Recognition: 2 theorem links
· Lean TheoremCausalCine: Real-Time Autoregressive Generation for Multi-Shot Video Narratives
Pith reviewed 2026-05-13 05:28 UTC · model grok-4.3
The pith
CausalCine turns multi-shot video generation into a real-time online process by training on native sequences and routing memory by content relevance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
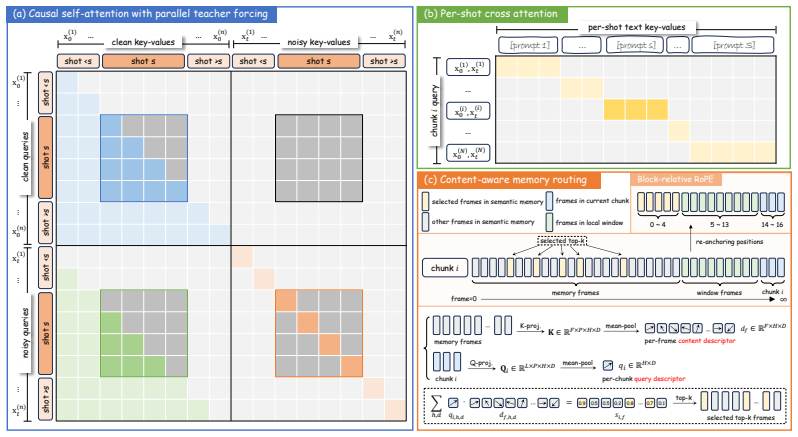
CausalCine generates causally across shot changes, accepts dynamic prompts on the fly, and reuses context without regenerating previous shots. It first trains a causal base model on native multi-shot sequences to learn complex shot transitions, then applies Content-Aware Memory Routing to dynamically retrieve historical KV entries according to attention-based relevance scores rather than temporal proximity. The base model is distilled into a few-step generator, enabling real-time interactive generation that significantly outperforms autoregressive baselines and approaches the capability of bidirectional models.
What carries the argument
Content-Aware Memory Routing (CAMR), which dynamically retrieves historical key-value entries according to attention-based relevance scores instead of temporal proximity to preserve cross-shot coherence under bounded active memory.
If this is right
- Long video rollouts can progress through discrete shot boundaries and viewpoint changes without treating the entire sequence as one extended scene.
- Users can insert or change prompts during generation while the model reuses prior context efficiently.
- Real-time streaming becomes feasible after distillation to few-step inference.
- Performance can reach levels close to bidirectional models without sacrificing the causality required for interactivity.
Where Pith is reading between the lines
- The same routing idea could be tested on other long-horizon sequential tasks where context must be selected by relevance rather than recency.
- Extending the training data to include more varied cinematic styles might reveal how broadly the learned transitions generalize.
- Live user interfaces that let directors steer the story mid-generation become a natural next step once real-time causal output is reliable.
Load-bearing premise
That training a causal model on native multi-shot video sequences will let it learn complex shot transitions, and that selecting memory entries by content relevance will maintain coherence even when only a limited amount of past information stays active.
What would settle it
Generate a multi-shot video sequence with clear viewpoint shifts and event changes; if semantic drift or motion stagnation appears at rates comparable to standard autoregressive rollouts, or if coherence collapses once active memory is restricted, the central claim would be falsified.
Figures





read the original abstract
Autoregressive video generation aims at real-time, open-ended synthesis. Yet, cinematic storytelling is not merely the endless extension of a single scene; it requires progressing through evolving events, viewpoint shifts, and discrete shot boundaries. Existing autoregressive models often struggle in this setting. Trained primarily for short-horizon continuation, they treat long sequences as extended single shots, inevitably suffering from motion stagnation and semantic drift during long rollouts. To bridge this gap, we introduce CausalCine, an interactive autoregressive framework that transforms multi-shot video generation into an online directing process. CausalCine generates causally across shot changes, accepts dynamic prompts on the fly, and reuses context without regenerating previous shots. To achieve this, we first train a causal base model on native multi-shot sequences to learn complex shot transitions prior to acceleration. We then propose Content-Aware Memory Routing (CAMR), which dynamically retrieves historical KV entries according to attention-based relevance scores rather than temporal proximity, preserving cross-shot coherence under bounded active memory. Finally, we distill the causal base model into a few-step generator for real-time interactive generation. Extensive experiments demonstrate that CausalCine significantly outperforms autoregressive baselines and approaches the capability of bidirectional models while unlocking the streaming interactivity of causal generation. Demo available at https://yihao-meng.github.io/CausalCine/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CausalCine, an interactive autoregressive framework for multi-shot video narrative generation. It first trains a causal base model on native multi-shot sequences to learn complex shot transitions, then applies Content-Aware Memory Routing (CAMR) to dynamically retrieve historical KV entries via attention-based relevance scores (rather than temporal order) to preserve cross-shot coherence under bounded memory, and finally distills the model into a few-step generator for real-time streaming interactivity. The central claim is that this enables causal models to significantly outperform standard autoregressive baselines, approach bidirectional model capabilities, and support on-the-fly prompting without regenerating prior shots.
Significance. If the empirical claims hold, the work would meaningfully advance autoregressive video generation by addressing motion stagnation and semantic drift in long-horizon multi-shot settings, while retaining the streaming and interactive advantages of causal architectures. The distillation step for real-time performance and the explicit focus on native multi-shot training data are practical strengths that could influence future interactive media systems.
major comments (3)
- [Abstract] Abstract: the assertion that 'extensive experiments demonstrate that CausalCine significantly outperforms autoregressive baselines' is unsupported by any reported metrics, baseline names, dataset details, or table/figure references, rendering the central outperformance claim impossible to evaluate.
- [Method (CAMR)] Method section describing CAMR: the mechanism computes relevance scores from the current query against historical keys to decide KV retrieval across shot boundaries, but no analysis, ablation, or bound is given on score behavior under semantic shifts (e.g., viewpoint changes or event progression), which directly undermines the claim that bounded-memory coherence is preserved.
- [Method (base model training)] Training procedure: the claim that training a causal base model on native multi-shot sequences teaches complex shot transitions lacks any supporting ablation (e.g., comparison to concatenated single-shot training) or diagnostic metrics on boundary detection, making this assumption load-bearing yet unverified for the multi-shot narrative capability.
minor comments (2)
- [Abstract] The demo link is provided but no statement on code or checkpoint release appears, limiting reproducibility assessment.
- [Method] Notation for 'Content-Aware Memory Routing' and KV cache management should be formalized with an equation or pseudocode to clarify the retrieval logic.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. Where the comments identify gaps in supporting evidence or analysis, we agree that revisions are warranted and will incorporate the necessary additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive experiments demonstrate that CausalCine significantly outperforms autoregressive baselines' is unsupported by any reported metrics, baseline names, dataset details, or table/figure references, rendering the central outperformance claim impossible to evaluate.
Authors: We agree that the abstract would be strengthened by including direct references to support the outperformance claim. The full manuscript reports quantitative results, baseline comparisons, and dataset details in the Experiments section. In the revised version, we will update the abstract to reference specific tables, figures, and key metrics that substantiate the claim. revision: yes
-
Referee: [Method (CAMR)] Method section describing CAMR: the mechanism computes relevance scores from the current query against historical keys to decide KV retrieval across shot boundaries, but no analysis, ablation, or bound is given on score behavior under semantic shifts (e.g., viewpoint changes or event progression), which directly undermines the claim that bounded-memory coherence is preserved.
Authors: We acknowledge that the current description of CAMR lacks explicit analysis of relevance score behavior under semantic shifts. While qualitative results are presented, we agree this is a gap. We will add an ablation study and analysis in the revised manuscript examining score distributions and retrieval behavior during viewpoint changes and narrative progressions, including empirical observations on stability. revision: yes
-
Referee: [Method (base model training)] Training procedure: the claim that training a causal base model on native multi-shot sequences teaches complex shot transitions lacks any supporting ablation (e.g., comparison to concatenated single-shot training) or diagnostic metrics on boundary detection, making this assumption load-bearing yet unverified for the multi-shot narrative capability.
Authors: We recognize that the advantage of native multi-shot training requires direct empirical verification through ablation. The manuscript currently relies on the design rationale without such a comparison. We will include an ablation comparing native multi-shot sequences to concatenated single-shot training, along with diagnostic metrics on boundary detection and transition quality, in the revised manuscript. revision: yes
Circularity Check
No circularity; architectural innovations evaluated independently
full rationale
The paper describes training a causal base model on native multi-shot video sequences, introducing Content-Aware Memory Routing (CAMR) for attention-based KV retrieval, and distilling to a few-step generator. These steps are presented as new components with empirical validation against baselines. No equations, derivations, or claims reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations; performance metrics are external to the method definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard transformer attention mechanisms can capture temporal and cross-shot dependencies when trained on appropriate data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe then propose Content-Aware Memory Routing (CAMR), which dynamically retrieves historical KV entries according to attention-based relevance scores rather than temporal proximity
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanabsolute_floor_iff_bare_distinguishability uncleartrain a causal base model on native multi-shot sequences to learn complex shot transitions prior to acceleration
Reference graph
Works this paper leans on
-
[1]
Hritik Bansal, Yonatan Bitton, Michal Yarom, Idan Szpektor, Aditya Grover, and Kai-Wei Chang. Talc: Time-aligned captions for multi-scene text-to-video generation.arXiv preprint arXiv:2405.04682, 2024
-
[2]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[3]
Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058, 2025
Shengqu Cai, Ceyuan Yang, Lvmin Zhang, Yuwei Guo, Junfei Xiao, Ziyan Yang, Yinghao Xu, Zhenheng Yang, Alan Yuille, Leonidas Guibas, et al. Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058, 2025
-
[4]
Mode seeking meets mean seeking for fast long video generation
Shengqu Cai, Weili Nie, Chao Liu, Julius Berner, Lvmin Zhang, Nanye Ma, Hansheng Chen, Maneesh Agrawala, Leonidas Guibas, Gordon Wetzstein, and Arash Vahdat. Mode seeking meets mean seeking for fast long video generation. InarXiv, 2026
work page 2026
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
-
[8]
Lol: Longer than longer, scaling video generation to hour.arXiv preprint arXiv:2601.16914, 2026
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Lol: Longer than longer, scaling video generation to hour.arXiv preprint arXiv:2601.16914, 2026
-
[9]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
-
[10]
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long-context autoregressive video modeling with next-frame prediction.arXiv preprint arXiv:2503.19325, 2025
-
[11]
Yuwei Guo, Ceyuan Yang, Hao He, Yang Zhao, Meng Wei, Zhenheng Yang, Weilin Huang, and Dahua Lin. End-to-end training for autoregressive video diffusion via self-resampling.arXiv preprint arXiv:2512.15702, 2025
-
[12]
Long context tuning for video generation
Yuwei Guo, Ceyuan Yang, Ziyan Yang, Zhibei Ma, Zhijie Lin, Zhenheng Yang, Dahua Lin, and Lu Jiang. Long context tuning for video generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17281–17291, 2025
work page 2025
-
[13]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page Pith review arXiv 2026
-
[14]
Streamingt2v: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2568–2577, 2025
work page 2025
-
[15]
Yining Hong, Beide Liu, Maxine Wu, Yuanhao Zhai, Kai-Wei Chang, Linjie Li, Kevin Lin, Chung-Ching Lin, Jianfeng Wang, Zhengyuan Yang, et al. Slowfast-vgen: Slow-fast learning for action-driven long video generation.arXiv preprint arXiv:2410.23277, 2024
-
[16]
Panwen Hu, Jin Jiang, Jianqi Chen, Mingfei Han, Shengcai Liao, Xiaojun Chang, and Xiaodan Liang. Storyagent: Customized storytelling video generation via multi-agent collaboration.arXiv preprint arXiv:2411.04925, 2024
-
[17]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length
Yubo Huang, Hailong Guo, Fangtai Wu, Shifeng Zhang, Shijie Huang, Qijun Gan, Lin Liu, Sirui Zhao, Enhong Chen, Jiaming Liu, and Steven Hoi. Live avatar: Streaming real-time audio-driven avatar generation with infinite length, 2025. URLhttps://arxiv.org/abs/2512.04677
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
-
[20]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Memflow: Flowing adaptive memory for consistent and efficient long video narratives,
Sihui Ji, Xi Chen, Shuai Yang, Xin Tao, Pengfei Wan, and Hengshuang Zhao. Memflow: Flowing adaptive memory for consistent and efficient long video narratives.arXiv preprint arXiv:2512.14699, 2025
-
[22]
Weinan Jia, Yuning Lu, Mengqi Huang, Hualiang Wang, Binyuan Huang, Nan Chen, Mu Liu, Jidong Jiang, and Zhendong Mao. Moga: Mixture-of-groups attention for end-to-end long video generation.arXiv preprint arXiv:2510.18692, 2025
-
[23]
Taekyung Ki, Sangwon Jang, Jaehyeong Jo, Jaehong Yoon, and Sung Ju Hwang. Avatar forcing: Real-time interactive head avatar generation for natural conversation.arXiv preprint arXiv:2601.00664, 2026
-
[24]
Vmem: Consistent interactive video scene generation with surfel-indexed view memory
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25690–25699, 2025
work page 2025
-
[25]
arXiv preprint arXiv:2501.08316 (2025) 2, 3, 4
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Yang, Xuefeng Xiao, and Lu Jiang. Diffusion adversarial post-training for one-step video generation.arXiv preprint arXiv:2501.08316, 2025
-
[26]
arXiv preprint arXiv:2509.25161 (2025) 4
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
-
[27]
Wei Liu, Ziyu Chen, Zizhang Li, Yue Wang, Hong-Xing Yu, and Jiajun Wu. Realwonder: Real-time physical action-conditioned video generation.arXiv preprint arXiv:2603.05449, 2026
-
[28]
Videostudio: Generating consistent-content and multi-scene videos
Fuchen Long, Zhaofan Qiu, Ting Yao, and Tao Mei. Videostudio: Generating consistent-content and multi-scene videos. InEuropean Conference on Computer Vision, pages 468–485. Springer, 2024
work page 2024
-
[29]
Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189, 2025
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, et al. Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189, 2025
-
[30]
Yawen Luo, Xiaoyu Shi, Junhao Zhuang, Yutian Chen, Quande Liu, Xintao Wang, Pengfei Wan, and Tianfan Xue. Shotstream: Streaming multi-shot video generation for interactive storytelling.arXiv preprint arXiv:2603.25746, 2026
-
[31]
Yihao Meng, Hao Ouyang, Yue Yu, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Hanlin Wang, Yixuan Li, Cheng Chen, Yanhong Zeng, et al. Holocine: Holistic generation of cinematic multi-shot long video narratives.arXiv preprint arXiv:2510.20822, 2025
-
[32]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[34]
Maskˆ 2dit: Dual mask-based diffusion transformer for multi-scene long video generation
Tianhao Qi, Jianlong Yuan, Wanquan Feng, Shancheng Fang, Jiawei Liu, SiYu Zhou, Qian He, Hongtao Xie, and Yongdong Zhang. Maskˆ 2dit: Dual mask-based diffusion transformer for multi-scene long video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18837–18846, 2025
work page 2025
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 11
work page 2021
-
[36]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
work page 2022
-
[37]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity. arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
arXiv preprint arXiv:2511.01266 (2025)
Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, Jaesik Park, Eli Shechtman, and Xun Huang. Motionstream: Real-time video generation with interactive motion controls.arXiv preprint arXiv:2511.01266, 2025
-
[39]
Transnet v2: An effective deep network architecture for fast shot transition detection
Tomás Soucek and Jakub Lokoc. Transnet v2: An effective deep network architecture for fast shot transition detection. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11218–11221, 2024
work page 2024
-
[40]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Echoshot: Multi-shot portrait video generation
Jiahao Wang, Hualian Sheng, Sijia Cai, Weizhan Zhang, Caixia Yan, Yachuang Feng, Bing Deng, and Jieping Ye. Echoshot: Multi-shot portrait video generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[43]
Qinghe Wang, Xiaoyu Shi, Baolu Li, Weikang Bian, Quande Liu, Huchuan Lu, Xintao Wang, Pengfei Wan, Kun Gai, and Xu Jia. Multishotmaster: A controllable multi-shot video generation framework.arXiv preprint arXiv:2512.03041, 2025
-
[44]
Wen Wang, Canyu Zhao, Hao Chen, Zhekai Chen, Kecheng Zheng, and Chunhua Shen. Autostory: Generating diverse storytelling images with minimal human efforts.International Journal of Computer Vision, 133(6):3083–3104, 2025
work page 2025
-
[45]
Internvideo: General video foundation models via generative and discriminative learning
Yi Wang, Kunchang Li, Yizhuo Li, Yinan He, Bingkun Huang, Zhiyu Zhao, Hongjie Zhang, Jilan Xu, Yi Liu, Zun Wang, Sen Xing, Guo Chen, Junting Pan, Jiashuo Yu, Yali Wang, Limin Wang, and Yu Qiao. Internvideo: General video foundation models via generative and discriminative learning.arXiv preprint arXiv:2212.03191, 2022
-
[46]
Internvid: A large-scale video-text dataset for multimodal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinyuan Chen, Yaohui Wang, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. Internvid: A large-scale video-text dataset for multimodal understanding and generation.arXiv preprint arXiv:2307.06942, 2023
-
[47]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Captain cinema: Towards short movie generation
Junfei Xiao, Ceyuan Yang, Lvmin Zhang, Shengqu Cai, Yang Zhao, Yuwei Guo, Gordon Wetzstein, Maneesh Agrawala, Alan Yuille, and Lu Jiang. Captain cinema: Towards short movie generation. InThe Fourteenth International Conference on Learning Representations, 2025
work page 2025
-
[49]
Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
-
[50]
arXiv preprint arXiv:2408.11788 (2024)
Zhifei Xie, Daniel Tang, Dingwei Tan, Jacques Klein, Tegawend F Bissyand, and Saad Ezzini. Dream- factory: Pioneering multi-scene long video generation with a multi-agent framework.arXiv preprint arXiv:2408.11788, 2024
-
[51]
arXiv preprint arXiv:2509.22622 (2025) 2, 3, 4, 10, 11, 12, 13, 21, 22
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, et al. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
-
[52]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-rope: Action-controllable infinite video generation emerges from autoregressive self-rollout.arXiv preprint arXiv:2511.20649, 2025. 12
-
[53]
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis.Advances in neural information processing systems, 37:47455–47487, 2024
work page 2024
-
[54]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
work page 2024
-
[55]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
work page 2025
-
[56]
Context as memory: Scene-consistent interactive long video generation with memory retrieval
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval. In Proceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–11, 2025
work page 2025
-
[57]
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models.arXiv preprint arXiv:2504.12626, 2025
-
[58]
Canyu Zhao, Mingyu Liu, Wen Wang, Weihua Chen, Fan Wang, Hao Chen, Bo Zhang, and Chun- hua Shen. Moviedreamer: Hierarchical generation for coherent long visual sequence.arXiv preprint arXiv:2407.16655, 2024
-
[59]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
Mingzhe Zheng, Yongqi Xu, Haojian Huang, Xuran Ma, Yexin Liu, Wenjie Shu, Yatian Pang, Feilong Tang, Qifeng Chen, Harry Yang, et al. Videogen-of-thought: Step-by-step generating multi-shot video with minimal manual intervention.arXiv preprint arXiv:2412.02259, 2024
-
[61]
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self-attention for long-range image and video generation.Advances in Neural Information Processing Systems, 37:110315–110340, 2024
work page 2024
-
[62]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregres- sive diffusion distillation done right for high-quality real-time interactive video generation.arXiv preprint arXiv:2602.02214, 2026. 13 A More Results To provide a more complete view of the generated videos beyond the still frames shown in the main paper, w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.