Recognition: no theorem link
RED-2400: A Public Benchmark of Algorithmically-Rejected Trading Events with Outcome Labels
Pith reviewed 2026-05-13 03:31 UTC · model grok-4.3
The pith
RED-2400 supplies labeled data on 6,659 algorithmically rejected trades to test filter precision on the reject side.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
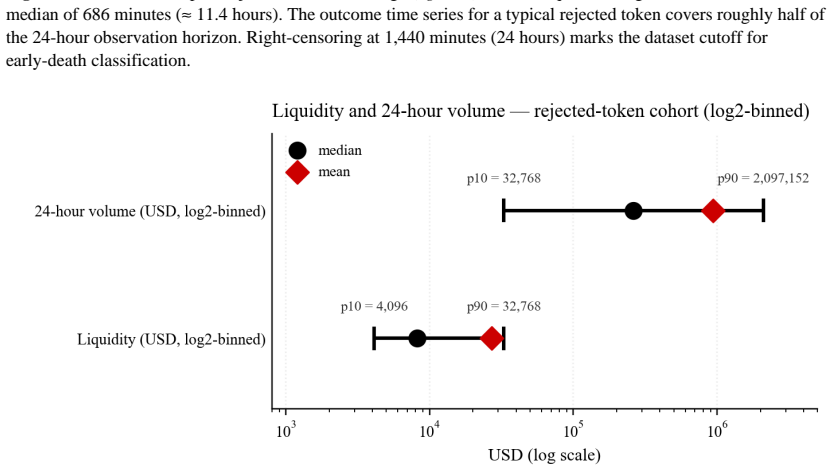
RED-2400 is a public benchmark of algorithmically-rejected trading events from a live Solana decentralized-exchange filter stack, containing 6,659 rejection events linked to 169,122 post-rejection price and liquidity observations and 1,836 graveyard-tracker snapshots, with outcome labels in five tiers: saved (windowed), saved (early-death), missed, flat, and unclassifiable, using thresholds from trough-to-reference and peak-to-reference price ratios within a 24-hour window.
What carries the argument
The five-tier outcome classification system based on 24-hour trough-to-reference and peak-to-reference price ratios, which assigns each rejection to saved (windowed), saved (early-death), missed, flat, or unclassifiable.
If this is right
- Filter designers can now measure how often rejections lead to missed gains or unnecessary blocks.
- Validation of trading algorithms can include both accept and reject performance without bias.
- Subsequent dataset windows will support analysis stratified by market regimes.
- Researchers can replicate filter-precision claims using the provided linked observations.
Where Pith is reading between the lines
- Improved filter designs could emerge from identifying patterns in the missed or flat rejection outcomes.
- This benchmark may encourage similar public datasets for other exchanges and time periods.
- Combining this reject data with accept-side datasets could yield a more complete picture of overall filter effectiveness.
Load-bearing premise
The five-tier labels derived from 24-hour price ratios accurately capture the true impact of each rejection and the logged events represent the filter's typical behavior.
What would settle it
Finding that the outcome labels do not predict actual trading results after rejections or that the dataset events are not representative of the filter's decisions over time.
Figures

read the original abstract
RED-2400 is a public benchmark of algorithmically-rejected trading events from a live Solana decentralized-exchange filter stack. I logged the data continuously between 2026-04-10 and 2026-05-02. The benchmark contains 6,659 rejection events linked to 169,122 post-rejection price and liquidity observations and 1,836 graveyard-tracker snapshots. Outcome labels follow the five-tier classification of Kamat (2026c): saved (windowed), saved (early-death), missed, flat, and unclassifiable. Thresholds use the trough-to-reference and peak-to-reference price ratios within a 24-hour window. Most filter-design datasets cover the accept side only. That gap leaves reject-side outcomes unmeasured and biases filter validation. RED-2400 lets researchers replicate filter-precision claims directly. RED-2400 is the first window in a planned dataset series; subsequent windows will extend the time horizon and enable regime-stratified analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RED-2400, a public benchmark of 6,659 algorithmically-rejected trading events logged from a live Solana DEX filter stack between 2026-04-10 and 2026-05-02. It includes 169,122 post-rejection price/liquidity observations and 1,836 graveyard-tracker snapshots, with events labeled into five tiers (saved windowed, saved early-death, missed, flat, unclassifiable) via 24-hour trough-to-reference and peak-to-reference price ratios following Kamat (2026c). The central claim is that existing filter-design datasets cover only the accept side, leaving reject-side outcomes unmeasured and biasing validation; RED-2400 fills this gap by enabling direct replication of filter-precision claims and is the first in a planned series for extended temporal and regime-stratified analysis.
Significance. If the logged events are representative and the five-tier labels validly proxy rejection outcomes, the benchmark would provide a novel public resource for evaluating the reject side of algorithmic trading filters on decentralized exchanges. This could reduce bias in precision assessments and support more reproducible validation of trading strategies. The public release of the dataset, linkage to post-event observations, and commitment to future windows are explicit strengths that enhance its utility for the q-fin.TR community.
major comments (2)
- [Abstract and Data Collection section] Abstract and Data Collection section: The manuscript states the collection period, event counts (6,659 rejections), and observation totals but supplies no description of the filter-stack implementation, logging procedures, data-validation steps, or error rates. This is load-bearing for the central claim that the benchmark enables unbiased replication of precision checks, as the representativeness of the logged rejection events cannot be assessed without these details.
- [Outcome Labels section] Outcome Labels section: The five-tier scheme derives labels solely from 24-hour trough-to-reference and peak-to-reference price ratios without incorporating fees, slippage, position sizing, liquidity decay, or any counterfactual PnL on acceptance. In Solana DEX data, where external factors can drive post-rejection price action, this risks systematic misclassification of 'saved' versus 'missed' events and undermines the claim that the labels accurately measure rejection impact.
minor comments (3)
- [Abstract] The term 'graveyard-tracker snapshots' is introduced without a definition or reference to its implementation, which reduces clarity for readers outside the immediate context.
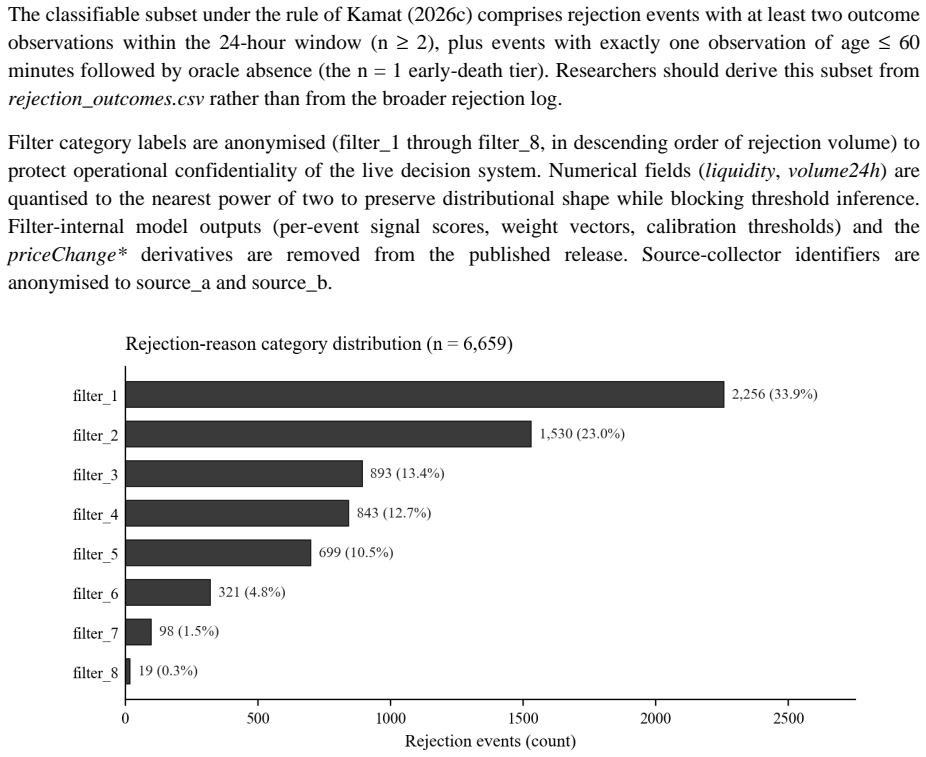
- The manuscript could include a table summarizing the distribution of the five label tiers across the 6,659 events to aid immediate assessment of class balance.
- [Outcome Labels section] The self-reference to Kamat (2026c) for the exact classification thresholds would benefit from a brief inline summary or appendix excerpt to improve standalone reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on RED-2400. We address each major comment below and commit to revisions that improve documentation and clarify scope without altering the benchmark's core contribution of providing reject-side labels.
read point-by-point responses
-
Referee: [Abstract and Data Collection section] Abstract and Data Collection section: The manuscript states the collection period, event counts (6,659 rejections), and observation totals but supplies no description of the filter-stack implementation, logging procedures, data-validation steps, or error rates. This is load-bearing for the central claim that the benchmark enables unbiased replication of precision checks, as the representativeness of the logged rejection events cannot be assessed without these details.
Authors: We agree that the Data Collection section lacks necessary detail on the filter-stack implementation, logging procedures, data-validation steps, and error rates. This information is required to evaluate representativeness. In the revised manuscript we will expand this section with a description of the filter logic, the logging pipeline from the Solana DEX, and validation steps performed on the collected events. Specific quantitative error rates for rejection detection were not computed during the original collection window; we will add an explicit statement of this limitation and indicate that such metrics will be included in subsequent dataset releases. revision: yes
-
Referee: [Outcome Labels section] Outcome Labels section: The five-tier scheme derives labels solely from 24-hour trough-to-reference and peak-to-reference price ratios without incorporating fees, slippage, position sizing, liquidity decay, or any counterfactual PnL on acceptance. In Solana DEX data, where external factors can drive post-rejection price action, this risks systematic misclassification of 'saved' versus 'missed' events and undermines the claim that the labels accurately measure rejection impact.
Authors: The five-tier labels are adopted verbatim from the methodology in Kamat (2026c) and function as a replicable price-ratio proxy rather than a full economic-impact calculation. We acknowledge that the scheme omits fees, slippage, position sizing, liquidity decay, and counterfactual PnL, which may produce misclassifications when external factors influence post-rejection price action on Solana DEX. We will revise the Outcome Labels section to state these limitations explicitly and to clarify that the tiers provide a standardized price-based proxy for rejection outcomes, not a net-PnL measure. This adjustment preserves the benchmark's intended use for replicating filter-precision claims while addressing the referee's concern. revision: partial
Circularity Check
Minor self-citation for label scheme; dataset release has no derivation chain
full rationale
This is a data-release paper whose central contribution is the public logging and release of 6,659 rejection events plus associated observations. No equations, fitted parameters, predictions, or uniqueness theorems are claimed. The sole self-reference is the adoption of the five-tier label taxonomy from Kamat (2026c) to annotate the released data; that taxonomy is not derived or validated inside the present manuscript and does not serve as a load-bearing premise for any result. The work is therefore self-contained against external benchmarks and receives only the minimal score for a routine self-citation that is not circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beygelzimer, A. and Langford, J. (2009). The offset tree for learning with partial labels. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD '09)
work page 2009
-
[2]
Crook, J. N. and Banasik, J. (2004). Does reject inference really improve the performance of application scoring models? Journal of Banking & Finance, 28(4): 857–874
work page 2004
-
[3]
Heckman, J. J. (1979). Sample selection bias as a specification error. Econometrica, 47(1): 153–161
work page 1979
-
[4]
Kamat, A. (2026c). Outcome-Classified Precision Auditing of Filter Rules in Algorithmic DEX Trading: Evidence from 2,400 Rejection Events. SSRN Working Paper, abstract_id 6638259. https://ssrn.com/abstract=6638259. Preprint mirror: Zenodo 10.5281/zenodo.19720041. Companion dataset: Zenodo 10.5281/zenodo.19987697. López de Prado, M. (2018). Advances in Fin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.