Recognition: no theorem link
Online Learning-to-Defer with Varying Experts
Pith reviewed 2026-05-13 03:58 UTC · model grok-4.3
The pith
An online algorithm for learning to defer routes queries to a changing pool of experts and achieves sublinear regret in multiclass classification with bandit feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
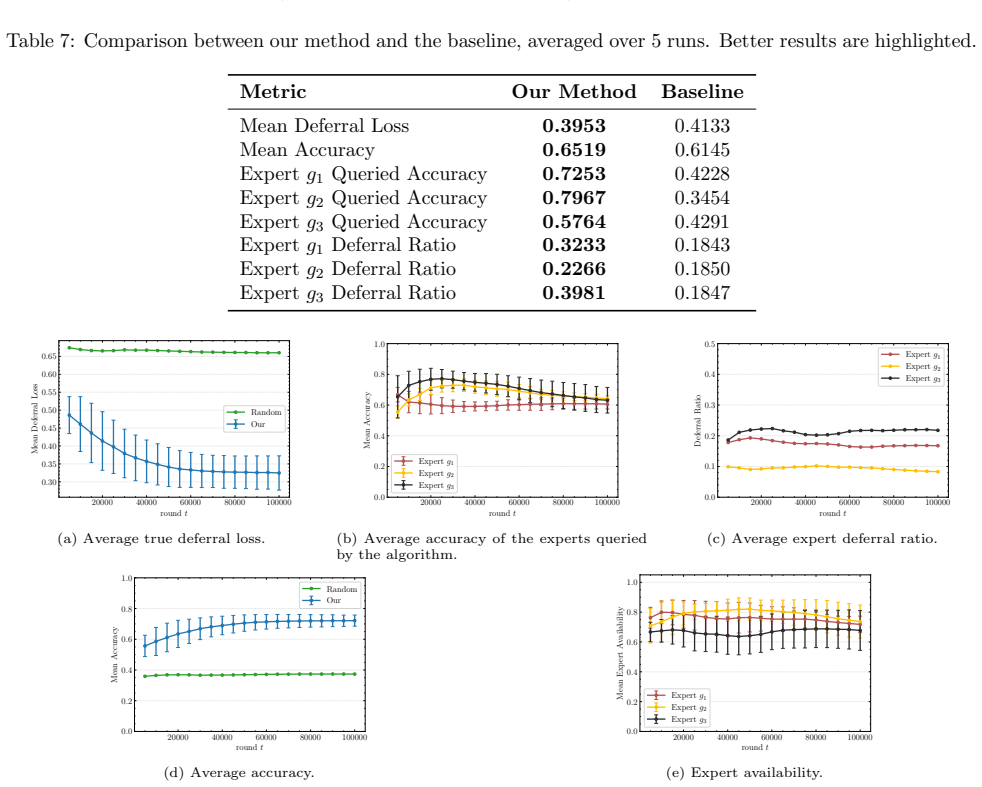
The paper establishes an online L2D algorithm for multiclass classification with bandit feedback that accommodates a dynamically varying pool of experts. This algorithm attains regret guarantees of O((n + n_e) T^{2/3}) in the general case and O((n + n_e) sqrt(T)) under a low-noise condition, where n is the number of classes, n_e the number of distinct experts seen, and T the horizon. The analysis relies on novel H-consistency bounds in the online setting paired with first-order online convex optimization methods. Experiments confirm the method works on both synthetic and real-world data.
What carries the argument
The online L2D algorithm that uses novel H-consistency bounds combined with first-order methods for online convex optimization to route each query to either the model or one of the available experts.
If this is right
- Standard batch Learning-to-Defer methods can be extended to handle streaming data and changing expert availability.
- The regret scales linearly with the number of classes and distinct experts observed.
- Improved sqrt(T) regret holds when the low-noise condition is satisfied.
- Empirical performance on synthetic and real datasets supports the theoretical guarantees.
Where Pith is reading between the lines
- The approach may support applications like real-time decision systems where expert availability fluctuates over time.
- Similar techniques could apply to other online decision problems involving deferral or routing.
- Relaxing the bandit feedback assumption might lead to even tighter bounds in future work.
Load-bearing premise
The regret analysis depends on novel H-consistency bounds holding in the online framework and on the low-noise condition being satisfied; if either fails, the stated regret rates may not be achieved.
What would settle it
Observe the actual regret growth in a setting where the low-noise condition is violated; if regret grows faster than sqrt(T) while other conditions hold, the improved bound would be falsified.
Figures
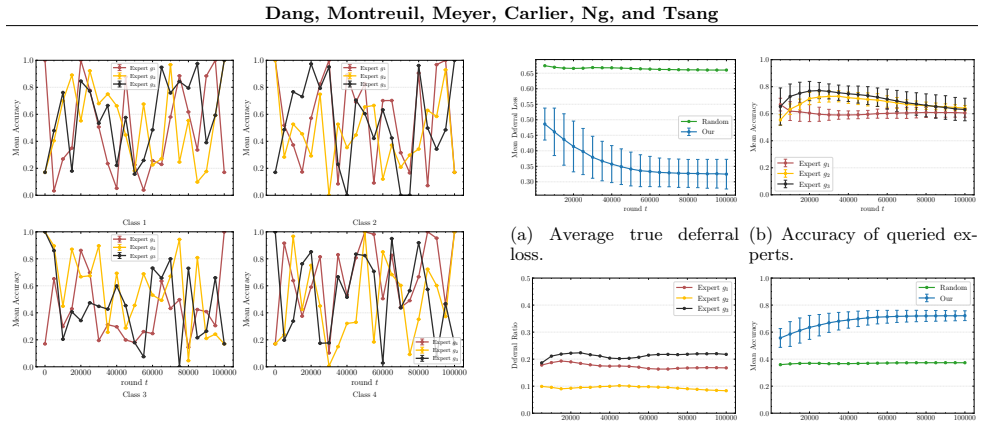


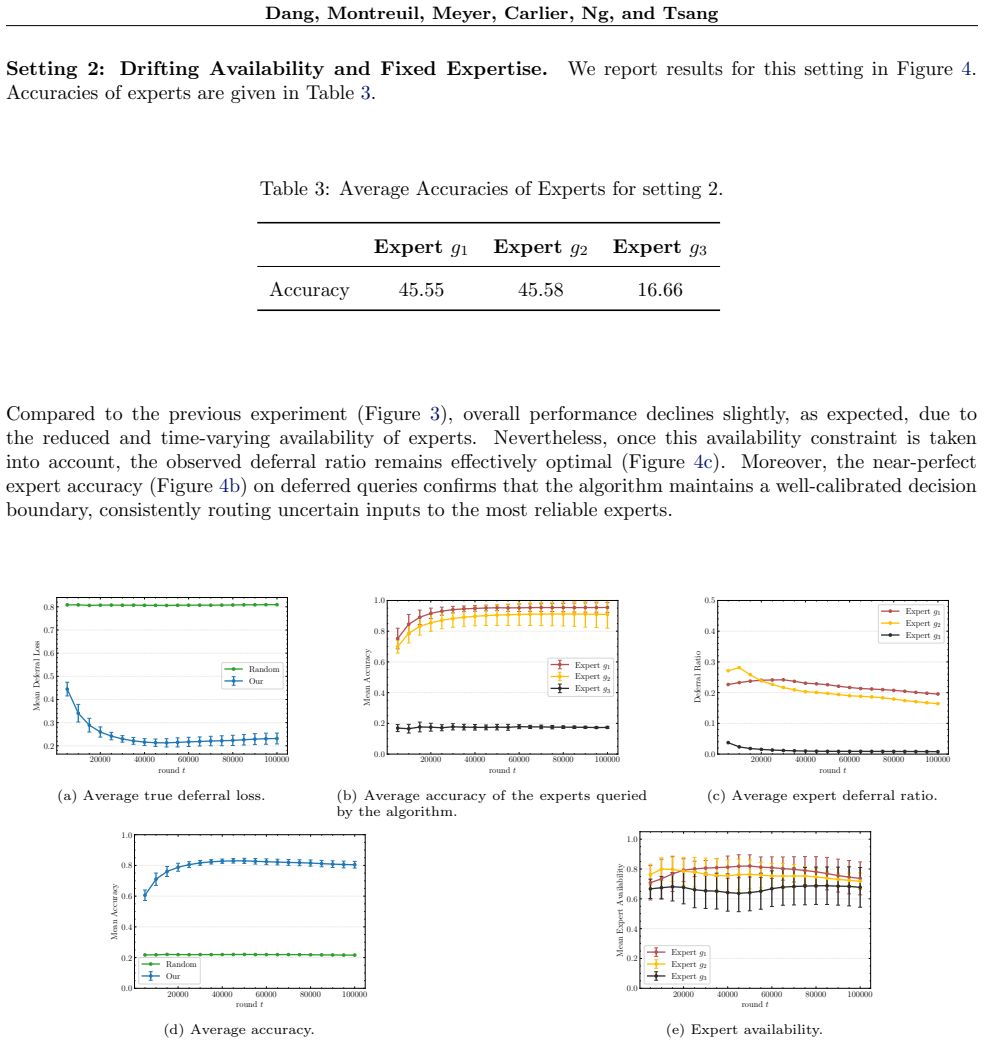



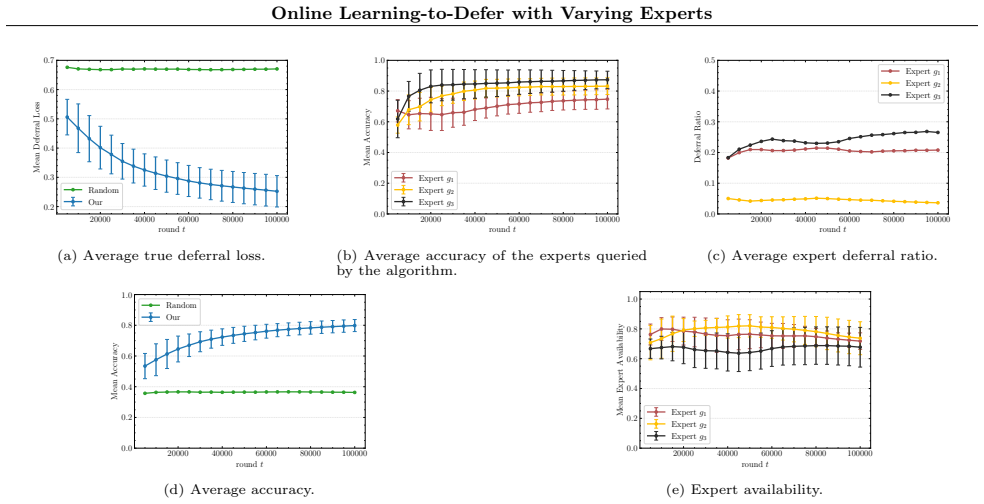
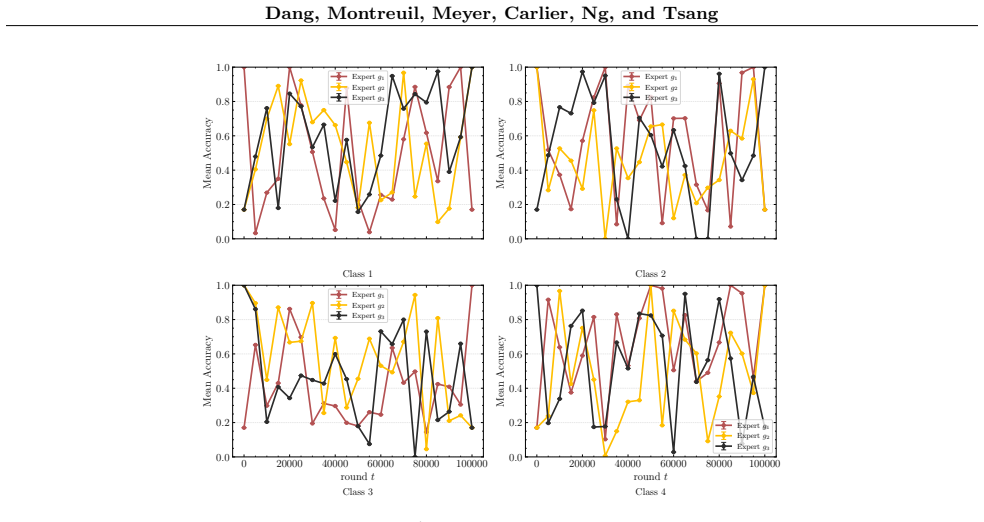

read the original abstract
Learning-to-Defer (L2D) methods route each query either to a predictive model or to external experts. While existing work studies this problem in batch settings, real-world deployments require handling streaming data, changing expert availability, and shifting expert distribution. We introduce the first online L2D algorithm for multiclass classification with bandit feedback and a dynamically varying pool of experts. Our method achieves regret guarantees of $O((n+n_e)T^{2/3})$ in general and $O((n+n_e)\sqrt{T})$ under a low-noise condition, where $T$ is the time horizon, $n$ is the number of labels, and $n_e$ is the number of distinct experts observed across rounds. The analysis builds on novel $\mathcal{H}$-consistency bounds for the online framework, combined with first-order methods for online convex optimization. Experiments on synthetic and real-world datasets demonstrate that our approach effectively extends standard Learning-to-Defer to settings with varying expert availability and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the first online Learning-to-Defer (L2D) algorithm for multiclass classification with bandit feedback and a dynamically varying pool of experts. It claims regret bounds of O((n + n_e) T^{2/3}) in general and O((n + n_e) √T) under a low-noise condition, derived via novel H-consistency bounds combined with first-order online convex optimization methods. Experiments on synthetic and real-world datasets are presented to demonstrate effectiveness in settings with changing expert availability.
Significance. If the regret analysis holds, this constitutes a solid contribution by extending batch L2D to realistic online streaming regimes with varying experts, providing the first such guarantees in the bandit multiclass setting. The technical approach of adapting H-consistency bounds to the online framework is a clear strength, as is the improved √T rate under low noise, which parallels standard results in online learning. The empirical validation supports applicability, though the overall impact would benefit from explicit verification of the low-noise regime in experiments.
major comments (2)
- [§4 (Regret Analysis)] §4 (Regret Analysis): The novel H-consistency bounds are central to both the general T^{2/3} and the improved √T claims; the manuscript must explicitly derive or state the precise conditions (including any dependence on the varying expert pool and bandit feedback) under which these bounds apply, as the current high-level description leaves open whether they hold without additional assumptions.
- [Experiments section] Experiments section: The low-noise condition is required for the O((n + n_e) √T) rate, yet no verification, estimation, or ablation is reported on whether the synthetic or real-world datasets satisfy it; without this, the experiments do not provide evidence that the improved rate is attained or that the general bound is the relevant one.
minor comments (2)
- [Introduction] Introduction: The quantity n_e (number of distinct experts observed across rounds) should be defined at first use with a brief remark on how it is determined in the online stream, to avoid ambiguity for readers.
- [Notation and preliminaries] Notation and preliminaries: Ensure the bandit feedback model (e.g., loss observation only for the chosen action) is restated consistently when transitioning from the L2D deferral decision to the regret definition.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The comments on the regret analysis and experiments are constructive, and we address each point below with plans for clarification in the revised manuscript.
read point-by-point responses
-
Referee: [§4 (Regret Analysis)] §4 (Regret Analysis): The novel H-consistency bounds are central to both the general T^{2/3} and the improved √T claims; the manuscript must explicitly derive or state the precise conditions (including any dependence on the varying expert pool and bandit feedback) under which these bounds apply, as the current high-level description leaves open whether they hold without additional assumptions.
Authors: We agree that the conditions underlying the H-consistency bounds merit a more explicit statement. In the revised manuscript we will expand Section 4 with a dedicated paragraph that derives the bounds from first principles: the surrogate loss is assumed convex and H-consistent with the multiclass 0-1 loss (standard in the batch L2D literature), the online adaptation proceeds via first-order online convex optimization with unbiased loss estimates under bandit feedback, and the dependence on the expert pool appears only through the aggregate quantity n_e (total distinct experts observed). No further assumptions on the arrival process of experts or on the feedback mechanism are required beyond boundedness of the loss and the usual online-convex-optimization step-size conditions. This addition will remove any ambiguity while preserving the stated regret rates. revision: yes
-
Referee: [Experiments section] Experiments section: The low-noise condition is required for the O((n + n_e) √T) rate, yet no verification, estimation, or ablation is reported on whether the synthetic or real-world datasets satisfy it; without this, the experiments do not provide evidence that the improved rate is attained or that the general bound is the relevant one.
Authors: We acknowledge that the experiments section currently contains no explicit check of the low-noise condition. In the revision we will add a short subsection (or appendix paragraph) that reports a simple empirical proxy for noise level on each dataset—for example, the average disagreement rate between the model and the best expert, or a Tsybakov-style noise estimate on the synthetic data. This will allow readers to judge whether the improved √T regime is plausibly active in the reported runs or whether the general T^{2/3} bound is the operative guarantee. The main experimental claims (practical superiority over baselines under varying expert availability) remain valid independently of the noise condition. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The provided abstract and description state that the regret bounds are obtained by building novel H-consistency bounds for the online setting and then applying standard first-order online convex optimization methods. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations are exhibited that would reduce the claimed O((n+ne)T^{2/3}) or O((n+ne)√T) guarantees to the inputs by construction. The analysis is presented as extending prior L2D work with new bounds plus off-the-shelf OCO tools; absent any quoted reduction (e.g., a bound that is tautological with its own fitting procedure), the derivation remains self-contained and independent of the target result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Novel H-consistency bounds exist for the online multiclass deferral setting
- domain assumption Low-noise condition holds for the improved O(sqrt(T)) bound
Reference graph
Works this paper leans on
-
[1]
MIMIC-III, a freely accessible critical care database , volume =
Johnson, Alistair and Pollard, Tom and Shen, Lu and Lehman, Li-wei and Feng, Mengling and Ghassemi, Mohammad and Moody, Benjamin and Szolovits, Peter and Celi, Leo and Mark, Roger , year =. MIMIC-III, a freely accessible critical care database , volume =. Scientific Data , doi =
-
[2]
MIMIC-IV, a freely accessible electronic health record dataset , volume =
Johnson, Alistair and Bulgarelli, Lucas and Shen, Lu and Gayles, Alvin and Shammout, Ayad and Horng, Steven and Pollard, Tom and Moody, Benjamin and Gow, Brian and Lehman, Li-wei and Celi, Leo and Mark, Roger , year =. MIMIC-IV, a freely accessible electronic health record dataset , volume =. Scientific Data , doi =
-
[3]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
SQuAD: 100,000+ Questions for Machine Comprehension of Text , author=. arXiv preprint arXiv:1606.05250 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
A Survey on Human-AI Teaming with Large Pre-Trained Models , author=. 2024 , eprint=
work page 2024
-
[6]
Foundations of machine learning
Mehryar Mohri and Afshin Rostamizadeh and Ameet Talwalkar. Foundations of machine learning. 2012
work page 2012
-
[7]
Advances in Neural Information Processing Systems , volume=
H -Consistency Bounds: Characterization and Extensions , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Combining Human Predictions with Model Probabilities via Confusion Matrices and Calibration , url =
Kerrigan, Gavin and Smyth, Padhraic and Steyvers, Mark , booktitle =. Combining Human Predictions with Model Probabilities via Confusion Matrices and Calibration , url =
-
[10]
International Conference on Artificial Intelligence and Statistics , pages=
Mitigating Underfitting in Learning to Defer with Consistent Losses , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
work page 2024
-
[11]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
Learning to Defer to a Population: A Meta-Learning Approach , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , editor =
work page 2024
-
[12]
Uncertainty in Artificial Intelligence , pages=
Counterfactual inference of second opinions , author=. Uncertainty in Artificial Intelligence , pages=. 2022 , organization=
work page 2022
-
[14]
Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =
Theoretically Grounded Loss Functions and Algorithms for Score-Based Multi-Class Abstention , author =. Proceedings of The 27th International Conference on Artificial Intelligence and Statistics , pages =. 2024 , editor =
work page 2024
-
[15]
The Pascal Visual Object Classes (VOC) challenge , volume =
Everingham, Mark and Van Gool, Luc and Williams, Christopher and Winn, John and Zisserman, Andrew , year =. The Pascal Visual Object Classes (VOC) challenge , volume =. International Journal of Computer Vision , doi =
-
[16]
The Algorithmic Automation Problem: Prediction, Triage, and Human Effort , author=. 2019 , eprint=
work page 2019
-
[17]
Learning Multiple Layers of Features from Tiny Images , author=. 2009 , url=
work page 2009
-
[18]
Sparse spatial autoregressions , journal =
R. Sparse spatial autoregressions , journal =. 1997 , issn =. doi:https://doi.org/10.1016/S0167-7152(96)00140-X , url =
-
[19]
Fisher and the making of maximum likelihood 1912-1922
Ohn Aldrich, R A. Fisher and the making of maximum likelihood 1912-1922. Statistical Science
work page 1912
-
[20]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications , author=. 2017 , eprint=
work page 2017
-
[21]
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks , author=. 2016 , eprint=
work page 2016
-
[22]
Principled Approaches for Learning to Defer with Multiple Experts , author=. ISAIM , year=
-
[23]
Calibration and Consistency of Adversarial Surrogate Losses , author=. 2021 , eprint=
work page 2021
-
[24]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Towards Consistency in Adversarial Classification , author=. 2022 , eprint=
work page 2022
-
[26]
Calibrated Surrogate Losses for Adversarially Robust Classification , author=. 2021 , eprint=
work page 2021
-
[27]
Evasion Attacks against Machine Learning at Test Time , ISBN=
Biggio, Battista and Corona, Igino and Maiorca, Davide and Nelson, Blaine and Šrndić, Nedim and Laskov, Pavel and Giacinto, Giorgio and Roli, Fabio , year=. Evasion Attacks against Machine Learning at Test Time , ISBN=. doi:10.1007/978-3-642-40994-3_25 , booktitle=
-
[28]
Advances in neural information processing systems , volume=
Realizable H -Consistent and Bayes-Consistent Loss Functions for Learning to Defer , author=. Advances in neural information processing systems , volume=
-
[29]
Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages =
Theoretically Grounded Loss Functions and Algorithms for Adversarial Robustness , author =. Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages =. 2023 , editor =
work page 2023
-
[30]
Multi-class support vector machines , author=. 1998 , institution=
work page 1998
-
[31]
Ghosh, Aritra and Kumar, Himanshu and Sastry, P. S. , title =. Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence , pages =. 2017 , publisher =
work page 2017
-
[32]
Cao, Yuzhou and Mozannar, Hussein and Feng, Lei and Wei, Hongxin and An, Bo , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2024 , publisher =
work page 2024
-
[33]
Science and Engineering Ethics , volume=
In AI we trust: ethics, artificial intelligence, and reliability , author=. Science and Engineering Ethics , volume=. 2020 , publisher=
work page 2020
-
[34]
Personal and ubiquitous computing , volume=
The chatbot usability scale: the design and pilot of a usability scale for interaction with AI-based conversational agents , author=. Personal and ubiquitous computing , volume=. 2022 , publisher=
work page 2022
-
[35]
Joshua Strong and Qianhui Men and Alison Noble , booktitle=. Towards Human-. 2024 , url=
work page 2024
-
[36]
Know What You Don't Know: Unanswerable Questions for SQuAD , author=. 2018 , eprint=
work page 2018
-
[37]
The 28th International Conference on Artificial Intelligence and Statistics , year=
A Causal Framework for Evaluating Deferring Systems , author=. The 28th International Conference on Artificial Intelligence and Statistics , year=
-
[38]
Post-hoc estimators for learning to defer to an expert , url =
Narasimhan, Harikrishna and Jitkrittum, Wittawat and Menon, Aditya K and Rawat, Ankit and Kumar, Sanjiv , booktitle =. Post-hoc estimators for learning to defer to an expert , url =
-
[39]
Proceedings of Thirty Sixth Conference on Learning Theory , pages =
On Classification-Calibration of Gamma-Phi Losses , author =. Proceedings of Thirty Sixth Conference on Learning Theory , pages =. 2023 , editor =
work page 2023
-
[40]
Cortes, Corinna and DeSalvo, Giulia and Mohri, Mehryar. Learning with Rejection. Algorithmic Learning Theory. 2016
work page 2016
-
[41]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Mao, Anqi and Mohri, Mehryar and Zhong, Yutao , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[42]
Forty-second International Conference on Machine Learning , year=
A Two-Stage Learning-to-Defer Approach for Multi-Task Learning , author=. Forty-second International Conference on Machine Learning , year=
-
[43]
Threat of adversarial attacks on deep learning in computer vision: A survey , author=. Ieee Access , volume=. 2018 , publisher=
work page 2018
-
[44]
Explaining and Harnessing Adversarial Examples
Explaining and harnessing adversarial examples , author=. arXiv preprint arXiv:1412.6572 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
CAAI Transactions on Intelligence Technology , volume=
A survey on adversarial attacks and defences , author=. CAAI Transactions on Intelligence Technology , volume=. 2021 , publisher=
work page 2021
- [46]
-
[47]
Transactions of the Association for Computational Linguistics , volume =
Jiang, Zhengbao and Araki, Jun and Ding, Haibo and Neubig, Graham , title = ". Transactions of the Association for Computational Linguistics , volume =. 2021 , month =. doi:10.1162/tacl_a_00407 , url =
-
[48]
M. I. Jordan and T. M. Mitchell , title =. Science , volume =. 2015 , doi =. https://www.science.org/doi/pdf/10.1126/science.aaa8415 , abstract =
-
[49]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. arXiv preprint arXiv:1810.04805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
International Conference on Artificial Intelligence and Statistics , year=
Learning to Defer to Multiple Experts: Consistent Surrogate Losses, Confidence Calibration, and Conformal Ensembles , author=. International Conference on Artificial Intelligence and Statistics , year=
-
[51]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Mozannar, Hussein and Sontag, David , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[52]
Controlling the Specificity of Clarification Question Generation
Cao, Yang Trista and Rao, Sudha and Daum \'e III, Hal. Controlling the Specificity of Clarification Question Generation. Proceedings of the 2019 Workshop on Widening NLP. 2019
work page 2019
-
[53]
Rao, Sudha and Daumé, III , year =
-
[54]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author=. 2023 , eprint=
work page 2023
-
[55]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[56]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. arXiv preprint arXiv:1705.03551 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
International Conference on Algorithmic Learning Theory , pages=
Predictor-rejector multi-class abstention: Theoretical analysis and algorithms , author=. International Conference on Algorithmic Learning Theory , pages=. 2024 , organization=
work page 2024
-
[58]
Selective Classification for Deep Neural Networks , url =
Geifman, Yonatan and El-Yaniv, Ran , booktitle =. Selective Classification for Deep Neural Networks , url =
-
[59]
The Journal of Machine Learning Research , author=
Classification with a Reject Option using a Hinge Loss , volume=. The Journal of Machine Learning Research , author=. 2008 , month=jun, pages=
work page 2008
-
[61]
LUKE : Deep Contextualized Entity Representations with Entity-aware Self-attention
Yamada, Ikuya and Asai, Akari and Shindo, Hiroyuki and Takeda, Hideaki and Matsumoto, Yuji. LUKE : Deep Contextualized Entity Representations with Entity-aware Self-attention. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.523
-
[62]
Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015) , pages=
HITSZ-ICRC: Exploiting classification approach for answer selection in community question answering , author=. Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015) , pages=
work page 2015
-
[63]
MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices , author=. 2020 , eprint=
work page 2020
- [64]
- [65]
-
[66]
Artificial Intelligence Review , volume=
Expert finding in community question answering: a review , author=. Artificial Intelligence Review , volume=. 2020 , publisher=
work page 2020
-
[67]
Uncovering the Limits of Adversarial Training against Norm-Bounded Adversarial Examples , author=. ArXiv , year=
-
[68]
Liu, Jessie and Gallego, Blanca and Barbieri, Sebastiano , year =. Incorporating uncertainty in learning to defer algorithms for safe computer-aided diagnosis , volume =. Scientific Reports , doi =
-
[69]
Improving Learning-to-Defer Algorithms Through Fine-Tuning , author=. 2021 , eprint=
work page 2021
-
[70]
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. ArXiv , year=
-
[71]
International conference on Machine learning , pages=
Cross-entropy loss functions: Theoretical analysis and applications , author=. International conference on Machine learning , pages=. 2023 , organization=
work page 2023
-
[72]
Constructive Approximation , year=
How to Compare Different Loss Functions and Their Risks , author=. Constructive Approximation , year=
-
[73]
Transactions of the Association for Computational Linguistics , volume=
Natural Questions: a Benchmark for Question Answering Research , author=. Transactions of the Association for Computational Linguistics , volume=
-
[74]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[75]
Advances in neural information processing systems , volume=
Generalized cross entropy loss for training deep neural networks with noisy labels , author=. Advances in neural information processing systems , volume=
-
[76]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. arXiv preprint arXiv:1809.09600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
arXiv preprint arXiv:1606.03126 , year=
Key-value memory networks for directly reading documents , author=. arXiv preprint arXiv:1606.03126 , year=
-
[78]
arXiv preprint arXiv:1611.01603 , year=
Bidirectional attention flow for machine comprehension , author=. arXiv preprint arXiv:1611.01603 , year=
-
[79]
arXiv preprint arXiv:1704.00051 , year=
Reading Wikipedia to Answer Open-Domain Questions , author=. arXiv preprint arXiv:1704.00051 , year=
-
[80]
arXiv preprint arXiv:1707.07328 , year=
Adversarial Examples for Evaluating Reading Comprehension Systems , author=. arXiv preprint arXiv:1707.07328 , year=
-
[81]
arXiv preprint arXiv:1908.07125 , year=
Universal Adversarial Triggers for Attacking and Analyzing NLP , author=. arXiv preprint arXiv:1908.07125 , year=
-
[82]
Convexity, Classification, and Risk Bounds , volume =
Bartlett, Peter and Jordan, Michael and McAuliffe, Jon , year =. Convexity, Classification, and Risk Bounds , volume =. Journal of the American Statistical Association , doi =
-
[83]
The Woman Worked as a Babysitter: On Biases in Language Generation , author=. 2019 , eprint=
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.