Recognition: 1 theorem link
· Lean TheoremCROP: Expert-Aligned Image Cropping via Compositional Reasoning and Optimizing Preference
Pith reviewed 2026-05-14 21:32 UTC · model grok-4.3
The pith
A vision-language model crops images to match expert aesthetics by reasoning through scene analysis, composition rules, and preference alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
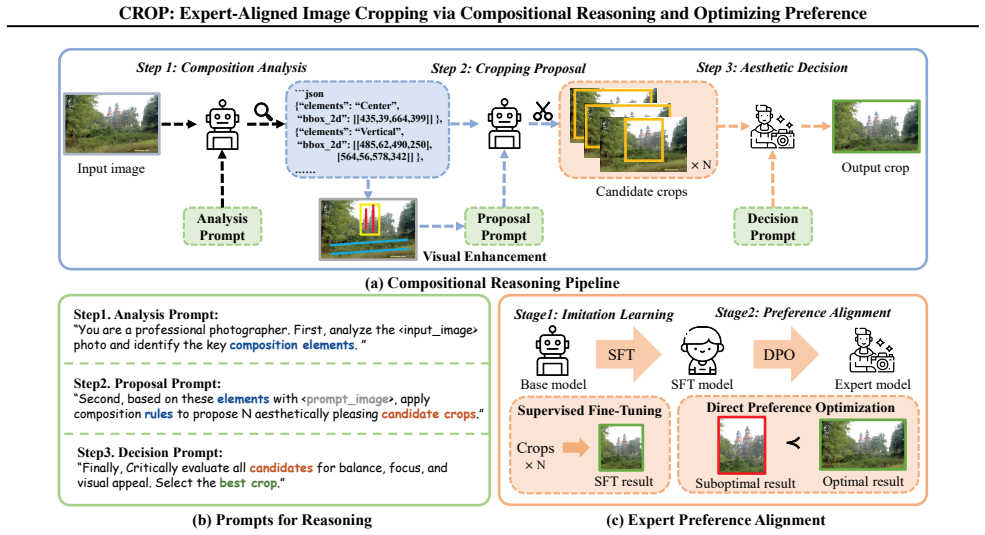
The central claim is that directing a vision-language model through an explicit analysis-proposal-decision process, paired with an expert preference alignment module, produces cropping decisions that align more closely with human experts and outperform both saliency-based and retrieval-based baselines across multiple datasets.
What carries the argument
The analysis-proposal-decision process, which deconstructs cropping into sequential steps of scene element analysis followed by compositional reasoning and final decision, together with the expert preference alignment module that enforces consistency with human aesthetic judgments.
If this is right
- Cropping decisions become adaptive to the specific content and composition of each image instead of defaulting to generic saliency maps.
- The model learns to make explicit trade-offs among competing compositional principles rather than relying on nearest-neighbor matches.
- Results remain consistent with expert choices even when scene elements create subjective ambiguity.
- The same reasoning structure can be applied to other composition-sensitive tasks that require step-by-step aesthetic judgment.
Where Pith is reading between the lines
- The same analysis-proposal-decision format could be tested on related subjective tasks such as video frame selection or graphic layout adjustment.
- If the alignment module generalizes, it might reduce the need for large task-specific training sets in other aesthetic applications.
- Real-world deployment would require checking whether the reasoning chain remains stable under image noise, compression artifacts, or mobile-device constraints.
Load-bearing premise
That a vision-language model can be reliably steered through the analysis-proposal-decision sequence and aligned to expert preferences so that its crops consistently beat simpler baselines on varied images.
What would settle it
A blind expert rating study on a held-out set of complex scenes in which the model's chosen crops receive lower average scores than those from established saliency or retrieval methods.
Figures









read the original abstract
Aesthetic image cropping aims to enhance the aesthetic quality of an image by improving its composition through spatial cropping. Previous methods often rely on saliency prediction or retrieval augmentation, ignoring the task's core requirement: a deep understanding of composition and aesthetics. Consequently, saliency-based methods struggle to make compositional trade-offs in complex scenes, while retrieval-based methods blindly refer to similar cases, lacking adaptive reasoning for unique scenes. Both approaches fail to align their automated cropping results with those of human experts. To address the above issues, we propose a novel paradigm that reformulates aesthetic cropping as a multimodal reasoning task, aiming to activate the VLM's analytical and comprehension capabilities in aesthetics. We design a Compositional Reasoning and Optimizing Preference method (CROP) that directs the VLM to think like a professional photographer. It deconstructs a complex and subjective aesthetic problem into an "analysis-proposal-decision" process, reasoning step by step through the analysis of scene elements and compositional principles. Meanwhile, our expert preference alignment module makes the model's decision consistent with human expert aesthetics. Extensive experiments across multiple datasets validate our method's superiority and component effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CROP, a Compositional Reasoning and Optimizing Preference method for aesthetic image cropping. It reformulates the task as a multimodal reasoning problem in which a VLM is directed through an explicit 'analysis-proposal-decision' pipeline that decomposes scene elements and compositional principles, augmented by an expert preference alignment module intended to enforce consistency with human expert aesthetics. The central claim is that this approach outperforms saliency-based and retrieval-based baselines by enabling adaptive, expert-aligned cropping decisions.
Significance. If the alignment mechanism functions as described, the work would offer a substantive shift from low-level saliency or case-retrieval methods toward explicit compositional reasoning in VLMs, addressing a recognized limitation in handling complex scenes and subjective trade-offs. The analysis-proposal-decision structure and expert alignment idea are conceptually promising for other subjective visual decision tasks.
major comments (2)
- [Expert Preference Alignment Module (Section 3)] The expert preference alignment module is described only at a high level; no formulation of the alignment objective, expert data collection protocol, or optimization procedure (prompt engineering, supervised fine-tuning, or preference loss) is provided. This detail is load-bearing for the claim that decisions become 'consistent with human expert aesthetics' and for the asserted superiority over baselines.
- [Experiments and Results] The abstract states that 'extensive experiments across multiple datasets validate our method's superiority and component effectiveness,' yet the provided text contains no quantitative results, implementation details, ablation numbers, or error analysis. Without these, the central empirical claim cannot be evaluated.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., mean IoU or aesthetic score improvement) to support the superiority claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the conceptual promise of the analysis-proposal-decision pipeline and expert alignment idea. We address each major comment below and will revise the manuscript to incorporate the requested details and ensure all empirical content is fully present.
read point-by-point responses
-
Referee: The expert preference alignment module is described only at a high level; no formulation of the alignment objective, expert data collection protocol, or optimization procedure (prompt engineering, supervised fine-tuning, or preference loss) is provided. This detail is load-bearing for the claim that decisions become 'consistent with human expert aesthetics' and for the asserted superiority over baselines.
Authors: We agree that the current description of the expert preference alignment module lacks necessary technical detail. In the revised manuscript we will add the precise formulation of the alignment objective, the expert data collection protocol (including expert recruitment, annotation guidelines, and resulting dataset statistics), and the optimization procedure (specifying whether prompt engineering, supervised fine-tuning, or a preference loss such as DPO is used). These additions will directly support the claim of consistency with human expert aesthetics. revision: yes
-
Referee: The abstract states that 'extensive experiments across multiple datasets validate our method's superiority and component effectiveness,' yet the provided text contains no quantitative results, implementation details, ablation numbers, or error analysis. Without these, the central empirical claim cannot be evaluated.
Authors: We apologize that the experimental section was missing from the version the referee received. The complete manuscript contains quantitative comparisons against saliency-based and retrieval-based baselines on multiple datasets, ablation studies isolating the compositional reasoning steps and the alignment module, full implementation details (model, hyperparameters, inference settings), and error analysis. We will ensure these sections appear in their entirety and are clearly organized in the revision. revision: yes
Circularity Check
No significant circularity in methodological proposal
full rationale
The paper introduces CROP as a new paradigm reformulating aesthetic cropping as multimodal reasoning in VLMs via an analysis-proposal-decision process plus an expert preference alignment module. No equations, derivations, or parameter-fitting steps are described that reduce any claimed output (e.g., cropping decisions) to inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core premises. Claims rest on empirical validation across datasets rather than self-referential definitions, making the approach self-contained with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Gee, L., Gritta, M., Lampouras, G., and Iacobacci, I. Code- optimise: Self-generated preference data for correctness and efficiency.arXiv preprint arXiv:2406.12502,
-
[4]
Jiang, R. and Chen, C. Multimodal llms can reason about aesthetics in zero-shot.arXiv preprint arXiv:2501.09012,
-
[5]
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct
9 CROP: Expert-Aligned Image Cropping via Compositional Reasoning and Optimizing Preference Luo, H., Sun, Q., Xu, C., Zhao, P., Lou, J., Tao, C., Geng, X., Lin, Q., Chen, S., and Zhang, D. Wizard- math: Empowering mathematical reasoning for large lan- guage models via reinforced evol-instruct.arXiv preprint arXiv:2308.09583,
-
[6]
Aligning codellms with direct pref- erence optimization.arXiv preprint arXiv:2410.18585,
Miao, Y ., Gao, B., Quan, S., Lin, J., Zan, D., Liu, J., Yang, J., Liu, T., and Deng, Z. Aligning codellms with direct pref- erence optimization.arXiv preprint arXiv:2410.18585,
-
[7]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Wang, C., Niu, L., Zhang, B., and Zhang, L. Image cropping with spatial-aware feature and rank consistency. InCVPR, 2023a. Wang, P., Li, L., Shao, Z., Xu, R., Dai, D., Li, Y ., Chen, D., Wu, Y ., and Sui, Z. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. arXiv preprint arXiv:2312.08935, 2023b. Wei, Z., Zhang, J., Shen, X....
work page internal anchor Pith review arXiv
-
[9]
PhotoFramer: Multi-modal Image Composition Instruction
You, Z., Wang, K., Zhang, H., Cai, X., Gu, J., Xue, T., Dong, C., and Zhang, Z. Photoframer: Multi-modal image com- position instruction.arXiv preprint arXiv:2512.00993,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Image composition as- sessment with saliency-augmented multi-pattern pooling
Zhang, B., Niu, L., and Zhang, L. Image composition as- sessment with saliency-augmented multi-pattern pooling. arXiv preprint arXiv:2104.03133,
-
[11]
Zhang, K., Ding, T., Jiang, J., Chen, T., Zharkov, I., Patel, V . M., and Liang, L. Procrop: Learning aesthetic image cropping from professional compositions.arXiv preprint arXiv:2505.22490,
- [12]
-
[13]
The pretrained Qwen2.5-VL-7B (Bai et al., 2025b) model is capable of effectively handling JSON-structured content. Leveraging this feature, we extract the compositional el- ement category labels and their corresponding bounding box coordinates from the CADB dataset to construct JSON- formatted response data, which are used for dialogue fine- tuning in the...
work page 2017
-
[14]
dataset as the source of annotations. GAICD dataset has 3,336 im- ages, with 2,636 for training, 200 for validation, and 500 for testing, containing 288,069 densely annotated crops with mean opinion scores (MOS) (Gao et al., 2022). For each 11 CROP: Expert-Aligned Image Cropping via Compositional Reasoning and Optimizing Preference Original image Subject ...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.