Recognition: no theorem link
Scalable Token-Level Hallucination Detection in Large Language Models
Pith reviewed 2026-05-13 05:44 UTC · model grok-4.3
The pith
A training pipeline lets even small models detect token-level hallucinations in LLM reasoning better than much larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TokenHD supplies a complete pipeline that first uses a scalable data engine to synthesize hallucination annotations and then applies an importance-weighted training recipe, allowing the resulting detector to label errors token by token in unrestricted LLM output and to reach performance levels that increase reliably with detector size.
What carries the argument
The TokenHD pipeline, which combines a scalable synthesis engine for hallucination annotations with an importance-weighted training procedure to produce detectors that label individual tokens in free-form text without any step segmentation.
If this is right
- Detectors can scan free-form text outputs without any predefined step breaks or reformatting.
- Detection accuracy increases steadily as the detector model size grows from 0.6B to 8B parameters.
- A 0.6B detector trained this way can exceed the hallucination detection performance of much larger reasoning models.
- The detectors maintain effectiveness across a range of practical application scenarios.
- Additional training adjustments can further improve performance on new domains.
Where Pith is reading between the lines
- If the synthesis method produces unbiased labels, the same engine could be adapted to flag other error types such as factual mistakes outside reasoning chains.
- Placing the detector inside the generation loop could enable early correction of erroneous tokens before full outputs are produced.
- The observed scaling suggests that detectors at 70B or beyond might reach levels of reliability sufficient for high-stakes verification tasks.
- Combining token-level signals with existing sentence-level or external-knowledge checks could yield hybrid systems with higher overall coverage.
Load-bearing premise
The annotations created by the data engine accurately reflect genuine hallucinations that occur in real reasoning outputs rather than artifacts introduced during synthesis.
What would settle it
A fresh test set of human-annotated token errors drawn from actual LLM reasoning traces where the trained detector shows markedly lower agreement with the human labels than the paper reports would falsify the performance claim.
Figures


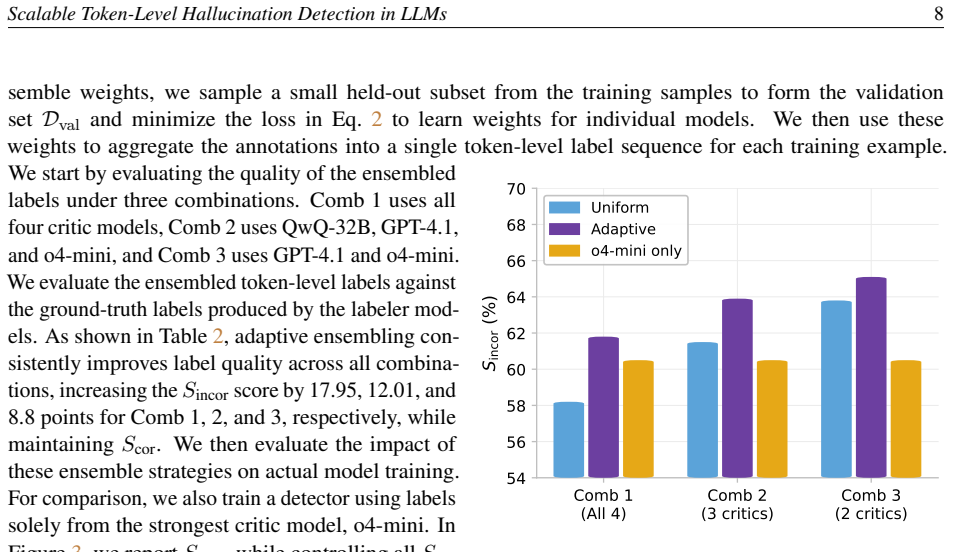

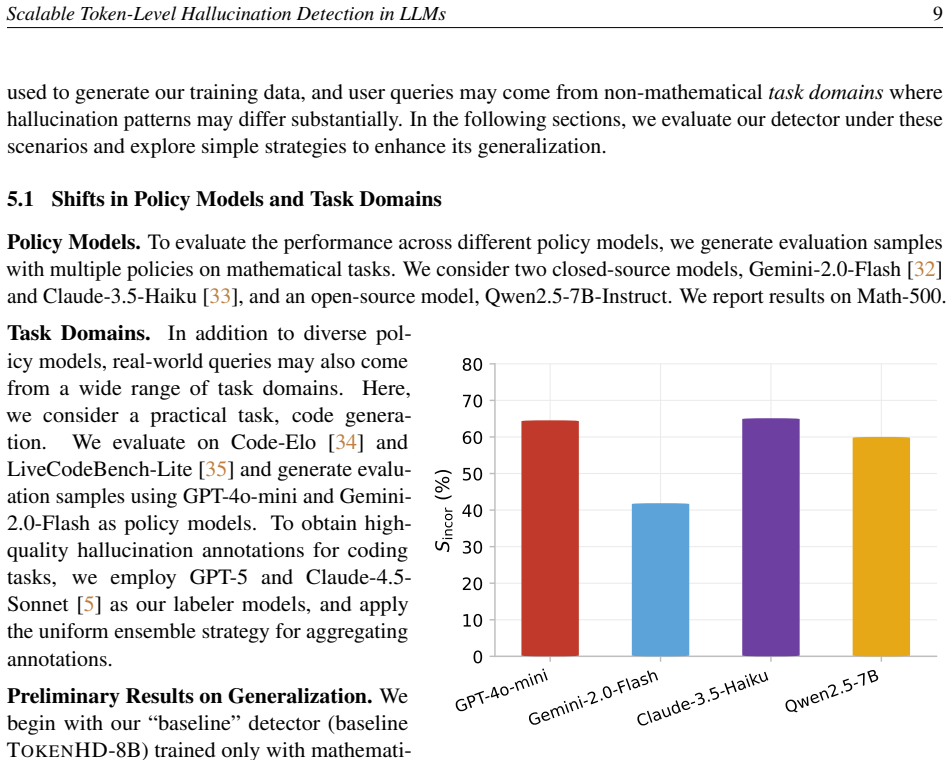





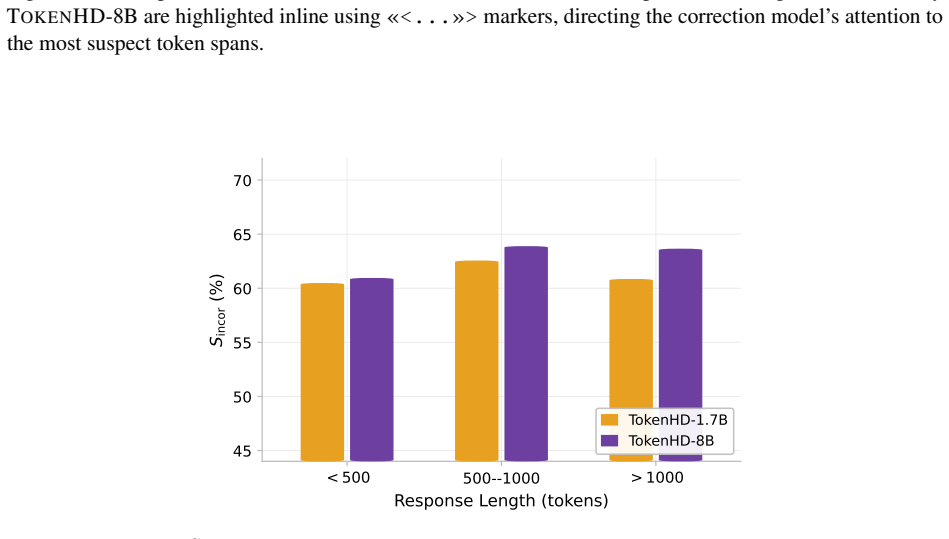
read the original abstract
Large language models (LLMs) have demonstrated remarkable capabilities, but they still frequently produce hallucinations. These hallucinations are difficult to detect in reasoning-intensive tasks, where the content appears coherent but contains errors like logical flaws and unreliable intermediate results. While step-level analysis is commonly used to detect internal hallucinations, it suffers from limited granularity and poor scalability due to its reliance on step segmentation. To address these limitations, we propose TokenHD, a holistic pipeline for training token-level hallucination detectors. Specifically, TokenHD consists of a scalable data engine for synthesizing large-scale hallucination annotations along with a training recipe featuring an importance-weighted strategy for robust model training. To systematically assess the detection performance, we also provide a rigorous evaluation protocol. Through training within TokenHD, our detector operates directly on free-form text to identify hallucinations, eliminating the need for predefined step segmentation or additional text reformatting. Our experiments show that even a small detector (0.6B) achieves substantial performance gains after training, surpassing much larger reasoning models (e.g., QwQ-32B), and detection performance scales consistently with model size from 0.6B to 8B. Finally, we show that our detector can generalize well across diverse practical scenarios and explore strategies to further enhance its cross-domain generalization capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TokenHD, a pipeline for training token-level hallucination detectors on free-form LLM outputs. It consists of a scalable synthetic data engine to generate large-scale token-level hallucination annotations, combined with an importance-weighted training recipe, and a rigorous evaluation protocol. The central claims are that even a 0.6B-parameter detector trained via TokenHD substantially outperforms much larger reasoning models (e.g., QwQ-32B) on hallucination detection in reasoning-intensive tasks, that detection performance scales consistently with model size from 0.6B to 8B, and that the detector generalizes well across diverse practical scenarios.
Significance. If the synthetic annotations prove faithful to genuine logical and factual errors, the work would offer a scalable alternative to step-level detection methods, enabling fine-grained, segmentation-free hallucination detection. The reported outperformance by small models and consistent scaling would represent a notable empirical finding for LLM reliability, provided the evaluation protocol includes appropriate controls and the results hold beyond the synthetic distribution.
major comments (1)
- [§3] §3 (TokenHD Pipeline, data engine subsection): The synthesis process for token-level hallucination annotations is not validated against human-annotated reasoning errors (no reported inter-annotator agreement, human-synthetic label correlation, or ablation removing synthesis-specific features). This is load-bearing for the central claim because the headline result (0.6B detector surpassing QwQ-32B) assumes the labels reflect real errors rather than artifacts such as unnatural token distributions or stylistic cues introduced by the engine.
minor comments (1)
- [Abstract] Abstract: The performance claims would be strengthened by including at least one concrete metric (e.g., F1 or AUC) and the exact baselines used, rather than qualitative statements such as 'substantial performance gains'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the importance of validating the synthetic annotation process. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (TokenHD Pipeline, data engine subsection): The synthesis process for token-level hallucination annotations is not validated against human-annotated reasoning errors (no reported inter-annotator agreement, human-synthetic label correlation, or ablation removing synthesis-specific features). This is load-bearing for the central claim because the headline result (0.6B detector surpassing QwQ-32B) assumes the labels reflect real errors rather than artifacts such as unnatural token distributions or stylistic cues introduced by the engine.
Authors: We agree that the absence of direct human validation for the synthetic labels represents a gap in the current manuscript, and that this validation is important for supporting the claim that small detectors outperform larger reasoning models on genuine errors. In the revised version, we will expand §3 with a new human evaluation subsection. This will include: (1) sampling 500 synthetic instances across reasoning tasks, (2) recruiting multiple expert annotators to label token-level hallucinations using guidelines aligned with the synthesis engine, (3) reporting inter-annotator agreement via Fleiss' kappa, and (4) computing correlation metrics (e.g., token-level accuracy and Cohen's kappa) between human and synthetic labels. We will also add an ablation study training a detector variant on data stripped of synthesis-specific features (such as targeted error injection patterns) to quantify their contribution versus potential artifacts. These additions will directly address concerns about label fidelity and strengthen the empirical foundation for the scaling and outperformance results. revision: yes
Circularity Check
No circularity in empirical pipeline or claims
full rationale
The paper describes an empirical pipeline (TokenHD) for synthesizing token-level hallucination annotations via a data engine, followed by model training with an importance-weighted strategy and evaluation under a stated protocol. No mathematical derivations, equations, or first-principles results appear that reduce performance claims to fitted parameters, self-definitions, or self-citation chains. The scaling results and comparisons (e.g., 0.6B detector vs. larger models) are presented as outcomes of training on the synthesized data and testing, not tautological. The work is self-contained against its own benchmarks and external evaluation protocol, with no load-bearing steps that collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hallucinations in reasoning tasks can be reliably synthesized at token granularity to create training data
invented entities (1)
-
TokenHD pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025. 1, 4.1
work page 2025
-
[3]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [5]
-
[6]
Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023. 1
work page 2023
-
[7]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025. 1, 6
work page 2025
-
[8]
Why Language Models Hallucinate
Adam Tauman Kalai, Ofir Nachum, Santosh S Vempala, and Edwin Zhang. Why language models hallucinate.arXiv preprint arXiv:2509.04664, 2025. 1, 6
work page internal anchor Pith review arXiv 2025
-
[9]
Hallucination detection: Robustly discerning reliable answers in large language models
Yuyan Chen, Qiang Fu, Yichen Yuan, Zhihao Wen, Ge Fan, Dayiheng Liu, Dongmei Zhang, Zhixu Li, and Yanghua Xiao. Hallucination detection: Robustly discerning reliable answers in large language models. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management, pages 245–255, 2023. 1, 6 Scalable Token-Level Hallucination ...
work page 2023
-
[10]
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 9004–9017, 2023. 1, 6
work page 2023
-
[11]
Oscar Obeso, Andy Arditi, Javier Ferrando, Joshua Freeman, Cameron Holmes, and Neel Nanda. Real-time detection of hallucinated entities in long-form generation.arXiv preprint arXiv:2509.03531,
-
[12]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1), 2023. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366,
work page internal anchor Pith review arXiv
-
[14]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023. 1, 6
work page 2023
-
[15]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024. 1, 6
work page 2024
-
[16]
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning.arXiv preprint arXiv:2501.07301, 2025. 1, 6
-
[17]
Lillicrap, Kenji Kawaguchi, and Michael Shieh
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning.arXiv preprint arXiv:2405.00451, 2024. 1
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 4.1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874, 2021. 4.1, 4.1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
arXiv preprint arXiv:2505.16400 , year=
Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Acereason-nemotron: Advancing math and code reasoning through reinforcement learning.arXiv preprint arXiv:2505.16400, 2025. 4.1
-
[21]
Marthe Ballon, Brecht Verbeken, Vincent Ginis, and Andres Algaba
Alon Albalak, Duy Phung, Nathan Lile, Rafael Rafailov, Kanishk Gandhi, Louis Castricato, Anikait Singh, Chase Blagden, Violet Xiang, Dakota Mahan, et al. Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models.arXiv preprint arXiv:2502.17387, 2025. 4.1
-
[22]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Qwq-32b: Embracing the power of reinforcement learning, 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, 2025. 4.1 Scalable Token-Level Hallucination Detection in LLMs13
work page 2025
-
[24]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. 4.1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Introducing openai o3 and o4-mini, 2025
OpenAI Team. Introducing openai o3 and o4-mini, 2025. 4.1, 4.1
work page 2025
- [26]
- [27]
-
[28]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
work page 2024
-
[29]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024. 4.1
work page 2024
-
[30]
Finqa: A dataset of numerical reasoning over financial data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan R Routledge, et al. Finqa: A dataset of numerical reasoning over financial data. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3697–3711, 2021. 4.1
work page 2021
- [31]
-
[32]
Introducing gemini 2.0: our new ai model for the agentic era, 2024
Google. Introducing gemini 2.0: our new ai model for the agentic era, 2024. 5.1
work page 2024
- [33]
-
[34]
Shanghaoran Quan, Jiaxi Yang, Bowen Yu, Bo Zheng, Dayiheng Liu, An Yang, Xuancheng Ren, Bofei Gao, Yibo Miao, Yunlong Feng, et al. Codeelo: Benchmarking competition-level code generation of llms with human-comparable elo ratings.arXiv preprint arXiv:2501.01257, 2025. 5.1
-
[35]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024. 5.1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Wasi Uddin Ahmad, Sean Narenthiran, Somshubra Majumdar, Aleksander Ficek, Siddhartha Jain, Jocelyn Huang, Vahid Noroozi, and Boris Ginsburg. Opencodereasoning: Advancing data distillation for competitive coding.arXiv preprint arXiv:2504.01943, 2025. 5.2
-
[37]
Unlocking efficient long-to-short llm reasoning with model merging.arXiv preprint arXiv:2503.20641,
Han Wu, Yuxuan Yao, Shuqi Liu, Zehua Liu, Xiaojin Fu, Xiongwei Han, Xing Li, Hui-Ling Zhen, Tao Zhong, and Mingxuan Yuan. Unlocking efficient long-to-short llm reasoning with model merging. arXiv preprint arXiv:2503.20641, 2025. 5.2
-
[38]
Mitchell Wortsman, Gabriel Ilharco, Samir Ya Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational conference on machine learning, pages 23965–23998. P...
work page 2022
-
[39]
Editing Models with Task Arithmetic
Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Han- naneh Hajishirzi, and Ali Farhadi. Editing models with task arithmetic.arXiv preprint arXiv:2212.04089,
work page internal anchor Pith review arXiv
-
[40]
5.2 Scalable Token-Level Hallucination Detection in LLMs14
-
[41]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in Neural Information Processing Systems, 36:7093–7115, 2023. 5.2
work page 2023
-
[42]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InForty-first International Conference on Machine Learning, 2024. 5.2
work page 2024
-
[43]
Zhitao He, Sandeep Polisetty, Zhiyuan Fan, Yuchen Huang, Shujin Wu, and Yi R Fung. Mmboundary: Advancing mllm knowledge boundary awareness through reasoning step confidence calibration. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16427–16444, 2025. 6
work page 2025
-
[44]
Xintong Wang, Jingheng Pan, Liang Ding, and Chris Biemann. Mitigating hallucinations in large vision-language models with instruction contrastive decoding.arXiv preprint arXiv:2403.18715, 2024. 6
-
[45]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474,
-
[46]
R-tuning: Instructing large language models to say ‘i don’t know’
Hanning Zhang, Shizhe Diao, Yong Lin, Yi Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Instructing large language models to say ‘i don’t know’. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7106...
work page 2024
-
[47]
Yuji Zhang, Sha Li, Cheng Qian, Jiateng Liu, Pengfei Yu, Chi Han, Yi R Fung, Kathleen McKeown, Chengxiang Zhai, Manling Li, et al. The law of knowledge overshadowing: Towards understanding, predicting, and preventing llm hallucination.arXiv preprint arXiv:2502.16143, 2025. 6
-
[48]
Weilei He, Feng Ju, Zhiyuan Fan, Rui Min, Minhao Cheng, and Yi R Fung. Empowering reliable visual-centric instruction following in mllms.arXiv preprint arXiv:2601.03198, 2026. 6
-
[49]
Ning Miao, Yee Whye Teh, and Tom Rainforth. Selfcheck: Using llms to zero-shot check their own step-by-step reasoning.arXiv preprint arXiv:2308.00436, 2023. 6
-
[50]
Llm-check: Investigating detection of hallucinations in large language models
Gaurang Sriramanan, Siddhant Bharti, Vinu Sankar Sadasivan, Shoumik Saha, Priyatham Kattakinda, and Soheil Feizi. Llm-check: Investigating detection of hallucinations in large language models. Advances in Neural Information Processing Systems, 37:34188–34216, 2024. 6
work page 2024
-
[51]
Starling-7b: Improving helpfulness and harmlessness with rlaif
Banghua Zhu, Evan Frick, Tianhao Wu, Hanlin Zhu, Karthik Ganesan, Wei-Lin Chiang, Jian Zhang, and Jiantao Jiao. Starling-7b: Improving helpfulness and harmlessness with rlaif. InFirst Conference on Language Modeling, 2024. 6
work page 2024
-
[52]
Skywork-Reward: Bag of tricks for reward modeling in llms
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. Skywork-reward: Bag of tricks for reward modeling in llms.arXiv preprint arXiv:2410.18451, 2024. 6
-
[53]
Jialun Zhong, Wei Shen, Yanzeng Li, Songyang Gao, Hua Lu, Yicheng Chen, Yang Zhang, Wei Zhou, Jinjie Gu, and Lei Zou. A comprehensive survey of reward models: Taxonomy, applications, challenges, and future.arXiv preprint arXiv:2504.12328, 2025. 6 Scalable Token-Level Hallucination Detection in LLMs15
-
[54]
Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. Rm-bench: Benchmarking reward models of language models with subtlety and style.arXiv preprint arXiv:2410.16184, 2024. 6
-
[55]
Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. Pairjudge rm: Perform best-of-n sampling with knockout tournament.arXiv preprint arXiv:2501.13007, 2025. 6
-
[56]
Mingyang Song, Zhaochen Su, Xiaoye Qu, Jiawei Zhou, and Yu Cheng. Prmbench: A fine-grained and challenging benchmark for process-level reward models.arXiv preprint arXiv:2501.03124, 2025. 6
-
[57]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1009–1024, 2025. 6
work page 2025
-
[58]
Cameron B Browne, Edward Powley, Daniel Whitehouse, Simon M Lucas, Peter I Cowling, Philipp Rohlfshagen, Stephen Tavener, Diego Perez, Spyridon Samothrakis, and Simon Colton. A survey of monte carlo tree search methods.IEEE Transactions on Computational Intelligence and AI in games, 4(1):1–43, 2012. 6
work page 2012
-
[59]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Chen, et al. Qwen2.5-math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024. F Scalable Token-Level Hallucination Detection in LLMs16 A Broader Impacts This paper introduces TOKENHD, a framework designed for token-level hallucination detection in LLM- generated res...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
**Original Text **: A long document or passage
-
[62]
**Extracted Text **: A segment supposedly extracted from the original text, but may contain slight variations, errors, or modifications **Your Task **: For each extracted text segment, locate the corresponding section in the original text that best matches it, and output the exact original text segment with appropriate tags. **Instructions**: - The extrac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.