Recognition: 1 theorem link
· Lean TheoremUncovering Latent Pathological Signatures in Pulmonary CT via Cross-Window Knowledge Distillation
Pith reviewed 2026-05-14 20:50 UTC · model grok-4.3
The pith
Distilling knowledge from the best CT window transfers latent pathological signatures to students on other windows and raises per-window AUC by 10-16 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Student encoders learn latent clinical priors from a teacher trained on the most informative window; this cross-window distillation internalises pathological signatures invisible to ordinary supervised approaches and produces consistent AUC gains on three independent pulmonary CT cohorts.
What carries the argument
Cross-window knowledge distillation framework in which a teacher encoder trained on the optimal window transfers feature or soft-target knowledge to student encoders operating on other density windows.
Load-bearing premise
The teacher trained on the single best window already contains every clinically relevant cross-density signature and can pass them to the other windows without introducing bias or losing window-specific information.
What would settle it
A test set in which a given window contains a unique density-specific lesion absent from the teacher's window; if distillation produces no gain or a drop in AUC on that window, the central claim is false.
Figures


read the original abstract
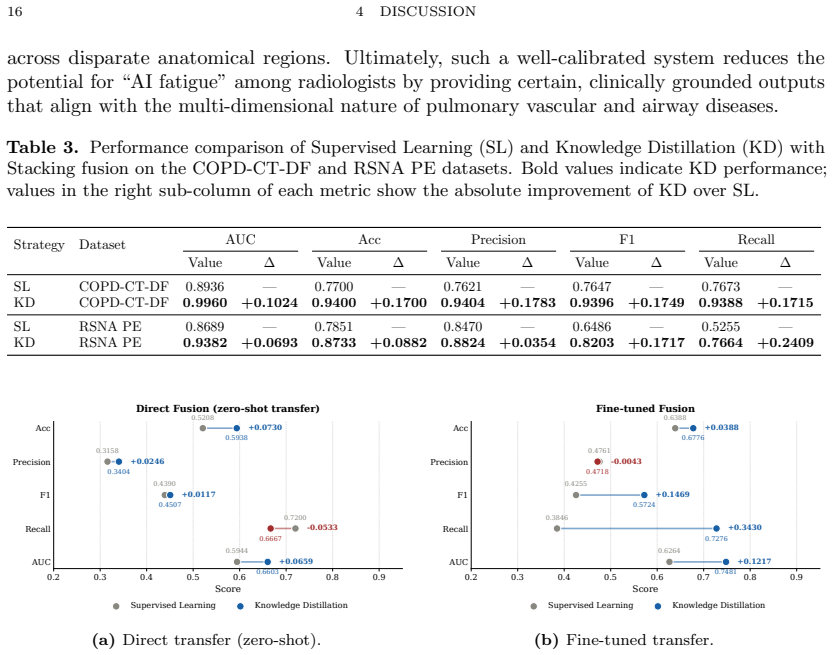
Multi-window CT imaging captures complementary pathological information across anatomical structures of differing densities, yet existing deep learning methods fuse representations only at later stages, missing cross-density interactions. We propose a cross-window knowledge distillation framework in which student encoders learn latent clinical priors from a teacher trained on the most informative window. Evaluated retrospectively on three cohorts - COPD-CT-DF (n=719), RSNA PE (n=1,433), and an in-house CTEPD dataset (n=161) - distillation improved per-window AUC by 10.1-16.5 percentage points on COPD-CT-DF (0.75-0.81 to 0.90-0.94; all P<0.001), with ensemble AUC reaching 0.9960. Similar gains were observed on RSNA PE (0.80-0.83 to 0.90-0.92) and CTEPD (AUC 0.7481 vs. 0.6264). Cross-window distillation internalises pathological signatures invisible to supervised approaches, offering a generalisable solution for multi-window pulmonary CT analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a cross-window knowledge distillation framework for multi-window pulmonary CT analysis. A teacher model is trained on the single most informative window to capture latent pathological signatures, which are then distilled to student encoders operating on other density windows. This is evaluated retrospectively on COPD-CT-DF (n=719), RSNA PE (n=1,433), and an in-house CTEPD (n=161) cohort, reporting per-window AUC gains of 10.1–16.5 percentage points on COPD-CT-DF (0.75–0.81 to 0.90–0.94, all P<0.001), ensemble AUC of 0.9960, and comparable improvements on the other datasets.
Significance. If the central claim holds after full verification, the work would be significant for multi-window CT analysis: it offers a mechanism to internalize cross-density pathological interactions via distillation rather than late fusion, with reported AUC lifts large enough to suggest clinical utility for COPD, PE, and CTEPD detection. The approach is generalizable in principle and could reduce the need for window-specific supervision.
major comments (2)
- [Abstract/Methods] Abstract and Methods: The central claim that distillation from a single teacher window successfully transfers all clinically relevant cross-density signatures is load-bearing, yet no ablation compares alternative teacher windows or quantifies information loss; the reported 10–16 pp AUC gains are therefore consistent with either successful transfer or simply stronger supervision, and cannot be distinguished without this test.
- [Abstract] Abstract: No details are supplied on architecture, loss functions, training protocol, or the procedure for selecting the 'most informative window'; without these the empirical results cannot be reproduced or verified, undermining assessment of the distillation mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below and will revise the manuscript to incorporate additional experiments and details as outlined.
read point-by-point responses
-
Referee: [Abstract/Methods] Abstract and Methods: The central claim that distillation from a single teacher window successfully transfers all clinically relevant cross-density signatures is load-bearing, yet no ablation compares alternative teacher windows or quantifies information loss; the reported 10–16 pp AUC gains are therefore consistent with either successful transfer or simply stronger supervision, and cannot be distinguished without this test.
Authors: We agree that an ablation comparing alternative teacher windows is required to isolate the effect of cross-density signature transfer from potential benefits of stronger supervision. In the revised manuscript we will add this experiment: we will train separate teachers on each density window, distill to the corresponding students, and report per-window AUCs together with a quantitative measure of information loss (feature-space KL divergence between teacher and student representations). This will directly test whether the originally selected window is optimal and whether the observed gains exceed those from window-specific supervision alone. revision: yes
-
Referee: [Abstract] Abstract: No details are supplied on architecture, loss functions, training protocol, or the procedure for selecting the 'most informative window'; without these the empirical results cannot be reproduced or verified, undermining assessment of the distillation mechanism.
Authors: The full Methods section already specifies the architecture (ResNet-50 encoders), composite loss (task cross-entropy plus KL distillation), optimizer (Adam, lr=1e-4, 50 epochs), and window-selection procedure (highest validation AUC on a held-out split). To address the referee’s concern we will expand the abstract with a concise sentence summarizing these elements so that the core mechanism is reproducible from the abstract alone. revision: yes
Circularity Check
No derivation chain present; purely empirical ML framework
full rationale
The manuscript proposes a cross-window knowledge distillation method and evaluates it via retrospective AUC metrics on three external cohorts. No equations, parameter-fitting steps, uniqueness theorems, or self-citations that reduce any claimed result to its own inputs appear in the provided text. Reported gains (10–16 pp AUC) are measured experimental outcomes, not quantities defined by construction from the same data or prior self-work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yanan Wu, Shuyue Xia, Zhenyu Liang, Rongchang Chen, and Shouliang Qi. Artificial intelligence in COPD CT images: identification, staging, and quantitation.Respir Res, 25(1):319, 2024. doi: 10.1186/s12931-024-02913-z
-
[2]
W Richard Webb, William E Brant, and Nancy M Major.Fundamentals of Body CT. Fundamentals of Radiology. Elsevier Health Sciences, 2015
work page 2015
-
[3]
Tao Yang, Chihua Chen, and Zhongyuanlong Chen. The CT pulmonary vascular parameters and disease severity in COPD patients on acute exacerbation: a correlation analysis.BMC Pulm Med, 21(1):34, 2021
work page 2021
-
[4]
Bartolome R Celli, Marc Decramer, Jadwiga A Wedzicha, Kevin C Wilson, Alvar Agust´ ı, Gerard J Criner, et al. An official American Thoracic Society/European Respiratory Society statement: research questions in chronic obstructive pulmonary disease.Am J Respir Crit Care Med, 191(7):e4–e27, 2015
work page 2015
-
[5]
Zixuan Hu, Hui Ming Lin, Shobhit Mathur, Robert Moreland, Christopher D Witiw, Laura Jimenez-Juan, et al. High performance with fewer labels using semi-weakly supervised learning for pulmonary embolism diagnosis.NPJ Digit Med, 8(1):254, 2025
work page 2025
-
[6]
Minyue Yin, Chao Xu, Jinzhou Zhu, Yuhan Xue, Yijia Zhou, Yu He, et al. Automated machine learning for the identification of asymptomatic COVID-19 carriers based on chest CT images.BMC Med Imaging, 24(1):50, 2024
work page 2024
-
[7]
G R Hemalakshmi, M Murugappan, Mohamed Yacin Sikkandar, D Santhi, N B Prakash, and A Mohanarathinam. PE-Ynet: a novel attention-based multi-task model for pulmonary embolism detection using CT pulmonary angiography (CTPA) scan images.Phys Eng Sci Med, 47(3):863–880, 2024
work page 2024
-
[8]
Knowledge distillation: a survey.Int J Comput Vis, 129(6):1789–1819, 2021
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: a survey.Int J Comput Vis, 129(6):1789–1819, 2021
work page 2021
-
[9]
Learnable cross-modal knowledge distillation for multi-modal learning with missing modality
Hu Wang, Congbo Ma, Jianpeng Zhang, Yuan Zhang, Jodie Avery, Louise Hull, and Gustavo Carneiro. Learnable cross-modal knowledge distillation for multi-modal learning with missing modality. InProc MICCAI, pages 216–226, 2023
work page 2023
-
[10]
C2KD: bridging the modality gap for cross-modal knowledge distillation
Fushuo Huo, Wenchao Xu, Jingcai Guo, Haozhao Wang, and Song Guo. C2KD: bridging the modality gap for cross-modal knowledge distillation. InProc CVPR, pages 16006–16015, 2024
work page 2024
-
[11]
Alvar Agust´ ı, Bartolome R Celli, Gerard J Criner, David Halpin, Antonio Anzueto, Peter Barnes, et al. Global initiative for chronic obstructive lung disease 2023 report: GOLD executive summary.Am J Respir Crit Care Med, 207(7):819–837, 2023
work page 2023
-
[12]
The RSNA pulmonary embolism CT dataset.Radiol Artif Intell, 3(2):e200254, 2021
Errol Colak, Felipe C Kitamura, Stephen B Hobbs, Carol C Wu, Matthew P Lungren, Luciano M Prevedello, et al. The RSNA pulmonary embolism CT dataset.Radiol Artif Intell, 3(2):e200254, 2021
work page 2021
-
[13]
Structural and inflammatory changes in COPD: a comparison with asthma
Peter K Jeffery. Structural and inflammatory changes in COPD: a comparison with asthma. Thorax, 53(2):129–136, 1998
work page 1998
-
[14]
Heidi Huhtanen, Mikko Nyman, Tarek Mohsen, Arho Virkki, Antti Karlsson, and Jussi Hirvonen. Automated detection of pulmonary embolism from CT-angiograms using deep learning.BMC Med Imaging, 22(1):43, 2022. 18 DISCUSSION
work page 2022
-
[15]
Identity mappings in deep residual networks
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. InProc ECCV, pages 630–645, 2016
work page 2016
-
[16]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. InProc CVPR, pages 7132–7141, 2018
work page 2018
-
[17]
Ibomoiye Domor Mienye and Yanxia Sun. A survey of ensemble learning: concepts, algorithms, applications, and prospects.IEEE Access, 10:99129–99149, 2022
work page 2022
-
[18]
Jibin B Thomas, K V Shihabudheen, Sheik Mohammed Sulthan, and Adel Al-Jumaily. Deep feature meta-learners ensemble models for COVID-19 CT scan classification.Electronics, 12(3):684, 2023
work page 2023
-
[19]
Kuan Wu, Xiaoyan Miu, Hui Wang, and Xiaodong Li. A Bayesian optimization tuning integrated multi-stacking classifier framework for the prediction of radiodermatitis from 4D-CT of patients underwent breast cancer radiotherapy.Front Oncol, 13:1152020, 2023
work page 2023
-
[20]
Guide to effect sizes and confidence intervals.OSF Preprints, 2024
Matthew B Jan´ e, Qinyu Xiao, Siu Kit Yeung, Flavio Azevedo, Mattan S Ben-Shachar, Aaron R Caldwell, et al. Guide to effect sizes and confidence intervals.OSF Preprints, 2024
work page 2024
-
[21]
Grad-CAM: visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: visual explanations from deep networks via gradient-based localization. InProc ICCV, pages 618–626, 2017
work page 2017
-
[22]
Mohammad Ennab and Hamid McHeick. Advancing AI interpretability in medical imaging: a comparative analysis of pixel-level interpretability and Grad-CAM models.Mach Learn Knowl Extr, 7(1):12, 2025. 19 A Validation Dataset and Annotation Protocol A.1 Participant Selection and Sampling Strategy To evaluate the mechanistic performance of the proposed architec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.