Recognition: 2 theorem links
· Lean TheoremSP-GCRL: Influence Maximization on Incomplete Social Graphs
Pith reviewed 2026-05-14 21:06 UTC · model grok-4.3
The pith
SP-GCRL learns end-to-end seed selection policies for influence maximization on incomplete social graphs using contrastive representations and a nonlinear diffusion model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SP-GCRL achieves higher influence spread on incomplete graphs by modeling nonlinear propagation effects, learning robust node embeddings via contrastive learning on dual views, replacing expensive metrics with a GAT regression surrogate, and optimizing seed selection end-to-end with DDQN under partial observability.
What carries the argument
The social-propagation-aware nonlinear diffusion function that models reinforcement, diminishing returns, and probability drift under repeated exposure.
If this is right
- The framework scales to large networks while improving spread across varying seed budgets and topologies.
- Contrastive representations reduce sensitivity to missing edges and weak ties compared with standard graph methods.
- Replacing strategy metrics with a GAT surrogate cuts computation time without sacrificing policy quality.
- End-to-end RL training enables direct optimization of seed sets under partial graph observability.
Where Pith is reading between the lines
- The same contrastive-plus-RL structure could be tested on other partial-observation network tasks such as link prediction or rumor containment.
- The nonlinear diffusion model might be adapted to capture opinion polarization or fatigue effects in online campaigns.
- Because the method avoids expensive simulations during training, it could support real-time seed selection on live platforms with streaming graph updates.
Load-bearing premise
The nonlinear diffusion function correctly models how influence reinforces or diminishes with repeated exposures on real incomplete graphs.
What would settle it
A controlled experiment on a synthetic network where repeated exposures produce linear rather than nonlinear diffusion effects, in which SP-GCRL shows no consistent advantage over baselines.
Figures




read the original abstract
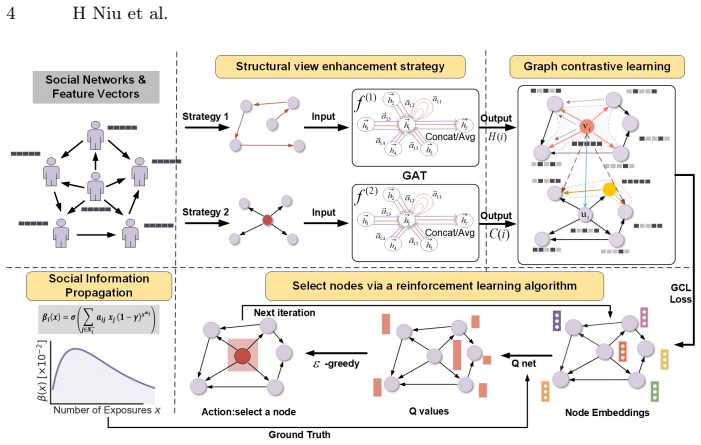
Influence maximization (IM) in real platforms is challenged by incomplete, noisy social graphs and non-stationary diffusion dynamics. We propose SP-GCRL, a social-propagation-aware graph contrastive reinforcement learning framework that learns end-to-end seed selection under partial observability.We first introduce a social-propagation-aware nonlinear diffusion function to model reinforcement/diminishing effects and probability drift under repeated exposure; we then construct dual structural views and perform contrastive learning to obtain node representations robust to missing edges and weak ties, while replacing expensive strategy metrics with a GAT-based regression surrogate to improve efficiency and scalability; finally, we use DDQN to learn an end-to-end seed selection policy on top of these representations. Experiments on multiple real-world networks show that SP-GCRL achieves significant gains over heuristic and learning-based baselines across budgets and topologies, while maintaining strong large-scale scalability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SP-GCRL, a social-propagation-aware graph contrastive reinforcement learning framework for influence maximization under incomplete graphs and non-stationary diffusion. It introduces a nonlinear diffusion function to capture reinforcement, diminishing returns, and probability drift; constructs dual structural views for contrastive learning to obtain robust node embeddings; replaces expensive metrics with a GAT regression surrogate; and trains an end-to-end DDQN policy for seed selection. Experiments on real-world networks report significant gains over heuristic and learning-based baselines across budgets while preserving scalability.
Significance. If the central performance claims hold under independent validation, the work would advance practical IM methods by integrating contrastive robustness to missing edges with RL-based policy learning and a scalable surrogate, addressing a key gap between theoretical IM and noisy real platforms. The end-to-end trainable pipeline and emphasis on large-scale applicability are strengths.
major comments (2)
- [§4 and §5] §4 (nonlinear diffusion function) and §5 (experimental setup): the influence-spread metric used to report final results appears to be the same social-propagation-aware nonlinear diffusion function employed both for policy training and for the GAT surrogate. This creates a risk that reported gains are artifacts of internal consistency with the assumed dynamics rather than genuine robustness to missing edges or real diffusion processes. Independent hold-out evaluation against standard IC/LT models or observed cascade data is required to substantiate the claims.
- [§5] §5 (experiments): no ablation results, hyperparameter tables, or sensitivity analysis on the nonlinear diffusion parameters are provided, making it impossible to determine whether the reported gains depend on careful tuning of the free parameters or generalize across reasonable settings.
minor comments (2)
- [§3] Notation for the dual structural views and contrastive loss could be clarified with an explicit equation reference in §3.
- [Abstract and §1] The abstract and introduction should explicitly state the number of networks, their sizes, and the range of budgets tested to allow immediate assessment of the scalability claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments on our manuscript. The feedback highlights important aspects of evaluation and experimental rigor that we will address in the revision. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [§4 and §5] §4 (nonlinear diffusion function) and §5 (experimental setup): the influence-spread metric used to report final results appears to be the same social-propagation-aware nonlinear diffusion function employed both for policy training and for the GAT surrogate. This creates a risk that reported gains are artifacts of internal consistency with the assumed dynamics rather than genuine robustness to missing edges or real diffusion processes. Independent hold-out evaluation against standard IC/LT models or observed cascade data is required to substantiate the claims.
Authors: We appreciate the referee's concern regarding potential circularity in evaluation. The nonlinear diffusion function is intentionally central to SP-GCRL because it captures reinforcement, diminishing returns, and probability drift under partial observability—dynamics that standard IC/LT models do not explicitly model. Nevertheless, we agree that independent validation strengthens the claims. In the revised manuscript, we will add hold-out experiments that evaluate the learned policies using the standard Independent Cascade (IC) model with fixed probabilities, reporting influence spread under this alternative diffusion process. We will also include comparisons against observed cascade data where available in the datasets. These additions will demonstrate that performance gains are not solely artifacts of the training dynamics. revision: yes
-
Referee: [§5] §5 (experiments): no ablation results, hyperparameter tables, or sensitivity analysis on the nonlinear diffusion parameters are provided, making it impossible to determine whether the reported gains depend on careful tuning of the free parameters or generalize across reasonable settings.
Authors: We agree that the absence of ablations and sensitivity analysis limits interpretability. In the revised version, we will include a dedicated ablation study section that isolates the contributions of the dual-view contrastive learning, the GAT surrogate, and the nonlinear diffusion components. We will also add a hyperparameter table listing all key values (including those for the nonlinear function) and sensitivity plots showing performance variation across reasonable ranges of the reinforcement and diminishing-return coefficients. These results will confirm that gains are stable and not due to narrow tuning. revision: yes
Circularity Check
No load-bearing circularity; custom diffusion used consistently but claims rest on empirical comparisons rather than definitional reduction
full rationale
The derivation introduces a social-propagation-aware nonlinear diffusion function, dual-view contrastive representations, GAT surrogate, and DDQN policy as distinct components. No equations or steps reduce the reported influence spread or performance gains to quantities defined by the same fitted parameters by construction. Experiments compare against external baselines on real networks, and the framework builds on standard contrastive/RL primitives without self-citation chains that force the central result. Minor risk of internal consistency with the assumed diffusion model exists but does not meet the threshold for circularity under the rules requiring explicit quoteable reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- nonlinear diffusion parameters
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
β_i(x) = σ(∑_{j∈N_i^-} a_ij x_j (1-γ) x^ω_i) with power-law f_i(x)=x^ω_i and γ from common-neighbor overlap (Eqs. 1-4)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Path-Entropy-Steiner backbone + Gramian controllability views with GAT surrogate and contrastive loss J (Eqs. 5-18)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Science advances10(15), eadh4439 (2024)
Aiyappa,R.,Flammini,A.,Ahn,Y.Y.:Emergenceofsimpleandcomplexcontagion dynamics from weighted belief networks. Science advances10(15), eadh4439 (2024)
2024
-
[2]
In: 2018 IEEE/WIC/ACM Interna- tional Conference on Web Intelligence (WI)
Ali, K., Wang, C.Y., Chen, Y.S.: Boosting reinforcement learning in competitive influence maximization with transfer learning. In: 2018 IEEE/WIC/ACM Interna- tional Conference on Web Intelligence (WI). pp. 395–400. IEEE (2018) SP-GCRL: Influence Maximization on Incomplete Social Graphs 15
2018
-
[3]
Proceedings of the National Academy of Sciences115(37), 9216–9221 (2018)
Bail, C.A., Argyle, L.P., Brown, T.W., Bumpus, J.P., Chen, H., Hunzaker, M.F., Lee,J.,Mann,M.,Merhout,F.,Volfovsky,A.:Exposuretoopposingviewsonsocial media can increase political polarization. Proceedings of the National Academy of Sciences115(37), 9216–9221 (2018)
2018
-
[4]
In: Uncertainty in Artificial In- telligence
Chen, H., Qiu, W., Ou, H.C., An, B., Tambe, M.: Contingency-aware influence maximization: A reinforcement learning approach. In: Uncertainty in Artificial In- telligence. pp. 1535–1545. PMLR (2021)
2021
-
[5]
IEEE Transactions on Compu- tational Social Systems11(2), 2210–2221 (2023)
Chen, T., Yan, S., Guo, J., Wu, W.: Touplegdd: A fine-designed solution of influ- ence maximization by deep reinforcement learning. IEEE Transactions on Compu- tational Social Systems11(2), 2210–2221 (2023)
2023
-
[6]
In: 2010 IEEE international conference on data mining
Chen, W., Yuan, Y., Zhang, L.: Scalable influence maximization in social networks under the linear threshold model. In: 2010 IEEE international conference on data mining. pp. 88–97. IEEE (2010)
2010
-
[7]
In: Proceedings of the 33rd ACM International Conference on Information and Knowledge Management
Chen, X., Lei, P.I., Sheng, Y., Liu, Y., Gong, Z.: Social influence learning for rec- ommendation systems. In: Proceedings of the 33rd ACM International Conference on Information and Knowledge Management. pp. 312–322 (2024)
2024
-
[8]
In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence
Du, W., Zhang, S., Di Wu, J.X., Zhao, Z., Fang, J., Wang, Y.: Mmgnn: A molecu- lar merged graph neural network for explainable solvation free energy prediction. In: Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence. pp. 5808–5816 (2024)
2024
-
[9]
In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Feng, Y., Tan, V.Y., Cautis, B.: Influence maximization via graph neural bandits. In: Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. pp. 771–781 (2024)
2024
-
[10]
In: International conference on machine learning
Hassani, K., Khasahmadi, A.H.: Contrastive multi-view representation learning on graphs. In: International conference on machine learning. pp. 4116–4126. PMLR (2020)
2020
-
[11]
Networks22(1), 55–89 (1992)
Hwang, F.K., Richards, D.S.: Steiner tree problems. Networks22(1), 55–89 (1992)
1992
-
[12]
In: Proceedings of the ninth ACM SIGKDD international confer- ence on Knowledge discovery and data mining
Kempe, D., Kleinberg, J., Tardos, É.: Maximizing the spread of influence through a social network. In: Proceedings of the ninth ACM SIGKDD international confer- ence on Knowledge discovery and data mining. pp. 137–146 (2003)
2003
-
[13]
Advances in neural information processing sys- tems30(2017)
Khalil, E., Dai, H., Zhang, Y., Dilkina, B., Song, L.: Learning combinatorial opti- mization algorithms over graphs. Advances in neural information processing sys- tems30(2017)
2017
-
[14]
European Journal of Operational Research300(3), 1136–1148 (2022)
Klages-Mundt, A., Minca, A.: Optimal intervention in economic networks using in- fluence maximization methods. European Journal of Operational Research300(3), 1136–1148 (2022)
2022
-
[15]
Information Sciences 607, 1617–1636 (2022)
Kumar, S., Mallik, A., Khetarpal, A., Panda, B.S.: Influence maximization in social networks using graph embedding and graph neural network. Information Sciences 607, 1617–1636 (2022)
2022
-
[16]
In: Proceedings of the 22nd international conference on world wide web
Kunegis, J.: Konect: the koblenz network collection. In: Proceedings of the 22nd international conference on world wide web. pp. 1343–1350 (2013)
2013
-
[17]
In: Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining
Leskovec, J., Krause, A., Guestrin, C., Faloutsos, C., VanBriesen, J., Glance, N.: Cost-effective outbreak detection in networks. In: Proceedings of the 13th ACM SIGKDD international conference on Knowledge discovery and data mining. pp. 420–429 (2007)
2007
-
[18]
IEEE Transactions on Compu- tational Social Systems10(3), 1288–1300 (2022)
Li, H., Xu, M., Bhowmick, S.S., Rayhan, J.S., Sun, C., Cui, J.: Piano: Influence maximization meets deep reinforcement learning. IEEE Transactions on Compu- tational Social Systems10(3), 1288–1300 (2022)
2022
-
[19]
In: Proceedings of 16 H Niu et al
Lin, S.C., Lin, S.D., Chen, M.S.: A learning-based framework to handle multi- round multi-party influence maximization on social networks. In: Proceedings of 16 H Niu et al. the 21th ACM SIGKDD international conference on knowledge discovery and data mining. pp. 695–704 (2015)
2015
-
[20]
In: International conference on machine learning
Ling, C., Jiang, J., Wang, J., Thai, M.T., Xue, R., Song, J., Qiu, M., Zhao, L.: Deep graph representation learning and optimization for influence maximization. In: International conference on machine learning. pp. 21350–21361. PMLR (2023)
2023
-
[21]
IEEE Transactions on Emerging Topics in Computational Intelligence7(4), 995– 1009 (2022)
Ma, L., Shao, Z., Li, X., Lin, Q., Li, J., Leung, V.C., Nandi, A.K.: Influence max- imization in complex networks by using evolutionary deep reinforcement learning. IEEE Transactions on Emerging Topics in Computational Intelligence7(4), 995– 1009 (2022)
2022
-
[22]
Proceedings of the National Academy of Sciences122(4), e2410227122 (2025)
Meng, F., Xie, J., Sun, J., Xu, C., Zeng, Y., Wang, X., Jia, T., Huang, S., Deng, Y., Hu, Y.: Spreading dynamics of information on online social networks. Proceedings of the National Academy of Sciences122(4), e2410227122 (2025)
2025
-
[23]
Page, L., Brin, S., Motwani, R., Winograd, T.: The pagerank citation ranking: Bringing order to the web. Tech. rep., Stanford infolab (1999)
1999
-
[24]
In: AAAI (2015),https://networkrepository.com
Rossi, R.A., Ahmed, N.K.: The network data repository with interactive graph analytics and visualization. In: AAAI (2015),https://networkrepository.com
2015
-
[25]
IEEE Transactions on Parallel and Distributed Systems32(10), 2386–2399 (2021)
Shahrouz, S., Salehkaleybar, S., Hashemi, M.: gim: Gpu accelerated ris-based in- fluence maximization algorithm. IEEE Transactions on Parallel and Distributed Systems32(10), 2386–2399 (2021)
2021
-
[26]
In: Proceedings of the 2015 ACM SIGMOD international conference on management of data
Tang, Y., Shi, Y., Xiao, X.: Influence maximization in near-linear time: A martin- gale approach. In: Proceedings of the 2015 ACM SIGMOD international conference on management of data. pp. 1539–1554 (2015)
2015
-
[27]
In: Proceedings of the 2014 ACM SIGMOD international conference on Management of data
Tang, Y., Xiao, X., Shi, Y.: Influence maximization: Near-optimal time complexity meets practical efficiency. In: Proceedings of the 2014 ACM SIGMOD international conference on Management of data. pp. 75–86 (2014)
2014
-
[28]
Data Science and Engineering5, 1–11 (2020)
Tian, S., Mo, S., Wang, L., Peng, Z.: Deep reinforcement learning-based approach to tackle topic-aware influence maximization. Data Science and Engineering5, 1–11 (2020)
2020
-
[29]
stat1050(20), 10–48550 (2017)
Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., Bengio, Y., et al.: Graph attention networks. stat1050(20), 10–48550 (2017)
2017
-
[30]
Data Mining and Knowledge Discov- ery25, 545–576 (2012)
Wang, C., Chen, W., Wang, Y.: Scalable influence maximization for independent cascade model in large-scale social networks. Data Mining and Knowledge Discov- ery25, 545–576 (2012)
2012
-
[31]
ACM Computing Surveys55(5), 1–37 (2022)
Wu, S., Sun, F., Zhang, W., Xie, X., Cui, B.: Graph neural networks in recom- mender systems: a survey. ACM Computing Surveys55(5), 1–37 (2022)
2022
-
[32]
In: Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval
Ye, M., Liu, X., Lee, W.C.: Exploring social influence for recommendation: a gen- erative model approach. In: Proceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval. pp. 671–680 (2012)
2012
-
[33]
Advances in neural information processing systems33, 5812–5823 (2020)
You, Y., Chen, T., Sui, Y., Chen, T., Wang, Z., Shen, Y.: Graph contrastive learn- ing with augmentations. Advances in neural information processing systems33, 5812–5823 (2020)
2020
-
[34]
Zhang, G., Yue, Y., Sun, X., Wan, G., Yu, M., Fang, J., Wang, K., Chen, T., Cheng, D.: G-designer: Architecting multi-agent communication topologies via graph neu- ral networks. arXiv preprint arXiv:2410.11782 (2024)
-
[35]
Expert Systems with Applications p
Zhu, W., Zhang, K., Zhong, J., Hou, C., Ji, J.: Bigdn: An end-to-end influence maximization framework based on deep reinforcement learning and graph neural networks. Expert Systems with Applications p. 126384 (2025)
2025
-
[36]
arXiv preprint arXiv:2109.01116 (2021)
Zhu, Y., Xu, Y., Liu, Q., Wu, S.: An empirical study of graph contrastive learning. arXiv preprint arXiv:2109.01116 (2021)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.