Recognition: 2 theorem links
· Lean TheoremA Causal Language Modeling Detour Improves Encoder Continued Pretraining
Pith reviewed 2026-05-13 04:29 UTC · model grok-4.3
The pith
Temporarily switching to causal language modeling during encoder pretraining improves biomedical task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
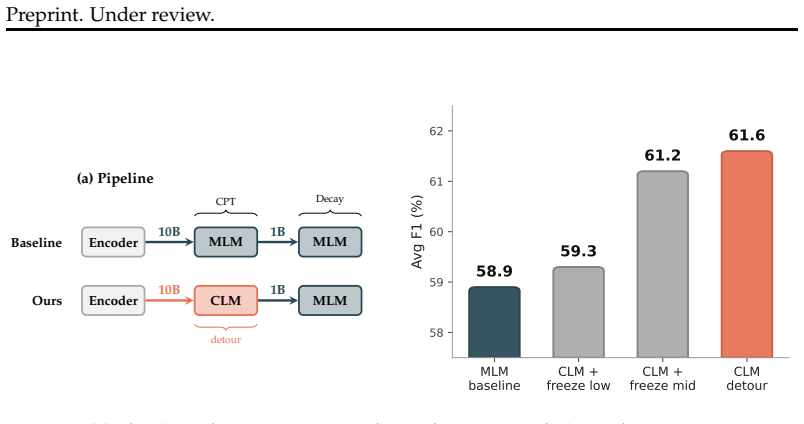
Temporarily switching from masked language modeling to causal language modeling, then applying a short masked language modeling decay, yields better downstream performance than continued masked language modeling on identical data and compute. On biomedical corpora this two-phase schedule raises accuracy by 1.2 to 2.8 points on eight French tasks and 0.3 to 0.8 points on eleven English tasks, depending on model size. The advantage traces to stronger updates in layers 0-7 during the causal phase; freezing those layers removes the benefit while freezing middle layers preserves it, and the layer-wise changes persist through the decay phase.
What carries the argument
The CLM detour: a continued-pretraining schedule that runs causal language modeling for a period before returning to masked language modeling, which alters low-layer representations more than masked modeling alone.
If this is right
- The low-layer representational shifts produced by the causal phase remain after an equally long masked decay phase.
- The size of the improvement grows as model capacity increases from base to large.
- Freezing layers 0-7 during the causal phase removes the downstream benefit, while freezing middle layers leaves it intact.
- The resulting models achieve state-of-the-art results among open biomedical encoders in both base and large sizes.
Where Pith is reading between the lines
- The same temporary objective switch could be tested for domain adaptation outside biomedicine, such as legal or technical text.
- Different pretraining objectives appear to affect transformer layers unevenly, which may guide choices when designing continued-pretraining curricula.
- Varying the relative length of the causal phase might further optimize the layer-specific impact for a given model size.
Load-bearing premise
The performance gains are produced by causal language modeling's denser supervision of the bottom transformer layers rather than by differences in optimization trajectory or data ordering.
What would settle it
Re-running the schedule while freezing layers 0-7 throughout the causal phase and observing no downstream improvement would show that low-layer supervision is not responsible for the gains.
Figures

read the original abstract
When adapting an encoder to a new domain, the standard approach is to continue training with Masked Language Modeling (MLM). We show that temporarily switching to Causal Language Modeling (CLM) followed by a short MLM decay improves downstream performance. On biomedical texts with ModernBERT, this CLM detour outperforms MLM baselines trained on identical data and compute across 8 French and 11 English biomedical tasks, by +1.2-2.8pp and +0.3-0.8pp respectively, depending on model size. We investigate the reasons for these gains. We find that CLM's dense supervision impacts low transformer layers (0-7) far more than MLM does. Freezing low layers during CLM eliminates the downstream benefit; freezing mid layers preserves it. The representational changes persist through the MLM decay phase, even when it matches the CLM phase in length, and they scale with model capacity. We release ModernCamemBERT-bio and ModernBERT-bio as state-of-the-art biomedical encoders in Base and Large sizes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that temporarily inserting a Causal Language Modeling (CLM) phase during continued pretraining of encoder models, followed by a short Masked Language Modeling (MLM) decay, yields better downstream performance than standard MLM-only continued pretraining on the same data and compute. Experiments on biomedical text using ModernBERT (base and large) show gains of +1.2-2.8pp on 8 French tasks and +0.3-0.8pp on 11 English tasks. Layer-freezing ablations are presented as mechanistic evidence that CLM's dense supervision disproportionately affects low layers (0-7), with changes persisting through the decay phase; the resulting models are released as new biomedical encoders.
Significance. If the empirical gains hold under tighter controls, the work supplies a low-overhead recipe for domain adaptation of encoders that could be adopted in specialized domains. The matched-data/compute comparisons and layer ablations provide a stronger empirical foundation than many prior objective-comparison studies, and releasing the fine-tuned models adds immediate utility. The layer-specific findings, if isolated from confounds, would also inform broader questions about how pretraining objectives shape internal representations.
major comments (2)
- [§4.2] §4.2 (layer-freezing ablations): Freezing layers 0-7 during the CLM phase removes the downstream gains while freezing mid-layers preserves them, but this manipulation simultaneously alters gradient flow, update magnitudes, and the effective optimization trajectory. Because the two-phase schedule itself already changes data ordering and loss landscape relative to uniform MLM, the freezing results do not cleanly attribute the benefit to “dense low-layer supervision” versus schedule-induced trajectory effects. A control condition that applies an equivalent two-phase MLM schedule (or randomizes phase order while keeping the same objectives) is needed to separate these factors.
- [§3] §3 (experimental protocol): The claim of “identical data and compute” is central to the performance comparison, yet the manuscript does not explicitly confirm that total training steps, effective batch size, peak learning rate, and decay schedule are numerically identical between the CLM-detour runs and the MLM-only baselines. Small mismatches in optimization trajectory could account for part of the reported 0.3–2.8 pp deltas; tabulating these hyperparameters side-by-side would strengthen the result.
minor comments (2)
- [Table 1, Figure 2] Table 1 and Figure 2: per-task standard deviations or confidence intervals across seeds are not reported, making it difficult to judge whether the smaller English gains (+0.3–0.8 pp) are statistically reliable.
- [§5] §5 (discussion): The paper could briefly contrast its findings with prior work on causal vs. masked objectives in encoder-only models (e.g., references to ELECTRA or other hybrid objectives) to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments highlight important considerations for interpreting the layer ablations and ensuring experimental transparency. We address each point below and have revised the manuscript accordingly to strengthen the presentation of our results on the CLM detour for encoder continued pretraining.
read point-by-point responses
-
Referee: [§4.2] §4.2 (layer-freezing ablations): Freezing layers 0-7 during the CLM phase removes the downstream gains while freezing mid-layers preserves them, but this manipulation simultaneously alters gradient flow, update magnitudes, and the effective optimization trajectory. Because the two-phase schedule itself already changes data ordering and loss landscape relative to uniform MLM, the freezing results do not cleanly attribute the benefit to “dense low-layer supervision” versus schedule-induced trajectory effects. A control condition that applies an equivalent two-phase MLM schedule (or randomizes phase order while keeping the same objectives) is needed to separate these factors.
Authors: We agree that freezing layers modifies gradient flow and optimization dynamics. However, the two-phase schedule (CLM phase followed by MLM decay) remains fixed across all ablation conditions; only the specific layers frozen during the CLM phase vary. The observation that downstream gains are eliminated exclusively when low layers (0-7) are frozen, yet preserved when mid-layers are frozen, therefore isolates the contribution of CLM's dense supervision on low layers beyond any schedule-induced trajectory effects. The MLM decay phase is identical in length and data across conditions, and representational changes from the CLM phase persist through it. While an additional two-phase MLM control would be valuable, the layer-specific differential already provides evidence against a pure schedule explanation. We have added a clarifying paragraph in §4.2 discussing this interpretation. revision: partial
-
Referee: [§3] §3 (experimental protocol): The claim of “identical data and compute” is central to the performance comparison, yet the manuscript does not explicitly confirm that total training steps, effective batch size, peak learning rate, and decay schedule are numerically identical between the CLM-detour runs and the MLM-only baselines. Small mismatches in optimization trajectory could account for part of the reported 0.3–2.8 pp deltas; tabulating these hyperparameters side-by-side would strengthen the result.
Authors: We thank the referee for this observation. All runs were configured with identical data, total training steps, effective batch size, peak learning rate, and decay schedules to ensure matched compute. In the revised manuscript we have added Table 3, which tabulates these hyperparameters side-by-side for the CLM-detour and MLM-only conditions, explicitly confirming the numerical equivalence. revision: yes
Circularity Check
No circularity: purely empirical comparisons with independent ablations
full rationale
The paper advances no derivation chain, equations, or first-principles claims. Its central result is an empirical observation that a CLM-then-MLM schedule outperforms matched MLM-only continued pretraining on fixed biomedical corpora, measured by downstream task accuracy. Supporting evidence consists of controlled training runs (identical data and compute) plus layer-freezing ablations that directly test the proposed mechanism. These are falsifiable experimental outcomes, not reductions of a prediction to its own fitted inputs or to self-cited uniqueness theorems. No self-definitional loops, ansatzes smuggled via citation, or renaming of known results appear; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer models trained with MLM or CLM objectives learn useful representations for downstream tasks
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleartemporarily switching to Causal Language Modeling (CLM) followed by a short MLM decay improves downstream performance... Freezing low layers during CLM eliminates the downstream benefit
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclearCLM phase modifies low transformer layers far more than seed noise alone (>9× in layers 0–7)
Reference graph
Works this paper leans on
-
[1]
Gemma Team. Gemma 3 technical report.arXiv preprint arXiv:2503.19786,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Should We Still Pretrain Encoders with Masked Language Modeling?
Hippolyte Gisserot-Boukhlef, Nicolas Boizard, Manuel Faysse, Duarte M. Alves, Em- manuel Malherbe, Andr´e F. T. Martins, C´eline Hudelot, and Pierre Colombo. Should we still pretrain encoders with masked language modeling?arXiv preprint arXiv:2507.00994,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. MiniCPM: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395,
work page internal anchor Pith review arXiv
-
[4]
What would elsa do? freezing layers during transformer fine-tuning.arXiv preprint arXiv:1911.03090,
Jaejun Lee, Raphael Tang, and Jimmy Lin. What would elsa do? freezing layers during transformer fine-tuning.arXiv preprint arXiv:1911.03090,
-
[5]
Simon A. Lee, Anthony Wu, and Jeffrey N. Chiang. Clinical ModernBERT: An efficient and long context encoder for biomedical text.arXiv preprint arXiv:2504.03964,
-
[6]
Jiao Li, Yueping Sun, Robin J. Johnson, et al. BioCreative V CDR task corpus: A resource for chemical disease relation extraction.Database, 2016:baw068,
work page 2016
-
[7]
Yusheng Liao, Chaoyi Wu, Junwei Liu, et al. EHR-R1: A reasoning-enhanced foundational language model for electronic health record analysis.arXiv preprint arXiv:2510.25628,
-
[8]
Kevin Lybarger, Meliha Yetisgen, and ¨Ozlem Uzuner. The 2022 n2c2/UW shared task on extracting social determinants of health.Journal of the American Medical Informatics Association, 30(8):1367–1378,
work page 2022
-
[9]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydl ´ıˇcek, Anton Lozhkov, Margaret Mitchell, Thomas Colin, Yacine Jernite, and Thomas Wolf. FineWeb: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Johann Pignat, Milena Vucetic, Christophe Gaudet-Blavignac, et al. FRACCO: A gold- standard annotated corpus of oncological entities with ICD-O-3.1 normalisation.arXiv preprint arXiv:2510.13873,
-
[11]
Thomas Sounack, Joshua Davis, Brigitte Durieux, Antoine Chaffin, Tom J Pollard, Eric Lehman, Alistair E W Johnson, Matthew McDermott, Tristan Naumann, and Charlotta Lindvall. BioClinical ModernBERT: A state-of-the-art long-context encoder for biomedi- cal and clinical NLP.arXiv preprint arXiv:2506.10896,
-
[12]
Yu Sun, Xingyu Qian, Weiwen Xu, et al. ReasonMed: A 370k multi-agent generated dataset for advancing medical reasoning.arXiv preprint arXiv:2506.09513,
-
[13]
Rian Touchent, Nathan Godey, and Eric de la Clergerie. Biomed-enriched: A biomedi- cal dataset enriched with LLMs for pretraining and extracting rare and hidden content. arXiv preprint arXiv:2506.20331,
-
[14]
12 Preprint. Under review. Orion Weller, Kathryn Ricci, Marc Marone, Antoine Chaffin, Dawn Lawrie, and Benjamin Van Durme. Seq vs seq: An open suite of paired encoders and decoders.arXiv preprint arXiv:2507.11412,
-
[15]
Limitations Domain and language scope.All experiments use biomedical text in French and English. The CLM detour gains are larger in French (+2.8pp, 8/8 task wins) than in English (+0.3– 0.8pp, 7/11 task wins), consistent with the larger domain gap for French. The gap narrows from 10B to 50B tokens in English, suggesting that additional data partially clos...
work page 2025
-
[16]
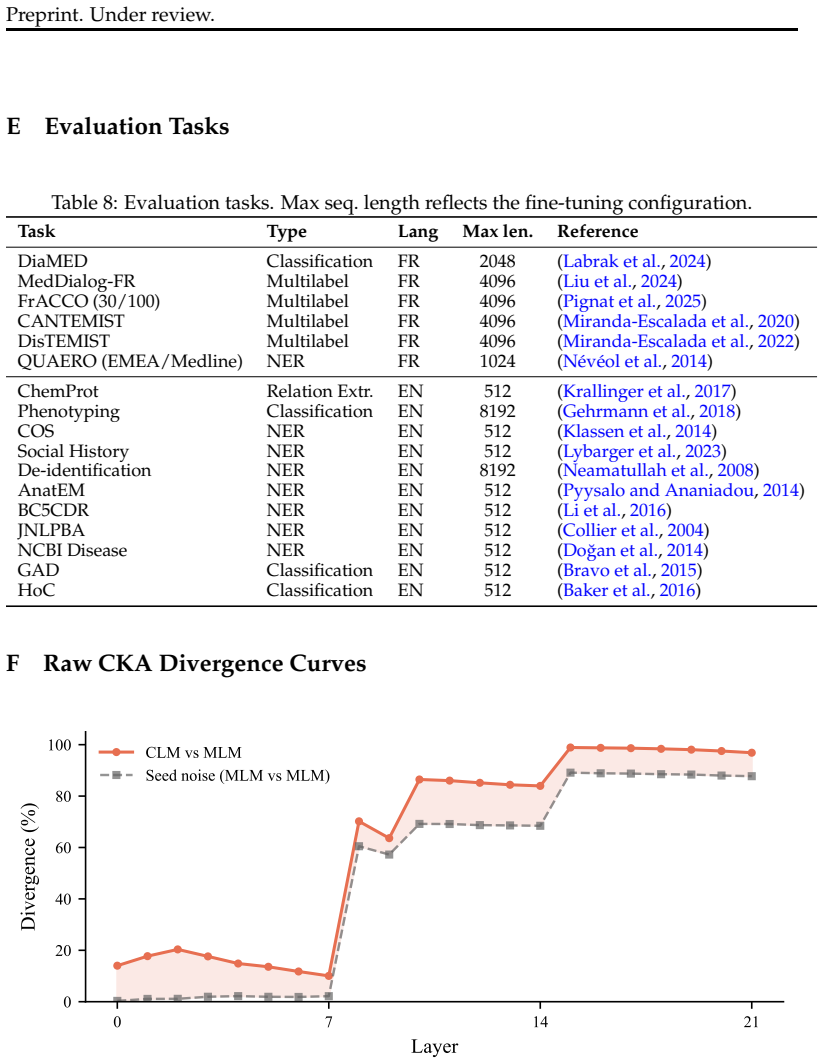
F Raw CKA Divergence Curves 0 7 14 21 Layer 0 20 40 60 80 100Divergence (%) CLM vs MLM Seed noise (MLM vs MLM) Figure 4: Per-layer CKA divergence for CLM vs MLM (coral) and seed noise (gray). Both continued pretraining objectives modify mid and deep layers heavily, but only CLM pro- duces large changes in low layers (0–7). The shaded area is the CLM-speci...
work page 2019
-
[17]
needle”) is inserted into a clinical document (the “haystack
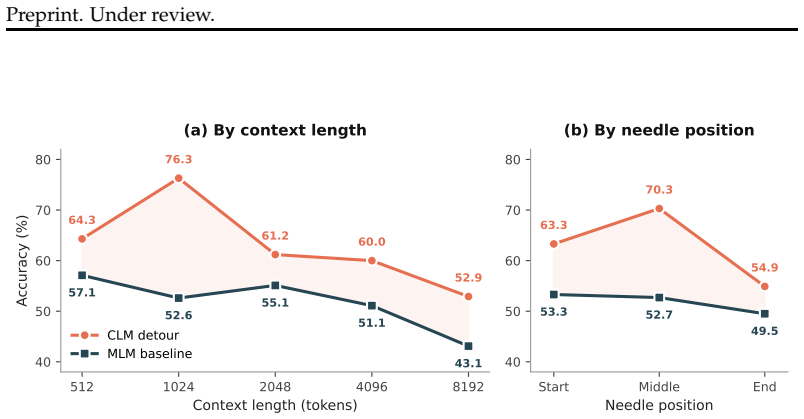
All tasks use AdamW with weight decay 0.01 and select the best checkpoint by validation F1. English tasks.We follow the BioClinical-ModernBERT evaluation protocol (Sounack et al., 2025): lr=5×10 −5, weight decay 0.01, batch size 16, 10 epochs for most tasks (20 for NER). All models are fine-tuned with the same hyperparameters per task. I Needle-in-Haystac...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.