Recognition: no theorem link
PERCEIVE: A Benchmark for Personalized Emotion and Communication Behavior Understanding on Social Media
Pith reviewed 2026-05-14 21:53 UTC · model grok-4.3
The pith
PERCEIVE is the first benchmark to combine social media posts with readers' real comments, behavior, attributes and networks for personalized emotion analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PERCEIVE supplies the first large-scale bilingual resource that simultaneously records author content, emotion labels derived directly from reader comments, communication intent, user attributes and the full social graph, thereby supporting reader-centric rather than author-centric emotion and behavior modeling.
What carries the argument
The PERCEIVE benchmark dataset, which annotates genuine emotional responses from reader comments while synchronously recording communication behavior and social context across English and Chinese posts.
If this is right
- Emotion models must incorporate individual reader differences instead of assuming a single response to a given post.
- Communication behavior and emotional feedback become jointly modellable when both are tied to the same social context.
- Standard author-centric methods, including current large language models, fall short on tasks that require reader-specific predictions.
- Future work can use the benchmark to develop unified systems that treat emotion as emerging from social interactions rather than isolated text.
Where Pith is reading between the lines
- The dataset could support improved content moderation tools that flag posts likely to trigger strong negative reactions for particular user groups.
- Linking comments to social graphs opens the possibility of studying how emotional responses spread or cluster within communities.
- Extending the same annotation approach to other platforms or languages would test whether the observed reader-author gaps generalize beyond the current bilingual collection.
Load-bearing premise
Emotions labeled from reader comments accurately capture genuine emotional responses, and the included user attributes plus social graph are enough to support effective personalization for different readers.
What would settle it
A concrete test would be whether models trained on PERCEIVE can predict the emotion a specific reader will express in a new comment more accurately than models that ignore reader identity and social connections; failure to show this gain would undermine the claim that the five dimensions enable meaningful personalization.
Figures






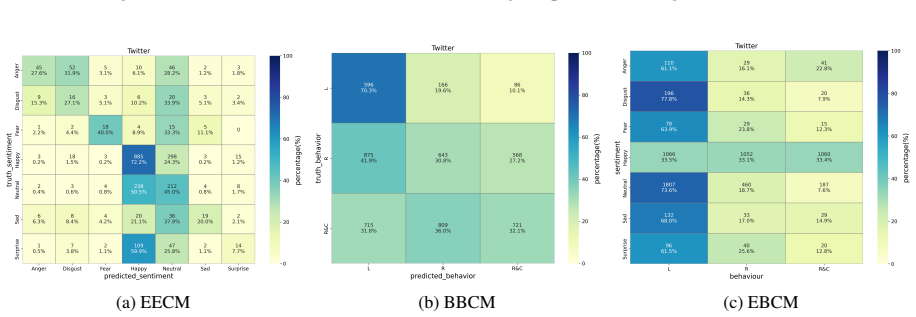




















read the original abstract
Current emotion analysis in social media is predominantly author-centric, failing to capture the subjective nature of emotional responses across diverse readers. This paradigm overlooks the crucial link between individual perception, communication behavior, and the underlying social network. To bridge this gap, we introduce PERCEIVE, a novel bilingual (English and Chinese) large-scale benchmark that, to the best of our knowledge, is the first to integrate five critical dimensions for social perception: author-created content, genuine readers' emotional feedback (derived from their comments), communication behavior, user attributes, and the social graph. This benchmark enables a paradigm shift towards truly personalized, reader-centric analysis, where different readers' emotional responses to the same content are naturally captured through their real-world interactions. By annotating emotions from reader comments and synchronously capturing communication intent, PERCEIVE provides a unique resource to model the intrinsic coupling between emotion and behavior, grounded in social context. We establish a comprehensive evaluation protocol, testing state-of-the-art methods, including large language models (LLMs) with advanced reasoning enhancement. Our findings reveal significant shortcomings in existing approaches when handling this multifaceted, user-aware task. PERCEIVE offers a foundational resource and clear direction for future research in socially-intelligent NLP, pushing models towards a more unified understanding of emotion on social media.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PERCEIVE, a novel bilingual (English-Chinese) large-scale benchmark for personalized emotion and communication behavior understanding on social media. It claims to be the first resource integrating five dimensions—author-created content, genuine readers' emotional feedback derived from comments, communication behavior, user attributes, and the social graph—enabling reader-centric analysis that captures varying emotional responses to the same content through real interactions. The work provides an evaluation protocol for state-of-the-art methods including LLMs with reasoning enhancements and reports significant shortcomings in existing approaches for this multifaceted task.
Significance. If the dataset construction, annotation reliability, and validation of comment-derived emotion labels are rigorously demonstrated, PERCEIVE would offer a valuable foundational resource for socially-intelligent NLP. It would enable research on the coupling between personalized emotion perception, communication intent, and social context in a multilingual setting, addressing a gap in author-centric emotion analysis and supporting models that account for individual reader differences grounded in observable interactions.
major comments (3)
- [Abstract] Abstract: The central claim that the benchmark captures 'genuine readers' emotional feedback (derived from their comments)' is unsupported. No details are supplied on data collection methods, annotation procedures, inter-annotator agreement, or any validation (e.g., comparison to self-report scales or physiological measures) showing that comment labels reflect private affective responses rather than public communicative behavior already captured in the separate communication-behavior dimension.
- [Benchmark Construction] Benchmark construction description: The integration of the social graph and user attributes is asserted to enable effective personalization, but the manuscript provides no quantitative information on graph scale, density, attribute completeness, or ablation studies demonstrating their contribution to modeling reader-specific emotional responses.
- [Evaluation Protocol] Evaluation protocol: The paper states that it tests SOTA methods including LLMs and reveals 'significant shortcomings,' yet supplies no concrete metrics, baseline comparisons, or dataset statistics (size, label distribution, IAA scores) to ground these findings or allow replication.
minor comments (2)
- [Benchmark Description] Clarify the exact annotation schema for emotions and communication intent with example comment threads to distinguish the two dimensions.
- [Dataset Statistics] Add a table summarizing dataset statistics (number of posts, comments, users, edges) broken down by language.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing PERCEIVE. We address each major comment point by point below, providing clarifications from the full paper and indicating revisions to strengthen the presentation of data collection, quantitative details, and evaluation results.
read point-by-point responses
-
Referee: [Abstract] The central claim that the benchmark captures 'genuine readers' emotional feedback (derived from their comments)' is unsupported. No details are supplied on data collection methods, annotation procedures, inter-annotator agreement, or any validation (e.g., comparison to self-report scales or physiological measures) showing that comment labels reflect private affective responses rather than public communicative behavior already captured in the separate communication-behavior dimension.
Authors: We acknowledge the need for greater explicitness in the abstract. The full manuscript details data collection via public social media APIs capturing real user comments on posts, with emotion labels derived through a hybrid process of automated detection followed by human annotation. We will revise the abstract and add a dedicated subsection on annotation procedures, including inter-annotator agreement metrics. We distinguish emotion labels (focused on affective content in comments) from the separate communication-behavior dimension (e.g., reply patterns and intent). Direct physiological validation is impractical at this scale, but we will incorporate additional discussion of correlations with observable interaction patterns and cite supporting literature on comment-based emotion proxies. revision: yes
-
Referee: [Benchmark Construction] The integration of the social graph and user attributes is asserted to enable effective personalization, but the manuscript provides no quantitative information on graph scale, density, attribute completeness, or ablation studies demonstrating their contribution to modeling reader-specific emotional responses.
Authors: The manuscript describes the integration but we agree that explicit quantitative summaries were not sufficiently prominent. In revision we will add specific statistics on graph scale (number of nodes and edges), density, and attribute completeness rates, along with ablation experiments quantifying the contribution of graph and attribute features to personalization performance. revision: yes
-
Referee: [Evaluation Protocol] The paper states that it tests SOTA methods including LLMs and reveals 'significant shortcomings,' yet supplies no concrete metrics, baseline comparisons, or dataset statistics (size, label distribution, IAA scores) to ground these findings or allow replication.
Authors: We will expand the evaluation section to prominently report all key dataset statistics (size, label distributions, IAA scores), full baseline comparisons across methods including LLMs with and without reasoning enhancements, and concrete performance metrics. This will ground the claims of shortcomings and support replication. revision: yes
Circularity Check
No circularity: benchmark dataset creation with no derivations or self-referential fits
full rationale
The paper introduces an external bilingual benchmark (PERCEIVE) that annotates five dimensions from public social media data: author content, reader comments for emotion labels, communication behavior, user attributes, and social graph. No equations, parameter fitting, predictions, or first-principles derivations are claimed. The central contribution is resource creation plus an evaluation protocol that tests existing models (including LLMs) on the new data. This is self-contained against external benchmarks and does not reduce any result to its own inputs by construction. Self-citations, if present, are not load-bearing for any claimed result. The reader's circularity score of 0.0 is confirmed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Emotions can be reliably inferred and annotated from reader comments on social media posts
Reference graph
Works this paper leans on
-
[1]
Ye, Jing and Xiang, Lu and Zhang, Yaping and Zong, Chengqing. From Generic Empathy to Personalized Emotional Support: A Self-Evolution Framework for User Preference Alignment. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1024
-
[2]
Exploring Persona Sentiment Sensitivity in Personalized Dialogue Generation
Jun, Yonghyun and Lee, Hwanhee. Exploring Persona Sentiment Sensitivity in Personalized Dialogue Generation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.900
-
[3]
Proceedings of the AAAI conference on artificial intelligence , volume=
Hg-sl: Jointly learning of global and local user spreading behavior for fake news early detection , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , pages=
work page 2025
-
[5]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[6]
Exploiting Rich Textual User-Product Context for Improving Personalized Sentiment Analysis
Lyu, Chenyang and Yang, Linyi and Zhang, Yue and Graham, Yvette and Foster, Jennifer. Exploiting Rich Textual User-Product Context for Improving Personalized Sentiment Analysis. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.92
-
[7]
Jian Liao and Yu Feng and Yujin Zheng and Jun Zhao and Suge Wang and Jianxing Zheng. My Words Imply Your Opinion: Reader Agent-based Propagation Enhancement for Personalized Implicit Emotion Analysis. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025
work page 2025
-
[8]
Emotion in Organizations: Theory and Research
Elfenbein, Hillary Anger. Emotion in Organizations: Theory and Research. Annual Review of Psychology. 2023. doi:https://doi.org/10.1146/annurev-psych-032720-035940
-
[9]
M - ABSA : A Multilingual Dataset for Aspect-Based Sentiment Analysis
Wu, ChengYan and Ma, Bolei and Liu, Yihong and Zhang, Zheyu and Deng, Ningyuan and Li, Yanshu and Chen, Baolan and Zhang, Yi and Xue, Yun and Plank, Barbara. M - ABSA : A Multilingual Dataset for Aspect-Based Sentiment Analysis. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.128
-
[10]
ECC : An Emotion-Cause Conversation Dataset for Empathy Response
He, Yuanyuan and Pan, Yongsen and Li, Wei and You, Jiali and Deng, Jiawen and Ren, Fuji. ECC : An Emotion-Cause Conversation Dataset for Empathy Response. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.306
-
[11]
Chebolu, Siva Uday Sampreeth and Dernoncourt, Franck and Lipka, Nedim and Solorio, Thamar. OATS : A Challenge Dataset for Opinion Aspect Target Sentiment Joint Detection for Aspect-Based Sentiment Analysis. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
work page 2024
-
[12]
S em E val-2014 Task 4: Aspect Based Sentiment Analysis
Pontiki, Maria and Galanis, Dimitris and Pavlopoulos, John and Papageorgiou, Harris and Androutsopoulos, Ion and Manandhar, Suresh. S em E val-2014 Task 4: Aspect Based Sentiment Analysis. Proceedings of the 8th International Workshop on Semantic Evaluation ( S em E val 2014). 2014. doi:10.3115/v1/S14-2004
-
[13]
S im USER : Simulating User Behavior with Large Language Models for Recommender System Evaluation
Bougie, Nicolas and Watanabe, Narimawa. S im USER : Simulating User Behavior with Large Language Models for Recommender System Evaluation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track). 2025. doi:10.18653/v1/2025.acl-industry.5
-
[14]
Evaluating Cognitive-Behavioral Fixation via Multimodal User Viewing Patterns on Social Media
Wang, Yujie and Zhao, Yunwei and Yang, Jing and Han, Han and Shan, Shiguang and Zhang, Jie. Evaluating Cognitive-Behavioral Fixation via Multimodal User Viewing Patterns on Social Media. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.987
-
[15]
Implicit Behavioral Alignment of Language Agents in High-Stakes Crowd Simulations
Wang, Yunzhe and Lucas, Gale and Becerik-Gerber, Burcin and Ustun, Volkan. Implicit Behavioral Alignment of Language Agents in High-Stakes Crowd Simulations. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1562
-
[16]
B e S imulator: A Large Language Model Powered Text-based Behavior Simulator
Wang, Jianan and Li, Bin and Qi, Jingtao and Wang, Xueying and Li, Fu and Lihanxun. B e S imulator: A Large Language Model Powered Text-based Behavior Simulator. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.237
-
[17]
Mou, Xinyi and Wei, Zhongyu and Huang, Xuanjing. Unveiling the Truth and Facilitating Change: Towards Agent-based Large-scale Social Movement Simulation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.285
-
[18]
From Individual to Society: A Survey on Social Simulation Driven by Large Language Model-based Agents , author=. 2024 , eprint=
work page 2024
-
[19]
Hellwig, Nils Constantin and Fehle, Jakob and Kruschwitz, Udo and Wolff, Christian. Do we still need Human Annotators? Prompting Large Language Models for Aspect Sentiment Quad Prediction. Proceedings of the 1st Joint Workshop on Large Language Models and Structure Modeling (XLLM 2025). 2025. doi:10.18653/v1/2025.xllm-1.15
-
[20]
Zhou, Wangchunshu and Li, Qifei and Li, Chenle. Learning to Predict Persona Information for Dialogue Personalization without Explicit Persona Description. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.186
-
[21]
L a MP : When Large Language Models Meet Personalization
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed. L a MP : When Large Language Models Meet Personalization. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.399
-
[22]
LLM s + Persona-Plug = Personalized LLM s
Liu, Jiongnan and Zhu, Yutao and Wang, Shuting and Wei, Xiaochi and Min, Erxue and Lu, Yu and Wang, Shuaiqiang and Yin, Dawei and Dou, Zhicheng. LLM s + Persona-Plug = Personalized LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.461
-
[23]
Yang, Senqi and Zhang, Dongyu and Ren, Jing and Xu, Ziqi and Zhang, Xiuzhen and Song, Yiliao and Lin, Hongfei and Xia, Feng. Cultural Bias Matters: A Cross-Cultural Benchmark Dataset and Sentiment-Enriched Model for Understanding Multimodal Metaphors. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long P...
-
[24]
Fostering YouTube followers’ stickiness through social contagion: The role of digital influencer' characteristics and followers’ compensation psychology , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.chb.2024.108304 , url =
-
[25]
MEC o T : M arkov Emotional Chain-of-Thought for Personality-Consistent Role-Playing
Wei, Yangbo and Huang, Zhen and Zhao, Fangzhou and Feng, Qi and Xing, Wei W. MEC o T : M arkov Emotional Chain-of-Thought for Personality-Consistent Role-Playing. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.435
-
[26]
Frontiers in Psychology , VOLUME=
Ahmad, Rehan and Nawaz, Muhammad Rafay and Ishaq, Muhammad Ishtiaq and Khan, Mumtaz Muhammad and Ashraf, Hafiz Ahmad , TITLE=. Frontiers in Psychology , VOLUME=. 2023 , DOI=
work page 2023
-
[27]
i N ews: A Multimodal Dataset for Modeling Personalized Affective Responses to News
Hu, Tiancheng and Collier, Nigel. i N ews: A Multimodal Dataset for Modeling Personalized Affective Responses to News. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1217
-
[28]
Liu, Haijiang and Li, Qiyuan and Gao, Chao and Cao, Yong and Xu, Xiangyu and Wu, Xun and Hershcovich, Daniel and Gu, Jinguang. Beyond Demographics: Enhancing Cultural Value Survey Simulation with Multi-Stage Personality-Driven Cognitive Reasoning. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1...
-
[29]
Sentiment Analysis using the Relationship between Users and Products
Kertkeidkachorn, Natthawut and Shirai, Kiyoaki. Sentiment Analysis using the Relationship between Users and Products. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.547
-
[30]
Communication Research , volume=
Spiral of Silence in the Social Media Era: A Simulation Approach to the Interplay Between Social Networks and Mass Media , author=. Communication Research , volume=. 2022 , pages=
work page 2022
-
[31]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools , author=. 2024 , journal=
work page 2024
-
[32]
GLM : General Language Model Pretraining with Autoregressive Blank Infilling
Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie. GLM : General Language Model Pretraining with Autoregressive Blank Infilling. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022
work page 2022
-
[33]
Liao, Jian and Lei, Jia and Wang, Suge and Zheng, Jianxing and Han, Xiaoqing , booktitle=. Personalized Implicit Sentiment Analysis Based on Multi-view Fusion of Implicit User Preference , year=
-
[34]
Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
Rdgcn: Reinforced dependency graph convolutional network for aspect-based sentiment analysis , author=. Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages=
-
[35]
Lazy, not biased: Susceptibility to partisan fake news is better explained by lack of reasoning than by motivated reasoning , author=. Cognition , volume=. 2019 , publisher=
work page 2019
-
[36]
Xu, L. and Lin, Hongfei and Pan, Y. and Ren, H. and Chen, J. , year =. Constructing the affective lexicon ontology , volume =
-
[37]
Advances in Neural Information Processing Systems , volume=
Demystifying oversmoothing in attention-based graph neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
IEEE Transactions on knowledge and data engineering , volume=
Knowledge graph augmented network towards multiview representation learning for aspect-based sentiment analysis , author=. IEEE Transactions on knowledge and data engineering , volume=. 2023 , publisher=
work page 2023
-
[39]
Causal Intervention Improves Implicit Sentiment Analysis
Siyin Wang and Jie Zhou and Changzhi Sun and Junjie Ye and Tao Gui and Qi Zhang and Xuanjing Huang , pages=. Causal Intervention Improves Implicit Sentiment Analysis. , booktitle=
-
[40]
Ma, Fukun and Hu, Xuming and Liu, Aiwei and Yang, Yawen and Li, Shuang and Yu, Philip S. and Wen, Lijie. AMR -based Network for Aspect-based Sentiment Analysis. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.19
-
[41]
Text Generation Model Enhanced with Semantic Information in Aspect Category Sentiment Analysis
Tran, Tu and Shirai, Kiyoaki and Kertkeidkachorn, Natthawut. Text Generation Model Enhanced with Semantic Information in Aspect Category Sentiment Analysis. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.323
-
[42]
Research on Implicit Sentiment Analysis based on Heterogeneous User Knowledge Fusion (in C hinese)
Liao, Jian and Zhang, Kai and Wang, Suge and Lei, Jia and Zhang, Yiyang. Research on Implicit Sentiment Analysis based on Heterogeneous User Knowledge Fusion (in C hinese). Proceedings of the 21st Chinese National Conference on Computational Linguistics. 2022
work page 2022
-
[43]
P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks
Liu, Xiao and Ji, Kaixuan and Fu, Yicheng and Tam, Weng and Du, Zhengxiao and Yang, Zhilin and Tang, Jie. P -Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.8
-
[44]
Reasoning Implicit Sentiment with Chain-of-Thought Prompting
Fei, Hao and Li, Bobo and Liu, Qian and Bing, Lidong and Li, Fei and Chua, Tat-Seng. Reasoning Implicit Sentiment with Chain-of-Thought Prompting. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.101
-
[45]
Multimodal Multi-loss Fusion Network for Sentiment Analysis
Wu, Zehui and Gong, Ziwei and Koo, Jaywon and Hirschberg, Julia. Multimodal Multi-loss Fusion Network for Sentiment Analysis. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.197
-
[46]
Wang, Zhihao and Zhang, Bo and Yang, Ru and Guo, Chang and Li, Maozhen. DAGCN : Distance-based and Aspect-oriented Graph Convolutional Network for Aspect-based Sentiment Analysis. Findings of the Association for Computational Linguistics: NAACL 2024. 2024. doi:10.18653/v1/2024.findings-naacl.120
-
[47]
arXiv preprint arXiv:2402.16539 , year=
Integrating Large Language Models with Graphical Session-Based Recommendation , author=. arXiv preprint arXiv:2402.16539 , year=
-
[48]
Youwei Liang and Dong Huang and Chang-Dong Wang and Philip S. Yu , pages=. IEEE Transactions on Neural Networks and Learning Systems , title=
-
[49]
Lightgcn: Simplifying and Powering Graph Convolution Network for Recommendation , author=. Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval , pages=
-
[50]
Role theory: Expectations, identities, and behaviors , author=. 2013 , publisher=
work page 2013
-
[51]
arXiv preprint arXiv:2402.18590 , year=
Exploring the Impact of Large Language Models on Recommender Systems: An Extensive Review , author=. arXiv preprint arXiv:2402.18590 , year=
-
[52]
DEEM : Dynamic Experienced Expert Modeling for Stance Detection
Wang, Xiaolong and Wang, Yile and Cheng, Sijie and Li, Peng and Liu, Yang. DEEM : Dynamic Experienced Expert Modeling for Stance Detection. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
work page 2024
-
[53]
Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions
Cai, Hongjie and Xia, Rui and Yu, Jianfei. Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.29
-
[54]
Emergent Abilities of Large Language Models
Emergent abilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Information Sciences , volume=
A dynamic adaptive multi-view fusion graph convolutional network recommendation model with dilated mask convolution mechanism , author=. Information Sciences , volume=. 2024 , publisher=
work page 2024
-
[56]
arXiv preprint arXiv:2405.16631 , year=
Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models , author=. arXiv preprint arXiv:2405.16631 , year=
-
[57]
arXiv preprint arXiv:2402.09176 , year=
Large Language Model Interaction Simulator for Cold-Start Item Recommendation , author=. arXiv preprint arXiv:2402.09176 , year=
-
[58]
arXiv preprint arXiv:2402.12150 , year=
Your Large Language Model is Secretly a Fairness Proponent and You Should Prompt it Like One , author=. arXiv preprint arXiv:2402.12150 , year=
-
[59]
arXiv preprint arXiv:2402.04559 , year=
Can Large Language Model Agents Simulate Human Trust Behaviors? , author=. arXiv preprint arXiv:2402.04559 , year=
-
[60]
arXiv preprint arXiv:2402.13374 , year=
Reliable LLM-based user simulator for task-oriented dialogue systems , author=. arXiv preprint arXiv:2402.13374 , year=
-
[61]
arXiv preprint arXiv:2309.13233 , year=
User simulation with large language models for evaluating task-oriented dialogue , author=. arXiv preprint arXiv:2309.13233 , year=
-
[62]
Exploiting simulated user feedback for conversational search: Ranking, rewriting, and beyond , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[63]
arXiv preprint arXiv:2306.00774 , year=
In-context learning user simulators for task-oriented dialog systems , author=. arXiv preprint arXiv:2306.00774 , year=
-
[64]
Li, Zhengyan and Zou, Yicheng and Zhang, Chong and Zhang, Qi and Wei, Zhongyu. Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.22
-
[65]
The impacts of data, ordering, and intrinsic dimensionality on recall in hierarchical navigable small worlds , author=. Proceedings of the 2024 ACM SIGIR International Conference on Theory of Information Retrieval , pages=
work page 2024
-
[66]
2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=
Scalable distance labeling maintenance and construction for dynamic small-world networks , author=. 2024 IEEE 40th International Conference on Data Engineering (ICDE) , pages=. 2024 , organization=
work page 2024
-
[67]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Tracking and Identifying International Propaganda and Influence Networks Online , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[68]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Political actor agent: Simulating legislative system for roll call votes prediction with large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Is LLMs Hallucination Usable? LLM-based Negative Reasoning for Fake News Detection , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[70]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Does your AI agent get you? A personalizable framework for approximating human models from argumentation-based dialogue traces , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Exploring Model Editing for LLM-based Aspect-Based Sentiment Classification , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[72]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
SimRP: Syntactic and Semantic Similarity Retrieval Prompting Enhances Aspect Sentiment Quad Prediction , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[73]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Open models, closed minds? on agents capabilities in mimicking human personalities through open large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[74]
ACM Transactions on Knowledge Discovery from Data , volume=
Structural properties on scale-free tree network with an ultra-large diameter , author=. ACM Transactions on Knowledge Discovery from Data , volume=. 2024 , publisher=
work page 2024
-
[75]
Proceedings of the 40th International Conference on Machine Learning , pages =
Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[76]
MBTI Personality Prediction for Fictional Characters Using Movie Scripts
Sang, Yisi and Mou, Xiangyang and Yu, Mo and Wang, Dakuo and Li, Jing and Stanton, Jeffrey. MBTI Personality Prediction for Fictional Characters Using Movie Scripts. Findings of the Association for Computational Linguistics: EMNLP 2022. 2022. doi:10.18653/v1/2022.findings-emnlp.500
-
[77]
Joshua N. Hook and Todd W. Hall and Don E. Davis and Daryl R. Van Tongeren and Mackenzie Conner , pages=. The Enneagram: A Systematic Review of the Literature and Directions for Future Research , volume=77, year=2021, journal=
work page 2021
-
[78]
Anita Feher and Philip A. Vernon , pages=. Looking Beyond the Big Five: A Selective Review of Alternatives to the Big Five Model of Personality , volume=169, year=2021, journal=
work page 2021
-
[79]
Van Lange, Paul A. M. and Higgins, E Tory and Kruglanski, Arie W. Handbook of Theories of Social Psychology. 2011
work page 2011
-
[80]
doi:doi:10.1515/9783110226324 , isbn =
Narratology: An Introduction , author =. doi:doi:10.1515/9783110226324 , isbn =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.