Recognition: 2 theorem links
· Lean TheoremSelf-Supervised Laplace Approximation for Bayesian Uncertainty Quantification
Pith reviewed 2026-05-13 04:44 UTC · model grok-4.3
The pith
Refitting models on their own predictions approximates the posterior predictive distribution directly and improves calibration over classical Laplace methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose to bypass the parameter posterior and focus directly on approximating the posterior predictive distribution by drawing inspiration from self-training. Essentially, we quantify a Bayesian model's predictive uncertainty by refitting on self-predicted data. If a model assigns high likelihood to self-predicted data, these predictions are of low uncertainty, and vice versa. This yields a deterministic, sampling-free approximation of the posterior predictive called Self-Supervised Laplace Approximation (SSLA). An approximate version (ASSLA) avoids expensive refitting. The method supports classical Bayesian sensitivity analysis via different priors and is studied in regression settings.
What carries the argument
Self-Supervised Laplace Approximation (SSLA), a procedure that refits the model on its own predictions treated as pseudo-data to quantify uncertainty in the posterior predictive distribution.
If this is right
- SSLA enables direct sensitivity analysis to prior choice without additional sampling.
- The method applies to both Bayesian linear models and Bayesian neural networks for regression.
- ASSLA provides a computationally cheaper alternative that still improves calibration over standard Laplace approximations.
- The approach remains deterministic and sampling-free across the studied tasks.
Where Pith is reading between the lines
- The self-supervised refitting idea could be tested for extending calibration gains to classification problems.
- If the initial model predictions are poor, the method may amplify errors rather than quantify uncertainty faithfully.
- Combining SSLA with other approximate inference techniques might further reduce computational cost in large-scale settings.
Load-bearing premise
That the model's initial predictions are reliable enough to serve as pseudo-labels whose likelihood under refitting accurately reflects true predictive uncertainty.
What would settle it
A dataset where SSLA or ASSLA predictive intervals show substantially worse calibration metrics (such as coverage or expected calibration error) than classical Laplace approximations on the same models.
Figures
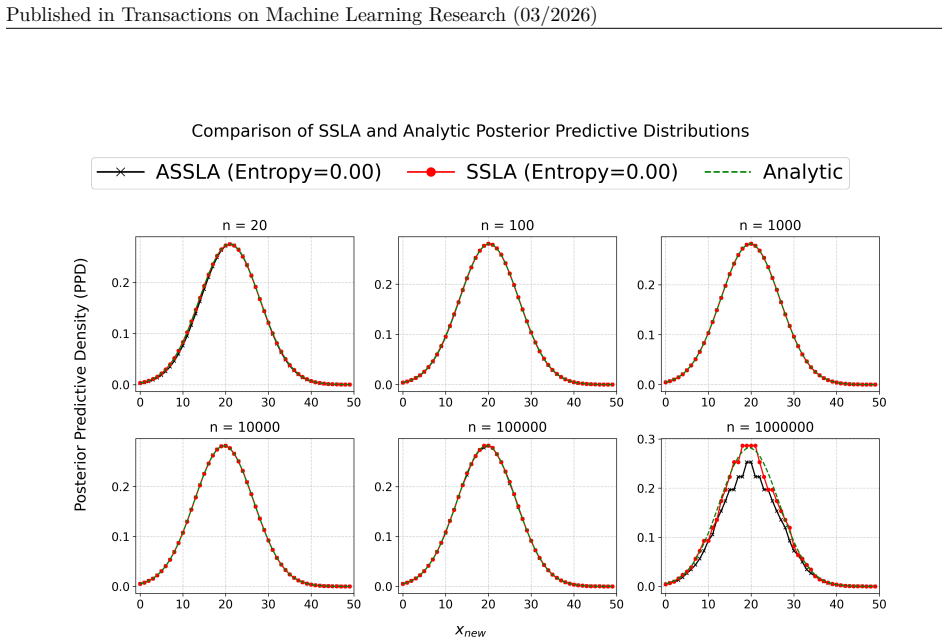


read the original abstract
Approximate Bayesian inference typically revolves around computing the posterior parameter distribution. In practice, however, the main object of interest is often a model's predictions rather than its parameters. In this work, we propose to bypass the parameter posterior and focus directly on approximating the posterior predictive distribution. We achieve this by drawing inspiration from self-training within self-supervised and semi-supervised learning. Essentially, we quantify a Bayesian model's predictive uncertainty by refitting on self-predicted data. The idea is strikingly simple: If a model assigns high likelihood to self-predicted data, these predictions are of low uncertainty, and vice versa. This yields a deterministic, sampling-free approximation of the posterior predictive. The modular structure of our Self-Supervised Laplace Approximation (SSLA) further allows us to plug in different prior specifications, enabling classical Bayesian sensitivity (w.r.t. prior choice) analysis. In order to bypass expensive refitting, we further introduce an approximate version of SSLA, called ASSLA. We study (A)SSLA both theoretically and empirically in regression models ranging from Bayesian linear models to Bayesian neural networks. Across a wide array of regression tasks with simulated and real-world datasets, our methods outperform classical Laplace approximations in predictive calibration while remaining computationally efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Self-Supervised Laplace Approximation (SSLA) to directly approximate the posterior predictive distribution p(y*|x*,D) in Bayesian regression models by refitting on self-generated pseudo-labels from the initial model predictions, inspired by self-training. An approximate variant ASSLA is introduced to avoid full refitting. The approach is analyzed theoretically and evaluated empirically on regression tasks ranging from Bayesian linear models to neural networks, with claims of improved predictive calibration over classical Laplace approximations while remaining computationally efficient and modular for prior sensitivity analysis.
Significance. If the central approximation holds with controlled bias, SSLA provides a simple, deterministic, sampling-free method for predictive uncertainty quantification that shifts focus from parameter posteriors to predictions. This could be useful for scalable Bayesian deep learning applications, and the modular prior plug-in enables straightforward sensitivity checks not always available in other approximations.
major comments (2)
- [§3] §3 (Method): The core construction refits the model (or its Laplace approximation) using the initial MAP predictions as targets to obtain a curvature or likelihood-based uncertainty measure. This step is load-bearing for the claim of approximating the posterior predictive, yet the paper provides no quantitative bound on the approximation error when the initial predictions deviate from the true conditional (e.g., under misspecification or high noise). A concrete error analysis or counterexample regime is required.
- [§5] §5 (Experiments): The abstract states outperformance in predictive calibration across simulated and real-world regression datasets, but the experimental design details (baselines, number of runs, error bars, statistical tests, and handling of self-prediction bias) are not summarized here; without these, the empirical support for the central claim cannot be fully assessed.
minor comments (2)
- [§3] Notation for the self-supervised loss and the resulting approximate predictive variance should be introduced with explicit equations early in §3 to improve readability.
- [Abstract] Clarify in the abstract and introduction whether ASSLA is a first-order approximation to SSLA or an independent method; the current wording leaves this ambiguous.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing the strongest honest defense of the manuscript while indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (Method): The core construction refits the model (or its Laplace approximation) using the initial MAP predictions as targets to obtain a curvature or likelihood-based uncertainty measure. This step is load-bearing for the claim of approximating the posterior predictive, yet the paper provides no quantitative bound on the approximation error when the initial predictions deviate from the true conditional (e.g., under misspecification or high noise). A concrete error analysis or counterexample regime is required.
Authors: We acknowledge that the current manuscript does not provide a general quantitative bound on the approximation error for arbitrary misspecification or high noise. The theoretical analysis in §3 characterizes SSLA for the linear Gaussian case, where it recovers the exact posterior predictive distribution, and motivates the approach more generally via the self-supervised refitting construction. In the revised version we will add a new paragraph to §3 that derives a simple error bound in terms of the L2 deviation between the initial MAP predictions and the true conditional mean (under standard Lipschitz assumptions on the model), together with a concrete counterexample in a high-noise linear regression regime that illustrates when the bias becomes noticeable. This directly supplies the requested error analysis while preserving the modular and sampling-free nature of the method. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract states outperformance in predictive calibration across simulated and real-world regression datasets, but the experimental design details (baselines, number of runs, error bars, statistical tests, and handling of self-prediction bias) are not summarized here; without these, the empirical support for the central claim cannot be fully assessed.
Authors: The abstract is necessarily brief and therefore omits experimental protocol details, but §5 of the manuscript fully specifies the baselines (classical Laplace, variational inference, and ensembles), the number of independent runs with reported variability, the calibration metrics and statistical tests employed, and the handling of self-prediction bias via training-only pseudo-label generation and strict held-out evaluation. To make these elements immediately accessible, we will insert a short “Experimental Protocol” paragraph at the beginning of §5 and add a one-sentence summary of the evaluation setup to the abstract. We believe this change will allow the empirical claims to be assessed without altering the reported results. revision: yes
Circularity Check
No significant circularity in the proposed approximation
full rationale
The paper proposes SSLA as a heuristic approximation to the posterior predictive distribution by refitting a Laplace approximation on self-generated pseudo-labels drawn from the initial model's point predictions. This construction is explicitly presented as an approximation technique inspired by self-training, not as a first-principles derivation whose output is definitionally identical to its input. The central claim (improved predictive calibration over classical Laplace) is evaluated empirically across simulated and real regression datasets and is therefore falsifiable against external benchmarks. No equations or steps in the provided abstract reduce the uncertainty measure to a tautological fit on the same quantities by construction, nor does the argument rest on load-bearing self-citations or imported uniqueness theorems. The acknowledged modeling assumption (initial predictions are sufficiently reliable pseudo-labels) is stated as such rather than smuggled in as a proven result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Laplace approximation provides a valid local Gaussian fit to the posterior
- ad hoc to paper Self-predicted data likelihood reliably indicates predictive uncertainty
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearlogp(ˆyn+1|xn+1,D)≈˜ℓ(˜θ)−ℓ(ˆθ)+logπ(˜θ)−logπ(ˆθ)−½log|˜J(˜θ)|+½log|J(ˆθ)| (eq. 12); ASSLA drops prior term via O(n⁻¹) expansion
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearrefitting on self-predicted data to quantify predictive uncertainty
Reference graph
Works this paper leans on
-
[1]
Optuna: A next- generation hyperparameter optimization framework,
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework, 2019. URL https://arxiv.org/abs/1907.10902
-
[2]
Adapting the linearised L aplace model evidence for modern deep learning
Javier Antoran, David Janz, James U Allingham, Erik Daxberger, Riccardo Rb Barbano, Eric Nalisnick, and Jose Miguel Hernandez-Lobato. Adapting the linearised L aplace model evidence for modern deep learning. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato (eds.), Proceedings of the 39th International Conferen...
work page 2022
-
[3]
Statistical multicriteria evaluation of llm-generated text
Esteban Garces Arias, Hannah Blocher, Julian Rodemann, Matthias A enmacher, and Christoph Jansen. Statistical multicriteria evaluation of llm-generated text. arXiv preprint arXiv:2506.18082, 2025 a
-
[4]
Towards better open-ended text generation: A multicriteria evaluation framework
Esteban Garces Arias, Hannah Blocher, Julian Rodemann, Meimingwei Li, Christian Heumann, and Matthias A enmacher. Towards better open-ended text generation: A multicriteria evaluation framework. In Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ), pp.\ 631--654, 2025 b
work page 2025
-
[5]
Arthur Asuncion, David Newman, et al. Liver Disorders . UCI Machine Learning Repository, 2016. DOI : https://doi.org/10.24432/C54G67
-
[6]
Coolen, Gert de Cooman, and Matthias C
Thomas Augustin, Frank P. Coolen, Gert de Cooman, and Matthias C. M. Troffaes (eds.). Introduction to Imprecise Probabilities. John Wiley, Chichester, 2014
work page 2014
-
[7]
Property elicitation on imprecise probabilities
James Bailie and Rabanus Derr. Property elicitation on imprecise probabilities. arXiv preprint arXiv:2507.05857 (last accessed October 27 2025), 2025
-
[8]
M. J. Beal. Variational Algorithms for Approximate B ayesian Inference . PhD thesis, Gatsby Computational Neuroscience Unit, University College London, 2003
work page 2003
-
[9]
M. J. Beal and Z. Ghahramani. Variational algorithms for approximate B ayesian inference. In Proceedings of the 16th Conference on Uncertainty in Artificial Intelligence, 2000
work page 2000
-
[10]
Algorithms for hyper-parameter optimization
James Bergstra, R\' e mi Bardenet, Yoshua Bengio, and Bal\' a zs K\' e gl. Algorithms for hyper-parameter optimization. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K.Q. Weinberger (eds.), Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011. URL https://proceedings.neurips.cc/paper_files/paper/2011/fil...
work page 2011
-
[11]
A conceptual introduction to hamiltonian monte carlo, 2018
Michael Betancourt. A conceptual introduction to hamiltonian monte carlo, 2018. URL https://arxiv.org/abs/1701.02434
-
[12]
Pattern recognition and machine learning, volume 4, chapter 4.4.1
Christopher Bishop and Nasser Nasrabadi. Pattern recognition and machine learning, volume 4, chapter 4.4.1. Springer, 2006
work page 2006
-
[13]
Variational inference: A review for statisticians
David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians. Journal of the American Statistical Association, 112 0 (518): 0 859--877, 2017
work page 2017
-
[14]
C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra. Weight uncertainty in neural network. In Proceedings of the International Conference on Machine Learning, 2015
work page 2015
- [15]
-
[16]
Linearized L aplace inference in neural additive models
Kouroche Bouchiat, Alexander Immer, Hugo Y \`e che, and Vincent Fortuin. Linearized L aplace inference in neural additive models. In Fifth Symposium on Advances in Approximate B ayesian Inference , 2023
work page 2023
-
[17]
Thomas Brooks, D. Pope, and Michael Marcolini. Airfoil Self-Noise . UCI Machine Learning Repository, 1989. DOI : https://doi.org/10.24432/C5VW2C
-
[18]
Optimal transport for -contaminated credal sets: To the memory of Sayan Mukherjee , 2025
Michele Caprio. Optimal transport for -contaminated credal sets: To the memory of Sayan Mukherjee , 2025. URL https://arxiv.org/abs/2410.03267
-
[19]
Ergodic theorems for dynamic imprecise probability kinematics
Michele Caprio and Sayan Mukherjee. Ergodic theorems for dynamic imprecise probability kinematics. International Journal of Approximate Reasoning, 152: 0 325--343, 2023
work page 2023
-
[20]
Constriction for sets of probabilities
Michele Caprio and Teddy Seidenfeld. Constriction for sets of probabilities. In Enrique Miranda, Ignacio Montes, Erik Quaeghebeur, and Barbara Vantaggi (eds.), Proceedings of the Thirteenth International Symposium on Imprecise Probability: Theories and Applications, volume 215 of Proceedings of Machine Learning Research, pp.\ 84--95. PMLR, 11--14 Jul 2023...
work page 2023
-
[21]
Credal B ayesian deep learning
Michele Caprio, Souradeep Dutta, Kuk Jin Jang, Vivian Lin, Radoslav Ivanov, Oleg Sokolsky, and Insup Lee. Credal B ayesian deep learning. Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=4NHF9AC5ui
work page 2024
-
[22]
Conformalized credal regions for classification with ambiguous ground truth
Michele Caprio, David Stutz, Shuo Li, and Arnaud Doucet. Conformalized credal regions for classification with ambiguous ground truth. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=L7sQ8CW2FY
work page 2025
-
[23]
Olivier Chapelle, Bernhard Sch \"o lkopf, and Alexander Zien (eds.). Semi-supervised learning. MIT Press, 2006
work page 2006
-
[24]
Fsp- L aplace: Function-space priors for the L aplace approximation in B ayesian deep learning
Tristan Cinquin, Marvin Pf \"o rtner, Vincent Fortuin, Philipp Hennig, and Robert Bamler. Fsp- L aplace: Function-space priors for the L aplace approximation in B ayesian deep learning. Advances in Neural Information Processing Systems, 37: 0 13897--13926, 2024
work page 2024
-
[25]
hamiltorch: A pytorch-based library for hamiltonian monte carlo
Adam D Cobb. hamiltorch: A pytorch-based library for hamiltonian monte carlo. In Proceedings of Cyber-Physical Systems and Internet of Things Week 2023, pp.\ 114--115. 2023 a
work page 2023
-
[26]
hamiltorch: A pytorch-based library for Hamiltonian Monte Carlo
Adam D Cobb. hamiltorch: A pytorch-based library for Hamiltonian Monte Carlo . In Proceedings of Cyber-Physical Systems and Internet of Things Week 2023, CPS-IoT Week '23, pp.\ 114–115, New York, NY, USA, 2023 b . Association for Computing Machinery. ISBN 9798400700491. doi:10.1145/3576914.3587528. URL https://doi.org/10.1145/3576914.3587528
-
[27]
P. Cortez, A. Cerdeira, F. Almeida, T. Matos, and J. Reis. Wine Quality . UCI Machine Learning Repository, 2009. DOI : https://doi.org/10.24432/C56S3T
-
[28]
L aplace redux-effortless Bayesian deep learning
Erik Daxberger, Agustinus Kristiadi, Alexander Immer, Runa Eschenhagen, Matthias Bauer, and Philipp Hennig. L aplace redux-effortless Bayesian deep learning. Advances in Neural Information Processing Systems, 34: 0 20089--20103, 2021 a
work page 2021
-
[29]
B ayesian deep learning via subnetwork inference
Erik Daxberger, Eric Nalisnick, James U Allingham, Javier Antor \'a n, and Jos \'e Miguel Hern \'a ndez-Lobato. B ayesian deep learning via subnetwork inference. In International Conference on Machine Learning, pp.\ 2510--2521. PMLR, 2021 b
work page 2021
-
[30]
Decomposition of uncertainty in B ayesian deep learning for efficient and risk-sensitive learning
Stefan Depeweg, Jose-Miguel Hernandez-Lobato, Finale Doshi-Velez, and Steffen Udluft. Decomposition of uncertainty in B ayesian deep learning for efficient and risk-sensitive learning. In Jennifer Dy and Andreas Krause (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp.\ ...
work page 2018
-
[31]
Semi-supervised learning guided by the generalized Bayes rule under soft revision
Stefan Dietrich, Julian Rodemann, and Christoph Jansen. Semi-supervised learning guided by the generalized Bayes rule under soft revision. In International Conference on Soft Methods in Probability and Statistics, pp.\ 110--117. Springer, 2024
work page 2024
-
[32]
Distributionally robust statistical verification with imprecise neural networks
Souradeep Dutta, Michele Caprio, Vivian Lin, Matthew Cleaveland, Kuk Jin Jang, Ivan Ruchkin, Oleg Sokolsky, and Insup Lee. Distributionally robust statistical verification with imprecise neural networks. In Proceedings of the 28th ACM International Conference on Hybrid Systems: Computation and Control, HSCC '25, New York, NY, USA, 2025. Association for Co...
-
[33]
Kronecker-factored approximate curvature for modern neural network architectures
Runa Eschenhagen, Alexander Immer, Richard Turner, Frank Schneider, and Philipp Hennig. Kronecker-factored approximate curvature for modern neural network architectures. Advances in Neural Information Processing Systems, 36: 0 33624--33655, 2023
work page 2023
-
[34]
Checking for prior-data conflict
Michael Evans and Hadas Moshonov. Checking for prior-data conflict. B ayesian analysis , 1 0 (4): 0 893--914, 2006
work page 2006
-
[35]
Hadi Fanaee-T. Bike Sharing . UCI Machine Learning Repository, 2013. DOI : https://doi.org/10.24432/C5W894
-
[36]
R. P. Ferreira, Andréa Martiniano, Arthur Arruda Leal Ferreira, Aleister Ferreira, and R. Sassi. Daily Demand Forecasting Orders . UCI Machine Learning Repository, 2016. DOI : https://doi.org/10.24432/C5BC8T
-
[37]
Martingale posterior distributions
Edwin Fong, Chris Holmes, and Stephen G Walker. Martingale posterior distributions. Journal of the Royal Statistical Society Series B: Statistical Methodology, 85 0 (5): 0 1357--1391, 2023
work page 2023
-
[38]
Gauss-newton approximation to B ayesian learning
F Dan Foresee and Martin T Hagan. Gauss-newton approximation to B ayesian learning. In Proceedings of International Conference on Neural Networks (ICNN'97), volume 3, pp.\ 1930--1935. IEEE, 1997
work page 1930
-
[39]
Peter I. Frazier. A tutorial on B ayesian optimization, 2018. URL https://arxiv.org/abs/1807.02811
work page internal anchor Pith review arXiv 2018
-
[40]
Imprecise Probabilities in Machine Learning: Structure and Semantics
Christian Fröhlich. Imprecise Probabilities in Machine Learning: Structure and Semantics. PhD thesis, University of Tübingen, 2025
work page 2025
- [41]
-
[42]
Theoria motus corporum coelestium in sectionibus conicis solem ambientium, volume 7
Carl Friedrich Gau . Theoria motus corporum coelestium in sectionibus conicis solem ambientium, volume 7. FA Perthes, 1877
-
[43]
B ayesian Gaussian processes for regression and classification
Mark N Gibbs. B ayesian Gaussian processes for regression and classification . PhD thesis, Citeseer, 1998
work page 1998
- [44]
-
[45]
Probabilistic backpropagation for scalable learning of B ayesian neural networks
Jos \'e Miguel Hern \'a ndez-Lobato and Ryan Adams. Probabilistic backpropagation for scalable learning of B ayesian neural networks. In International conference on machine learning, pp.\ 1861--1869. PMLR, 2015
work page 2015
-
[46]
I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner. beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representations (ICLR), 2017
work page 2017
-
[47]
Fast predictive uncertainty for classification with B ayesian deep networks
Marius Hobbhahn, Agustinus Kristiadi, and Philipp Hennig. Fast predictive uncertainty for classification with B ayesian deep networks. In Uncertainty in Artificial Intelligence, pp.\ 822--832. PMLR, 2022
work page 2022
-
[48]
M. D. Hoffman and A. Gelman. The no-u-turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo . In Journal of Machine Learning Research, 2014
work page 2014
-
[49]
Scalable marginal likelihood estimation for model selection in deep learning, 2021 a
Alexander Immer, Matthias Bauer, Vincent Fortuin, Gunnar Rätsch, and Mohammad Emtiyaz Khan. Scalable marginal likelihood estimation for model selection in deep learning, 2021 a . URL https://arxiv.org/abs/2104.04975
-
[50]
Improving predictions of B ayesian neural nets via local linearization
Alexander Immer, Maciej Korzepa, and Matthias Bauer. Improving predictions of B ayesian neural nets via local linearization. In International conference on artificial intelligence and statistics, pp.\ 703--711. PMLR, 2021 b
work page 2021
-
[51]
Christoph Jansen. Contributions to the decision theoretic foundations of machine learning and robust statistics under weakly structured information. arXiv preprint arXiv:2501.10195, 2025
-
[52]
Statistical comparisons of classifiers by generalized stochastic dominance
Christoph Jansen, Malte Nalenz, Georg Schollmeyer, and Thomas Augustin. Statistical comparisons of classifiers by generalized stochastic dominance. arXiv preprint arXiv:2209.01857, 2022 a
-
[53]
Quantifying degrees of e-admissibility in decision making with imprecise probabilities
Christoph Jansen, Georg Schollmeyer, and Thomas Augustin. Quantifying degrees of e-admissibility in decision making with imprecise probabilities. In Reflections on the Foundations of Probability and Statistics: Essays in Honor of Teddy Seidenfeld, pp.\ 319--346. Springer, 2022 b
work page 2022
-
[54]
Robust statistical comparison of random variables with locally varying scale of measurement
Christoph Jansen, Georg Schollmeyer, Hannah Blocher, Julian Rodemann, and Thomas Augustin. Robust statistical comparison of random variables with locally varying scale of measurement. In Uncertainty in Artificial Intelligence (UAI). PMLR, 2023
work page 2023
-
[55]
Statistical multicriteria benchmarking via the GSD -front
Christoph Jansen, Georg Schollmeyer, Julian Rodemann, Hannah Blocher, and Thomas Augustin. Statistical multicriteria benchmarking via the GSD -front. In Neural Information Processing Systems, volume 37, pp.\ 98143--98179, 2024 a
work page 2024
-
[56]
Statistical multicriteria benchmarking via the gsd-front
Christoph Jansen, Georg Schollmeyer, Julian Rodemann, Hannah Blocher, and Thomas Augustin. Statistical multicriteria benchmarking via the gsd-front. Advances in Neural Information Processing Systems, 37: 0 98143--98179, 2024 b
work page 2024
-
[57]
Self-supervised visual feature learning with deep neural networks: A survey
Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43 0 (11): 0 4037--4058, 2021
work page 2021
-
[58]
RE Kass, L Tierney, and JB Kadane. The validity of posterior expansions based on L aplace's method." essays in honor of george barnard, eds. s. geisser, js hodges, 1990
work page 1990
-
[59]
Using semantic information for defining and detecting ood inputs, 2023
Ramneet Kaur, Xiayan Ji, Souradeep Dutta, Michele Caprio, Yahan Yang, Elena Bernardis, Oleg Sokolsky, and Insup Lee. Using semantic information for defining and detecting ood inputs, 2023. URL https://arxiv.org/abs/2302.11019
-
[60]
The uci machine learning repository, 2025
Markelle Kelly, Rachel Longjohn, and Kolby Nottingham. The uci machine learning repository, 2025. URL https://archive.ics.uci.edu. Last Accessed: 19.01.2025. For citation see https://archive.ics.uci.edu/citation
work page 2025
-
[61]
D. P. Kingma and M. Welling. Auto-encoding variational bayes. Proceedings of the International Conference on Learning Representations (ICLR), 2014
work page 2014
-
[62]
Information criteria and statistical modeling
Sadanori Konishi and Genshiro Kitagawa. Information criteria and statistical modeling. Springer, 2008
work page 2008
-
[63]
Being bayesian, even just a bit, fixes overconfidence in relu networks
Agustinus Kristiadi, Matthias Hein, and Philipp Hennig. Being bayesian, even just a bit, fixes overconfidence in relu networks. In International conference on machine learning, pp.\ 5436--5446. PMLR, 2020
work page 2020
-
[64]
Posterior refinement improves sample efficiency in B ayesian neural networks
Agustinus Kristiadi, Runa Eschenhagen, and Philipp Hennig. Posterior refinement improves sample efficiency in B ayesian neural networks. Advances in Neural Information Processing Systems, 35: 0 30333--30346, 2022
work page 2022
-
[65]
Tomasz M. api \'n ski. Multivariate L aplace’s approximation with estimated error and application to limit theorems. Journal of Approximation Theory, 248: 0 105305, 2019. ISSN 0021-9045. doi:https://doi.org/10.1016/j.jat.2019.105305. URL https://www.sciencedirect.com/science/article/pii/S0021904519301108
-
[66]
PS Laplace. M \'e moires de math \'e matique et de physique, tome sixieme [memoir on the probability of causes of events.]. Statistical Science, pp.\ 366--367, 1986
work page 1986
-
[67]
Martingale posterior neural processes
Hyungi Lee, Eunggu Yun, Giung Nam, Edwin Fong, and Juho Lee. Martingale posterior neural processes. arXiv preprint arXiv:2304.09431, 2023
-
[68]
Estimating model uncertainty of neural networks in sparse information form
Jongseok Lee, Matthias Humt, Jianxiang Feng, and Rudolph Triebel. Estimating model uncertainty of neural networks in sparse information form. In International Conference on Machine Learning, pp.\ 5702--5713. PMLR, 2020
work page 2020
-
[69]
Stewart, Vytautas Jancauskas, Stefan Depeweg, Eric Nalisnick, and Nina M
Nils Lehmann, Jakob Gawlikowski, Adam J. Stewart, Vytautas Jancauskas, Stefan Depeweg, Eric Nalisnick, and Nina M. Gottschling. Lightning UQ Box : A comprehensive framework for uncertainty quantification in deep learning. arXiv preprint arXiv:2410.03390, 2024
-
[70]
Marginal likelihood computation for model selection and hypothesis testing: an extensive review
Fernando Llorente, Luca Martino, David Delgado, and Javier Lopez-Santiago. Marginal likelihood computation for model selection and hypothesis testing: an extensive review. SIAM Review, 65 0 (1): 0 3--58, 2023
work page 2023
-
[71]
Dhruv Lowe, Terrence Sanvictores, Muhammad Zubair, and Savio John. Alkaline Phosphatase. Treasure Island (FL): StatPearls Publishing, 2025. URL https://www.ncbi.nlm.nih.gov/books/NBK459201/
work page 2025
-
[72]
Ibcl: Zero-shot model generation under stability-plasticity trade-offs, 2024
Pengyuan Lu, Michele Caprio, Eric Eaton, and Insup Lee. Ibcl: Zero-shot model generation under stability-plasticity trade-offs, 2024. URL https://arxiv.org/abs/2305.14782
-
[73]
An empirical study of prior-data conflicts in Bayesian neural networks, 2023
Alexander Marquardt, Julian Rodemann, and Thomas Augustin. An empirical study of prior-data conflicts in Bayesian neural networks, 2023. Poster presented at the International Symposium on Imprecise Probability: Theories and Applications (ISIPTA). Available at https://isipta23.sipta.org/accepted-papers/short-marquard/ (last accessed October 29 2025)
work page 2023
-
[74]
Optimizing neural networks with kronecker-factored approximate curvature
James Martens and Roger Grosse. Optimizing neural networks with kronecker-factored approximate curvature. In International conference on machine learning, pp.\ 2408--2417. PMLR, 2015
work page 2015
-
[75]
Integrated nested L aplace approximations (inla)
Sara Martino and Andrea Riebler. Integrated nested L aplace approximations (inla). arXiv preprint arXiv:1907.01248, 2019
-
[76]
Applied asymptotic analysis, volume 75
Peter David Miller. Applied asymptotic analysis, volume 75. American Mathematical Soc., 2006
work page 2006
-
[77]
Divergence measures and message passing
Tom Minka. Divergence measures and message passing. Technical Report MSR-TR-2005-173, January 2005. URL https://www.microsoft.com/en-us/research/publication/divergence-measures-and-message-passing/
work page 2005
-
[78]
A. Mnih and K. Gregor. Neural variational inference and learning in belief networks. In Proceedings of the 31st International Conference on Machine Learning, 2014
work page 2014
-
[79]
Airfoil’s aerodynamic coefficients prediction using artificial neural network
Hassan Moin, Hafiz Zeeshan Iqbal Khan, Surrayya Mobeen, and Jamshed Riaz. Airfoil’s aerodynamic coefficients prediction using artificial neural network. In 2022 19th International Bhurban Conference on Applied Sciences and Technology (IBCAST), pp.\ 175–182. IEEE, August 2022. doi:10.1109/ibcast54850.2022.9990112. URL http://dx.doi.org/10.1109/IBCAST54850....
-
[80]
Martingale posterior distributions for time-series models
Blake Moya and Stephen G Walker. Martingale posterior distributions for time-series models. Statistical Science, 40 0 (1): 0 68--80, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.