Recognition: 2 theorem links
· Lean TheoremTrust the Batch, On- or Off-Policy: Adaptive Policy Optimization for RL Post-Training
Pith reviewed 2026-05-13 05:28 UTC · model grok-4.3
The pith
The normalized effective sample size of each batch's policy ratios adaptively replaces fixed clipping and removes multiple hyper-parameters in RL post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The normalized effective sample size of the policy-ratio distribution in each batch serves as a reliable data-driven proxy that replaces fixed clipping, caps the score-function weight, and controls the strength of an off-policy regularizer, allowing the update to stay close to the usual on-policy score-function update when ratios are nearly uniform and to tighten automatically when stale or mismatched data cause ratio concentration while retaining a nonzero learning signal on high-ratio tokens.
What carries the argument
the normalized effective sample size of the policy-ratio distribution in each batch, which replaces fixed clipping, caps the score-function weight, and sets the strength of an off-policy regularizer
If this is right
- The update stays close to the usual on-policy score-function update when ratios are nearly uniform.
- It tightens automatically when stale or mismatched data cause ratio concentration.
- It retains a nonzero learning signal on high-ratio tokens.
- The method matches or exceeds tuned baselines across a wide range of settings.
- No new objective hyper-parameters are introduced and several existing ones are removed.
Where Pith is reading between the lines
- The approach may reduce the tuning burden when scaling RL post-training to new tasks or larger models.
- Batch-level statistics such as effective sample size could serve as a general mechanism for adapting other objectives that mix on- and off-policy signals.
- Similar adaptive use of ratio distributions might improve stability in sequential decision algorithms outside standard RL post-training.
Load-bearing premise
The normalized effective sample size of the policy-ratio distribution in each batch reliably captures both the trust-region violation risk and the off-policy data reliability without introducing new instabilities or requiring hidden tuning.
What would settle it
A controlled experiment in a high-mismatch setting where the ESS-based adaptive method performs measurably worse than carefully tuned baselines that use fixed clipping and regularizers.
Figures
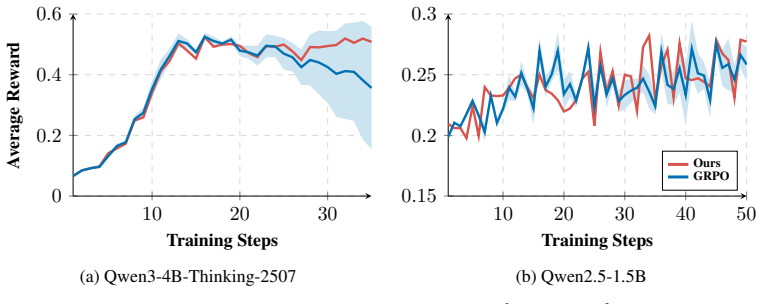
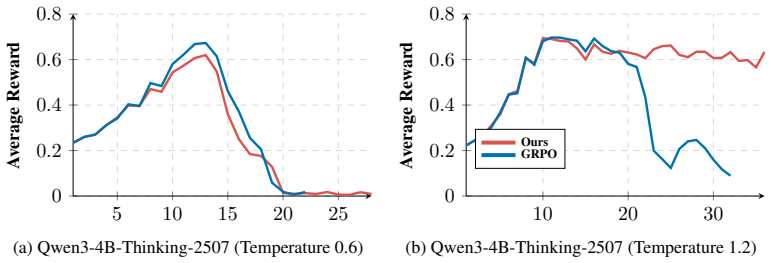
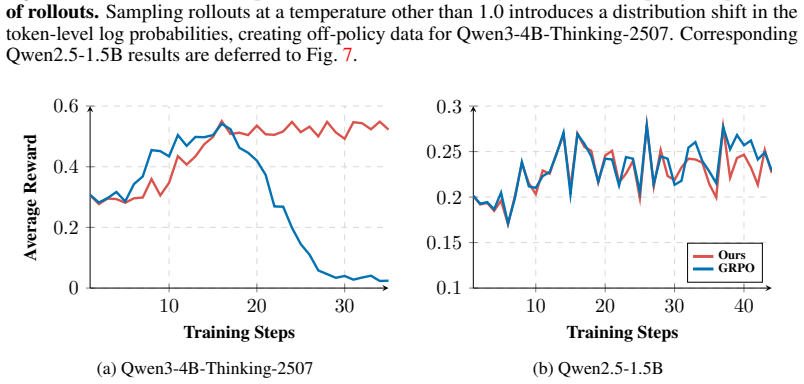
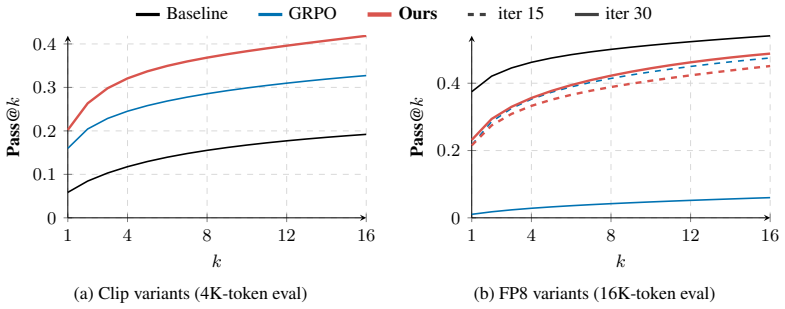
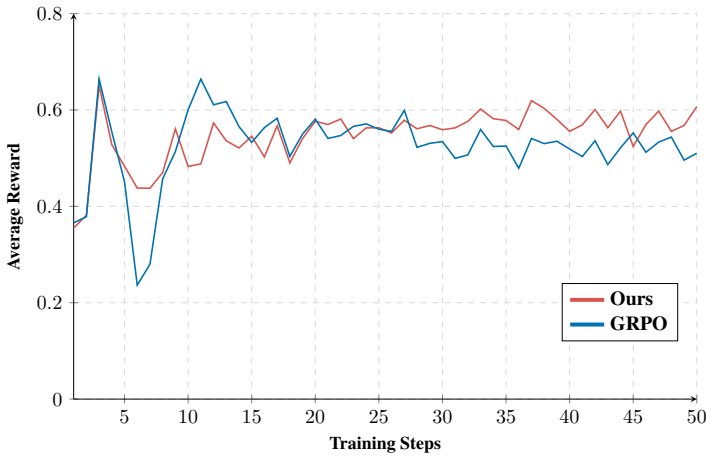
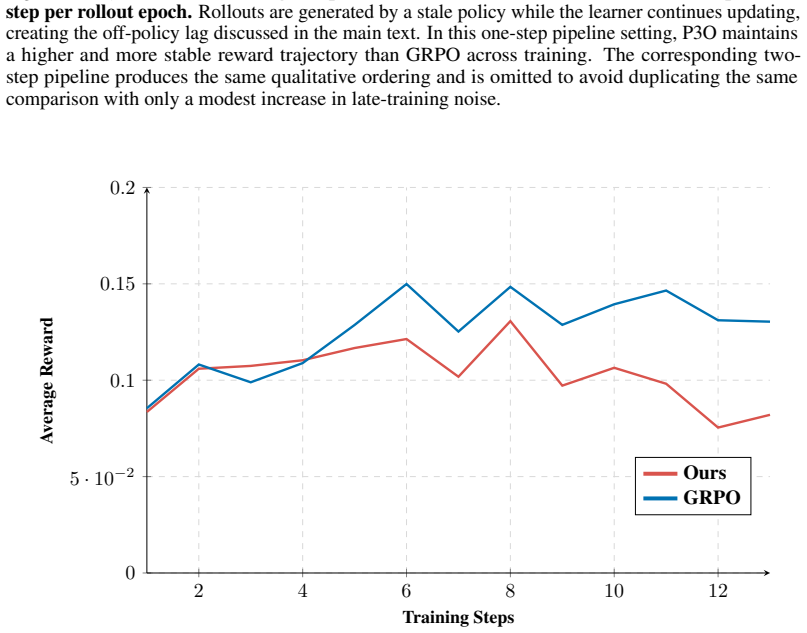


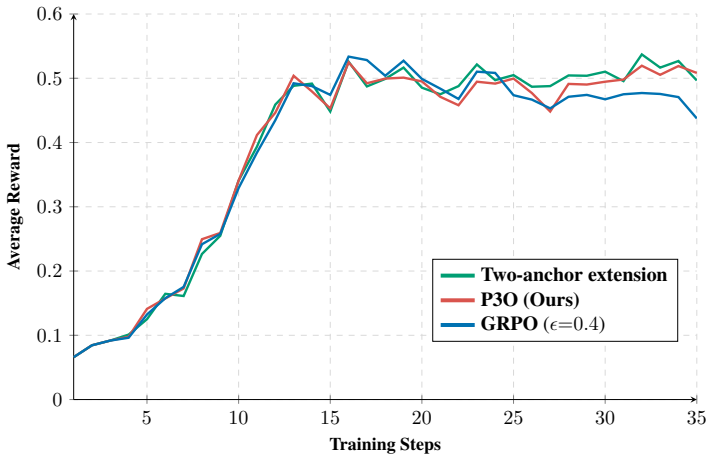
read the original abstract
Reinforcement learning is structurally harder than supervised learning because the policy changes the data distribution it learns from. The resulting fragility is especially visible in large-model training, where the training and rollout systems differ in numerical precision, sampling, and other implementation details. Existing methods manage this fragility by adding hyper-parameters to the training objective, which makes the algorithm more sensitive to its configuration and requires retuning whenever the task, model scale, or distribution mismatch changes. This fragility traces to two concerns that current objectives entangle through hyper-parameters set before training begins: a trust-region concern, that updates should not move the policy too far from its current value, and an off-policy concern, that data from older or different behavior policies should influence the update only to the extent that it remains reliable. Neither concern is a constant to set in advance, and their severity is reflected in the policy-ratio distribution of the current batch. We present a simple yet effective batch-adaptive objective that replaces fixed clipping with the normalized effective sample size of the policy ratios. The same statistic caps the score-function weight and sets the strength of an off-policy regularizer, so the update stays close to the usual on-policy score-function update when ratios are nearly uniform, and tightens automatically when stale or mismatched data cause ratio concentration, while retaining a nonzero learning signal on high-ratio tokens. Experiments across a wide range of settings show that our method matches or exceeds tuned baselines, introducing no new objective hyper-parameters and removing several existing ones. The code is available at https://github.com/FeynRL-project/FeynRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a batch-adaptive objective for RL post-training of large models that replaces fixed clipping and several hyperparameters with the normalized effective sample size (ESS) of the per-batch policy-ratio distribution; this single statistic is used both to cap score-function weights (enforcing a trust region) and to modulate an off-policy regularizer, so that the update remains close to standard on-policy score-function gradient when ratios are uniform and automatically tightens under ratio concentration from stale or mismatched data. Experiments across diverse settings are reported to match or exceed tuned baselines while introducing no new objective hyperparameters.
Significance. If the central claim holds, the approach would meaningfully reduce hyperparameter sensitivity in RL post-training for large models, where numerical and distributional mismatches between training and rollout systems are common. The public code release is a clear strength that supports reproducibility and further testing of the batch-adaptive mechanism.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): the central claim that normalized ESS simultaneously replaces clipping and sets the off-policy regularizer without new hyperparameters rests on the assumption that ESS = (∑ r_i)^2 / ∑ r_i^2 (normalized by batch size) reliably proxies both trust-region violation risk and data reliability. No derivation or ablation is provided showing how this scalar is exactly inserted into the objective or normalized, leaving open the possibility that the construction reduces to a reparameterized form of existing clipping or regularization terms.
- [§4] §4 (experiments): the reported matches to tuned baselines lack error bars, details on how ESS is computed across batches, and ablations isolating the effect of the ESS-based capping versus the regularizer modulation. Without these, it is impossible to verify that the method avoids the instabilities the skeptic notes for heavy-tailed ratio regimes typical in LLM post-training.
minor comments (1)
- [Abstract] The abstract states that the code is available at the given GitHub link; please confirm the repository contains the exact scripts used for the reported experiments and any additional implementation details on ESS normalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications from the existing text and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the central claim that normalized ESS simultaneously replaces clipping and sets the off-policy regularizer without new hyperparameters rests on the assumption that ESS = (∑ r_i)^2 / ∑ r_i^2 (normalized by batch size) reliably proxies both trust-region violation risk and data reliability. No derivation or ablation is provided showing how this scalar is exactly inserted into the objective or normalized, leaving open the possibility that the construction reduces to a reparameterized form of existing clipping or regularization terms.
Authors: Section 3 derives the normalized ESS explicitly as ESS = (1/N) * (∑ r_i)^2 / ∑ r_i^2, where r_i denotes the per-token policy ratio in the current batch and N is the batch size. This scalar is inserted into the objective by (i) capping the score-function importance weights at 1/ESS to enforce a per-batch trust region and (ii) scaling the coefficient of the off-policy regularizer by (1 - ESS). When the ratio distribution is uniform, ESS approaches 1 and the update recovers the standard on-policy score-function gradient; when ratios concentrate due to staleness or mismatch, ESS drops and both the cap and regularizer tighten automatically. The construction is not a reparameterization of fixed clipping because the threshold is computed from the empirical second moment of the batch ratios rather than a preset hyperparameter. We will add an explicit ablation that isolates the capping term from the regularizer modulation to further demonstrate their distinct contributions. revision: partial
-
Referee: [§4] §4 (experiments): the reported matches to tuned baselines lack error bars, details on how ESS is computed across batches, and ablations isolating the effect of the ESS-based capping versus the regularizer modulation. Without these, it is impossible to verify that the method avoids the instabilities the skeptic notes for heavy-tailed ratio regimes typical in LLM post-training.
Authors: We agree that error bars, explicit computation details, and component ablations are required for full verification. The revised manuscript will report mean performance with standard error bars over multiple random seeds for every experiment. We will add a dedicated paragraph in §4 describing the per-batch ESS computation (ratios are evaluated on the sampled tokens, then normalized ESS is obtained exactly as defined in §3). We will also include ablations that disable the ESS-based weight cap and the regularizer modulation independently. For heavy-tailed regimes, the adaptive tightening via low ESS is intended to mitigate instability; we will supplement the experiments with plots of per-batch ratio histograms and ESS values to illustrate this behavior under the conditions noted. revision: yes
Circularity Check
No circularity: objective defined directly from batch statistics
full rationale
The paper proposes an explicit batch-adaptive objective that computes normalized effective sample size (ESS) from the current batch's policy ratios and uses that scalar to cap score-function weights and modulate an off-policy regularizer. This is a direct construction from observable batch data rather than a fitted parameter or self-referential definition. No step claims a 'prediction' that reduces to the input by construction, no uniqueness theorem is imported via self-citation, and the provided text contains no load-bearing self-citations. The derivation chain remains self-contained: the method is presented as a heuristic that automatically tightens when ratios concentrate, with empirical validation against baselines, without tautological reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Policy gradient theorem applies to the score-function updates used here
- domain assumption Normalized effective sample size of policy ratios accurately reflects both trust-region and off-policy reliability
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesP3O replaces the fixed clip in Eq. (4) with two terms whose strength is set by the batch ESS... LP3O(θ) = ... −sg(min{ρt, eB}) logπθ(yt|c<t)A + (1−eB) KL(πθ ∥ πb)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection refinesThe same statistic caps the score-function weight and sets the strength of an off-policy regularizer... introducing no new objective hyper-parameters
Reference graph
Works this paper leans on
-
[1]
Amo-bench: Large language models still struggle in high school math competitions, 2025
Shengnan An, Xunliang Cai, Xuezhi Cao, Xiaoyu Li, Yehao Lin, Junlin Liu, Xinxuan Lv, Dan Ma, Xuanlin Wang, Ziwen Wang, and Shuang Zhou. Amo-bench: Large language models still struggle in high school math competitions, 2025. 9
work page 2025
-
[2]
What matters for on-policy deep actor-critic methods? A large-scale study
Marcin Andrychowicz, Anton Raichuk, Piotr Sta´nczyk, Manu Orsini, Sertan Girgin, Raphaël Marinier, Léonard Hussenot, Matthieu Geist, Olivier Pietquin, Marcin Michalski, Sylvain Gelly, and Olivier Bachem. What matters for on-policy deep actor-critic methods? A large-scale study. InInternational Conference on Learning Representations (ICLR), 2021. 1
work page 2021
-
[3]
Zhepeng Cen, Yao Liu, Siliang Zeng, Pratik Chaudhari, Huzefa Rangwala, George Karypis, and Rasool Fakoor. Bridging the training-inference gap in LLMs by leveraging self-generated tokens.Transactions on Machine Learning Research, 2025. 4
work page 2025
-
[4]
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.Nature, 645:633–638, 2025. 1
work page 2025
-
[5]
Implementation matters in deep policy gradients: A case study on PPO and TRPO
Logan Engstrom, Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Firdaus Janoos, Larry Rudolph, and Aleksander Madry. Implementation matters in deep policy gradients: A case study on PPO and TRPO. InInternational Conference on Learning Representations (ICLR),
-
[6]
IMPALA: Scalable distributed deep-RL with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, V olodymyr Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. IMPALA: Scalable distributed deep-RL with importance weighted actor-learner architectures. InInternational Conference on Machine Learning, pages 1407–1416, 2018. 2
work page 2018
-
[7]
Rasool Fakoor, Pratik Chaudhari, and Alexander J. Smola. P3O: policy-on policy-off pol- icy optimization. InProceedings of the Thirty-Fifth Conference on Uncertainty in Artificial Intelligence, UAI 2019, page 371, 2019. 2, 5
work page 2019
-
[8]
Rasool Fakoor, Pratik Chaudhari, and Alexander J Smola. Ddpg++: Striving for simplicity in continuous-control off-policy reinforcement learning.arXiv:2006.15199, 2020. 1
-
[9]
Rasool Fakoor, Pratik Chaudhari, Stefano Soatto, and Alexander J. Smola. Meta-q-learning. In ICLR, 2020. 2, 4
work page 2020
-
[10]
Lipton, Pratik Chaudhari, and Alexander J
Rasool Fakoor, Jonas Mueller, Zachary C. Lipton, Pratik Chaudhari, and Alexander J. Smola. Time-varying propensity score to bridge the gap between the past and present. InICLR, 2024. 2, 4
work page 2024
-
[11]
Rasool Fakoor, Jonas W Mueller, Kavosh Asadi, Pratik Chaudhari, and Alexander J Smola. Continuous doubly constrained batch reinforcement learning.Advances in Neural Information Processing Systems, 34:11260–11273, 2021. 2
work page 2021
-
[12]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InAAAI Conference on Artificial Intelligence,
-
[13]
Batch size-invariance for policy optimization
Jacob Hilton, Karl Cobbe, and John Schulman. Batch size-invariance for policy optimization. InAdvances in Neural Information Processing Systems, volume 35, pages 17086–17098, 2022. 2, 6
work page 2022
-
[14]
The 37 implementation details of proximal policy optimization
Shengyi Huang, Rousslan Fernand Julien Dossa, Antonin Raffin, Anssi Kanervisto, and Weixun Wang. The 37 implementation details of proximal policy optimization. InICLR Blog Track,
-
[15]
A note on importance sampling using standardized weights.Technical Report 348, 1992
Augustine Kong. A note on importance sampling using standardized weights.Technical Report 348, 1992. 2
work page 1992
-
[16]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems.arXiv:2005.01643, May 2020. 2 10
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[17]
Budgeting counterfactual for offline rl
Yao Liu, Pratik Chaudhari, and Rasool Fakoor. Budgeting counterfactual for offline rl. In Advances in Neural Information Processing Systems, volume 36, pages 5729–5751, 2023. 2
work page 2023
-
[18]
Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl, 2025
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Erran Li, Raluca Ada Popa, and Ion Stoica. Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl, 2025. Notion Blog. 7
work page 2025
-
[19]
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, and Fuli Luo. Stabilizing MoE reinforcement learning by aligning training and inference routers.arXiv preprint arXiv:2510.11370, 2025. 2
-
[20]
2023 american mathematics competitions (amc 10 and amc 12)
Mathematical Association of America. 2023 american mathematics competitions (amc 10 and amc 12). https://huggingface.co/datasets/math-ai/amc23, 2023. Dataset curated by the Math-AI community. 9
work page 2023
-
[21]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedba...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Penghui Qi, Zichen Liu, Xiangxin Zhou, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Defeating the training-inference mismatch via FP16.arXiv preprint arXiv:2510.26788, 2025. 2
-
[23]
Springer Science & Business Media, 2013
Sidney I Resnick.A probability path. Springer Science & Business Media, 2013. 4
work page 2013
-
[24]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational Conference on Machine Learning (ICML), pages 1889–1897, 2015. 2, 3
work page 2015
-
[25]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY , USA, 2020. Curran Associates Inc. 1, 4
work page 2020
-
[28]
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. MIT Press, 2nd edition, 2018. 3
work page 2018
-
[29]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024. 7
work page 2024
- [30]
-
[31]
Fp8 quantization — vllm documentation
vLLM Team. Fp8 quantization — vllm documentation. https://docs.vllm.ai/en/v0.5. 0.post1/quantization/fp8.html, 2024. Accessed: 2026-05-06. 8
work page 2024
- [32]
-
[33]
Haocheng Xi, Charlie Ruan, Peiyuan Liao, Yujun Lin, Han Cai, Yilong Zhao, Shuo Yang, Kurt Keutzer, Song Han, and Ligeng Zhu. Jet-rl: Enabling on-policy fp8 reinforcement learning with unified training and rollout precision flow, 2026. 8
work page 2026
-
[34]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, 11 Jingjing Liu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
American invitational mathematics examination (aime) 2024,
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024,
work page 2024
-
[36]
American invitational mathematics examination (aime) 2025,
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025,
work page 2025
-
[37]
American invitational mathematics examination (aime) 2026,
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2026,
work page 2026
-
[38]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019. 1, 4 12 Algorithm 1GRPO Require:Policyπ θ; group sizeG; clip(ϵ ℓ, ϵh); entropy coefficientβ ent Rollout:for each prompt xp, sample G comple...
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.