Recognition: 2 theorem links
· Lean TheoremEnhancing Instruction Prefetching via Cache and TLB Management
Pith reviewed 2026-05-13 03:02 UTC · model grok-4.3
The pith
IP-CaT jointly manages TLB translations and L2 cache replacements to enhance L1 instruction prefetching, delivering an 8.7% geomean speedup on server workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
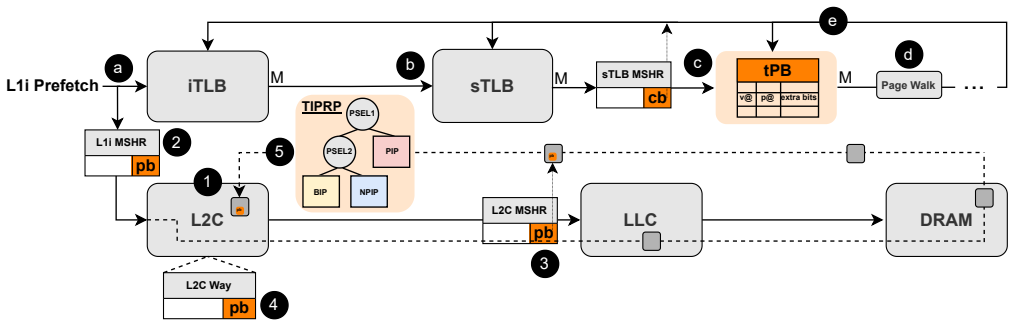
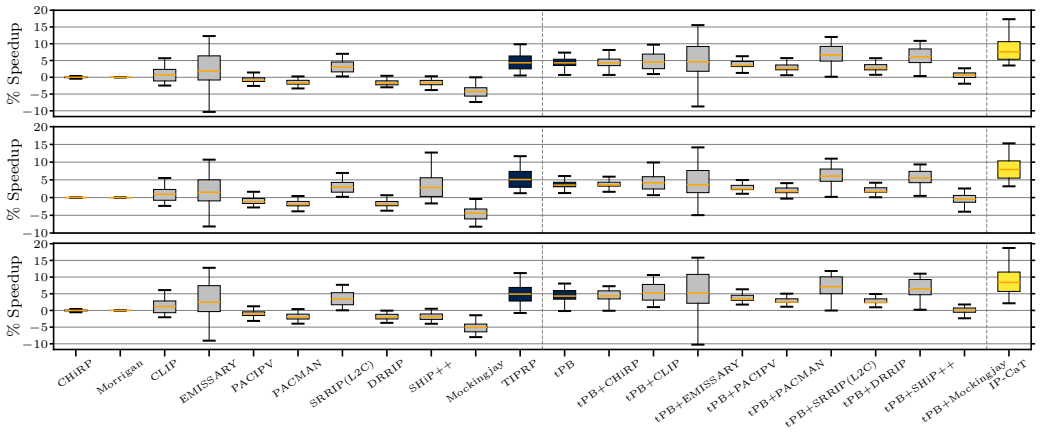
The paper introduces Instruction Prefetch-Centric Cache and TLB Management (IP-CaT), consisting of the translation Prefetch Buffer (tPB) colocated with the second-level TLB to store page table entries for page-crossing L1I prefetches, reducing translation overheads, and the Trimodal Instruction Prefetch Replacement Policy (TIPRP), a decision-tree-based L2 cache replacement policy specialized for lines fetched by L1I prefetchers. When applied to existing prefetchers including EPI, FNL+MMA, and Barca across 105 contemporary server workloads, IP-CaT consistently improves performance, for example achieving an 8.7% geomean speedup over EPI alone, while also outperforming state-of-the-art TLB and
What carries the argument
The translation Prefetch Buffer (tPB) colocated with the second-level TLB together with the Trimodal Instruction Prefetch Replacement Policy (TIPRP) that together reduce translation latency for page-crossing prefetches and manage heterogeneous reuse of prefetched L2 lines.
If this is right
- IP-CaT improves the effectiveness of multiple existing L1I prefetchers without requiring changes to those prefetchers.
- Page-crossing L1I prefetches become timelier because the tPB supplies translations without full page-table walk delays.
- L2 cache space is used more efficiently by retaining high-reuse prefetched lines and evicting dead-on-arrival ones via the TIPRP.
- IP-CaT surpasses prior instruction TLB prefetching methods, advanced TLB replacement policies such as CHiRP, and multiple cache replacement policies including Emissary, SHiP++, and Mockingjay.
- Performance gains appear consistently across three different state-of-the-art L1I prefetchers on a broad set of contemporary server workloads.
Where Pith is reading between the lines
- Joint TLB and cache management for prefetchers could be extended to data prefetchers if similar page-boundary and reuse heterogeneity appear in data streams.
- Lightweight classifiers like the decision tree in TIPRP might be adapted for other microarchitectural decisions that face heterogeneous access patterns.
- As instruction footprints grow further in cloud applications, structures such as tPB could help front-end performance scale without proportional increases in TLB size.
Load-bearing premise
The tPB and TIPRP incur negligible area, power, and latency overheads while the heterogeneous reuse patterns observed in the 105 workloads generalize to future server applications.
What would settle it
Hardware implementation showing that tPB accesses add measurable latency or power, or an evaluation on new workloads where the geomean speedup over baseline prefetchers falls to zero.
Figures














read the original abstract
Modern server workloads exhibit massive instruction footprints that heavily pressure the processor front-end, making L1 instruction (L1I) prefetching critical for sustaining performance. However, this paper shows that current L1I prefetchers fail to reach their full potential due to two key limitations. First, L1I prefetches crossing page boundaries require address translation before issuance, and translation latency reduces prefetch timeliness. Second, the reuse behavior of code lines fetched by L1I prefetches is highly heterogeneous: while some lines are reused many times, others are dead-on-arrival. This paper introduces Instruction Prefetch-Centric Cache and TLB Management (IP-CaT), the first microarchitectural framework jointly optimizing TLB and cache management for L1I prefetching. IP-CaT consists of two components: (i) the translation Prefetch Buffer (tPB), a small structure colocated with the second-level TLB (sTLB) that stores page table entries fetched by page-crossing L1I prefetches, reducing translation overheads; and (ii) the Trimodal Instruction Prefetch Replacement Policy (TIPRP), a decision-tree-based L2 cache replacement policy specialized for lines fetched by L1I prefetches. We evaluate IP-CaT with three state-of-the-art L1I prefetchers: EPI, FNL+MMA, and Barca. Across 105 contemporary server workloads, IP-CaT consistently improves performance. For example, IP-CaT+EPI achieves an 8.7% geomean speedup over EPI alone. We further show that IP-CaT outperforms state-of-the-art instruction TLB prefetching, advanced TLB replacement (CHiRP), and state-of-the-art code-aware, prefetch-aware, and general-purpose cache replacement policies, including Emissary, SHiP++, and Mockingjay.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IP-CaT, a framework to enhance L1I prefetching by jointly optimizing TLB and cache management. It introduces the translation Prefetch Buffer (tPB) colocated with the sTLB to cache page table entries for page-crossing prefetches and reduce translation latency, plus the Trimodal Instruction Prefetch Replacement Policy (TIPRP), a decision-tree L2 replacement policy specialized for lines fetched by L1I prefetchers. Evaluated with EPI, FNL+MMA, and Barca across 105 server workloads, IP-CaT+EPI delivers an 8.7% geomean speedup over EPI alone and outperforms instruction TLB prefetching, CHiRP, Emissary, SHiP++, and Mockingjay.
Significance. If the central performance claims hold after explicit overhead accounting, the work would be significant for server processor front-end design. Large instruction footprints make L1I prefetch timeliness and reuse heterogeneity key bottlenecks; a lightweight joint TLB-cache approach that demonstrably improves multiple prefetchers without offsetting costs would be a practical contribution with broad applicability.
major comments (3)
- [Abstract] Abstract: the 8.7% geomean speedup for IP-CaT+EPI is reported without any cycle-accurate latency, power, or area numbers for the tPB on the translation path or for TIPRP decision logic; these overheads are load-bearing because even small added latency on page-crossing prefetches or extra dynamic power could erase or reverse the net gain.
- [Evaluation] Evaluation section: no error bars, no workload selection criteria or cross-validation of TIPRP on held-out workloads, and no sensitivity analysis to tPB size are provided; this leaves open whether the reported outperformance over Emissary/SHiP++/Mockingjay is robust or corpus-specific.
- [Design of tPB] Design of tPB: the claim that colocating tPB with sTLB incurs negligible latency requires explicit modeling of the lookup on the critical path for page-crossing L1I prefetches; without it the timeliness benefit cannot be verified.
minor comments (2)
- [Abstract] Abstract: the sizes of tPB and the decision-tree depth of TIPRP are described only as 'small' and 'specialized'; quantitative parameters would improve reproducibility.
- [Design] The paper could add a short table summarizing tPB and TIPRP hardware costs (entries, bits, comparators) for direct comparison with baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments on overhead accounting, evaluation robustness, and tPB timing analysis are well-taken. We address each major comment below and will make targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 8.7% geomean speedup for IP-CaT+EPI is reported without any cycle-accurate latency, power, or area numbers for the tPB on the translation path or for TIPRP decision logic; these overheads are load-bearing because even small added latency on page-crossing prefetches or extra dynamic power could erase or reverse the net gain.
Authors: We agree that the abstract would benefit from explicit context on overheads to support the net speedup claim. The full manuscript already includes area, power, and latency estimates for the tPB (small buffer colocated with sTLB) and TIPRP decision logic in the hardware overhead and evaluation sections, showing tPB area under 1 KB with negligible dynamic power and no added critical-path latency in our models. To directly address the concern, we will revise the abstract to note that these overheads were modeled and do not offset the reported gains, with a pointer to the detailed analysis. This is a partial revision focused on visibility rather than new data. revision: partial
-
Referee: [Evaluation] Evaluation section: no error bars, no workload selection criteria or cross-validation of TIPRP on held-out workloads, and no sensitivity analysis to tPB size are provided; this leaves open whether the reported outperformance over Emissary/SHiP++/Mockingjay is robust or corpus-specific.
Authors: We appreciate the call for greater statistical rigor and validation. The 105 workloads were drawn from standard server suites (SPEC CPU, CloudSuite, and production server traces) selected specifically for large instruction footprints; we will add explicit selection criteria and workload characteristics to the evaluation section. We will also add error bars to all geomean and per-workload figures. For TIPRP robustness, we will include a new sensitivity study on tPB size (varying from 4 to 32 entries) and a cross-validation experiment partitioning workloads into training/test sets to confirm the decision-tree policy generalizes and the gains over Emissary, SHiP++, and Mockingjay are not corpus-specific. These additions will be incorporated in the revised manuscript. revision: yes
-
Referee: [Design of tPB] Design of tPB: the claim that colocating tPB with sTLB incurs negligible latency requires explicit modeling of the lookup on the critical path for page-crossing L1I prefetches; without it the timeliness benefit cannot be verified.
Authors: We acknowledge that the current description of tPB colocation would be strengthened by explicit critical-path modeling. The tPB is a small structure (8-16 entries) placed adjacent to the sTLB to enable parallel or overlapped lookup for page-crossing prefetches. Our cycle-level simulations already account for this access and show no additional stalls. In the revision, we will add a dedicated timing diagram and pipeline analysis subsection that models the exact lookup sequence on the translation path, confirming the added latency remains hidden within existing TLB access cycles. This will make the timeliness benefit fully verifiable. revision: yes
Circularity Check
No circularity: empirical evaluation against external baselines with no derivations or self-referential reductions
full rationale
The paper presents a microarchitectural proposal (tPB colocated with sTLB and TIPRP decision-tree policy) evaluated via simulation on 105 server workloads. All performance claims (e.g., 8.7% geomean speedup of IP-CaT+EPI over EPI) are reported as measured speedups relative to independent prior prefetchers and replacement policies (EPI, FNL+MMA, Barca, Emissary, SHiP++, Mockingjay, CHiRP). No equations, fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatzes appear in the provided text. The central results are therefore falsifiable by re-running the same simulators on the same workloads rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
translation Prefetch Buffer (tPB)
no independent evidence
-
Trimodal Instruction Prefetch Replacement Policy (TIPRP)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearIP-CaT comprises two modules: i) the translation Prefetch Buffer (tPB), a small buffer located alongside the last-level TLB (sTLB) ... and ii) the Trimodal Instruction Prefetch Replacement Policy (TIPRP), a decision-tree based replacement policy for the L2 cache
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe evaluate IP-CaT with three state-of-the-art L1I prefetchers ... across 105 contemporary server workloads
Reference graph
Works this paper leans on
-
[1]
A Cost-Effective Entangling Prefetcher for Instructions,
A. Ros and A. Jimborean, “A Cost-Effective Entangling Prefetcher for Instructions,” inProceedings of the 48th International Symposium on Computer Architecture, ser. ISCA ’21, 2021, pp. 99–111. [Online]. Available: https://doi.org/10.1109/ISCA52012.2021.00017
-
[2]
The FNL+MMA Instruction Cache Prefetcher,
A. Seznec, “The FNL+MMA Instruction Cache Prefetcher,” https://hal. inria.fr/hal-02884880/document
-
[3]
Barca: Branch- agnostic region searching algorithm,
P. Gratz, D. A. Jim ´enez, N. Gober, and G. Chacon, “Barca: Branch- agnostic region searching algorithm,” inProceedings of the First In- struction Prefetching Championship (IPC), 2020
work page 2020
-
[4]
Morrigan: A Composite Instruction TLB Prefetcher,
G. Vavouliotis, L. Alvarez, B. Grot, D. Jim ´enez, and M. Casas, “Morrigan: A Composite Instruction TLB Prefetcher,” inProceedings of the 54th International Symposium on Microarchitecture, ser. MICRO ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 1138–1153. [Online]. Available: https://doi.org/10. 1145/3466752.3480049
-
[5]
CHiRP: Control-Flow History Reuse Prediction,
S. Mirbagher-Ajorpaz, E. Garza, G. Pokam, and D. A. Jim ´enez, “CHiRP: Control-Flow History Reuse Prediction,” inProceedings of the 2020 53rd International Symposium on Microarchitecture, ser. MICRO ’16, 2020, pp. 131–145. [Online]. Available: https: //doi.org/10.1109/MICRO50266.2020.00023
-
[6]
Emissary: Enhanced miss awareness replacement policy for l2 instruction caching,
N. P. Nagendra, B. R. Godala, I. Chaturvedi, A. Patel, S. Kanev, T. Moseley, J. Stark, G. A. Pokam, S. Campanoni, and D. I. August, “Emissary: Enhanced miss awareness replacement policy for l2 instruction caching,” inProceedings of the 50th Annual International Symposium on Computer Architecture, ser. ISCA ’23. New York, NY , USA: Association for Computin...
-
[7]
SHiP++: Enhancing Signature-Based Hit Predictor for Improved Cache Performance,
V . Young, C.-C. Chou, A. Jaleel, and M. K. Qureshi, “SHiP++: Enhancing Signature-Based Hit Predictor for Improved Cache Performance,” in2nd Cache Replacement Championship (CRC-2), in conjunction with ISCA 2017, Jun. 2017. [Online]. Available: https://crc2.ece.tamu.edu/?page id=53
work page 2017
-
[8]
Effective mimicry of belady’s min policy,
I. Shah, A. Jain, and C. Lin, “Effective mimicry of belady’s min policy,” in2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA), April 2022, pp. 558–572. [Online]. Available: https://doi.org/10.1109/HPCA53966.2022.00048
-
[9]
AsmDB: Understanding and Mitigating Front-End Stalls in Warehouse-Scale Computers,
N. P. Nagendra, G. Ayers, D. I. August, H. K. Cho, S. Kanev, C. Kozyrakis, T. Krishnamurthy, H. Litz, T. Moseley, and P. Ranganathan, “AsmDB: Understanding and Mitigating Front-End Stalls in Warehouse-Scale Computers,”IEEE Micro, vol. 40, no. 3, pp. 56–63, 2020. [Online]. Available: https://doi.org/10.1145/3307650.3322234
-
[10]
BOLT: A Practical Binary Optimizer for Data Centers and Beyond,
M. Panchenko, R. Auler, B. Nell, and G. Ottoni, “BOLT: A Practical Binary Optimizer for Data Centers and Beyond,” inProceedings of the 2019 International Symposium on Code Generation and Optimization, ser. CGO ’19. IEEE Press, 2019, pp. 2–14. [Online]. Available: https://doi.org/10.1109/CGO.2019.8661201
-
[11]
Hot Chips 2023: Arm’s Neoverse V2,
“Hot Chips 2023: Arm’s Neoverse V2,” https://chipsandcheese.com/ 2023/09/11/hot-chips-2023-arms-neoverse-v2/
work page 2023
-
[12]
Clearing the Clouds: A Study of Emerging Scale-out Workloads on Modern Hardware,
M. Ferdman, A. Adileh, O. Kocberber, S. V olos, M. Alisafaee, D. Jevdjic, C. Kaynak, A. D. Popescu, A. Ailamaki, and B. Falsafi, “Clearing the Clouds: A Study of Emerging Scale-out Workloads on Modern Hardware,” inProceedings of the 17th International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’12. New...
work page 2012
-
[13]
Available: http://doi.acm.org/10.1145/2150976.2150982
[Online]. Available: http://doi.acm.org/10.1145/2150976.2150982
-
[14]
Fetch Directed Instruction Prefetching,
G. Reinman, B. Calder, and T. Austin, “Fetch Directed Instruction Prefetching,” inProceedings of the 32nd International Symposium on Microarchitecture, ser. MICRO ’99, 1999, pp. 16–27. [Online]. Available: https://doi.org/10.1109/MICRO.1999.809439
-
[15]
Reducing Memory Reference Energy with Opportunistic Virtual Caching,
A. Basu, M. D. Hill, and M. M. Swift, “Reducing Memory Reference Energy with Opportunistic Virtual Caching,” inProceedings of the 39th International Symposium on Computer Architecture, ser. ISCA ’12, 2012, pp. 297–308. [Online]. Available: https: //doi.org/10.1109/ISCA.2012.6237026
-
[16]
Advanced Concepts on Address Translation, Appendix L in
Abhishek Bhattacharjee, “Advanced Concepts on Address Translation, Appendix L in ”Computer Architecture: A Quantitative Approach” by Hennessy and Patterson,” http://www.cs.yale.edu/homes/abhishek/ abhishek-appendix-l.pdf
-
[17]
ARM Cortex-A55 Core Technical Reference Manual r1p0,
“ARM Cortex-A55 Core Technical Reference Manual r1p0,” https://developer.arm.com/documentation/100442/0100/functional- description/level-1-memory-system/data-prefetching?lang=en
-
[18]
Hermes: Accelerating long-latency load requests via perceptron-based off-chip load prediction,
G. Vavouliotis, G. Chacon, L. Alvarez, P. V . Gratz, D. A. Jim´enez, and M. Casas, “Page Size Aware Cache Prefetching,” in Proceedings of the 55th International Symposium on Microarchitecture, ser. MICRO ’22, 2022, pp. 956–974. [Online]. Available: https: //doi.org/10.1109/MICRO56248.2022.00070
-
[19]
To cross, or not to cross pages for prefetching?
G. Vavouliotis, M. Torrents, B. Grot, K. Kalaitzidis, L. Peled, and M. Casas, “To cross, or not to cross pages for prefetching?” in 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), March 2025, pp. 188–203. [Online]. Available: https://doi.org/10.1109/HPCA61900.2025.00025
-
[20]
Adaptive insertion policies for high performance caching,
M. K. Qureshi, A. Jaleel, Y . N. Patt, S. C. Steely, and J. Emer, “Adaptive insertion policies for high performance caching,” in Proceedings of the 34th Annual International Symposium on Computer Architecture, ser. ISCA ’07. New York, NY , USA: Association for Computing Machinery, 2007, p. 381–391. [Online]. Available: https://doi.org/10.1145/1250662.1250709
-
[21]
A. Jaleel, J. Nuzman, A. Moga, S. C. Steely, and J. Emer, “High performing cache hierarchies for server workloads: Relaxing inclusion to capture the latency benefits of exclusive caches,” in2015 IEEE 21st International Symposium on High Performance Computer Architecture (HPCA), 2015, pp. 343–353. [Online]. Available: https://doi.org/10.1109/HPCA.2015.7056045
-
[22]
Ship: signature-based hit predictor for high performance caching,
C.-J. Wu, A. Jaleel, M. Martonosi, S. C. Steely, and J. Emer, “Pacman: Prefetch-aware cache management for high performance caching,” in2011 44th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), 2011, pp. 442–453. [Online]. Available: https://doi.org/10.1145/2155620.215567
-
[23]
Windserve: Efficient phase- disaggregated llm serving with stream-based dynamic scheduling
S. Mostofi, S. Gupta, A. Hassani, K. Tibrewala, E. Teran, P. V . Gratz, and D. A. Jim ´enez, “Light-weight cache replacement for instruction heavy workloads,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1005–1019. [Online]. Available: ht...
-
[24]
A Dueling Segmented LRU Replacement Algorithm with Adaptive Bypassing,
H. Gao and C. Wilkerson, “A Dueling Segmented LRU Replacement Algorithm with Adaptive Bypassing,” in1st JILP Workshop on Computer Architecture Competitions (JWAC-1): Cache Replacement Championship, Jun. 2010. [Online]. Available: https://jilp.org/jwac- 1/online/papers/005 gao.pdf
work page 2010
-
[25]
High performance cache replacement using re-reference interval prediction (rrip),
A. Jaleel, K. B. Theobald, S. C. Steely, and J. Emer, “High performance cache replacement using re-reference interval prediction (rrip),” inProceedings of the 37th Annual International Symposium on Computer Architecture, ser. ISCA ’10. New York, NY , USA: Association for Computing Machinery, 2010, p. 60–71. [Online]. Available: https://doi.org/10.1145/181...
-
[26]
D. Lee, J. Choi, J.-H. Kim, S. H. Noh, S. L. Min, Y . Cho, and C. S. Kim, “On the existence of a spectrum of policies that subsumes the least recently used (lru) and least frequently used (lfu) policies,” inProceedings of the 1999 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, ser. SIGMETRICS ’99. New York, NY , U...
-
[27]
The lru-k page replacement algorithm for database disk buffering,
E. J. O’Neil, P. E. O’Neil, and G. Weikum, “The lru-k page replacement algorithm for database disk buffering,” inProceedings of the 1993 ACM SIGMOD International Conference on Management of Data, ser. SIGMOD ’93. New York, NY , USA: Association for Computing Machinery, 1993, p. 297–306. [Online]. Available: https://doi.org/10.1145/170035.170081
-
[28]
Adaptive caches: Effective shaping of cache behavior to workloads,
R. Subramanian, Y . Smaragdakis, and G. H. Loh, “Adaptive caches: Effective shaping of cache behavior to workloads,” in2006 39th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO’06), Dec 2006, pp. 385–396. [Online]. Available: https: //doi.org/10.1109/MICRO.2006.7
-
[29]
Modified lru policies for improving second-level cache behavior,
W. Wong and J.-L. Baer, “Modified lru policies for improving second-level cache behavior,” inProceedings Sixth International Symposium on High-Performance Computer Architecture. HPCA-6 (Cat. No.PR00550), 2000, pp. 49–60. [Online]. Available: https: //doi.org/10.1109/HPCA.2000.824338
-
[30]
Ship: signature-based hit predictor for high performance caching,
C.-J. Wu, A. Jaleel, W. Hasenplaugh, M. Martonosi, S. C. Steely, and J. Emer, “Ship: signature-based hit predictor for high performance caching,” inProceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-44. New York, NY , USA: Association for Computing Machinery, 2011, p. 430–441. [Online]. Available: https://doi....
-
[31]
Multiperspective Reuse Prediction,
D. A. Jim ´enez and E. Teran, “Multiperspective Reuse Prediction,” in Proceedings of the 50th International Symposium on Microarchitecture, ser. MICRO ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 436–448. [Online]. Available: https://doi.org/10. 1145/3123939.3123942
-
[32]
Perceptron learning for reuse prediction,
E. Teran, Z. Wang, and D. A. Jim ´enez, “Perceptron learning for reuse prediction,” in2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2016, pp. 1–12. [Online]. Available: https://doi.org/10.1109/MICRO.2016.7783705
-
[33]
Sampling dead block prediction for last-level caches,
S. M. Khan, Y . Tian, and D. A. Jim ´enez, “Sampling dead block prediction for last-level caches,” in2010 43rd Annual IEEE/ACM International Symposium on Microarchitecture, Dec 2010, pp. 175–186. [Online]. Available: https://doi.org/10.1109/MICRO.2010.24
-
[34]
Applying deep learning to the cache replacement problem,
Z. Shi, X. Huang, A. Jain, and C. Lin, “Applying deep learning to the cache replacement problem,” inProceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’52. New York, NY , USA: Association for Computing Machinery, 2019, p. 413–425. [Online]. Available: https://doi.org/10.1145/3352460. 3358319
-
[35]
Back to the future: Leveraging belady’s algorithm for improved cache replacement,
A. Jain and C. Lin, “Back to the future: Leveraging belady’s algorithm for improved cache replacement,” in2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, pp. 78–89. [Online]. Available: https://doi.org/10.1109/ISCA.2016.17
-
[36]
Improving cache management policies using dynamic reuse distances,
N. Duong, D. Zhao, T. Kim, R. Cammarota, M. Valero, and A. V . Veidenbaum, “Improving cache management policies using dynamic reuse distances,” inProceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-45. USA: IEEE Computer Society, 2012, p. 389–400. [Online]. Available: https://doi.org/10.1109/MICRO.2012.43
-
[37]
Timekeeping in the memory system: Predicting and optimizing memory behavior,
Z. Hu, S. Kaxiras, and M. Martonosi, “Timekeeping in the memory system: Predicting and optimizing memory behavior,” inProceedings of the 29th Annual International Symposium on Computer Architecture, ser. ISCA ’02. USA: IEEE Computer Society, 2002, p. 209–220. [Online]. Available: https://doi.org/10.1145/545214.545239
-
[38]
Cache replacement based on reuse-distance prediction,
G. Keramidas, P. Petoumenos, and S. Kaxiras, “Cache replacement based on reuse-distance prediction,” in2007 25th International Conference on Computer Design, 2007, pp. 245–250. [Online]. Available: https://doi.org/10.1109/ICCD.2007.4601909
-
[39]
Counter-based cache replacement and bypassing algorithms,
M. Kharbutli and Y . Solihin, “Counter-based cache replacement and bypassing algorithms,”IEEE Transactions on Computers, vol. 57, no. 4, pp. 433–447, 2008. [Online]. Available: https://doi.org/10.1109/ TC.2007.70816
-
[40]
Cache bursts: A new approach for eliminating dead blocks and increasing cache efficiency,
H. Liu, M. Ferdman, J. Huh, and D. Burger, “Cache bursts: A new approach for eliminating dead blocks and increasing cache efficiency,” in2008 41st IEEE/ACM International Symposium on Microarchitecture, Nov 2008, pp. 222–233. [Online]. Available: https://doi.org/10.1109/MICRO.2008.4771793
-
[41]
Leeway: Addressing variability in dead-block prediction for last-level caches,
P. Faldu and B. Grot, “Leeway: Addressing variability in dead-block prediction for last-level caches,” in2017 26th International Conference on Parallel Architectures and Compilation Techniques (PACT), 2017, pp. 180–193. [Online]. Available: https://doi.org/10.1109/PACT.2017.32
-
[42]
Insertion and promotion for tree-based pseudolru last-level caches,
D. A. Jim ´enez, “Insertion and promotion for tree-based pseudolru last-level caches,” inProceedings of the 46th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-46. New York, NY , USA: Association for Computing Machinery, 2013, p. 284–296. [Online]. Available: https://doi.org/10.1145/2540708.2540733
-
[43]
IEEE Computer Society, 338–351
D. Schall, A. Sandberg, and B. Grot, “The last-level branch predictor,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2024, pp. 464–479. [Online]. Available: https://doi.org/10.1109/MICRO61859.2024.00042
-
[44]
Profiling a Warehouse-scale Computer,
S. Kanev, J. P. Darago, K. Hazelwood, P. Ranganathan, T. Moseley, G.-Y . Wei, and D. Brooks, “Profiling a Warehouse-scale Computer,” inProceedings of the 42nd International Symposium on Computer Architecture, ser. ISCA ’15. New York, NY , USA: ACM, 2015, pp. 158–
work page 2015
-
[45]
Available: http://doi.acm.org/10.1145/2749469.2750392
[Online]. Available: http://doi.acm.org/10.1145/2749469.2750392
-
[46]
Inside 6th- generation intel core: New microarchitecture code-named skylake,
J. Doweck, W.-F. Kao, A. K.-y. Lu, J. Mandelblat, A. Rahatekar, L. Rappoport, E. Rotem, A. Yasin, and A. Yoaz, “Inside 6th- generation intel core: New microarchitecture code-named skylake,” IEEE Micro, vol. 37, no. 2, pp. 52–62, 2017. [Online]. Available: https://doi.org/10.1109/MM.2017.38
-
[47]
Adapting cache partitioning algorithms to pseudo-lru replacement policies,
K. Kedzierski, M. Moreto, F. J. Cazorla, and M. Valero, “Adapting cache partitioning algorithms to pseudo-lru replacement policies,” in2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), 2010, pp. 1–12. [Online]. Available: https: //doi.org/10.1109/IPDPS.2010.5470352
-
[48]
Implementation of a pseudo-LRU algorithm in a partitioned cache,
W.-T. T. Chen, P. P. Liu, and K. C. Stelzer, “Implementation of a pseudo-LRU algorithm in a partitioned cache,” US Patent US7 069 390B2, jun, 2006. [Online]. Available: https://patents.google. com/patent/US7069390B2/en
work page 2006
-
[49]
Context-aware set dueling for dynamic policy arbitration,
D. Patsidis and G. Vavouliotis, “Context-aware set dueling for dynamic policy arbitration,”IEEE Computer Architecture Letters, vol. 24, no. 2, pp. 301–304, 2025. [Online]. Available: https: //doi.org/10.1109/LCA.2025.3617159
-
[50]
Processing metadata, policies, and composite tags (prefetch flag in cache tag),
Advanced Micro Devices, Inc., “Processing metadata, policies, and composite tags (prefetch flag in cache tag),” U.S. Patent US11 635 960B2, 2023, describes a metadata flag in cache tags used to track or prevent prefetching into caches. [Online]. Available: https://patents.google.com/patent/US11635960B2 [49]Intel ® 64 and IA-32 Architectures Software Devel...
work page 2023
-
[51]
A case for (partially) tagged geometric history length branch prediction,
A. Seznec and P. Michaud, “A case for (partially) tagged geometric history length branch prediction,”Journal of Instruction-Level Parallelism, vol. 8, 2006, special issue on Branch Prediction. [Online]. Available: http://www.jilp.org/vol8/v8paper1.pdf
work page 2006
-
[52]
A new case for the tage branch predictor,
A. Seznec, “A new case for the tage branch predictor,” in Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO-44. New York, NY , USA: Association for Computing Machinery, 2011, p. 117–127. [Online]. Available: https://doi.org/10.1145/2155620.2155635
-
[53]
Hermes: Accelerating long-latency load requests via perceptron-based off-chip load prediction,
A. Navarro-Torres, B. Panda, J. Alastruey-Bened ´e, P. Ib ´a˜nez, V . Vi˜nals-Y´ufera, and A. Ros, “Berti: an accurate local-delta data prefetcher,” inProceedings of the 55th International Symposium on Microarchitecture, ser. MICRO ’22, 2022, pp. 975–991. [Online]. Available: https://doi.org/10.1109/MICRO56248.2022.00072
- [54]
-
[55]
The championship simulator: Architectural simulation for education and competition,
N. Gober, G. Chacon, L. Wang, P. V . Gratz, D. A. Jimenez, E. Teran, S. Pugsley, and J. Kim, “The championship simulator: Architectural simulation for education and competition,” 2022. [Online]. Available: https://arxiv.org/abs/2210.14324
-
[56]
Re-establishing fetch-directed instruction prefetching: An industry perspective,
Y . Ishii, J. Lee, K. Nathella, and D. Sunwoo, “Re-establishing fetch-directed instruction prefetching: An industry perspective,” in2021 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2021, pp. 172–182. [Online]. Available: https://doi.org/10.1109/ISPASS51385.2021.00034
-
[57]
D. A. Patterson and J. L. Hennessy,Computer Architecture: A Quantita- tive Approach. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1990
work page 1990
- [58]
-
[59]
A two level neural approach combining off-chip prediction with adaptive prefetch filtering,
A. V . Jamet, G. Vavouliotis, D. A. Jim ´enez, L. Alvarez, and M. Casas, “A two level neural approach combining off-chip prediction with adaptive prefetch filtering,” in2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA), 2024, pp. 528–542. [Online]. Available: https://doi.org/10.1109/HPCA57654.2024.00046
-
[60]
Instruction-aware cooperative tlb and cache replacement policies,
D. Chasapis, G. Vavouliotis, D. A. Jim ´enez, and M. Casas, “Instruction-aware cooperative tlb and cache replacement policies,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, ser. ASPLOS ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 619–636...
-
[61]
Beyond malloc Efficiency to Fleet Efficiency: a Hugepage-aware Memory Allocator,
A. Hunter, C. Kennelly, P. Turner, D. Gove, T. Moseley, and P. Ranganathan, “Beyond malloc Efficiency to Fleet Efficiency: a Hugepage-aware Memory Allocator,” inProceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation, ser. OSDI ’21. USENIX Association, jul 2021, pp. 257–273. [Online]. Available: https://www.usenix.org/confe...
work page 2021
-
[62]
Translation Ranger: Operating System Support for Contiguity-Aware TLBs,
Z. Yan, D. Lustig, D. Nellans, and A. Bhattacharjee, “Translation Ranger: Operating System Support for Contiguity-Aware TLBs,” 15 inProceedings of the 46th International Symposium on Computer Architecture, ser. ISCA ’19. New York, NY , USA: Association for Computing Machinery, 2019, pp. 698–710. [Online]. Available: https://doi.org/10.1145/3307650.3322223
-
[63]
Championship Value Prediction (CVP),
“Championship Value Prediction (CVP),” https://www.microarch.org/ cvp1/, accessed: 17-04-2024
work page 2024
-
[64]
The 1st Instruction Prefetching Championship,
“The 1st Instruction Prefetching Championship,” https://research.ece. ncsu.edu/ipc/, accessed: 17-04-2024
work page 2024
-
[65]
A Cost-Effective Entangling Prefetcher for Instructions,
G. Vavouliotis, L. Alvarez, V . Karakostas, K. Nikas, N. Koziris, D. A. Jim´enez, and M. Casas, “Exploiting page table locality for agile tlb prefetching,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), 2021, pp. 85–98. [Online]. Available: https://doi.org/10.1109/ISCA52012.2021.00016
-
[66]
Thermometer: profile-guided btb replacement for data center applications,
S. Song, T. A. Khan, S. M. Shahri, A. Sriraman, N. K. Soundararajan, S. Subramoney, D. A. Jim ´enez, H. Litz, and B. Kasikci, “Thermometer: profile-guided btb replacement for data center applications,” in Proceedings of the 49th Annual International Symposium on Computer Architecture, ser. ISCA ’22. New York, NY , USA: Association for Computing Machinery,...
-
[67]
Hermes: Accelerating long-latency load requests via perceptron-based off-chip load prediction,
R. Bera, K. Kanellopoulos, S. Balachandran, D. Novo, A. Olgun, M. Sadrosadat, and O. Mutlu, “Hermes: Accelerating long-latency load requests via perceptron-based off-chip load prediction,” in2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), Oct 2022, pp. 1–18. [Online]. Available: https://doi.org/10.1109/ MICRO56248.2022.00015
-
[68]
Alternative basis matrix multiplication is fast and stable,
A. V . Jamet, G. Vavouliotis, D. A. Jim ´enez, L. Alvarez, and M. Casas, “Practically tackling memory bottlenecks of graph- processing workloads,” in2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2024, pp. 1034–1045. [Online]. Available: https://doi.org/10.1109/IPDPS57955.2024.00096
-
[69]
Multi-program benchmark definition,
A. N. Jacobvitz, A. D. Hilton, and D. J. Sorin, “Multi-program benchmark definition,” in2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), March 2015, pp. 72–82. [Online]. Available: https://doi.org/10.1109/ISPASS.2015. 7095786
-
[70]
Multiperspective reuse prediction,
D. A. Jim ´enez and E. Teran, “Multiperspective reuse prediction,” in2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), ser. MICRO-50 ’17, IEEE. New York, NY , USA: Association for Computing Machinery, 2017, pp. 436–448. [Online]. Available: https://doi.org/10.1145/3123939.3123942
-
[71]
A 64-Kbytes ITTAGE indirect branch predictor,
A. Seznec, “A 64-Kbytes ITTAGE indirect branch predictor,” inJWAC- 2: Championship Branch Prediction. San Jose, United States: JILP, Jun 2011. [Online]. Available: https://inria.hal.science/hal-00639041
work page 2011
-
[72]
G. Gerogiannis and J. Torrellas, “Micro-armed bandit: Lightweight & reusable reinforcement learning for microarchitecture decision-making,” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 698–713. [Online]. Available: https://doi.org/1...
-
[73]
Micro-mama: Multi-agent reinforcement learning for multicore prefetching,
C. Block, G. Gerogiannis, and J. Torrellas, “Micro-mama: Multi-agent reinforcement learning for multicore prefetching,” inProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 884–898. [Online]. Available: https://doi.org/10. 1145/3725843.3756096
-
[74]
Going the Distance for TLB Prefetching: An Application-driven Study,
G. B. Kandiraju and A. Sivasubramaniam, “Going the Distance for TLB Prefetching: An Application-driven Study,” inProceedings of the 29th International Symposium on Computer Architecture, ser. ISCA ’02. Washington, DC, USA: IEEE Computer Society, 2002, pp. 195–206. [Online]. Available: http://dl.acm.org/citation.cfm?id=545215.545237
-
[75]
B. Pham, J. Vesel ´y, G. H. Loh, and A. Bhattacharjee, “Large Pages and Lightweight Memory Management in Virtualized Environments: Can You Have It Both Ways?” inProceedings of the 48th International Symposium on Microarchitecture, ser. MICRO ’15. New York, NY , USA: ACM, 2015, pp. 1–12. [Online]. Available: http://doi.acm.org/10.1145/2830772.2830773
-
[76]
Effective Hardware-Based Data Prefetching for High-Performance Processors,
J.-L. Baer and T.-F. Chen, “Effective Hardware-Based Data Prefetching for High-Performance Processors,”IEEE Trans. Comput., vol. 44, no. 5, pp. 609–623, may 1995. [Online]. Available: https://doi.org/10. 1109/12.381947
work page 1995
-
[77]
Pushing the envelope on free tlb prefetching,
G. Vavouliotis, L. Alvarez, and M. Casas, “Pushing the envelope on free tlb prefetching,” Barcelona Supercomputing Center (BSC) and Universitat Polit `ecnica de Catalunya (UPC), Tech. Rep., 2021. [Online]. Available: https://upcommons.upc.edu/entities/publication/ 198eaf18-44e5-4ed3-8bfa-bd2f3e96e154
work page 2021
-
[78]
Advanced hardware prefetching in virtual memory systems,
G. Vavouliotis, “Advanced hardware prefetching in virtual memory systems,” Ph.D. dissertation, Universitat Polit `ecnica de Catalunya (UPC), 2023. [Online]. Available: https://upcommons.upc.edu/entities/ publication/f16d637b-ad15-4f69-b830-3471b7f2fb84
work page 2023
-
[79]
Rethinking TLB Designs in Virtualized Environments: A Very Large Part-of-Memory TLB,
J. H. Ryoo, N. Gulur, S. Song, and L. K. John, “Rethinking TLB Designs in Virtualized Environments: A Very Large Part-of-Memory TLB,” inProceedings of the 44th International Symposium on Computer Architecture, ser. ISCA ’17. New York, NY , USA: ACM, 2017, pp. 469–
work page 2017
-
[80]
Available: http://doi.acm.org/10.1145/3079856.3080210
[Online]. Available: http://doi.acm.org/10.1145/3079856.3080210
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.