Recognition: 2 theorem links
· Lean TheoremScalable Packed Layouts for Vector-Length-Agnostic ML Code Generation
Pith reviewed 2026-05-13 02:16 UTC · model grok-4.3
The pith
Vector-length-aware packed data layouts enable ML compilers to generate efficient vector-length-agnostic code for scalable vector hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
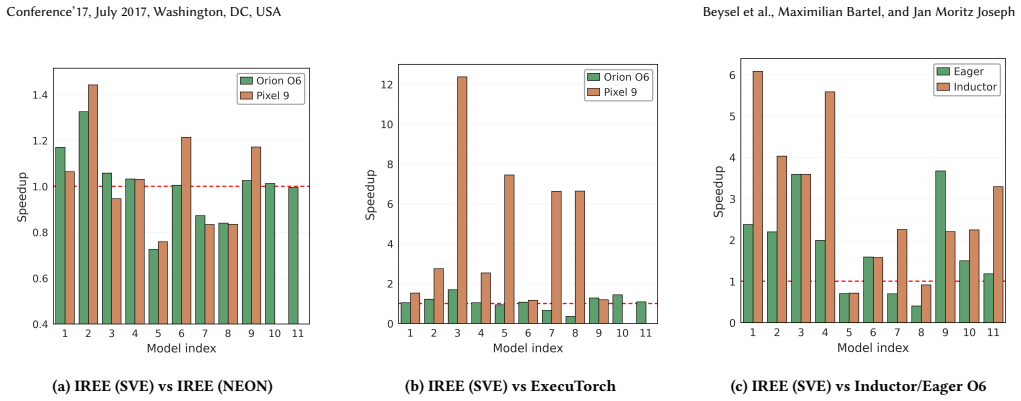
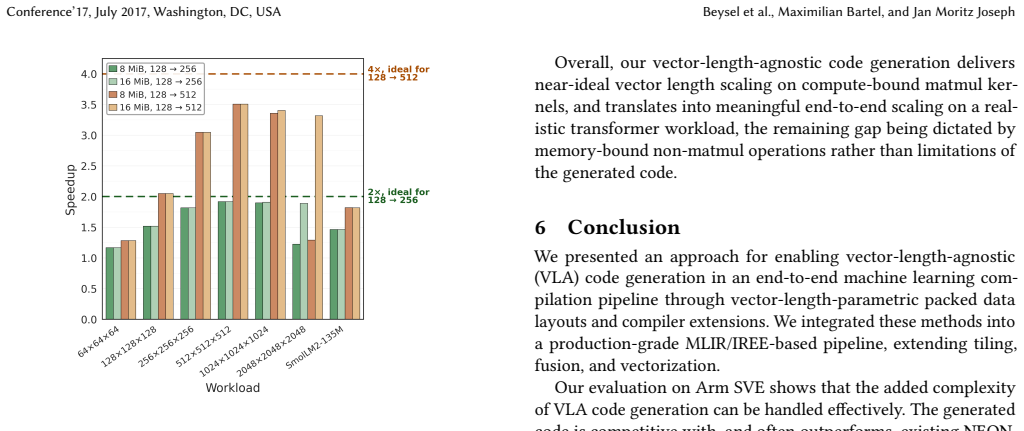
The authors argue that vector-length-aware packed data layouts together with extensions to tiling, fusion, and vectorization let an end-to-end ML compilation pipeline produce vector-length-agnostic code for scalable vector instruction sets. On real-world workloads this code is competitive with or faster than fixed-length vector generation, reaching speedups of up to 1.45 times, and the performance improves as vector length grows on compute-bound tasks.
What carries the argument
Vector-length-aware packed data layouts, which organize data so that layout decisions remain valid even when the vector length is determined only at execution time.
If this is right
- The generated scalable vector code performs competitively with fixed-length vector code on ML workloads.
- Observed speedups reach 1.45 times relative to traditional fixed-length generation.
- The code outperforms several common ML execution frameworks on the evaluated tasks.
- Performance scales upward with larger vector lengths on compute-bound workloads.
Where Pith is reading between the lines
- Similar adaptive layout techniques could address portability issues in other parallel systems where hardware parameters such as thread or lane counts are not known at compile time.
- Placing these layouts early in the compilation flow may reduce the need for later, architecture-specific rewrites.
- Extending evaluation to models with more irregular memory access patterns would test whether the approach holds beyond the compute-bound cases studied.
Load-bearing premise
The new layouts and compiler extensions integrate without introducing correctness problems, hidden runtime costs, or poor results on workloads beyond those tested.
What would settle it
Running the generated code on additional ML workloads or on hardware with vector lengths outside the tested range and measuring whether performance stays competitive with fixed-length methods; any consistent slowdown or functional errors would disprove the claim.
Figures

read the original abstract
Scalable vector instruction sets such as Arm SVE enable vector-length-agnostic (VLA) execution, allowing a single implementation to adapt across hardware with different vector lengths. However, they complicate compiler code generation, as tiling and data layout decisions can no longer be fixed at compile time. We present an approach for enabling VLA code generation in an end-to-end ML compilation pipeline through vector-length-aware packed data layouts and corresponding compiler extensions. We integrate these mechanisms into MLIR/IREE and extend tiling, fusion, and vectorization to operate with scalable vector lengths. Evaluated on real-world ML workloads on Arm CPUs, our approach generates SVE code that is competitive with, and often outperforms, existing NEON-based code generation within IREE, achieving up to $1.45\times$ speedup. We also outperform PyTorch ecosystem frameworks, including ExecuTorch, TorchInductor, and eager execution, demonstrating the effectiveness of scalable vectorization in a production compiler setting. A simulator-based study further shows that the generated code scales with increasing SVE vector length on compute-bound workloads, supporting performance portability across hardware configurations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes vector-length-aware packed data layouts together with extensions to tiling, fusion, and vectorization passes inside MLIR/IREE to enable vector-length-agnostic (VLA) code generation for scalable vector ISAs such as Arm SVE. It reports that the resulting SVE code is competitive with or faster than NEON-based generation on real Arm CPUs for ML workloads (up to 1.45× speedup), outperforms several PyTorch ecosystem frameworks, and includes a simulator study demonstrating scaling with increasing vector length on compute-bound workloads.
Significance. If the central claims hold, the work addresses a practically important obstacle to performance portability in ML compilation for VLA architectures whose vector lengths are not known at compile time. The end-to-end integration into a production compiler (IREE) and the use of real hardware measurements constitute concrete strengths; the simulator study supplies additional evidence of scalability.
major comments (2)
- [Evaluation section] Evaluation section (performance results and simulator study): the reported speedups (up to 1.45×) and the performance-portability conclusion rest on comparisons whose experimental methodology, hardware configurations, workload selection, baselines, error bars, and statistical validation are not described in sufficient detail. Without these, the data cannot be assessed as support for the central claim that the packed-layout approach is competitive and portable.
- [Simulator-based scaling study] Simulator-based scaling study (mentioned in abstract and Evaluation): the claim that the generated code scales with SVE vector length and therefore supports performance portability across hardware configurations is supported only by simulator results on compute-bound workloads. Real SVE implementations can differ in cache-line behavior, prefetching, and bandwidth scaling; if the simulator does not faithfully reproduce these interactions with the vector-length-aware layouts, the observed scaling may not translate to hardware, weakening the portability conclusion.
minor comments (1)
- [Abstract] Abstract: the sentence describing the simulator study could explicitly state the vector lengths examined and the workload characteristics (compute-bound) to give readers an immediate sense of scope.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the work's practical relevance. We address the two major comments below and will incorporate clarifications in a revised manuscript.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (performance results and simulator study): the reported speedups (up to 1.45×) and the performance-portability conclusion rest on comparisons whose experimental methodology, hardware configurations, workload selection, baselines, error bars, and statistical validation are not described in sufficient detail. Without these, the data cannot be assessed as support for the central claim that the packed-layout approach is competitive and portable.
Authors: We agree that the Evaluation section requires additional methodological detail to support reproducibility and the central claims. In the revision we will expand this section to specify the exact Arm CPU models and SVE vector lengths used, the precise workload selection criteria together with input tensor sizes, the configuration of all baselines (IREE NEON path and the listed PyTorch frameworks), the number of timed runs performed, and statistical measures such as standard deviation or error bars. These additions will allow readers to assess the reported speedups and performance-portability results directly. revision: yes
-
Referee: [Simulator-based scaling study] Simulator-based scaling study (mentioned in abstract and Evaluation): the claim that the generated code scales with SVE vector length and therefore supports performance portability across hardware configurations is supported only by simulator results on compute-bound workloads. Real SVE implementations can differ in cache-line behavior, prefetching, and bandwidth scaling; if the simulator does not faithfully reproduce these interactions with the vector-length-aware layouts, the observed scaling may not translate to hardware, weakening the portability conclusion.
Authors: We acknowledge that any simulator study necessarily abstracts certain micro-architectural effects such as cache-line behavior, prefetching, and memory-bandwidth scaling. The primary evidence for competitiveness and portability in the manuscript is the set of real-hardware measurements on Arm CPUs, where the packed-layout SVE code is shown to match or exceed the NEON baseline. The simulator results are presented only as supplementary evidence of scaling behavior on compute-bound kernels. In the revision we will add an explicit paragraph discussing the simulator's modeling assumptions and the potential gaps relative to real SVE hardware, while clarifying that the portability claims rest principally on the hardware measurements. revision: partial
Circularity Check
No circularity; claims rest on independent implementation and external evaluations
full rationale
The paper describes an engineering approach to vector-length-aware packed layouts integrated into MLIR/IREE, with extensions to tiling/fusion/vectorization. All performance claims are supported by direct measurements on real Arm SVE hardware (up to 1.45× speedup vs. NEON) and a separate simulator study on scaling. No equations, parameters, or results are defined in terms of themselves, no fitted inputs are relabeled as predictions, and no load-bearing premise reduces to a self-citation chain. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose scalable packed layouts as an abstraction for representing data layouts parameterized by the hardware vector length... tile sizes are expressed as m_r = f_m(VL), n_r = f_n(VL), k_r = f_k(VL)
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclearA simulator-based study further shows that the generated code scales with increasing SVE vector length on compute-bound workloads
Reference graph
Works this paper leans on
-
[1]
https://lists.riscv.org/g/tech-vector- ext/attachment/691/0/riscv-v-spec-1.0.pdf, 2021
The risc-v vector extension, version 1.0. https://lists.riscv.org/g/tech-vector- ext/attachment/691/0/riscv-v-spec-1.0.pdf, 2021
work page 2021
-
[2]
Arm scalable matrix extension (sme) architecture specification. https://developer. arm.com/documentation/109246/0101/, 2024
work page 2024
-
[3]
Executorch: On-device ai across mobile, embedded and edge for pytorch. https: //executorch.ai, 2026
work page 2026
-
[4]
https://github.com/google/XNNPACK, 2026
Xnnpack: High-efficiency floating-point neural network inference operators for mobile, server, and web. https://github.com/google/XNNPACK, 2026. Accessed: 2026-04-20
work page 2026
-
[5]
Adit, N., and Sampson, A.Performance left on the table: An evaluation of compiler autovectorization for risc-v.IEEE Micro 42, 5 (2022), 41–48
work page 2022
-
[6]
Anonymous artifact: Compiler extensions for scalable vector code generation, 2026
Anonymous Authors. Anonymous artifact: Compiler extensions for scalable vector code generation, 2026. Link to branch omitted due to double-blind review; will be added for final publication
work page 2026
-
[7]
Ansel, J., Y ang, E., He, H., Gimelshein, N., Jain, A., Voznesensky, M., Bao, B., Bell, P., Berard, D., Burovski, E., et al.Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation. In Scalable Packed Layouts for Vector-Length-Agnostic ML Code Generation Conference’17, July 2017, Washington, DC, USA Proceedin...
work page 2017
-
[8]
Arm Ltd.Kleidiai: Ai microkernels optimized for arm cpus. https://gitlab.arm. com/kleidi/kleidiai, 2024. GitLab repository, accessed 2026-04-22
work page 2024
-
[9]
K., Saidi, A., Basu, A., Hestness, J., Hower, D
Binkert, N., Beckmann, B., Black, G., Reinhardt, S. K., Saidi, A., Basu, A., Hestness, J., Hower, D. R., Krishna, T., Sardashti, S., et al.The gem5 simulator. ACM SIGARCH computer architecture news 39, 2 (2011), 1–7
work page 2011
-
[10]
Brank, B.Vector length agnostic SIMD parallelism on modern processor architec- tures with the focus on Arm’s SVE. PhD thesis, Ph. D. thesis, Bergische Universität Wuppertal, 2023
work page 2023
-
[11]
Carpentieri, L., VazirPanah, M., and Cosenza, B.A performance analysis of autovectorization on rvv risc-v boards. In2025 33rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP)(2025), IEEE, pp. 129–136
work page 2025
-
[12]
InTenth international workshop on frontiers in handwriting recognition(2006), Suvisoft
Chellapilla, K., Puri, S., and Simard, P.High performance convolutional neural networks for document processing. InTenth international workshop on frontiers in handwriting recognition(2006), Suvisoft
work page 2006
-
[13]
{TVM}: An automated {End-to-End} optimizing compiler for deep learning
Chen, T., Moreau, T., Jiang, Z., Zheng, L., Y an, E., Shen, H., Cowan, M., W ang, L., Hu, Y., Ceze, L., et al. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX symposium on operating systems design and implementation (OSDI 18)(2018), pp. 578–594
work page 2018
-
[14]
Goto, K., and Geijn, R. A. v. d.Anatomy of high-performance matrix mul- tiplication.ACM Transactions on Mathematical Software (TOMS) 34, 3 (2008), 1–25
work page 2008
-
[15]
Igual, F., Piñuel, L., Catalán, S., Martínez, H., Castelló, A., and Quintana- Ortí, E.Automatic generation of micro-kernels for performance portability of matrix multiplication on risc-v vector processors. InProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Net- work, Storage, and Analysis(2023), pp. 1523–1532
work page 2023
-
[16]
In Proceedings of the Workshop on Compilers for Machine Learning (C4ML) at CGO (2024)
Kalda, E., and Hutton, L.Introducing vector length agnostic programming into ml compilation: Comparing sve and sme enablement in tvm and mlir. In Proceedings of the Workshop on Compilers for Machine Learning (C4ML) at CGO (2024). Arm Ltd
work page 2024
-
[17]
Lai, H.-M., Lin, P.-H., Gokhale, M., Peng, I., Patel, H., and Lee, J.-K.Risc- v vectorization coverage for hpc: A tsvc-based analysis. InProceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis(2025), pp. 1676–1683
work page 2025
-
[18]
In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO)(2021), pp
Lattner, C., Amini, M., Bondhugula, U., Cohen, A., Davis, A., Pienaar, J., Riddle, R., Shpeisman, T., Vasilache, N., and Zinenko, O.MLIR: Scaling compiler infrastructure for domain specific computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO)(2021), pp. 2–14
work page 2021
-
[19]
Liu, H.-I. C., Brehler, M., Ravishankar, M., Vasilache, N., Vanik, B., and Laurenzo, S.Tinyiree: An ml execution environment for embedded systems from compilation to deployment.IEEE micro 42, 5 (2022), 9–16
work page 2022
-
[20]
LLVM Project. Torch-mlir. https://github.com/llvm/torch-mlir, 2026. Compiler infrastructure bridging the PyTorch and MLIR ecosystems
work page 2026
-
[21]
Lowe-Power, J., Ahmad, A. M., Akram, A., Alian, M., Amslinger, R., An- dreozzi, M., Armejach, A., Asmussen, N., Beckmann, B., Bharadwaj, S., et al. The gem5 simulator: Version 20.0+.arXiv preprint arXiv:2007.03152(2020)
-
[22]
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al.Pytorch: An imperative style, high- performance deep learning library.Advances in neural information processing systems 32(2019)
work page 2019
-
[23]
Peccia, F. N., Haxel, F., and Bringmann, O.Tensor program optimization for the risc-v vector extension using probabilistic programs. In2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD)(2025), IEEE, pp. 1–9
work page 2025
-
[24]
InEuropean Conference on Parallel Processing (2020), Springer, pp
Poenaru, A., and McIntosh-Smith, S.Evaluating the effectiveness of a vector- length-agnostic instruction set. InEuropean Conference on Parallel Processing (2020), Springer, pp. 98–114
work page 2020
-
[25]
In2019 International Conference on High Performance Computing & Simulation (HPCS)(2019), IEEE, pp
Pohl, A., Greese, M., Cosenza, B., and Juurlink, B.A performance analysis of vector length agnostic code. In2019 International Conference on High Performance Computing & Simulation (HPCS)(2019), IEEE, pp. 159–164
work page 2019
-
[26]
Remke, S., and Breuer, A.Hello sme! generating fast matrix multiplication kernels using the scalable matrix extension. InSC24-W: Workshops of the Inter- national Conference for High Performance Computing, Networking, Storage and Analysis(2024), IEEE, pp. 1443–1454
work page 2024
-
[27]
RIKEN Center for Computational Science and Fujitsu. Supercomputer fugaku, 2021. Arm-based A64FX processor, world-leading HPC system
work page 2021
-
[28]
M., V an De Geijn, R., Smelyanskiy, M., Hammond, J
Smith, T. M., V an De Geijn, R., Smelyanskiy, M., Hammond, J. R., and V an Zee, F. G.Anatomy of high-performance many-threaded matrix multiplication. In 2014 IEEE 28th International Parallel and Distributed Processing Symposium(2014), IEEE, pp. 1049–1059
work page 2014
-
[29]
Stephens, N., Biles, S., Boettcher, M., Eapen, J., Eyole, M., Gabrielli, G., Horsnell, M., Magklis, G., Martinez, A., Premillieu, N., et al.The arm scalable vector extension.IEEE micro 37, 2 (2017), 26–39
work page 2017
-
[30]
Accelerated pytorch inference with torch.compile on aws graviton processors
Sunita Nadampalli. Accelerated pytorch inference with torch.compile on aws graviton processors. https://pytorch.org/blog/accelerated-pytorch-inference/, July 2024. Accessed: 2026-04-20
work page 2024
-
[31]
Van Zee, F. G., and van de Geijn, R. A.BLIS: A framework for rapidly instan- tiating BLAS functionality.ACM Transactions on Mathematical Software 41, 3 (June 2015), 14:1–14:33
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.