedicated old-logit model, and synchronization via partial rollout interruption) plus a revised PPO-EWMA approximation, reporting significant gains in training speed and optimization performance.
Significance. If the repairs restore the intended semantic separation without new biases, the work addresses a practical bottleneck in scaling asynchronous RL for large language model agents. The GitHub code release is a strength that enables direct verification of the proposed methods and reported gains.
major comments (3)
- [Abstract and §2] The central claim that the total importance ratio factors cleanly into a training-inference discrepancy term and a separate policy-staleness term (abstract and §2) is load-bearing, yet the manuscript provides no derivation or proof that this factorization remains valid once partial rollouts mix tokens from different behavior-policy snapshots; the skeptic's concern that the factors become interdependent is not directly addressed.
- [§4] §4 (exact acquisition strategies): none of the three proposed strategies is shown, via analysis or controlled experiment, to restore the original semantic decomposition after entanglement has occurred under delayed updates and partial rollouts; the strategies are motivated from the mismatch but do not demonstrate that the repaired ratio recovers the intended decoupled form.
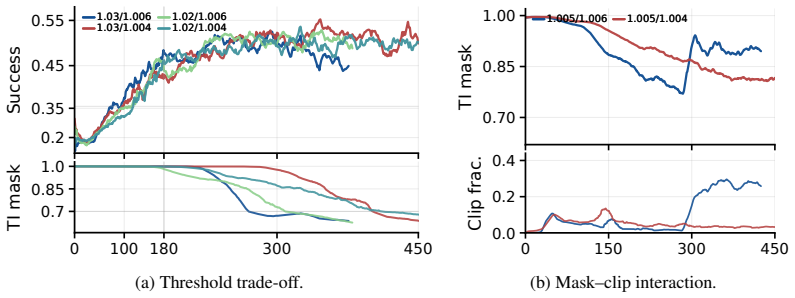
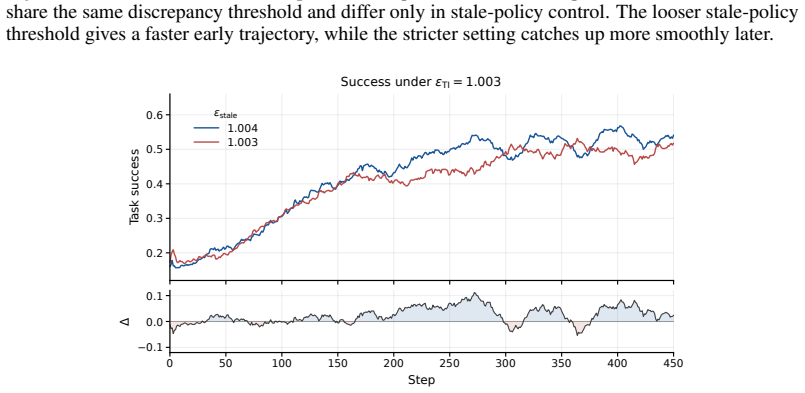
- [Results] Experimental evaluation (results section): the reported gains for the revised PPO-EWMA approximation lack ablations or controls that isolate whether the method preserves the decoupled-correction semantics versus simply altering the bias-variance tradeoff of the importance ratio.
minor comments (2)
- [Abstract] The abstract is dense; separating the problem diagnosis, the three exact strategies, and the approximate method into distinct sentences would improve readability.
- [§2] Notation for 'old logits' and the two importance-ratio factors is introduced without an early equation that explicitly defines them in terms of the behavior and target policies.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the formal grounding and empirical validation of our claims. We address each major point below and will revise the manuscript accordingly to incorporate explicit derivations, restoration demonstrations, and targeted ablations.
read point-by-point responses
-
Referee: [Abstract and §2] The central claim that the total importance ratio factors cleanly into a training-inference discrepancy term and a separate policy-staleness term (abstract and §2) is load-bearing, yet the manuscript provides no derivation or proof that this factorization remains valid once partial rollouts mix tokens from different behavior-policy snapshots; the skeptic's concern that the factors become interdependent is not directly addressed.
Authors: We agree that an explicit derivation is needed. In the revision we will add a formal proof in §2 establishing that, when old logits are available per token, the total importance ratio decomposes exactly as (training-inference discrepancy at fixed behavior-policy version) × (policy-staleness term). We will also show algebraically that mixing tokens from different snapshots without the corresponding old logits is precisely what entangles the two factors; restoring per-token old logits via any of the three strategies recovers the original factorization. This directly addresses the interdependence concern. revision: yes
-
Referee: [§4] §4 (exact acquisition strategies): none of the three proposed strategies is shown, via analysis or controlled experiment, to restore the original semantic decomposition after entanglement has occurred under delayed updates and partial rollouts; the strategies are motivated from the mismatch but do not demonstrate that the repaired ratio recovers the intended decoupled form.
Authors: We acknowledge the need for explicit verification. In the revised manuscript we will augment §4 with (i) a short mathematical argument that each acquisition method supplies the missing per-token old logits and thereby restores the decoupled decomposition, and (ii) a controlled experiment that computes the statistical dependence (e.g., correlation) between the discrepancy and staleness terms before and after each strategy, confirming that dependence drops to near zero post-repair. revision: yes
-
Referee: [Results] Experimental evaluation (results section): the reported gains for the revised PPO-EWMA approximation lack ablations or controls that isolate whether the method preserves the decoupled-correction semantics versus simply altering the bias-variance tradeoff of the importance ratio.
Authors: We will add the requested controls in the results section. Specifically, we will report the variance and bias of the importance-ratio estimator under the original PPO-EWMA versus the revised version, together with an ablation that measures how closely each version approximates the ideal decoupled correction (via a proxy that uses ground-truth old logits when available). These additions will clarify that the observed speed and performance gains arise from better semantic alignment rather than an incidental change in bias-variance tradeoff. revision: yes
Circularity Check
No significant circularity; analysis and proposals are independent of self-referential inputs
full rationale
The paper states an ideal decomposition of the importance ratio into discrepancy and staleness terms as a target semantic structure, identifies the missing-old-logit problem in async pipelines as a practical entanglement, and proposes three exact acquisition strategies plus a revised PPO-EWMA approximation. No equations or claims reduce the proposed corrections or the decomposition itself to fitted parameters, self-citations, or prior results by the same authors that would make the output equivalent to the input by construction. The central claims rest on system-level observation and engineering remedies rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The total importance ratio in PPO decomposes cleanly into a training-inference discrepancy term and a policy-staleness term
Reference graph
Works this paper leans on
-
[1]
Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce-style optimization for learning from human feedback in llms. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–12267, 2024
work page 2024
-
[2]
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms, 2024
work page 2024
-
[3]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Eval- uating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Agentic reinforced policy optimization
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, et al. Agentic reinforced policy optimization. arXiv preprint arXiv:2507.19849, 2025
-
[6]
Areal: A large-scale asynchronous reinforcement learning system for language reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, WANG JIASHU, et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[7]
RL-VLA$^3$: A Flexible and Asynchronous Reinforcement Learning Framework for VLA Training
Zhong Guan, Haoran Sun, Yongjian Guo, Shuai Di, Xiaodong Bai, Jing Long, Tianyun Zhao, Mingxi Luo, Chen Zhou, Yucheng Guo, et al. Rl-vla3: Reinforcement learning vla accelerating via full asynchronism.arXiv preprint arXiv:2602.05765, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, et al. Vitabench: Benchmarking llm agents with versatile interactive tasks in real-world applications.arXiv preprint arXiv:2509.26490, 2025
-
[9]
Batch size-invariance for policy optimization
Jacob Hilton, Karl Cobbe, and John Schulman. Batch size-invariance for policy optimization. Advances in Neural Information Processing Systems, 35:17086–17098, 2022
work page 2022
-
[10]
Stable asynchrony: Variance-controlled off-policy rl for llms.arXiv preprint arXiv:2602.17616, 2026
Luke J Huang, Zhuoyang Zhang, Qinghao Hu, Shang Yang, and Song Han. Stable asynchrony: Variance-controlled off-policy rl for llms.arXiv preprint arXiv:2602.17616, 2026
-
[11]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[12]
Xiaocan Li, Shiliang Wu, and Zheng Shen. A-3po: Accelerating asynchronous llm training with staleness-aware proximal policy approximation.arXiv preprint arXiv:2512.06547, 2025
-
[13]
When speed kills stability: Demystifying RL collapse from the training-inference mismatch
Jiacai Liu, Yingru Li, Yuqian Fu, Jiawei Wang, Qian Liu, and Zhuo Jiang. When speed kills stability: Demystifying RL collapse from the training-inference mismatch. https:// richardli.xyz/rl-collapse, September 2025. Online article. 10
work page 2025
-
[14]
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, and Fuli Luo. Stabilizing moe reinforcement learning by aligning training and inference routers.arXiv preprint arXiv:2510.11370, 2025
-
[15]
Rethinking the trust region in LLM reinforcement learning.arXiv preprint arXiv:2602.04879, 2026
Penghui Qi, Xiangxin Zhou, Zichen Liu, Tianyu Pang, Chao Du, Min Lin, and Wee Sun Lee. Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879, 2026
-
[16]
Nicolas Le Roux, Marc G Bellemare, Jonathan Lebensold, Arnaud Bergeron, Joshua Greaves, Alex Fréchette, Carolyne Pelletier, Eric Thibodeau-Laufer, Sándor Toth, and Sam Work. Tapered off-policy reinforce: Stable and efficient reinforcement learning for llms.arXiv preprint arXiv:2503.14286, 2025
-
[17]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training
Guobin Shen, Chenxiao Zhao, Xiang Cheng, Lei Huang, and Xing Yu. Vespo: Variational sequence-level soft policy optimization for stable off-policy llm training.arXiv preprint arXiv:2602.10693, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
arXiv preprint arXiv:2510.12633 , year=
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, et al. Laminar: A scalable asynchronous rl post-training framework.arXiv preprint arXiv:2510.12633, 2025
-
[21]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
work page 2025
-
[22]
Zhenpeng Su, Leiyu Pan, Xue Bai, Dening Liu, Guanting Dong, Jiaming Huang, Minxuan Lv, Wenping Hu, Fuzheng Zhang, Kun Gai, et al. Klear-reasoner: Advancing reasoning capability via gradient-preserving clipping policy optimization.arXiv preprint arXiv:2508.07629, 2025
-
[23]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
arXiv preprint arXiv:2510.18855 , year=
Ling Team, Anqi Shen, Baihui Li, Bin Hu, Bin Jing, Cai Chen, Chao Huang, Chao Zhang, Chaokun Yang, Cheng Lin, et al. Every step evolves: Scaling reinforcement learning for trillion-scale thinking model.arXiv preprint arXiv:2510.18855, 2025
-
[25]
Ernie 5.0 technical report.arXiv preprint arXiv:2602.04705, 2026
Haifeng Wang, Hua Wu, Tian Wu, Yu Sun, Jing Liu, Dianhai Yu, Yanjun Ma, Jingzhou He, Zhongjun He, Dou Hong, et al. Ernie 5.0 technical report.arXiv preprint arXiv:2602.04705, 2026
-
[26]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, et al. Reinforcement learning optimization for large- scale learning: An efficient and user-friendly scaling library.arXiv preprint arXiv:2506.06122, 2025
-
[27]
Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, Yancheng He, Ju Huang, Qiang Ji, Hanqi Jin, Xiaoyang Li, et al. Let it flow: Agentic crafting on rock and roll, building the rome model within an open agentic learning ecosystem.arXiv preprint arXiv:2512.24873, 2025
-
[28]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Your efficient rl framework secretly brings you off-policy rl training, August 2025
Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jianfeng Gao. Your efficient rl framework secretly brings you off-policy rl training, August 2025
work page 2025
-
[30]
Feng Yao, Liyuan Liu, Dinghuai Zhang, Chengyu Dong, Jingbo Shang, and Jianfeng Gao. Your efficient rl framework secretly brings you off-policy rl training, august 2025.URL https://fengyao. notion. site/off-policy-rl, 2025
work page 2025
-
[31]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. Glm-5: from vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhong-Zhi Li, Xiangyuan Xue, Yijiang Li, et al. The landscape of agentic reinforcement learning for llms: A survey.Transactions on Machine Learning Research, 2025
work page 2025
-
[34]
Small leak can sink a great ship–boost rl training on moe with icepop!, 2025
Xin Zhao, Yongkang Liu, Kuan Xu, Jia Guo, Zihao Wang, Yan Sun, Xinyu Kong, Qianggang Cao, Liang Jiang, Zujie Wen, et al. Small leak can sink a great ship–boost rl training on moe with icepop!, 2025
work page 2025
-
[35]
arXiv preprint arXiv:2512.01374 , year=
Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, et al. Stabilizing reinforcement learning with llms: Formulation and practices.arXiv preprint arXiv:2512.01374, 2025
-
[36]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Haizhong Zheng, Jiawei Zhao, and Beidi Chen. Prosperity before collapse: How far can off-policy rl reach with stale data on llms?arXiv preprint arXiv:2510.01161, 2025
-
[38]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37:62557–62583, 2024
work page 2024
-
[39]
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. slime: An llm post-training framework for rl scaling. https://github.com/THUDM/slime, 2025. GitHub repository. Corresponding author: Xin Lv. A Detailed Derivations for Interpolation-Based Proxies This appendix gives the derivation behind Proposition 1. We write the total ratio between the current t...
work page 2025
-
[40]
Therefore IRB approval is not applicable
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.