Recognition: no theorem link
GKnow: Measuring the Entanglement of Gender Bias and Factual Gender
Pith reviewed 2026-05-13 04:46 UTC · model grok-4.3
The pith
Gender bias and factual gender are entangled in language model circuits and neurons, making ablation unreliable for debiasing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We curate GKnow, a benchmark to assess gender knowledge and gender bias in language models across different types of gender-related predictions. GKnow allows us to identify and analyze circuits and individual neurons responsible for gendered predictions. We test the impact of neuron ablation on benchmarks for disentangling stereotypical and factual gender (DiFair and the test set of GKnow), as well as StereoSet. Results show that gender bias and factual gender are severely entangled on the level of both circuits and neurons, entailing that ablation is an unreliable debiasing method. Furthermore, we show that benchmarks for evaluating gender bias can hide the decrease in factual gender thatac
What carries the argument
The GKnow benchmark for measuring both factual gender knowledge and stereotypical bias, paired with circuit and neuron identification to test ablation effects.
Load-bearing premise
The DiFair benchmark and GKnow test set can reliably disentangle stereotypical gender bias from factual gender knowledge.
What would settle it
Observing a neuron set whose ablation reduces bias on StereoSet and DiFair while preserving or improving accuracy on GKnow's factual gender test items.
Figures
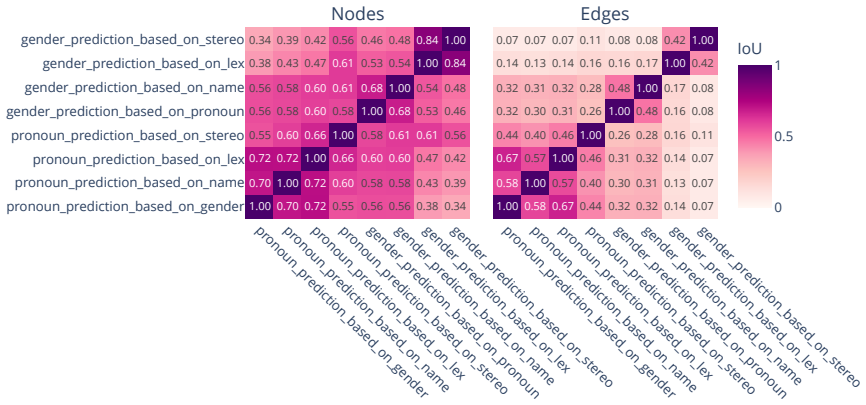

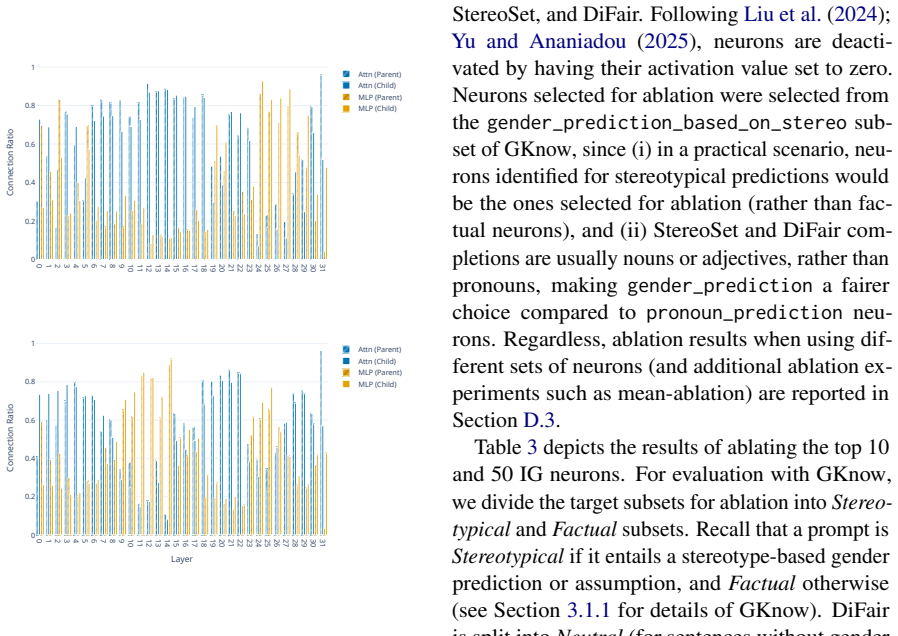

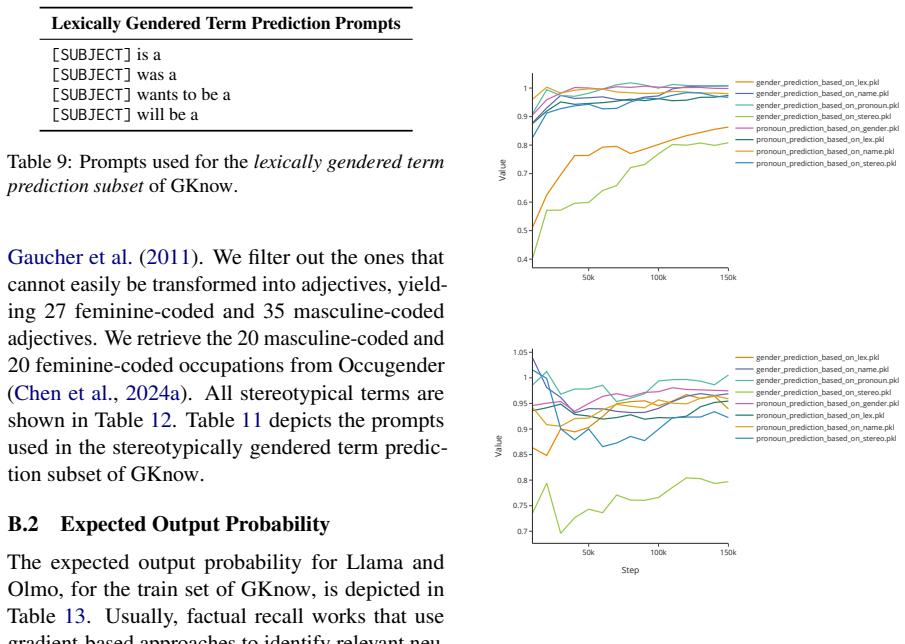
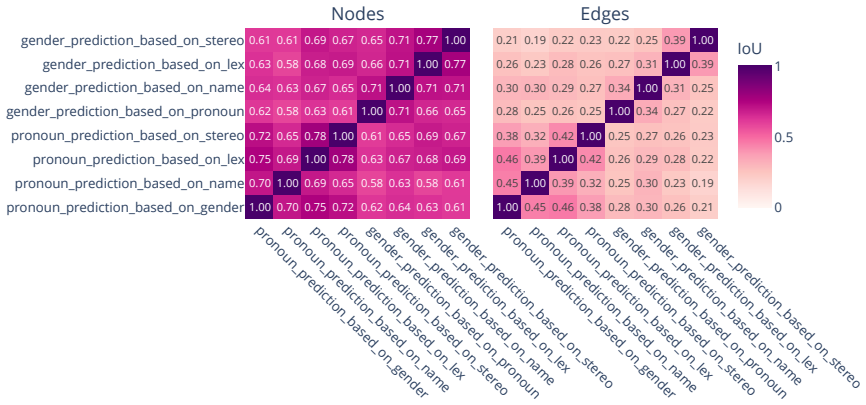


read the original abstract
Recent works have analyzed the impact of individual components of neural networks on gendered predictions, often with a focus on mitigating gender bias. However, mechanistic interpretations of gender tend to (i) focus on a very specific gender-related task, such as gendered pronoun prediction, or (ii) fail to distinguish between the production of factually gendered outputs (the correct assumption of gender given a word that carries gender as a semantic property) and gender biased outputs (based on a stereotype). To address these issues, we curate \gknow, a benchmark to assess gender knowledge and gender bias in language models across different types of gender-related predictions. \gknow allows us to identify and analyze circuits and individual neurons responsible for gendered predictions. We test the impact of neuron ablation on benchmarks for disentangling stereotypical and factual gender (DiFair and the test set of GKnow), as well as StereoSet. Results show that gender bias and factual gender are severely entangled on the level of both circuits and neurons, entailing that ablation is an unreliable debiasing method. Furthermore, we show that benchmarks for evaluating gender bias can hide the decrease in factual gender knowledge that accompanies neuron ablation. We curate GKnow as a contribution to the continuous development of robust gender bias benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GKnow, a new benchmark designed to separately evaluate factual gender knowledge (correct gender inference from semantic properties) and stereotypical gender bias in language models. It identifies circuits and individual neurons responsible for gendered predictions, then conducts ablation experiments on DiFair, the GKnow test set, and StereoSet. The central results claim severe entanglement between bias and factual gender at both circuit and neuron levels, rendering ablation-based debiasing unreliable; the work also argues that standard bias benchmarks can mask accompanying losses in factual knowledge.
Significance. If the entanglement findings hold after addressing controls, the paper would be significant for mechanistic interpretability and bias mitigation research. It contributes a benchmark that explicitly disentangles factual gender from stereotypes, provides empirical evidence on the limits of neuron/circuit ablation for debiasing, and highlights risks in current evaluation practices. Strengths include the curation of GKnow as a public resource and the multi-benchmark testing of both circuits and neurons.
major comments (2)
- [Ablation Experiments] Ablation results (detailed after the circuit identification in the experiments): performance drops are reported only on DiFair, GKnow test set, and StereoSet, with no controls on unrelated tasks such as general language understanding (e.g., GLUE subsets or factual QA). This is load-bearing for the entanglement claim, because nonspecific representational damage from ablation could produce the observed drops without requiring circuit-level overlap between bias and factual gender.
- [Neuron-level Analysis] § on neuron-level analysis: the claim that individual neurons are 'responsible for gendered predictions' and that their ablation reveals entanglement relies on the assumption that the GKnow test set and DiFair reliably isolate factual vs. stereotypical effects; without reported validation that ablations preserve non-gender capabilities, the neuron-level conclusion risks overinterpretation.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction could more explicitly state the size and construction details of the GKnow test set (e.g., number of examples per category) to allow immediate assessment of statistical power.
- [Figures] Figure captions for circuit diagrams should include the exact activation thresholds or selection criteria used to identify the reported circuits.
Simulated Author's Rebuttal
Thank you for the detailed review and the recommendation for major revision. We appreciate the feedback on the ablation experiments and neuron-level analysis. We address each major comment below, indicating the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Ablation Experiments] Ablation results (detailed after the circuit identification in the experiments): performance drops are reported only on DiFair, GKnow test set, and StereoSet, with no controls on unrelated tasks such as general language understanding (e.g., GLUE subsets or factual QA). This is load-bearing for the entanglement claim, because nonspecific representational damage from ablation could produce the observed drops without requiring circuit-level overlap between bias and factual gender.
Authors: We agree that including controls on unrelated tasks would provide stronger evidence for the entanglement claim by ruling out nonspecific representational damage. Our focus was on the gender-specific benchmarks to directly evaluate the disentanglement. We will incorporate ablation results on a GLUE subset and a factual QA task in the revised manuscript. revision: yes
-
Referee: [Neuron-level Analysis] § on neuron-level analysis: the claim that individual neurons are 'responsible for gendered predictions' and that their ablation reveals entanglement relies on the assumption that the GKnow test set and DiFair reliably isolate factual vs. stereotypical effects; without reported validation that ablations preserve non-gender capabilities, the neuron-level conclusion risks overinterpretation.
Authors: The GKnow benchmark is designed to isolate factual gender knowledge from stereotypical bias, providing the basis for our neuron-level claims. We acknowledge the lack of explicit validation for non-gender capabilities in the neuron ablations. In the revision, we will add a discussion of this limitation and, if possible, include checks on unrelated tasks for the neuron ablations. revision: partial
Circularity Check
No circularity: empirical benchmark curation and ablation experiments are self-contained
full rationale
The paper introduces the GKnow benchmark to separate factual gender knowledge from stereotypical bias, identifies responsible circuits/neurons via standard mechanistic interpretability techniques, and reports ablation results on DiFair, GKnow test set, and StereoSet. No equations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes smuggled via prior work appear in the derivation chain. All central claims rest on direct experimental measurements rather than reducing to definitional equivalences or inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mechanistic interpretability can identify circuits and neurons responsible for specific predictions in language models.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2310.14329 , year=
DiFair: A Benchmark for Disentangled Assessment of Gender Knowledge and Bias , author=. arXiv preprint arXiv:2310.14329 , year=
-
[2]
The Twelfth International Conference on Learning Representations , year=
The devil is in the neurons: Interpreting and mitigating social biases in language models , author=. The Twelfth International Conference on Learning Representations , year=
-
[3]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Neuron-level knowledge attribution in large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[4]
arXiv preprint arXiv:2403.00824 , year=
Information flow routes: Automatically interpreting language models at scale , author=. arXiv preprint arXiv:2403.00824 , year=
-
[5]
Causally Testing Gender Bias in
Yuen Chen and Vethavikashini Chithrra Raghuram and Justus Mattern and Rada Mihalcea and Zhijing Jin , booktitle=. Causally Testing Gender Bias in
-
[6]
Dependency in linguistic description , volume=
Dependency in natural language , author=. Dependency in linguistic description , volume=. 2009 , publisher=
work page 2009
- [7]
-
[8]
arXiv preprint arXiv:2104.08696 , year=
Knowledge neurons in pretrained transformers , author=. arXiv preprint arXiv:2104.08696 , year=
-
[9]
arXiv preprint arXiv:2206.10744 , year=
Don't Forget About Pronouns: Removing Gender Bias in Language Models Without Losing Factual Gender Information , author=. arXiv preprint arXiv:2206.10744 , year=
-
[10]
arXiv preprint arXiv:1809.01496 , year=
Learning gender-neutral word embeddings , author=. arXiv preprint arXiv:1809.01496 , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Leace: Perfect linear concept erasure in closed form , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Causal mediation analysis for interpreting neural nlp: The case of gender bias , author=. arXiv preprint arXiv:2004.12265 , year=
-
[13]
International Conference on Intelligent Computing , pages=
Locating and mitigating gender bias in large language models , author=. International Conference on Intelligent Computing , pages=. 2024 , organization=
work page 2024
-
[14]
arXiv preprint arXiv:1906.00742 , year=
Gender-preserving debiasing for pre-trained word embeddings , author=. arXiv preprint arXiv:1906.00742 , year=
-
[15]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Journey to the center of the knowledge neurons: Discoveries of language-independent knowledge neurons and degenerate knowledge neurons , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[16]
arXiv preprint arXiv:2409.15827 , year=
Unveiling Language Competence Neurons: A Psycholinguistic Approach to Model Interpretability , author=. arXiv preprint arXiv:2409.15827 , year=
-
[17]
arXiv preprint arXiv:2405.02421 , year=
What does the Knowledge Neuron Thesis Have to do with Knowledge? , author=. arXiv preprint arXiv:2405.02421 , year=
-
[18]
arXiv preprint arXiv:2004.09456 , year=
StereoSet: Measuring stereotypical bias in pretrained language models , author=. arXiv preprint arXiv:2004.09456 , year=
-
[19]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2021
-
[20]
Proceedings of the 9th Workshop on Representation Learning for NLP (RepL4NLP-2024) , pages=
LLM Circuit Analyses Are Consistent Across Training and Scale , author=. Proceedings of the 9th Workshop on Representation Learning for NLP (RepL4NLP-2024) , pages=
work page 2024
-
[21]
Identifying a preliminary circuit for predicting gendered pronouns in gpt-2 small , author=. URL: https://itch. io/jam/mechint/rate/1889871 , year=
-
[22]
Advances in Neural Information Processing Systems , year=
Attention is all you need , author=. Advances in Neural Information Processing Systems , year=
-
[23]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Knowledge Circuits in Pretrained Transformers , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[24]
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[25]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in Neural Information Processing Systems , volume=
Towards automated circuit discovery for mechanistic interpretability , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
arXiv preprint arXiv:2204.06827 , year=
How gender debiasing affects internal model representations, and why it matters , author=. arXiv preprint arXiv:2204.06827 , year=
-
[28]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small , author=. arXiv preprint arXiv:2211.00593 , year=
work page internal anchor Pith review arXiv
-
[29]
ICML 2024 Workshop on Mechanistic Interpretability , year=
Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms , author=. ICML 2024 Workshop on Mechanistic Interpretability , year=
work page 2024
- [30]
-
[31]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Sparse feature circuits: Discovering and editing interpretable causal graphs in language models , author=. arXiv preprint arXiv:2403.19647 , year=
work page internal anchor Pith review arXiv
-
[32]
Forty-first International Conference on Machine Learning , year=
Observable Propagation: Uncovering Feature Vectors in Transformers , author=. Forty-first International Conference on Machine Learning , year=
-
[33]
arXiv preprint arXiv:2501.14457 , year=
Understanding and Mitigating Gender Bias in LLMs via Interpretable Neuron Editing , author=. arXiv preprint arXiv:2501.14457 , year=
-
[34]
Neurons in Large Language Models: Dead, N-gram, Positional
Voita, Elena and Ferrando, Javier and Nalmpantis, Christoforos. Neurons in Large Language Models: Dead, N-gram, Positional. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.75
-
[35]
Identifying and Adapting Transformer-Components Responsible for Gender Bias in an English Language Model , author=. Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[36]
English Language and Linguistics , volume=
English tag questions: Corpus findings and theoretical implications , author=. English Language and Linguistics , volume=. 2008 , publisher=
work page 2008
-
[37]
arXiv preprint arXiv:1804.06876 , year=
Gender bias in coreference resolution: Evaluation and debiasing methods , author=. arXiv preprint arXiv:1804.06876 , year=
- [38]
-
[39]
arXiv preprint arXiv:2308.09124 , year=
Linearity of relation decoding in transformer language models , author=. arXiv preprint arXiv:2308.09124 , year=
-
[40]
arXiv preprint arXiv:2502.17355 , year=
On Relation-Specific Neurons in Large Language Models , author=. arXiv preprint arXiv:2502.17355 , year=
-
[41]
Inferring gender: A scalable methodology for gender detection with online lexical databases , author=. Proceedings of the Second Workshop on Language Technology for Equality, Diversity and Inclusion , pages=
-
[42]
arXiv preprint arXiv:2311.08968 , year=
Identifying linear relational concepts in large language models , author=. arXiv preprint arXiv:2311.08968 , year=
-
[43]
arXiv preprint arXiv:2501.10150 , year=
Dual Debiasing: Remove Stereotypes and Keep Factual Gender for Fair Language Modeling and Translation , author=. arXiv preprint arXiv:2501.10150 , year=
-
[44]
arXiv preprint arXiv:2503.06734 , year=
Gender Encoding Patterns in Pretrained Language Model Representations , author=. arXiv preprint arXiv:2503.06734 , year=
-
[45]
Trans women and the meaning of ``woman'' , author=
-
[46]
Words matter: The language of gender , author=. Handbook of Gender Research in Psychology: Volume 1: Gender Research in General and Experimental Psychology , pages=. 2010 , publisher=
work page 2010
-
[47]
OLMo: Accelerating the Science of Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[48]
Debiasing Algorithm through Model Adaptation , author=
-
[49]
Advances in neural information processing systems , volume=
Man is to computer programmer as woman is to homemaker? debiasing word embeddings , author=. Advances in neural information processing systems , volume=
-
[50]
arXiv preprint arXiv:2406.09265 , year=
Sharing matters: Analysing neurons across languages and tasks in llms , author=. arXiv preprint arXiv:2406.09265 , year=
-
[51]
arXiv preprint arXiv:2505.22586 , year=
Precise In-Parameter Concept Erasure in Large Language Models , author=. arXiv preprint arXiv:2505.22586 , year=
-
[52]
arXiv preprint arXiv:2501.08319 , year=
Enhancing automated interpretability with output-centric feature descriptions , author=. arXiv preprint arXiv:2501.08319 , year=
-
[53]
arXiv preprint arXiv:2504.13151 , year=
Mib: A mechanistic interpretability benchmark , author=. arXiv preprint arXiv:2504.13151 , year=
-
[54]
International conference on machine learning , pages=
Axiomatic attribution for deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[55]
Computational Linguistics , pages=
Are formal and functional linguistic mechanisms dissociated in language models? , author=. Computational Linguistics , pages=. 2025 , publisher=
work page 2025
-
[56]
arXiv preprint arXiv:2502.14258 , year=
Does Time Have Its Place? Temporal Heads: Where Language Models Recall Time-specific Information , author=. arXiv preprint arXiv:2502.14258 , year=
-
[57]
arXiv preprint arXiv:2508.15875 , year=
NEAT: Concept driven Neuron Attribution in LLMs , author=. arXiv preprint arXiv:2508.15875 , year=
-
[58]
Proceedings of the 4th Workshop on Gender Bias in Natural Language Processing (GeBNLP) , pages=
Choose Your Lenses: Flaws in Gender Bias Evaluation , author=. Proceedings of the 4th Workshop on Gender Bias in Natural Language Processing (GeBNLP) , pages=
-
[59]
Stereotyping Norwegian salmon: An inventory of pitfalls in fairness benchmark datasets , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[60]
arXiv preprint arXiv:2506.05166 , year=
Dissecting Bias in LLMs: A Mechanistic Interpretability Perspective , author=. arXiv preprint arXiv:2506.05166 , year=
- [61]
-
[62]
Advances in Neural Information Processing Systems , volume=
Optimal ablation for interpretability , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.