Recognition: no theorem link
The Algorithmic Caricature: Auditing LLM-Generated Political Discourse Across Crisis Events
Pith reviewed 2026-05-13 04:19 UTC · model grok-4.3
The pith
LLM-generated political discourse during crises is fluent but less realistic at the population level than real social media posts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
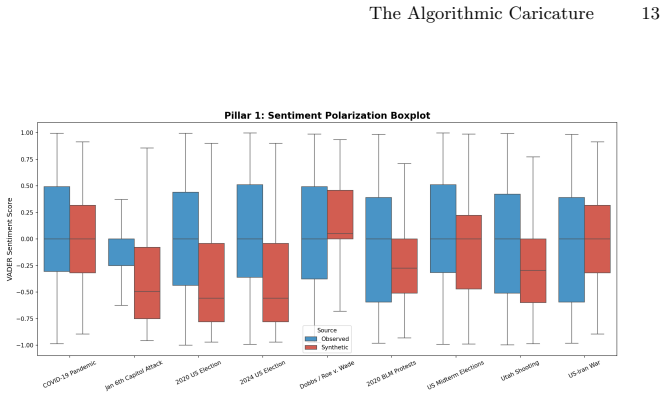
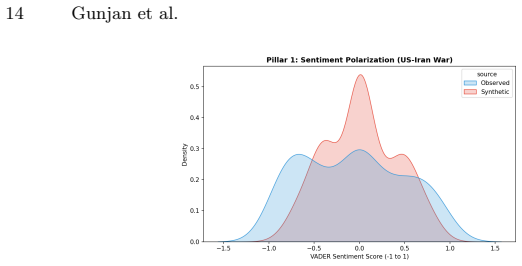
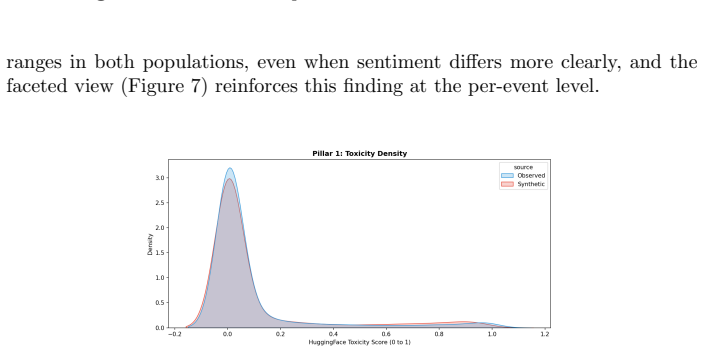
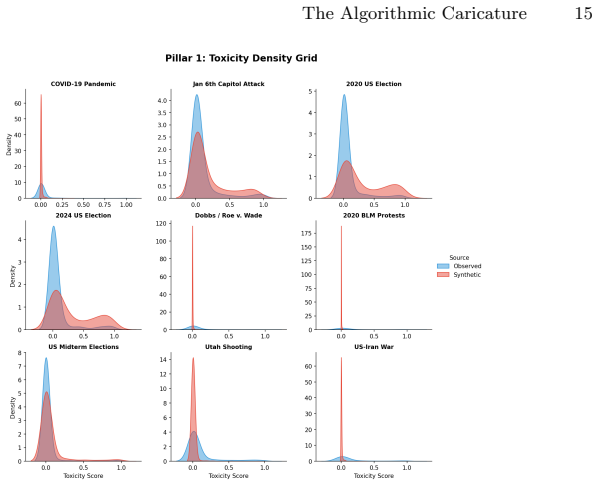
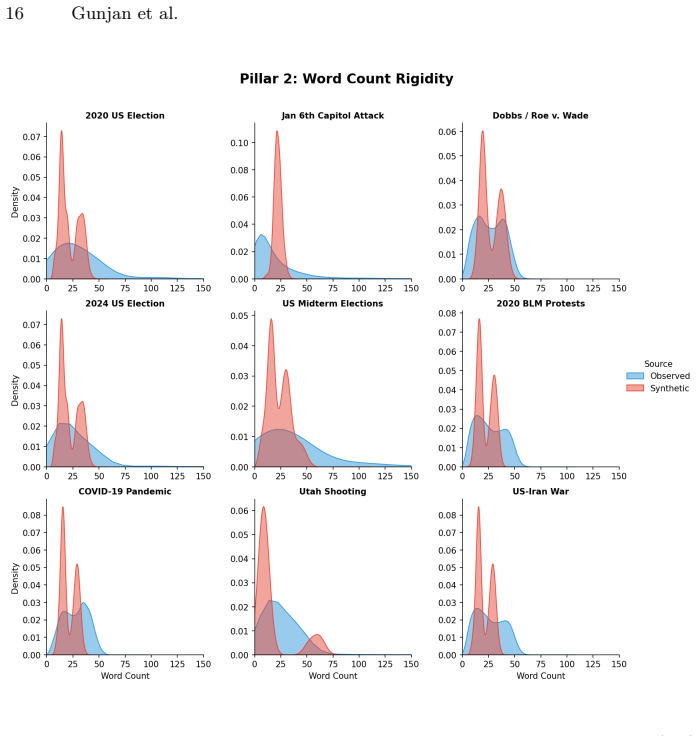
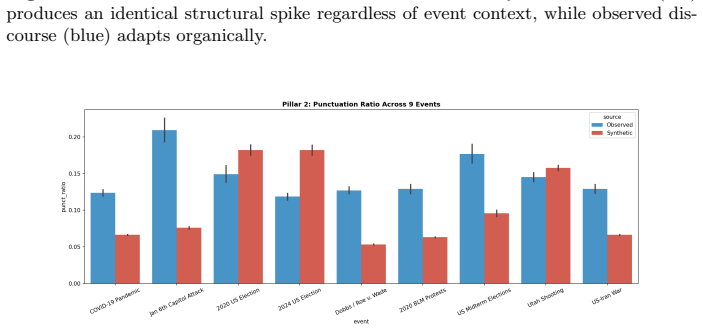
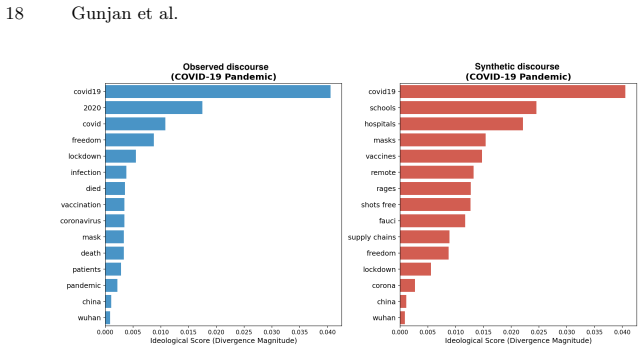
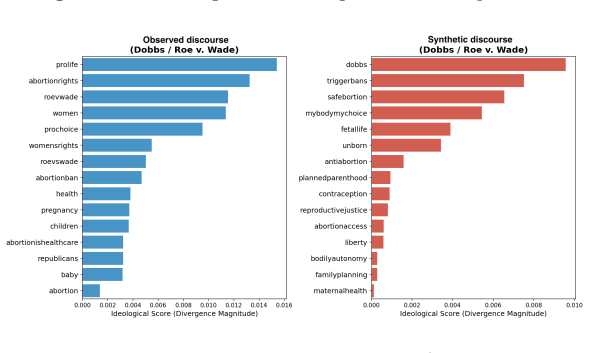
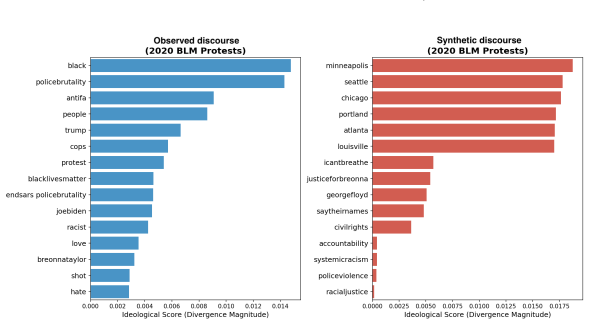
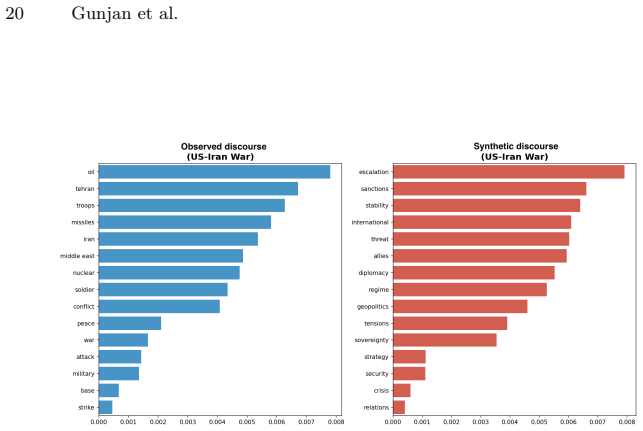
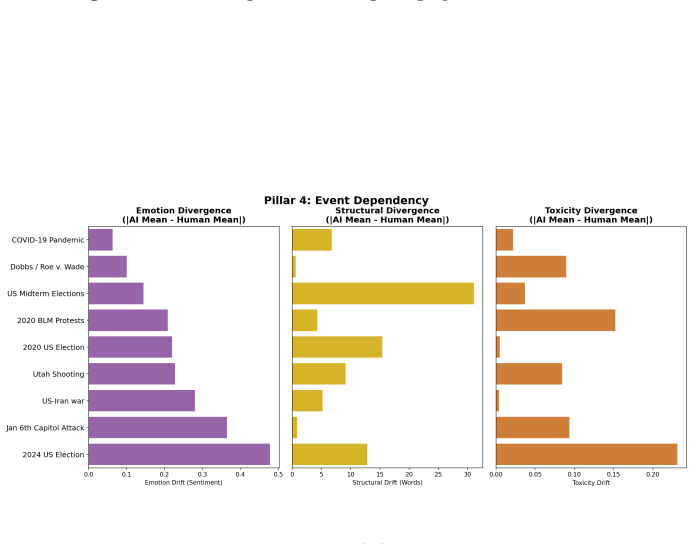
Across the nine events, synthetic discourse shows greater negativity and lower sentiment dispersion, higher structural regularity, and more abstract lexical-ideological markers than observed discourse. Observed posts instead display broader emotional variation, longer-tailed structural distributions, and more context-specific colloquial elements. These gaps vary by event type, with larger differences in fast-moving decentralized crises, and are summarized by an event-level Caricature Gap measure. The central finding is that the primary limitation of LLM political discourse is reduced population realism rather than basic fluency.
What carries the argument
The Caricature Gap, an event-level summary measure of differences in emotional intensity, structural regularity, lexical-ideological framing, and cross-event dependency between synthetic and observed discourse.
If this is right
- Synthetic discourse tends to amplify uniformly negative tones without the emotional breadth seen in real populations.
- Population-level statistics such as dispersion and tail behavior provide a more durable signal than sentence-level fluency cues for auditing generated text.
- The size of the realism gap depends on crisis type, being larger for decentralized fast-moving events.
- Observed discourse carries more event-specific colloquial and ideological markers that synthetic versions abstract away.
Where Pith is reading between the lines
- Prompt engineering or fine-tuning aimed at increasing output variance could reduce the observed gaps without changing model architecture.
- The same auditing approach might expose similar population-level shortfalls when LLMs generate discourse in non-political domains such as health or economic discussions.
- Models that explicitly incorporate population sampling during generation could better approximate real discourse distributions for simulation tasks.
Load-bearing premise
That the chosen LLM prompts and generation settings produce a representative sample of what synthetic political discourse would look like when used in the wild.
What would settle it
Generating new synthetic discourse with alternative prompts or models for the same nine events and finding that it matches the observed levels of sentiment dispersion, structural tail length, and context-specific lexical markers.
Figures








read the original abstract
Large Language Models (LLMs) can generate fluent political text at scale, raising concerns about synthetic discourse during crises and social conflict. Existing AI-text detection often focuses on sentence-level cues such as perplexity, burstiness, or token irregularities, but these signals may weaken as generative systems improve. We instead adopt a Computational Social Science perspective and ask whether synthetic political discourse behaves like an observed online population. We construct a paired corpus of 1,789,406 posts across nine crisis events: COVID-19, the Jan. 6 Capitol attack, the 2020 and 2024 U.S. elections, Dobbs/Roe v. Wade, the 2020 BLM protests, U.S. midterms, the Utah shooting, and the U.S.-Iran war. For each event, we compare observed discourse from social platforms with synthetic discourse generated for the same context. We evaluate four dimensions: emotional intensity, structural regularity, lexical-ideological framing, and cross-event dependency, using mean gaps and dispersion evidence. Across events, synthetic discourse is fluent but population-level unrealistic. It is generally more negative and less dispersed in sentiment, structurally more regular, and lexically more abstract than observed discourse. Observed discourse instead shows broader emotional variation, longer-tailed structural distributions, and more context-specific, colloquial lexical markers. These differences are event-dependent: larger for fast-moving, decentralized crises and smaller for formal or institutionally mediated events. We summarize them with a simple event-level measure, the Caricature Gap. Our findings suggest that the main limitation of synthetic political discourse is not grammar or fluency, but reduced population realism. Population-level auditing complements traditional text-detection and provides a CSS framework for evaluating the social realism of generated discourse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs paired corpora of 1.79M observed social-media posts and LLM-generated synthetic posts across nine crisis events (COVID-19, Jan. 6, elections, Dobbs, BLM, etc.). It compares the two on four dimensions—emotional intensity, structural regularity, lexical-ideological framing, and cross-event dependency—using mean gaps and dispersion statistics, reports that synthetic discourse is systematically more negative, less dispersed, more regular, and more abstract, and summarizes the differences with an event-level “Caricature Gap” metric. The central claim is that the primary shortcoming of synthetic political discourse is reduced population realism rather than lack of fluency, with the size of the gap varying by event type.
Significance. If the empirical comparisons survive scrutiny of prompt construction and sampling, the work supplies a population-level auditing framework that complements token-level detection methods and offers a reproducible CSS lens for evaluating the social realism of generated crisis discourse. The event-dependence finding and the Caricature Gap metric are potentially useful for future studies of synthetic content in polarized settings.
major comments (3)
- [Methods (synthetic data generation)] Methods section on synthetic generation: the exact prompt templates, system instructions, temperature, top-p, and any role-play or chain-of-thought elements are not reported in sufficient detail. Because the central claim attributes the observed caricature (more negative, less dispersed, more regular text) to inherent properties of LLM discourse, the absence of these parameters leaves open the possibility that the gaps are artifacts of minimal zero-shot prompting rather than general model behavior.
- [Results (Caricature Gap)] Results, Caricature Gap definition: the paper introduces the Caricature Gap as a simple event-level aggregate but does not supply an explicit formula or weighting scheme that combines the four dimension-wise mean gaps and dispersion statistics. Without this, the reported event dependence (larger gaps for fast-moving crises) cannot be reproduced or tested for robustness to alternative aggregations.
- [Data collection] Data and sampling: while the observed corpus size is given, the precise platform sources, keyword filters, temporal windows, and deduplication steps for each of the nine events are not stated. This matters because any mismatch in topical coverage or user demographics between observed and synthetic samples directly affects the validity of the population-realism comparison.
minor comments (2)
- [Abstract] Abstract: the phrase “mean gaps and dispersion evidence” is used without a one-sentence gloss; adding a parenthetical definition would improve immediate readability.
- [Throughout] Notation: the four dimensions are referred to interchangeably as “emotional intensity,” “sentiment,” and “emotional variation”; consistent terminology across sections would reduce ambiguity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which has improved the transparency and reproducibility of our work. We address each major comment below and have revised the manuscript to provide the requested details.
read point-by-point responses
-
Referee: [Methods (synthetic data generation)] Methods section on synthetic generation: the exact prompt templates, system instructions, temperature, top-p, and any role-play or chain-of-thought elements are not reported in sufficient detail. Because the central claim attributes the observed caricature (more negative, less dispersed, more regular text) to inherent properties of LLM discourse, the absence of these parameters leaves open the possibility that the gaps are artifacts of minimal zero-shot prompting rather than general model behavior.
Authors: We thank the referee for highlighting this omission. In the revised manuscript we have added a new subsection in Methods that reports the exact prompt templates (event-context only), system instructions (neutral and non-directive), temperature=0.7, top-p=0.9, and confirms the absence of role-play or chain-of-thought. The prompting was deliberately minimal and zero-shot to align synthetic posts with observed event contexts without introducing additional bias. With these parameters now fully specified, readers can evaluate whether the caricature effects are prompting artifacts or reflect broader model tendencies; we maintain that the central claim is supported under the reported conditions. revision: yes
-
Referee: [Results (Caricature Gap)] Results, Caricature Gap definition: the paper introduces the Caricature Gap as a simple event-level aggregate but does not supply an explicit formula or weighting scheme that combines the four dimension-wise mean gaps and dispersion statistics. Without this, the reported event dependence (larger gaps for fast-moving crises) cannot be reproduced or tested for robustness to alternative aggregations.
Authors: We agree that an explicit formula is required for reproducibility. We have revised the Results section to include the precise definition: the Caricature Gap is the unweighted average of four standardized gaps, where each dimension gap is (observed mean – synthetic mean) / pooled standard deviation, augmented by a dispersion component (1 – IQR ratio). The formula appears as Equation 1, with equal weighting across dimensions. We also added robustness checks using alternative weightings in the appendix, confirming that the event-dependence pattern (larger gaps for fast-moving crises) is stable. revision: yes
-
Referee: [Data collection] Data and sampling: while the observed corpus size is given, the precise platform sources, keyword filters, temporal windows, and deduplication steps for each of the nine events are not stated. This matters because any mismatch in topical coverage or user demographics between observed and synthetic samples directly affects the validity of the population-realism comparison.
Authors: We accept that these sampling details are necessary for assessing validity. The revised Data Collection section now specifies, for each event: primary platforms (Twitter/X for seven events, Reddit for BLM and Dobbs), exact keyword filters and hashtags, temporal windows (e.g., COVID-19: 1 March–30 June 2020), and deduplication (exact-match removal plus cosine-similarity threshold of 0.95 for near-duplicates). Synthetic posts were generated using the same event descriptors to maintain topical alignment. These additions allow direct evaluation of coverage and demographic comparability. revision: yes
Circularity Check
No circularity; claims rest on direct empirical corpus comparisons
full rationale
The paper constructs paired observed and synthetic corpora across nine events and performs direct statistical comparisons on four dimensions (emotional intensity, structural regularity, lexical framing, cross-event dependency) plus the derived Caricature Gap summary. No equations, fitted parameters, or first-principles derivations appear that reduce by construction to the inputs or to self-citations. The central finding that synthetic discourse is more negative, regular, and abstract is an empirical observation from the data, not a prediction forced by model assumptions or prior author results. The analysis is self-contained against external benchmarks of real social media text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be prompted to produce contextually relevant political text for crisis events
Reference graph
Works this paper leans on
-
[1]
Ahmed, M. (2026). Youth, social media, and political slogans (abusive words, slangs) in bangladesh: A contemporary evaluation.Social Media, and Po- litical Slogans (Abusive Words, Slangs) in Bangladesh: A Contemporary Evaluation (January 08, 2026). Argyle et al.,
work page 2026
-
[2]
Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J. R., Rytting, C., and Wingate, D. (2023). Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337–351. Balasubramanian et al.,
work page 2023
- [3]
-
[4]
Chang, R.-C., Rao, A., Zhong, Q., Wojcieszak, M., and Lerman, K. (2023). #RoeOverturned: Twitter dataset on the abortion rights controversy. InPro- ceedings of the International AAAI Conference on Web and Social Media (ICWSM), volume 17, pages 997–1005. Chen et al.,
work page 2023
-
[5]
Chen, E., Lerman, K., and Ferrara, E. (2020). Tracking social me- dia discourse about the COVID-19 pandemic: Development of a public coronavirus twitter data set.JMIR Public Health and Surveillance, 6(2):e19273. Chuang et al.,
work page 2020
-
[6]
Chuang, Y.-S., Goyal, A., Harlalka, N., Suresh, S., Hawkins, R., Yang, S., Shah, D., Hu, J., and Rogers, T. T. (2024). Simulating opinion dynamics with networks of LLM-based agents. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 3326–3346, Mexico City, Mexico. Association for Computational Linguistics. Cinelli et al.,
work page 2024
-
[7]
Cinelli, M., De Francisci Morales, G., Galeazzi, A., Quattrociocchi, W., and Starnini, M. (2021). The echo chamber effect on social media.Proceedings of the National Academy of Sciences, 118(9):e2023301118. The Algorithmic Caricature 25 Crothers et al.,
work page 2021
-
[8]
N., Japkowicz, N., and Viktor, H
Crothers, E. N., Japkowicz, N., and Viktor, H. L. (2023). Machine-generated text: A comprehensive survey of threat models and detection methods.IEEE Access, 11:70977–71002. Dugan et al.,
work page 2023
-
[9]
M., Xu, H., Ippolito, D., and Callison-Burch, C
Dugan, L., Hwang, A., Trhl´ ık, F., Zhu, A., Ludan, J. M., Xu, H., Ippolito, D., and Callison-Burch, C. (2024). RAID: A shared benchmark for robust evaluation of machine-generated text detectors. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12463–12492, Bangkok, Thailand. Associat...
work page 2024
-
[10]
Fagni, T., Falchi, F., Gambini, M., Martella, A., and Tesconi, M. (2021). TweepFake: About detecting deepfake tweets.PLOS ONE, 16(5):e0251415. Falkenberg et al.,
work page 2021
-
[11]
Falkenberg, M., Galeazzi, A., Torricelli, M., Di Marco, N., Larosa, F., Sas, M., Mekacher, A., Pearce, W., Zollo, F., Quattrociocchi, W., and Baronchelli, A. (2024). Patterns of partisan toxicity and engagement reveal the common structure of online political communication across countries.Nature Com- munications, 15:9560. Feng et al.,
work page 2024
-
[12]
Feng, S., Park, C. Y., Liu, Y., and Tsvetkov, Y. (2023). From pre- training data to language models to downstream tasks: Tracking the trails of political biases leading to unfair NLP models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11737– 11762, Toronto, Canada. Association fo...
work page 2023
-
[13]
Gehrmann, S., Strobelt, H., and Rush, A. M. (2019). GLTR: Statistical detection and visualization of generated text. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demon- strations, pages 111–116, Florence, Italy. Association for Computational Linguistics. Hans et al.,
work page 2019
-
[14]
Hans, A., Schwarzschild, A., Cherepanova, V., Kazemi, H., Saha, A., Goldblum, M., Geiping, J., and Goldstein, T. (2024). Spotting LLMs with binoc- ulars: Zero-shot detection of machine-generated text. InProceedings of the 41st International Conference on Machine Learning (ICML), volume 235 ofProceedings of Machine Learning Research, pages 17519–17537. PML...
work page 2024
-
[15]
Hanu, L. and Unitary Team (2020). Detoxify. GitHub repository. Model:unitary/toxic-bert. Hasan and Paul,
work page 2020
-
[16]
Hasan, M. and Paul, A. (2025). The role of social media in political mobilization: a systematic review.Business & Social Sciences, 3(1):1–8. He et al.,
work page 2025
-
[17]
He, B., Mokhberian, N., Cˆ amara, A., Abeliuk, A., and Lerman, K. (2024). Affective polarization and dynamics of information spread in online networks. npj Complexity, 1:8. Hutto and Gilbert,
work page 2024
-
[18]
Hutto, C. and Gilbert, E. (2014). VADER: A parsimonious rule-based model for sentiment analysis of social media text. InProceedings of the 8th International AAAI Conference on Weblogs and Social Media (ICWSM), pages 216–225. AAAI Press. Kehkashan et al.,
work page 2014
-
[19]
Kehkashan, T., Riaz, R. A., Al-Shamayleh, A. S., Akhunzada, A., Ali, N., Hamza, M., and Akbar, F. (2025). Ai-generated text detection: A com- prehensive review of methods, datasets, and applications.Computer Science Review, 58:100793. Kirchenbauer et al.,
work page 2025
-
[20]
Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., and Goldstein, T. (2023). A watermark for large language models. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 202 of Proceedings of Machine Learning Research, pages 17061–17084. PMLR. Kumarage et al.,
work page 2023
- [21]
-
[22]
S., Merizalde, J., Colautti, J
Lee, C. S., Merizalde, J., Colautti, J. D., An, J., and Kwak, H. (2022). Storm the Capitol: Linking offline political speech and online Twitter extra- representational participation on QAnon and the January 6 insurrection.Frontiers in Sociology, 7:876070. Lu et al.,
work page 2022
-
[23]
Lu, M., He, Z., Guo, Y., Liu, S., Huang, J., Zhao, Y., Tian, Z., Zhao, X., Shao, C., Deng, L., et al. (2026). Llm-driven adversarial example synthesis for emerging topic rumor detection on social media.IEEE Transactions on Knowledge and Data Engineering. Mitchell et al.,
work page 2026
-
[24]
Mitchell, E., Lee, Y., Khazatsky, A., Manning, C. D., and Finn, C. (2023). DetectGPT: Zero-shot machine-generated text detection using probability curvature. InProceedings of the 40th International Conference on Machine Learning (ICML), volume 202 ofProceedings of Machine Learning Research, pages 24950– 24962. PMLR. Orgeret et al.,
work page 2023
-
[25]
S., Mutsvairo, B., de Bruijn, M., Schroeder, D
Orgeret, K. S., Mutsvairo, B., de Bruijn, M., Schroeder, D. T., Badji, S. D., and Moges, M. A. (2026). Hashtags, hatetags and social media campaigns in ethiopia’s tigray conflict.Information, Communication & Society, 29(3):850–868. Park et al.,
work page 2026
-
[26]
Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), pages 1–22, San Francisco, CA, USA. ACM. Sadasivan et al.,
work page 2023
-
[27]
S., Kumar, A., Balasubramanian, S., Wang, W., and Feizi, S
Sadasivan, V. S., Kumar, A., Balasubramanian, S., Wang, W., and Feizi, S. (2023). Can AI-generated text be reliably detected?arXiv preprint arXiv:2303.11156. Spitale et al.,
-
[28]
Spitale, G., Biller-Andorno, N., and Germani, F. (2023). AI model GPT-3 (dis)informs us better than humans.Science Advances, 9(26):eadh1850. Theocharis and Jungherr,
work page 2023
-
[29]
Theocharis, Y. and Jungherr, A. (2024). Introduc- tion: Computational social science and the study of political communication. In Computational Political Communication, pages 1–22. Routledge. T¨ ornberg et al.,
work page 2024
- [30]
-
[31]
Verma, V., Fleisig, E., Tomlin, N., and Klein, D. (2024). Ghost- buster: Detecting text ghostwritten by large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies (NAACL-HLT), pages 1702–1717, Mexico City, Mexico. Association for Computational Li...
work page 2024
-
[32]
(2022).Making sense of media and politics: Five prin- ciples in political communication
Wolfsfeld, G. (2022).Making sense of media and politics: Five prin- ciples in political communication. Routledge. Wu,
work page 2022
-
[33]
Wu, J. e. a. (2025). A survey on llm generated text detection necessity, methods, and future directions.Computational Linguistics, 51(1):275–338. Zellers et al.,
work page 2025
-
[34]
Zellers, R., Holtzman, A., Rashkin, H., Bisk, Y., Farhadi, A., Roes- ner, F., and Choi, Y. (2019). Defending against neural fake news. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.