Recognition: no theorem link
LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues
Pith reviewed 2026-05-13 03:43 UTC · model grok-4.3
The pith
A coding-agent memory method called AgentRunbook-C reaches 72.5 percent accuracy on a benchmark of 451 questions that test whether agents can internalize environment-specific experience.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
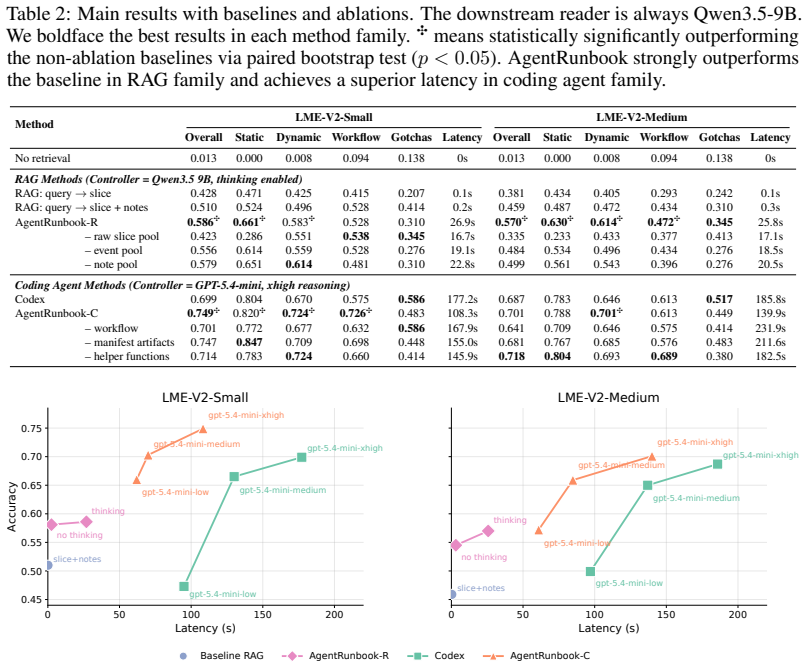
LongMemEval-V2 uses a context-gathering formulation in which memory systems ingest long history trajectories and return compact evidence for question answering. AgentRunbook-C stores trajectories as files and invokes a coding agent to gather evidence, achieving 72.5 percent average accuracy across the five memory abilities. This outperforms the strongest RAG baseline at 48.5 percent and an off-the-shelf coding-agent baseline at 69.3 percent, advancing the accuracy-latency frontier even though latency remains high and further gains are needed.
What carries the argument
AgentRunbook-C stores trajectories as files and invokes a coding agent to gather evidence inside an augmented sandbox; it replaces pure retrieval with executable code that can inspect and manipulate the stored history.
If this is right
- Direct measurement of internalized experience becomes possible without relying solely on downstream task success.
- Coding-based retrieval can scale to histories of hundreds of trajectories and over 100 million tokens more effectively than standard RAG.
- Accuracy gains from AgentRunbook-C come with substantially higher latency, establishing a new point on the accuracy-latency trade-off.
- Current memory methods still leave substantial room for improvement before agents match experienced human colleagues on environment-specific knowledge.
- The five abilities provide a structured target for developing future long-term memory systems.
Where Pith is reading between the lines
- If the benchmark proves predictive, it could guide iterative improvement of memory systems before they are deployed in production environments.
- The file-plus-coding approach may transfer to other long-horizon agent settings where histories contain structured but noisy interaction traces.
- Hybrid systems that combine lightweight retrieval with selective coding queries could reduce latency while preserving most of the accuracy gain.
- Wider adoption of such benchmarks would shift evaluation focus from short traces to cumulative experience over hundreds of interactions.
Load-bearing premise
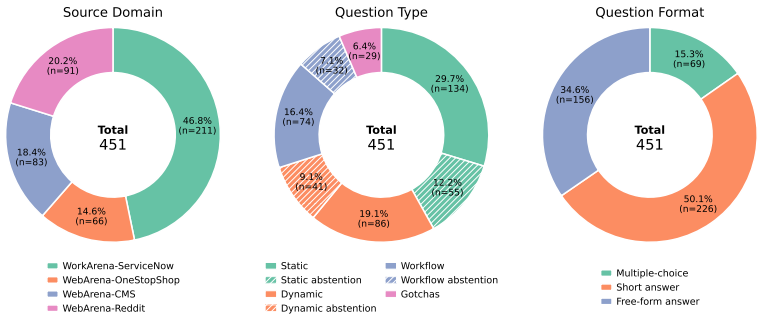
The 451 manually curated questions accurately and comprehensively measure the five core memory abilities that experienced colleagues need in customized web environments.
What would settle it
An experiment in which agents that score high on LongMemEval-V2 still fail to apply the same recalled knowledge during extended live interactions with the actual web environment.
Figures





read the original abstract
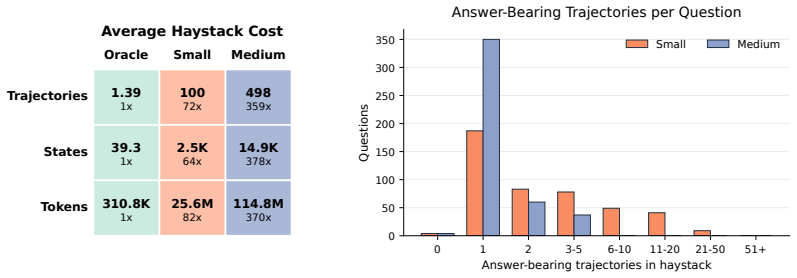
Long-term memory is crucial for agents in specialized web environments, where success depends on recalling interface affordances, state dynamics, workflows, and recurring failure modes. However, existing memory benchmarks for agents mostly focus on user histories, short traces, or downstream task success, leaving open how to directly evaluate whether memory systems effectively internalize environment-specific experience. To address this gap, we introduce LongMemEval-V2 (LME-V2), a benchmark for evaluating whether memory systems can help agents acquire the experience needed to become knowledgeable colleagues in customized environments. LME-V2 contains 451 manually curated questions covering five core memory abilities for web agents: static state recall, dynamic state tracking, workflow knowledge, environment gotchas, and premise awareness. Questions are paired with history trajectories containing up to 500 trajectories and 115M tokens. We use a context gathering formulation: memory systems consume history trajectories and return compact evidence for downstream question answering. We propose a suite of two memory methods: AgentRunbook-R, an efficient RAG-based memory with knowledge pools for raw state observations, events, and strategy notes, and AgentRunbook-C, which stores trajectories as files and invokes a coding agent to gather evidence in an augmented sandbox. Experiments show that AgentRunbook-C achieves the best performance with 72.5% average accuracy, outperforming the strongest RAG baseline (48.5%) and the off-the-shelf coding agent baseline (69.3%). Despite the strong performance gains, coding agent based methods have high latency costs. While AgentRunbook-C advances the accuracy-latency Pareto frontier, substantial room for improvement remains. Together, these results establish LME-V2 as a challenging testbed for developing long-term memory systems for environment experience.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LongMemEval-V2 (LME-V2), a benchmark of 451 manually curated questions paired with long agent history trajectories (up to 500 trajectories and 115M tokens) to directly evaluate whether memory systems enable agents to internalize experience as knowledgeable colleagues in customized web environments. It defines five core abilities (static state recall, dynamic state tracking, workflow knowledge, environment gotchas, premise awareness) and proposes two methods: AgentRunbook-R (RAG-based with knowledge pools for states, events, and strategies) and AgentRunbook-C (trajectory storage as files with coding-agent evidence gathering in an augmented sandbox). Experiments report AgentRunbook-C at 72.5% average accuracy, outperforming the strongest RAG baseline (48.5%) and off-the-shelf coding agent (69.3%), while noting latency costs and room for improvement.
Significance. If the benchmark questions are shown to validly and unbiasedly probe the targeted abilities, LME-V2 supplies a needed direct testbed for long-term memory internalization in specialized environments, moving beyond user-history or task-success proxies. The empirical comparison credibly positions coding-augmented retrieval as advancing the accuracy-latency frontier relative to pure RAG, providing concrete baselines and a challenging scale (115M tokens) for future work on agent memory.
major comments (2)
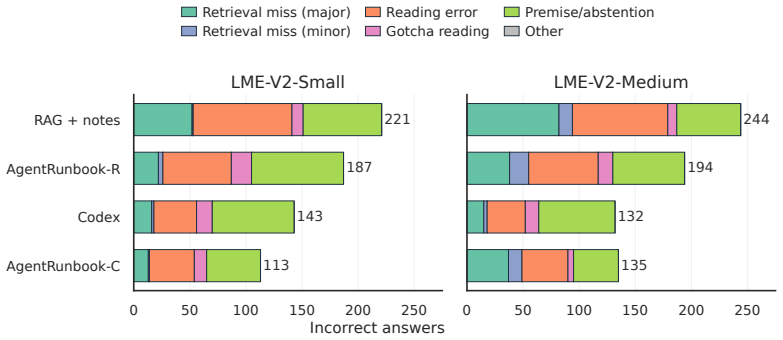
- [Abstract and benchmark construction] Abstract and benchmark description: The central performance claims (AgentRunbook-C at 72.5% vs. 48.5% RAG and 69.3% coding baseline) rest on the premise that the 451 manually curated questions comprehensively and without bias measure the five stated memory abilities. No inter-annotator agreement, coverage audit against the five abilities, adversarial question filtering, or external validation is reported, leaving open the possibility that deltas reflect curation artifacts rather than genuine memory internalization.
- [Experiments] Experiments section: The headline accuracy figures are given as point estimates without error bars, statistical significance tests, per-ability breakdowns, or controls for question difficulty variance across environments, which is required to substantiate that AgentRunbook-C meaningfully advances the Pareto frontier.
minor comments (1)
- [Abstract] The abstract notes high latency for coding-agent methods but provides no quantitative latency numbers or trade-off curves, which would strengthen the Pareto-frontier claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important aspects of benchmark validity and experimental reporting that we address point-by-point below. We have revised the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [Abstract and benchmark construction] Abstract and benchmark description: The central performance claims (AgentRunbook-C at 72.5% vs. 48.5% RAG and 69.3% coding baseline) rest on the premise that the 451 manually curated questions comprehensively and without bias measure the five stated memory abilities. No inter-annotator agreement, coverage audit against the five abilities, adversarial question filtering, or external validation is reported, leaving open the possibility that deltas reflect curation artifacts rather than genuine memory internalization.
Authors: We appreciate the referee's emphasis on rigorous benchmark validation. The 451 questions were constructed by the authors according to explicit criteria for each of the five abilities (detailed in Section 3.2 of the manuscript), with each question designed to require internalization of specific history elements that general knowledge or surface-level retrieval cannot provide. In the revised version, we will expand the benchmark construction section to include: (1) the full curation guidelines used by the authors, (2) a coverage table showing the number of questions per ability, and (3) representative examples for each ability. While formal inter-annotator agreement statistics were not computed during initial curation, all questions underwent cross-review by multiple authors to ensure alignment with the target abilities; we will report this process and acknowledge the absence of IAA as a limitation. We will also add a discussion of potential curation artifacts and note that the distinct performance patterns across methods (e.g., AgentRunbook-C excelling on dynamic tracking while RAG lags on workflow knowledge) provide evidence that the questions discriminate based on memory mechanisms rather than artifacts alone. External validation against other benchmarks is planned for future work but is outside the scope of the current submission. revision: partial
-
Referee: [Experiments] Experiments section: The headline accuracy figures are given as point estimates without error bars, statistical significance tests, per-ability breakdowns, or controls for question difficulty variance across environments, which is required to substantiate that AgentRunbook-C meaningfully advances the Pareto frontier.
Authors: We agree that the experimental section would benefit from greater statistical detail. The reported figures (72.5%, 48.5%, 69.3%) represent mean accuracy across all 451 questions. In the revised manuscript, we will: (1) add bootstrap-derived 95% confidence intervals as error bars for the primary results, (2) include a per-ability performance breakdown (new Table or Figure) showing accuracy for static state recall, dynamic state tracking, workflow knowledge, environment gotchas, and premise awareness separately, and (3) provide an analysis of performance stratified by trajectory length and environment to control for difficulty variance. We will also report statistical significance of the differences using appropriate tests (e.g., McNemar's test for paired accuracy comparisons). These additions will more clearly demonstrate that AgentRunbook-C advances the accuracy-latency frontier beyond the baselines. revision: yes
Circularity Check
No circularity: purely empirical benchmark evaluation with no derivations or self-referential reductions.
full rationale
The paper introduces LME-V2 as a new manually-curated benchmark of 451 questions across five memory abilities, pairs them with history trajectories, and reports empirical accuracy numbers for proposed memory methods (AgentRunbook-C at 72.5%) versus baselines. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the derivation chain; the central claims are direct experimental comparisons on the introduced testbed. The validity of the question set is an external concern but does not create circularity within the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manually curated questions can accurately and comprehensively assess the five specified memory abilities for web agents.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2402.13718, 2024b
Xinrong Zhang and Yingfa Chen and Shengding Hu and Zihang Xu and Junhao Chen and Moo Khai Hao and Xu Han and Zhen Leng Thai and Shuo Wang and Zhiyuan Liu and Maosong Sun , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.13718 , eprinttype =. 2402.13718 , timestamp =
-
[2]
Helmet: How to evaluate long-context language models effectively and thoroughly, 2025
Howard Yen and Tianyu Gao and Minmin Hou and Ke Ding and Daniel Fleischer and Peter Izsak and Moshe Wasserblat and Danqi Chen , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.02694 , eprinttype =. 2410.02694 , timestamp =
-
[5]
Yushi Bai and Shangqing Tu and Jiajie Zhang and Hao Peng and Xiaozhi Wang and Xin Lv and Shulin Cao and Jiazheng Xu and Lei Hou and Yuxiao Dong and Jie Tang and Juanzi Li , editor =. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks , booktitle =. 2025 , url =
work page 2025
-
[6]
Rossi and Seunghyun Yoon and Hinrich Sch
Ali Modarressi and Hanieh Deilamsalehy and Franck Dernoncourt and Trung Bui and Ryan A. Rossi and Seunghyun Yoon and Hinrich Sch. NoLiMa: Long-Context Evaluation Beyond Literal Matching , booktitle =. 2025 , url =
work page 2025
-
[7]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =
Di Wu and Hongwei Wang and Wenhao Yu and Yuwei Zhang and Kai. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory , booktitle =. 2025 , url =
work page 2025
-
[14]
Yuanzhe Hu and Yu Wang and Julian J. McAuley , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2507.05257 , eprinttype =. 2507.05257 , timestamp =
-
[18]
Mengkang Hu and Tianxing Chen and Qiguang Chen and Yao Mu and Wenqi Shao and Ping Luo , editor =. HiAgent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks with Large Language Model , booktitle =. 2025 , url =
work page 2025
-
[25]
Yiting Shen and Kun Li and Wei Zhou and Songlin Hu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.19935 , eprinttype =. 2601.19935 , timestamp =
-
[27]
Zijian Zhou and Ao Qu and Zhaoxuan Wu and Sunghwan Kim and Alok Prakash and Daniela Rus and Jinhua Zhao and Bryan Kian Hsiang Low and Paul Pu Liang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.15841 , eprinttype =. 2506.15841 , timestamp =
-
[28]
arXiv preprint arXiv:2509.23040 , year=
Yaorui Shi and Yuxin Chen and Siyuan Wang and Sihang Li and Hengxing Cai and Qi Gu and Xiang Wang and An Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.23040 , eprinttype =. 2509.23040 , timestamp =
-
[29]
Vladimir Araujo and Alvaro Soto and Marie. A Memory Model for Question Answering from Streaming Data Supported by Rehearsal and Anticipation of Coreference Information , booktitle =. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-ACL.830 , timestamp =
-
[30]
Yue Zhou and Xiaobo Guo and Belhassen Bayar and Srinivasan H. Sengamedu , editor =. Amory: Building Coherent Narrative-Driven Agent Memory through Agentic Reasoning , booktitle =. 2026 , url =
work page 2026
-
[34]
Chenghao Xiao and Isaac Chung and Imene Kerboua and Jamie Stirling and Xin Zhang and M. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.10471 , eprinttype =. 2504.10471 , timestamp =
-
[35]
The Thirteenth International Conference on Learning Representations,
Ziyan Jiang and Rui Meng and Xinyi Yang and Semih Yavuz and Yingbo Zhou and Wenhu Chen , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[39]
Laradji and Manuel Del Verme and Tom Marty and David V
Alexandre Drouin and Maxime Gasse and Massimo Caccia and Issam H. Laradji and Manuel Del Verme and Tom Marty and David V. WorkArena: How Capable are Web Agents at Solving Common Knowledge Work Tasks? , booktitle =. 2024 , url =
work page 2024
-
[40]
L. WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks , booktitle =. 2024 , url =
work page 2024
-
[41]
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[42]
Agent Workflow Memory , booktitle =
Zora Zhiruo Wang and Jiayuan Mao and Daniel Fried and Graham Neubig , editor =. Agent Workflow Memory , booktitle =. 2025 , url =
work page 2025
-
[45]
CocoaBench: Evaluating Unified Digital Agents in the Wild , author=. 2026 , eprint=
work page 2026
-
[46]
The Tenth International Conference on Learning Representations,
Yuhuai Wu and Markus Norman Rabe and DeLesley Hutchins and Christian Szegedy , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
work page 2022
-
[47]
Yu Wang and Yifan Gao and Xiusi Chen and Haoming Jiang and Shiyang Li and Jingfeng Yang and Qingyu Yin and Zheng Li and Xian Li and Bing Yin and Jingbo Shang and Julian J. McAuley , editor =. Forty-first International Conference on Machine Learning,. 2024 , url =
work page 2024
-
[48]
Guanzhi Wang and Yuqi Xie and Yunfan Jiang and Ajay Mandlekar and Chaowei Xiao and Yuke Zhu and Linxi Fan and Anima Anandkumar , title =. Trans. Mach. Learn. Res. , volume =. 2024 , url =
work page 2024
-
[52]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
work page 2023
-
[53]
2025 , howpublished =
work page 2025
-
[54]
2026 , howpublished =
work page 2026
-
[55]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
- [56]
-
[57]
Anthropic . Claude Opus 4.6 System Card . https://www-cdn.anthropic.com/14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, 2026. Accessed: 2026-04-23
work page 2026
-
[58]
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual...
work page 2025
-
[59]
Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks
L \' e o Boisvert, Megh Thakkar, Maxime Gasse, Massimo Caccia, Thibault Le Sellier de Chezelles, Quentin Cappart, Nicolas Chapados, Alexandre Lacoste, and Alexandre Drouin. Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. T...
work page 2024
-
[60]
Test Intention Guided LLM-Based Unit Test Generation ,
Islem Bouzenia, Premkumar T. Devanbu, and Michael Pradel. Repairagent: An autonomous, llm-based agent for program repair. In 47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025 , pages 2188--2200. IEEE , 2025. doi:10.1109/ICSE55347.2025.00157. URL https://doi.org/10.1109/ICSE55347.2025.00157
-
[61]
Coding agents are effective long-context processors
Weili Cao, Xunjian Yin, Bhuwan Dhingra, and Shuyan Zhou. Coding agents are effective long-context processors. CoRR, abs/2603.20432, 2026. doi:10.48550/ARXIV.2603.20432. URL https://doi.org/10.48550/arXiv.2603.20432
-
[62]
Mem0: Building production-ready AI agents with scalable long-term memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready AI agents with scalable long-term memory. In In \^ e s Lynce, Nello Murano, Mauro Vallati, Serena Villata, Federico Chesani, Michela Milano, Andrea Omicini, and Mehdi Dastani, editors, ECAI 2025 - 28th European Conference on Artificial Intelligenc...
-
[63]
Cl-bench: A benchmark for context learning
Shihan Dou, Ming Zhang, Zhangyue Yin, Chenhao Huang, Yujiong Shen, Junzhe Wang, Jiayi Chen, Yuchen Ni, Junjie Ye, Cheng Zhang, Huaibing Xie, Jianglu Hu, Shaolei Wang, Weichao Wang, Yanling Xiao, Yiting Liu, Zenan Xu, Zhen Guo, Pluto Zhou, Tao Gui, Zuxuan Wu, Xipeng Qiu, Qi Zhang, Xuanjing Huang, Yu - Gang Jiang, Di Wang, and Shunyu Yao. Cl-bench: A benchm...
-
[64]
Laradji, Manuel Del Verme, Tom Marty, David V \' a zquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David V \' a zquez, Nicolas Chapados, and Alexandre Lacoste. Workarena: How capable are web agents at solving common knowledge work tasks? In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berken...
work page 2024
-
[65]
Yiming Du, Hongru Wang, Zhengyi Zhao, Bin Liang, Baojun Wang, Wanjun Zhong, Zezhong Wang, and Kam - Fai Wong. Perltqa: A personal long-term memory dataset for memory classification, retrieval, and synthesis in question answering. CoRR, abs/2402.16288, 2024. doi:10.48550/ARXIV.2402.16288. URL https://doi.org/10.48550/arXiv.2402.16288
-
[66]
Agentlongbench: A controllable long benchmark for long-contexts agents via environment rollouts
Shicheng Fang, Yuxin Wang, Xiaoran Liu, Jiahao Lu, Chuanyuan Tan, Xinchi Chen, Yining Zheng, Xuanjing Huang, and Xipeng Qiu. Agentlongbench: A controllable long benchmark for long-contexts agents via environment rollouts. CoRR, abs/2601.20730, 2026. doi:10.48550/ARXIV.2601.20730. URL https://doi.org/10.48550/arXiv.2601.20730
-
[67]
Google DeepMind . Gemini 3 Pro Model Card . https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf, 2025. Accessed: 2026-04-23
work page 2025
-
[68]
Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu - Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, Jiaxin Pei, Julian J. McAuley, Yejin Choi, and Alex Pentland. Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks. CoRR, abs/2602.16313, 2026. doi:10.48550/ARXIV.2602.16313. URL https://doi.org/10.48550/a...
-
[69]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng - Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. RULER: what's the real context size of your long-context language models? CoRR, abs/2404.06654, 2024. doi:10.48550/ARXIV.2404.06654. URL https://doi.org/10.48550/arXiv.2404.06654
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.06654 2024
-
[70]
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Ling...
work page 2025
-
[71]
Bowen Jiang, Zhuoqun Hao, Young - Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle H. Ungar, Camillo J. Taylor, and Dan Roth. Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale. CoRR, abs/2504.14225, 2025 a . doi:10.48550/ARXIV.2504.14225. URL https://doi.org/10.48550/arXiv.2504.14225
-
[72]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, Radha Poovendran, Gregory W. Wornell, Lyle H. Ungar, Dan Roth, Sihao Chen, and Camillo Jose Taylor. Personamem-v2: Towards personalized intelligence via learning implicit user personas and agentic memory. CoRR, abs/2512.06688, ...
-
[73]
Needle in a haystack: Pressure testing llms
Gregory Kamradt. Needle in a haystack: Pressure testing llms. https://github.com/gkamradt/LLMTest_NeedleInAHaystack, 2023. GitHub repository
work page 2023
-
[74]
One thousand and one pairs: A "novel" challenge for long-context language models
Marzena Karpinska, Katherine Thai, Kyle Lo, Tanya Goyal, and Mohit Iyyer. One thousand and one pairs: A "novel" challenge for long-context language models. In Yaser Al - Onaizan, Mohit Bansal, and Yun - Nung Chen, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 20...
-
[75]
Jiho Kim, Woosog Chay, Hyeonji Hwang, Daeun Kyung, Hyunseung Chung, Eunbyeol Cho, Yohan Jo, and Edward Choi. Dialsim: A real-time simulator for evaluating long-term dialogue understanding of conversational agents. CoRR, abs/2406.13144, 2024. doi:10.48550/ARXIV.2406.13144. URL https://doi.org/10.48550/arXiv.2406.13144
-
[76]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626, 2023
work page 2023
-
[77]
Emembench: Interactive benchmarking of episodic memory for vlm agents, 2026
Xinze Li, Ziyue Zhu, Siyuan Liu, Yubo Ma, Yuhang Zang, Yixin Cao, and Aixin Sun. Emembench: Interactive benchmarking of episodic memory for VLM agents. CoRR, abs/2601.16690, 2026. doi:10.48550/ARXIV.2601.16690. URL https://doi.org/10.48550/arXiv.2601.16690
-
[78]
Sleep-time compute: Beyond inference scaling at test-time
Kevin Lin, Charlie Snell, Yu Wang, Charles Packer, Sarah Wooders, Ion Stoica, and Joseph E. Gonzalez. Sleep-time compute: Beyond inference scaling at test-time. CoRR, abs/2504.13171, 2025. doi:10.48550/ARXIV.2504.13171. URL https://doi.org/10.48550/arXiv.2504.13171
-
[79]
FileGram: Grounding Agent Personalization in File-System Behavioral Traces
Shuai Liu, Shulin Tian, Kairui Hu, Yuhao Dong, Zhe Yang, Bo Li, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Filegram: Grounding agent personalization in file-system behavioral traces. arXiv preprint arXiv:2604.04901, 2026 a
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[80]
The pensieve paradigm: Stateful language models mastering their own context, 2026
Xiaoyuan Liu, Tian Liang, Dongyang Ma, Deyu Zhou, Haitao Mi, Pinjia He, and Yan Wang. The pensieve paradigm: Stateful language models mastering their own context. CoRR, abs/2602.12108, 2026 b . doi:10.48550/ARXIV.2602.12108. URL https://doi.org/10.48550/arXiv.2602.12108
-
[81]
Evaluating very long-term conversational memory of LLM agents
Adyasha Maharana, Dong - Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. In Lun - Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, T...
-
[82]
Rossi, Seunghyun Yoon, and Hinrich Sch \" u tze
Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan A. Rossi, Seunghyun Yoon, and Hinrich Sch \" u tze. Nolima: Long-context evaluation beyond literal matching. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste - Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Forty-second International Conference...
work page 2025
- [83]
-
[84]
Update to GPT-5 System Card: GPT-5.2
OpenAI . Update to GPT-5 System Card: GPT-5.2 . https://openai.com/index/gpt-5-system-card-update-gpt-5-2/, 2025. Accessed: 2026-04-23
work page 2025
-
[85]
OpenAI . GPT-5 System Card , 2026. URL https://arxiv.org/abs/2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[86]
OpenRouter . OpenRouter . https://openrouter.ai/, 2026. AI model routing and inference API. Accessed: 2026-04-24
work page 2026
-
[87]
Siru Ouyang, Jun Yan, I - Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen - Yu Lee, and Tomas Pfister. Reasoningbank: Scaling agent self-evolving with reasoning memory. CoRR, abs/2509.25140, 2025. doi:10.48550/ARXIV.2509.25140....
-
[88]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems. CoRR, abs/2310.08560, 2023. doi:10.48550/ARXIV.2310.08560. URL https://doi.org/10.48550/arXiv.2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[89]
Qwen3.5 : Towards native multimodal agents, February 2026
Qwen Team . Qwen3.5 : Towards native multimodal agents, February 2026. URL https://qwen.ai/blog?id=qwen3.5
work page 2026
-
[90]
Chemagent: Self-updating library in large language models improves chemical reasoning
Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchunshu Zhou, Pan Lu, Zhuosheng Zhang, Yilun Zhao, Arman Cohan, and Mark Gerstein. Chemagent: Self-updating library in large language models improves chemical reasoning. CoRR, abs/2501.06590, 2025. doi:10.48550/ARXIV.2501.06590. URL https://doi.org/10.48550/arXiv.2501.06590
-
[91]
Mohammad Tavakoli, Alireza Salemi, Carrie Ye, Mohamed Abdalla, Hamed Zamani, and J. Ross Mitchell. Beyond a million tokens: Benchmarking and enhancing long-term memory in llms. CoRR, abs/2510.27246, 2025. doi:10.48550/ARXIV.2510.27246. URL https://doi.org/10.48550/arXiv.2510.27246
-
[92]
CocoaBench: Evaluating Unified Digital Agents in the Wild
CocoaBench Team, Shibo Hao, Zhining Zhang, Zhiqi Liang, Tianyang Liu, Yuheng Zha, Qiyue Gao, Jixuan Chen, Zilong Wang, Zhoujun Cheng, Haoxiang Zhang, Junli Wang, Hexi Jin, Boyuan Zheng, Kun Zhou, Yu Wang, Feng Yao, Licheng Liu, Yijiang Li, Zhifei Li, Zhengtao Han, Pracha Promthaw, Tommaso Cerruti, Xiaohan Fu, Ziqiao Ma, Jingbo Shang, Lianhui Qin, Julian M...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[93]
Voyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. Trans. Mach. Learn. Res., 2024, 2024 a . URL https://openreview.net/forum?id=ehfRiF0R3a
work page 2024
-
[94]
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, and Julian J. McAuley. MEMORYLLM: towards self-updatable large language models. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Forty-firs...
work page 2024
-
[95]
URL https://openreview.net/forum?id=ehfRiF0R3a
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian J. McAuley, and Xiaojian Wu. Mem- \( \) : Learning memory construction via reinforcement learning. CoRR, abs/2509.25911, 2025 a . doi:10.48550/ARXIV.2509.25911. URL https://doi.org/10.48550/arXiv.2509.25911
-
[96]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste - Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 , Proceedings of Machi...
work page 2025
-
[97]
Longmemeval: Benchmarking chat assistants on long-term interactive memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai - Wei Chang, and Dong Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025 a . URL https://openreview.net/forum?id=pZiyCaVuti
work page 2025
-
[98]
Auto-scaling continuous memory for GUI agent
Wenyi Wu, Kun Zhou, Ruoxin Yuan, Vivian Yu, Stephen Wang, Zhiting Hu, and Biwei Huang. Auto-scaling continuous memory for GUI agent. CoRR, abs/2510.09038, 2025 b . doi:10.48550/ARXIV.2510.09038. URL https://doi.org/10.48550/arXiv.2510.09038
-
[99]
Yuhuai Wu, Markus Norman Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing transformers. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=TrjbxzRcnf-
work page 2022
-
[100]
xAI . Grok 4.1 Model Card . https://data.x.ai/2025-11-17-grok-4-1-model-card.pdf, 2025. Accessed: 2026-04-23
work page 2025
-
[101]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: agentic memory for LLM agents. CoRR, abs/2502.12110, 2025. doi:10.48550/ARXIV.2502.12110. URL https://doi.org/10.48550/arXiv.2502.12110
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110 2025
-
[102]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Sch \" u tze, Volker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning. CoRR, abs/2508.19828, 2025. doi:10.48550/ARXIV.2508.19828. URL https://doi.org/10.48550/arXiv.2508.19828
work page internal anchor Pith review doi:10.48550/arxiv.2508.19828 2025
-
[103]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023. URL https://openreview.net/forum?id=WE\_vluYUL-X
work page 2023
-
[104]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents. CoRR, abs/2602.02474, 2026. doi:10.48550/ARXIV.2602.02474. URL https://doi.org/10.48550/arXiv.2602.02474
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02474 2026
-
[105]
Expel: LLM agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong - Jin Liu, and Gao Huang. Expel: LLM agents are experiential learners. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors, Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2...
-
[106]
LMEB: Long-horizon Memory Embedding Benchmark
Xinping Zhao, Xinshuo Hu, Jiaxin Xu, Danyu Tang, Xin Zhang, Mengjia Zhou, Yan Zhong, Yao Zhou, Zifei Shan, Meishan Zhang, Baotian Hu, and Min Zhang. LMEB: long-horizon memory embedding benchmark. CoRR, abs/2603.12572, 2026 a . doi:10.48550/ARXIV.2603.12572. URL https://doi.org/10.48550/arXiv.2603.12572
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.12572 2026
-
[107]
Yujie Zhao, Boqin Yuan, Junbo Huang, Haocheng Yuan, Zhongming Yu, Haozhou Xu, Lanxiang Hu, Abhilash Shankarampeta, Zimeng Huang, Wentao Ni, Yuandong Tian, and Jishen Zhao. Ama-bench: Evaluating long-horizon memory for agentic applications. CoRR, abs/2602.22769, 2026 b . doi:10.48550/ARXIV.2602.22769. URL https://doi.org/10.48550/arXiv.2602.22769
-
[108]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net,...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.