Recognition: no theorem link
NPAP: Network Partitioning and Aggregation Package for Python
Pith reviewed 2026-05-13 03:59 UTC · model grok-4.3
The pith
NPAP splits network graph reduction into separate partitioning and aggregation steps using a strategy pattern for custom methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
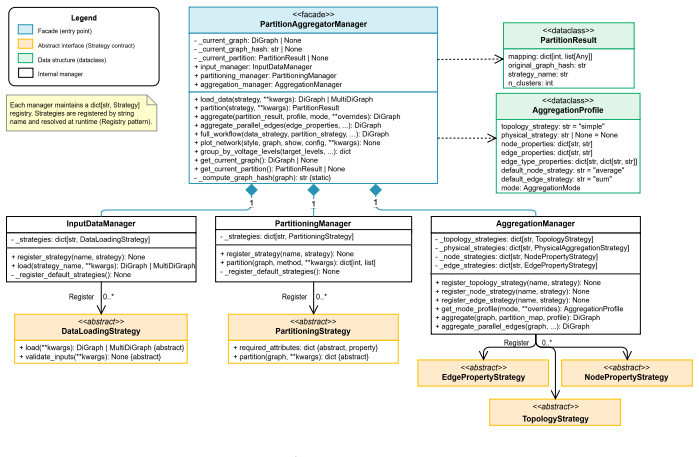
By treating spatial reduction as two sequential operations rather than one indivisible action, NPAP assigns vertices to clusters in a partitioning step and then contracts the graph according to that assignment in an aggregation step. The strategy pattern architecture registers custom partitioning and aggregation routines at runtime so that new methods integrate without code changes to the main package. This yields a standalone, readily embeddable library that currently includes thirteen partitioning strategies and two predefined aggregation profiles.
What carries the argument
The strategy pattern architecture that decouples partitioning (vertex-to-group assignment) from aggregation (graph reduction based on the assignment), allowing runtime registration of user-defined strategies.
If this is right
- Users can register new partitioning or aggregation strategies without modifying the library core.
- The same codebase works for power-system networks and for graphs from any other domain.
- Thirteen built-in partitioning strategies plus two aggregation profiles are immediately available for common use cases.
- The package integrates directly with existing NetworkX workflows and other Python frameworks.
- Spatial reduction becomes a configurable two-stage pipeline rather than a fixed black-box operation.
Where Pith is reading between the lines
- Researchers could test the effect of different partitioning choices on final aggregation accuracy by swapping strategies on the same input graph.
- The modular design might shorten the time needed to adapt network simplification pipelines in transportation or social-network studies.
- Because the steps are separate, hybrid workflows that combine one library's partitioning output with another's aggregation routine become straightforward.
- Extending the library to handle dynamic or time-varying networks would require changes only to the partitioning or aggregation modules rather than the entire pipeline.
Load-bearing premise
That splitting reduction into two steps plus supplying thirteen partitioning strategies and two aggregation profiles delivers practical value and seamless integration without meaningful overhead or accuracy loss versus existing single-action tools.
What would settle it
A side-by-side benchmark on the same large network showing that a custom strategy coded inside NPAP produces slower runtimes, larger final graphs, or higher downstream error than an equivalent monolithic reduction routine would demonstrate that the separation adds no practical benefit.
Figures

read the original abstract
NPAP (Network Partitioning and Aggregation Package) is an open-source Python library for reducing the spatial complexity of network graphs. Built on NetworkX, it provides an accessible standalone package designed to be readily integrated with other software and frameworks. Instead of treating the spatial reduction process as a single action, NPAP explicitly splits it into two distinct steps: partitioning, which assigns vertices (nodes) to groups (clusters), and aggregation, which reduces the network based on a given assignment. NPAP's strategy pattern architecture allows users to employ and register custom partitioning and aggregation strategies seamlessly without modifying the core code. Currently, NPAP provides 13 different partitioning strategies and two pre-defined aggregation profiles. Although initially developed with a focus on power systems, its architecture is general-purpose and applicable to any network graph.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents NPAP, an open-source Python library built on NetworkX for reducing the spatial complexity of network graphs. It explicitly separates the reduction process into two steps—partitioning (assigning vertices to groups) and aggregation (reducing the network based on a given assignment)—and employs a strategy pattern architecture to support seamless registration and use of custom strategies. The package currently includes 13 partitioning strategies and two pre-defined aggregation profiles; although developed with an initial focus on power systems, the design is described as general-purpose for any network graph.
Significance. If the described architecture is faithfully implemented, NPAP provides a modular, extensible framework for network coarsening that aligns with standard Python design patterns and could facilitate custom workflows in network analysis across domains. The open-source release, separation of partitioning from aggregation, and support for user-defined strategies via registration are clear strengths that promote reusability without core modifications.
minor comments (2)
- Abstract: the two aggregation profiles are mentioned but not described; adding one sentence on their differences (e.g., how they handle edge weights or supernode attributes) would improve clarity for readers evaluating applicability.
- The manuscript contains no code examples, installation instructions, or usage snippets; including a minimal working example of strategy registration and a call to the reduction pipeline would make the claimed 'seamless' integration concrete.
Simulated Author's Rebuttal
We thank the referee for their careful review of our manuscript on NPAP and for the positive assessment of its architecture, modularity, and potential utility. The recommendation for minor revision is noted. However, the report lists no specific major comments, so we have no points requiring direct response or revision at this stage. We remain available to address any minor comments or clarifications if provided in a subsequent round.
Circularity Check
No circularity: purely descriptive software package
full rationale
The manuscript is a software package announcement describing the design of NPAP, an open-source Python library built on NetworkX. It splits spatial reduction into partitioning and aggregation steps, uses a strategy pattern for extensibility, and lists 13 partitioning strategies plus two aggregation profiles. No equations, derivations, predictions, fitted parameters, or first-principles results are present. The architecture is presented as a standard implementation choice without any claimed mathematical results or load-bearing steps that could reduce to inputs by construction. The paper is self-contained as a descriptive account with no circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Voltage-Aware Grid Aggregation: Expanding the European High-Voltage Network
A voltage-aware network aggregation method preserves up to 70% of transformer expansion costs in aggregated European grid models compared to the full-resolution version.
Reference graph
Works this paper leans on
-
[1]
Brown, T., Hörsch, J., & Schlachtberger, D. (2018). PyPSA: Python for power system analysis. Journal of Open Research Software, 6(1), 4. https://doi.org/10.5334/jors.188
-
[2]
Campello, R. J. G. B., Moulavi, D., & Sander, J. (2013). Density-based clustering based on hierarchical density estimates. Advances in Knowledge Discovery and Data Mining, 160--172. https://doi.org/10.1007/978-3-642-37456-2_14
-
[3]
Colonetti, B. (2025). Ward reduction in unit-commitment problems. Electric Power Systems Research, 240, 111271. https://doi.org/10.1016/j.epsr.2024.111271
-
[4]
Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96), 226--231
work page 1996
-
[5]
Fortenbacher, P., Demiray, T., & Schaffner, C. (2018). Transmission network reduction method using nonlinear optimization. 2018 Power Systems Computation Conference (PSCC), 1--7. https://doi.org/10.23919/pscc.2018.8442974
-
[6]
Frysztacki, M. M., Recht, G., & Brown, T. (2022). A comparison of clustering methods for the spatial reduction of renewable electricity optimisation models of europe. Energy Inform, 5(1), 4. https://doi.org/10.1186/s42162-022-00187-7
-
[7]
Hagberg, A. A., Schult, D. A., & Swart, P. J. (2008). Exploring network structure, dynamics, and function using NetworkX. In G. Varoquaux, T. Vaught, & J. Millman (Eds.), Proceedings of the 7th python in science conference (pp. 11--15)
work page 2008
-
[8]
Harris, C. R., Millman, K. J., Walt, S. J. van der, Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., Kerkwijk, M. H. van, Brett, M., Haldane, A., Río, J. F. del, Wiebe, M., Peterson, P., Oliphant, T. E. (2020). Array programming with NumPy. Nature, 585(7825), 357--362. https://doi.o...
-
[9]
Hoffmann, M., Kotzur, L., & Stolten, D. (2022). The pareto-optimal temporal aggregation of energy system models. Applied Energy, 315, 119029. https://doi.org/10.1016/j.apenergy.2022.119029
-
[10]
Hoffmann, M., Kotzur, L., Stolten, D., & Robinius, M. (2020). A review on time series aggregation methods for energy system models. Energies, 13(3), 641. https://doi.org/10.3390/en13030641
-
[11]
Hörsch, J., Hofmann, F., Schlachtberger, D., & Brown, T. (2018). PyPSA - Eur : An open optimisation model of the european transmission system. Energy Strategy Reviews, 22, 207--215. https://doi.org/10.1016/j.esr.2018.08.012
-
[12]
Inc., P. T. (2015). Collaborative data science. Plotly Technologies Inc. https://plot.ly
work page 2015
-
[13]
Klütz, T., Knosala, K., Behrens, J., Maier, R., Hoffmann, M., Pflugradt, N., & Stolten, D. (2025). ETHOS.FINE: A framework for integrated energy system assessment. Journal of Open Source Software, 10(105), 6274. https://doi.org/10.21105/joss.06274
-
[14]
Kotzur, L., Nolting, L., Hoffmann, M., Groß, T., Smolenko, A., Priesmann, J., Büsing, H., Beer, R., Kullmann, F., Singh, B., Praktiknjo, A., Stolten, D., & Robinius, M. (2021). A modeler's guide to handle complexity in energy systems optimization. Advances in Applied Energy, 4, 100063. https://doi.org/10.1016/j.adapen.2021.100063
-
[15]
Lloyd, S. P. (1982). Least squares quantization in PCM. IEEE Transactions on Information Theory, 28(2), 129--137. https://doi.org/10.1109/TIT.1982.1056489
-
[16]
Patil, S., Kotzur, L., & Stolten, D. (2022). Advanced spatial and technological aggregation scheme for energy system models. Energies, 15(24), 9517. https://doi.org/10.3390/en15249517
-
[17]
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-learn: Machine learning in P ython. Journal of Machine Learning Research, 12, 2825--2830
work page 2011
-
[18]
Schubert, E., & Rousseeuw, P. J. (2021). Fast and eager k-medoids clustering: O(k) runtime improvement of the PAM, CLARA, and CLARANS algorithms. Information Systems, 101, 101804. https://doi.org/10.1016/j.is.2021.101804
-
[19]
Stöckl, B., Werner, Y., & Wogrin, S. (2025). Congestion-sensitive grid aggregation for DC optimal power flow. 2025 IEEE Kiel PowerTech, 1--7. https://doi.org/10.1109/powertech59965.2025.11180585
-
[20]
Teichgraeber, H., & Brandt, A. R. (2022). Time-series aggregation for the optimization of energy systems: Goals, challenges, approaches, and opportunities. Renewable and Sustainable Energy Reviews, 157, 111984. https://doi.org/10.1016/j.rser.2021.111984
-
[21]
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., Walt, S. J. van der, Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Vázquez-Baeza, Y. (2020). SciPy 1.0: Fundamental algorithms for scientific computing in pyth...
-
[22]
Ward Jr, J. H. (1963). Hierarchical grouping to optimize an objective function. Journal of the American Statistical Association, 58(301), 236--244. https://doi.org/10.1080/01621459.1963.10500845
-
[23]
Wogrin, S. (2023). Time series aggregation for optimization: One-size-fits-all? IEEE Transactions on Smart Grid, 14(3), 2489--2492. https://doi.org/10.1109/TSG.2023.3242467
-
[24]
Wood, A. J., Wollenberg, B. F., & Sheblé, G. B. (2012). Power generation, operation, and control (3rd ed.). John Wiley & Sons
work page 2012
-
[25]
Xiong, B., Fioriti, D., Neumann, F., Riepin, I., & Brown, T. (2025). Modelling the high-voltage grid using open data for europe and beyond. Scientific Data, 12, 277. https://doi.org/10.1038/s41597-025-04550-7 CSLReferences document
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.