Recognition: 2 theorem links
· Lean TheoremTriBand-BEV: Real-Time LiDAR-Only 3D Pedestrian Detection via Height-Aware BEV and High-Resolution Feature Fusion
Pith reviewed 2026-05-13 06:35 UTC · model grok-4.3
The pith
A three-band height-aware BEV turns full LiDAR scans into 2D detection followed by 3D box reconstruction for real-time pedestrian spotting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
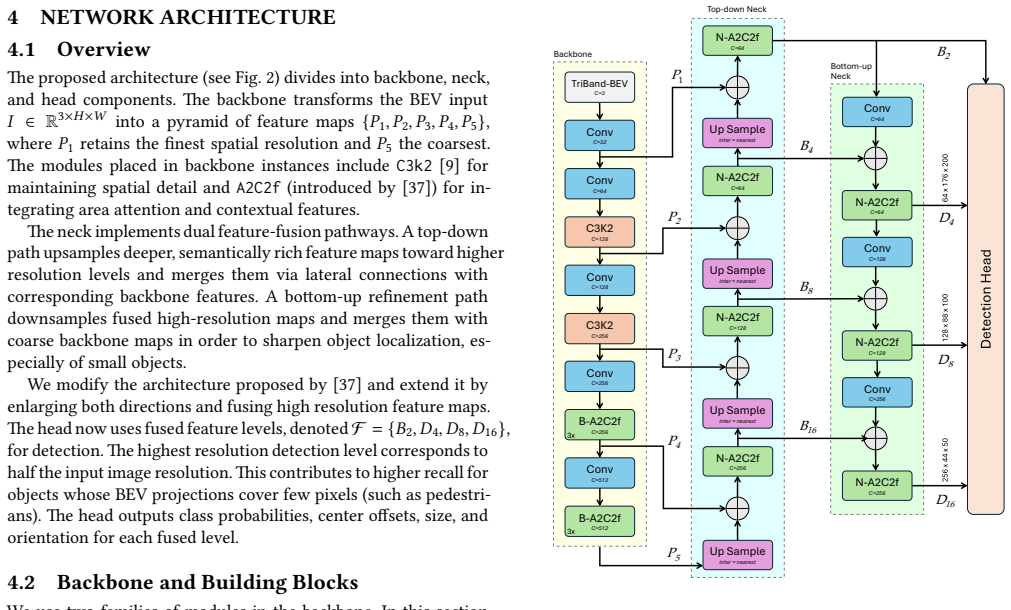
TriBand-BEV maps every LiDAR point into a lightweight 2D BEV tensor using three fixed vertical height bands, recasts 3D detection as ordinary 2D oriented-box regression, and recovers final 3D boxes from the 2D outputs via an IQR-based outlier filter. The network combines deep area attention, a hierarchical bidirectional neck fusing P1-P4 scales, distribution focal learning for side offsets, and a rotated IoU loss; training adds mild vertical re-binning and reflectance jitter.
What carries the argument
The TriBand-BEV encoding that divides the 3D point cloud into three fixed height bands to produce a 2D tensor supporting fast 2D detection and subsequent geometric reconstruction.
If this is right
- One forward pass detects cars, pedestrians and cyclists together.
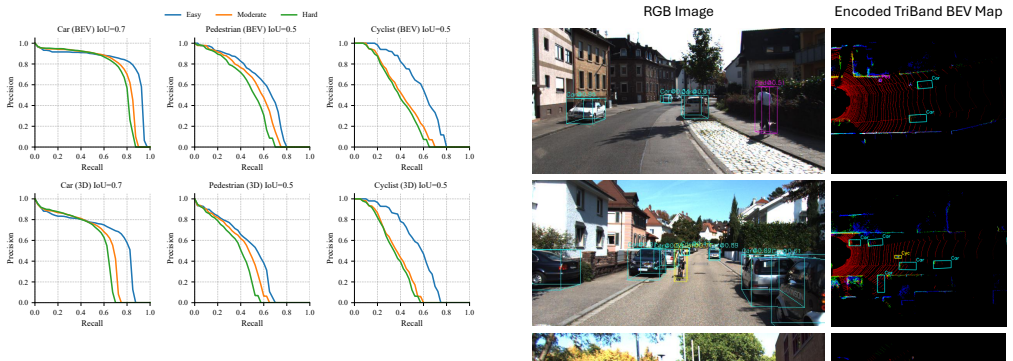
- Pedestrian BEV AP reaches 58.7 / 52.6 / 47.2 on KITTI easy / moderate / hard while sustaining 49 FPS on a single consumer GPU.
- Qualitative scenes remain stable when pedestrians are partially hidden by other objects.
- The compact pipeline requires no explicit 3D convolutions or cross-view fusion.
Where Pith is reading between the lines
- Height-band encodings of this style could be tried on radar or camera-LiDAR fusion pipelines to lower compute.
- Fixed three-band spacing may need scene-adaptive adjustment on datasets with extreme height variation.
- Replacing the IQR filter with a small learned lifting head could further improve reconstruction on noisy scans.
- Real-time speed makes online monitoring of band statistics feasible for domain adaptation.
Load-bearing premise
Projecting points into three fixed height bands plus simple 2D-to-3D lifting preserves enough geometry for accurate pedestrian detection even under occlusion and varying point density.
What would settle it
Run the same network on a LiDAR dataset rich in heavily occluded or unusually tall pedestrians and measure whether BEV AP falls more than 10 points below the KITTI numbers while a comparable full-3D detector does not.
Figures





read the original abstract
Safe autonomous agents and mobile robots need fast real time 3D perception, especially for vulnerable road users (VRUs) such as pedestrians. We introduce a new bird's eye view (BEV) encoding, which maps the full 3D LiDAR point cloud into a light-weight 2D BEV tensor with three height bands. We explicitly reformulate 3D detection as a 2D detection problem and then reconstruct 3D boxes from the BEV outputs. A single network detects cars, pedestrians, and cyclists in one pass. The backbone uses area attention at deep stages, a hierarchical bidirectional neck over P1 to P4 fuses context and detail, and the head predicts oriented boxes with distribution focal learning for side offsets and a rotated IoU loss. Training applies a small vertical re bin and a mild reflectance jitter in channel space to resist memorization. We use an interquartile range (IQR) filter to remove noisy and outlier LiDAR points during 3D reconstruction. On KITTI dataset, TriBand-BEV attains 58.7/52.6/47.2 pedestrian BEV AP(%) for easy, moderate, and hard at 49 FPS on a single consumer GPU, surpassing Complex-YOLO, with gains of +12.6%, +7.5%, and +3.1%. Qualitative scenes show stable detection under occlusion. The pipeline is compact and ready for real time robotic deployment. Our source code is publicly available on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TriBand-BEV, a LiDAR-only pipeline for real-time 3D detection of pedestrians (and jointly cars/cyclists). It encodes the full point cloud into a lightweight 2D BEV tensor via three fixed height bands, reformulates detection as a 2D oriented-box task with area attention and a hierarchical bidirectional neck, then lifts predictions to 3D boxes via IQR filtering and a small vertical re-bin. On KITTI it reports pedestrian BEV AP of 58.7/52.6/47.2 (easy/moderate/hard) at 49 FPS on a single consumer GPU, outperforming Complex-YOLO by +12.6/+7.5/+3.1 points; code is released on GitHub.
Significance. If the performance numbers are reproducible and the fixed-band assumption holds under occlusion and sparsity, the method offers a compact, real-time alternative to full 3D convolutions or multi-view fusion for VRU detection. The public code release is a clear strength that enables direct verification and extension.
major comments (3)
- [Abstract] Abstract: the headline claim of +12.6/+7.5/+3.1 point gains over Complex-YOLO rests on KITTI pedestrian BEV AP numbers, yet the manuscript supplies no train/val split, no error bars, and no statement of whether results are single-run or averaged; this directly affects whether the central empirical result can be trusted.
- [Method] Method (height-band encoding and reconstruction): the three fixed height bands plus IQR-based 2D-to-3D lift are presented as sufficient to recover accurate 3D boxes even for hard/occluded pedestrians, but no ablation on band count, thresholds, or IQR multiplier is given; without these, it is impossible to judge whether the reported hard-case AP (47.2) is robust or an artifact of the chosen discretization.
- [Experiments] Experiments: the vertical re-bin and reflectance jitter are described only qualitatively ('small' and 'mild') with no quantitative sensitivity analysis; because these are the only explicit regularizers mentioned, their omission leaves open whether post-processing rather than the network architecture drives the claimed FPS and accuracy.
minor comments (2)
- [Abstract] The abstract and method text introduce the 'TriBand-BEV tensor' without an accompanying equation or figure that defines its exact channel layout and bin boundaries.
- [Qualitative results] A few sentences in the reconstruction paragraph use ambiguous phrasing ('stable detection under occlusion') that would benefit from a quantitative metric or additional qualitative examples.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, clarifying our approach and committing to revisions that strengthen the empirical claims and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of +12.6/+7.5/+3.1 point gains over Complex-YOLO rests on KITTI pedestrian BEV AP numbers, yet the manuscript supplies no train/val split, no error bars, and no statement of whether results are single-run or averaged; this directly affects whether the central empirical result can be trusted.
Authors: We agree that explicit details improve trust in the results. The reported numbers use the standard KITTI split (3712 training / 3769 validation samples) as defined by the benchmark and followed in prior works such as Complex-YOLO. All results are from a single training run. We will add this information to the abstract and experiments section in the revision. Error bars are not provided due to the computational cost of multiple full trainings on our hardware; however, the public GitHub code release enables direct reproduction and optional multi-run averaging by others. We have added a clarifying statement on single-run reporting. revision: partial
-
Referee: [Method] Method (height-band encoding and reconstruction): the three fixed height bands plus IQR-based 2D-to-3D lift are presented as sufficient to recover accurate 3D boxes even for hard/occluded pedestrians, but no ablation on band count, thresholds, or IQR multiplier is given; without these, it is impossible to judge whether the reported hard-case AP (47.2) is robust or an artifact of the chosen discretization.
Authors: We acknowledge that ablations would help demonstrate robustness. The three fixed bands are chosen to span typical pedestrian height distributions (approximately 0–0.5 m, 0.5–1.5 m, >1.5 m) while preserving a compact BEV tensor for real-time inference; the IQR filter is a standard outlier removal step. In the revision we will add an ablation table varying band count (2/3/4), height thresholds, and IQR multiplier values, showing that the reported hard-case performance remains stable and is not an artifact of the specific discretization. revision: yes
-
Referee: [Experiments] Experiments: the vertical re-bin and reflectance jitter are described only qualitatively ('small' and 'mild') with no quantitative sensitivity analysis; because these are the only explicit regularizers mentioned, their omission leaves open whether post-processing rather than the network architecture drives the claimed FPS and accuracy.
Authors: We agree that a quantitative sensitivity study is warranted. The vertical re-bin and reflectance jitter serve as lightweight regularizers to reduce overfitting on sparse LiDAR data. We will insert a new table in the experiments section that reports pedestrian AP and FPS across a range of re-bin sizes and jitter amplitudes. This analysis will show that the core network (area attention, bidirectional neck, rotated IoU loss) accounts for the majority of the accuracy and speed gains, while the regularizers provide modest but consistent improvements without driving the overall results. revision: yes
Circularity Check
Empirical architecture with no derivation chain
full rationale
The paper introduces an empirical pipeline that encodes LiDAR points into a three-band BEV tensor, reformulates 3D detection as 2D detection, and reconstructs boxes via IQR filtering. No equations or theorems are presented whose outputs are shown to equal their inputs by construction, nor are any load-bearing claims justified solely by self-citation. Reported numbers are direct benchmark results on KITTI rather than predictions derived from fitted parameters within the same model. The design choices (fixed bands, area attention, rotated IoU loss) remain independent of the final AP figures.
Axiom & Free-Parameter Ledger
free parameters (1)
- height band thresholds
axioms (1)
- domain assumption LiDAR points can be losslessly projected into a 2D BEV tensor with three height channels without discarding critical 3D structure for detection
invented entities (1)
-
TriBand-BEV tensor
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
The returns are partitioned into three vertical bands: B1: z < 0.65 m, B2: 0.65 ≤ z < 1.30 m, and B3: z ≥ 1.30 m.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Xuyang Bai, Zeyu Hu, Xinge Zhu, Qingqiu Huang, Yilun Chen, Hongbo Fu, and Chiew-Lan Tai. 2022. Transfusion: Robust lidar-camera fusion for 3d object de- tection with transformers. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 1090–1099
work page 2022
-
[3]
Xiaozhi Chen, Kaustav Kundu, Yukun Zhu, Andrew G Berneshawi, Huimin Ma, Sanja Fidler, and Raquel Urtasun. 2015. 3d object proposals for accurate object class detection. Advances in neural information processing systems 28 (2015)
work page 2015
-
[4]
Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. 2017. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE con- ference on Computer Vision and Pattern Recognition . 1907–1915
work page 2017
-
[5]
Jiajun Deng, Shaoshuai Shi, Peiwei Li, Wengang Zhou, Yanyong Zhang, and Houqiang Li. 2021. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI conference on artificial intelligence , Vol. 35. 1201–1209
work page 2021
-
[6]
Lue Fan, Ziqi Pang, Tianyuan Zhang, Yu-Xiong Wang, Hang Zhao, Feng Wang, Naiyan Wang, and Zhaoxiang Zhang. 2022. Embracing single stride 3d object detector with sparse transformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 8458–8468
work page 2022
-
[7]
Andreas Geiger, Philip Lenz, and Raquel Urtasun. 2012. Are we ready for Au- tonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 3354–3361
work page 2012
-
[8]
Tengteng Huang, Zhe Liu, Xiwu Chen, and Xiang Bai. 2020. Epnet: Enhancing point features with image semantics for 3d object detection. In European confer- ence on computer vision . 35–52
work page 2020
-
[9]
Rahima Khanam and Muhammad Hussain. 2024. Yolov11: An overview of the key architectural enhancements. arXiv preprint arXiv:2410.17725 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Mohammad Khoshkdahan, Arman Akbari, Arash Akbari, and Xuan Zhang
-
[11]
In International Conference on Intelligent Transportation Systems (ITSC)
Beyond Overall Accuracy: Pose-and Occlusion-driven Fairness Analysis in Pedestrian Detection for Autonomous Driving. In International Conference on Intelligent Transportation Systems (ITSC)
-
[12]
Mohammad Khoshkdahan, Nicholas Kjär, and Fabian B Flohr. 2025. Fair-ped: Fairness evaluation in pedestrian detection using clip. In 2025 IEEE Intelligent Vehicles Symposium (IV). 1504–1509
work page 2025
- [13]
-
[14]
Peizhao Li, Pu Wang, Karl Berntorp, and Hongfu Liu. 2022. Exploiting tempo- ral relations on radar perception for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 17071–17080
work page 2022
-
[15]
Qi Li, Yue Wang, Yilun Wang, and Hang Zhao. 2022. Hdmapnet: An online hd map construction and evaluation framework. In 2022 International Conference on Robotics and Automation (ICRA) . 4628–4634
work page 2022
-
[16]
Ming Liang, Bin Yang, Shenlong Wang, and Raquel Urtasun. 2018. Deep contin- uous fusion for multi-sensor 3d object detection. In Proceedings of the European conference on computer vision (ECCV) . 641–656
work page 2018
-
[17]
Biao Liu and Yanxin Wu. 2025. BFT3D: A Robust BEV Feature Transformation Module for Multisensor 3-D Object Detection. IEEE Sensors Journal 25, 15 (2025), 30175–30185
work page 2025
-
[18]
Wenjie Luo, Bin Yang, and Raquel Urtasun. 2018. Fast and furious: Real time end-to-end 3d detection, tracking and motion forecasting with a single convolu- tional net. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 3569–3577
work page 2018
-
[19]
Jiageng Mao, Minzhe Niu, Haoyue Bai, Xiaodan Liang, Hang Xu, and Chunjing Xu. 2021. Pyramid r-cnn: Towards better performance and adaptability for 3d object detection. In Proceedings of the IEEE/CVF international conference on com- puter vision. 2723–2732
work page 2021
-
[20]
Jiageng Mao, Yujing Xue, Minzhe Niu, Haoyue Bai, Jiashi Feng, Xiaodan Liang, Hang Xu, and Chunjing Xu. 2021. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF international conference on computer vision . 3164– 3173
work page 2021
-
[21]
Gregory P Meyer, Jake Charland, Shreyash Pandey, Ankit Laddha, Shivam Gau- tam, Carlos Vallespi-Gonzalez, and Carl K Wellington. 2020. Laserflow: Efficient and probabilistic object detection and motion forecasting. IEEE Robotics and Automation Letters 6, 2, 526–533
work page 2020
-
[22]
Gregory P Meyer, Ankit Laddha, Eric Kee, Carlos Vallespi-Gonzalez, and Carl K Wellington. 2019. Lasernet: An efficient probabilistic 3d object detector for au- tonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12677–12686
work page 2019
- [23]
-
[24]
Pha Nguyen, Kha Gia Quach, Chi Nhan Duong, Ngan Le, Xuan-Bac Nguyen, and Khoa Luu. 2022. Multi-camera multiple 3d object tracking on the move for autonomous vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 2569–2578
work page 2022
-
[25]
Anshul Paigwar, Özgür Erkent, David Sierra-Gonzalez, and Christian Laugier
-
[26]
In 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS)
GndNet: Fast ground plane estimation and point cloud segmentation for autonomous vehicles. In 2020 IEEE/RSJ international conference on intelligent robots and systems (IROS) . IEEE, 2150–2156
work page 2020
-
[27]
Xuran Pan, Zhuofan Xia, Shiji Song, Li Erran Li, and Gao Huang. 2021. 3d ob- ject detection with pointformer. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 7463–7472
work page 2021
-
[28]
Su Pang, Daniel Morris, and Hayder Radha. 2020. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In 2020 IEEE/RSJ International Confer- ence on Intelligent Robots and Systems (IROS) . 10386–10393
work page 2020
-
[29]
Charles R Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J Guibas. 2018. Frus- tum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE conference on computer vision and pattern recognition . 918–927
work page 2018
-
[30]
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. 2017. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition . 652–660
work page 2017
-
[31]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. 2017. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems 30
work page 2017
-
[32]
Yongxin Shao, Zhetao Sun, Aihong Tan, and Tianhong Yan. 2023. Efficient three- dimensional point cloud object detection based on improved Complex-YOLO. Frontiers in Neurorobotics 17 (2023), 1092564
work page 2023
-
[33]
Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, and Hongsheng Li. 2020. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10529–10538
work page 2020
-
[34]
Shaoshuai Shi, Li Jiang, Jiajun Deng, Zhe Wang, Chaoxu Guo, Jianping Shi, Xi- aogang Wang, and Hongsheng Li. 2023. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Interna- tional Journal of Computer Vision 131, 2, 531–551
work page 2023
-
[35]
Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. 2019. Pointrcnn: 3d ob- ject proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 770–779
work page 2019
-
[36]
Weijing Shi and Raj Rajkumar. 2020. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 1711–1719
work page 2020
-
[37]
Martin Simony, Stefan Milzy, Karl Amendey, and Horst-Michael Gross. 2018. Complex-yolo: An euler-region-proposal for real-time 3d object detection on point clouds. In Proceedings of the European conference on computer vision (ECCV) workshops
work page 2018
-
[38]
Vishwanath A Sindagi, Yin Zhou, and Oncel Tuzel. 2019. Mvx-net: Multimodal voxelnet for 3d object detection. In 2019 International Conference on Robotics and Automation (ICRA). 7276–7282
work page 2019
-
[39]
Yunjie Tian, Qixiang Ye, and David Doermann. 2025. Yolov12: Attention-centric real-time object detectors. arXiv preprint arXiv:2502.12524 (2025)
work page internal anchor Pith review arXiv 2025
-
[40]
Sourabh Vora, Alex H Lang, Bassam Helou, and Oscar Beijbom. 2020. Pointpaint- ing: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 4604–4612
work page 2020
-
[41]
Zhixin Wang and Kui Jia. 2019. Frustum convnet: Sliding frustums to aggre- gate local point-wise features for amodal 3d object detection. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . 1742–1749
work page 2019
-
[42]
Hai Wu, Jinhao Deng, Chenglu Wen, Xin Li, Cheng Wang, and Jonathan Li. 2022. CasA: A cascade attention network for 3-D object detection from LiDAR point clouds. IEEE Transactions on Geoscience and Remote Sensing 60 (2022), 1–11
work page 2022
-
[43]
Hai Wu, Chenglu Wen, Wei Li, Xin Li, Ruigang Yang, and Cheng Wang. 2023. Transformation-equivariant 3d object detection for autonomous driving. In Pro- ceedings of the AAAI Conference on Artificial Intelligence , Vol. 37. 2795–2802
work page 2023
-
[44]
Hai Wu, Chenglu Wen, Shaoshuai Shi, Xin Li, and Cheng Wang. 2023. Vir- tual sparse convolution for multimodal 3d object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 21653–21662
work page 2023
-
[45]
Yutian Wu, Yueyu Wang, Shuwei Zhang, and Harutoshi Ogai. 2020. Deep 3D object detection networks using LiDAR data: A review. IEEE Sensors Journal 21, 2 (2020), 1152–1171
work page 2020
-
[46]
Yan Yan, Yuxing Mao, and Bo Li. 2018. Second: Sparsely embedded convolutional detection. Sensors 18, 10, 3337
work page 2018
-
[47]
Bin Yang, Wenjie Luo, and Raquel Urtasun. 2018. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition . 7652–7660
work page 2018
-
[48]
Zetong Yang, Yanan Sun, Shu Liu, and Jiaya Jia. 2020. 3dssd: Point-based 3d sin- gle stage object detector. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 11040–11048
work page 2020
-
[49]
Zetong Yang, Yanan Sun, Shu Liu, Xiaoyong Shen, and Jiaya Jia. 2019. Std: Sparse- to-dense 3d object detector for point cloud. In Proceedings of the IEEE/CVF inter- national conference on computer vision . 1951–1960
work page 2019
-
[50]
Wei Ye, Qiming Xia, Hai Wu, Zhen Dong, Ruofei Zhong, Cheng Wang, and Chenglu Wen. 2025. Fade3D: Fast and Deployable 3D Object Detection for Au- tonomous Driving. IEEE Transactions on Intelligent Transportation Systems 26, 9 (2025), 12934–12946
work page 2025
-
[51]
Jin Hyeok Yoo, Yecheol Kim, Jisong Kim, and Jun Won Choi. 2020. 3d-cvf: Gen- erating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In European conference on computer vision . 720–736
work page 2020
-
[52]
Zhuochen Yu, Bijie Qiu, and Andy WH Khong. 2025. ViKIENet: Towards Ef- ficient 3D Object Detection with Virtual Key Instance Enhanced Network. In Proceedings of the Computer Vision and Pattern Recognition Conference . 11844– 11853
work page 2025
-
[53]
Jie Zhou, Xin Tan, Zhiwen Shao, and Lizhuang Ma. 2019. FVNet: 3D front-view proposal generation for real-time object detection from point clouds. In 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI). 1–8
work page 2019
-
[54]
Yin Zhou and Oncel Tuzel. 2018. Voxelnet: End-to-end learning for point cloud based 3d object detection. InProceedings of the IEEE conference on computer vision and pattern recognition. 4490–4499
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.