Recognition: unknown
DistractMIA: Black-Box Membership Inference on Vision-Language Models via Semantic Distraction
Pith reviewed 2026-05-14 20:39 UTC · model grok-4.3
The pith
DistractMIA infers VLM training membership by adding a semantic distractor to an image and tracking shifts in generated text responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
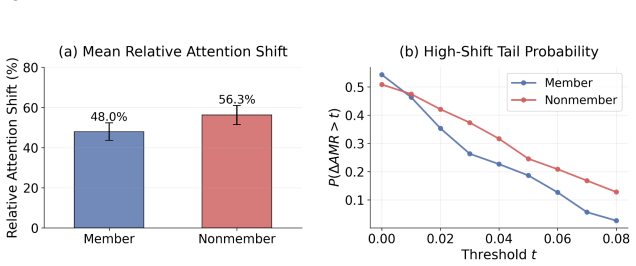
Member samples produce more stable responses that remain anchored to the original image semantics even after a distractor is introduced, whereas non-member samples more readily adopt the distractor; repeated generations therefore yield a usable membership score from text outputs alone.
What carries the argument
Semantic distraction process that preserves the original image, inserts a calibrated distractor, and derives membership from response stability plus distractor uptake across multiple generations.
If this is right
- Auditors can check for unauthorized use of private images in deployed VLMs using only query access.
- The attack applies to medical imaging benchmarks, not only natural-image datasets.
- Membership scoring requires no probability outputs or hidden states, only repeated text generations.
- The method outperforms both output-only baselines and stronger-access attacks on multiple VLMs.
Where Pith is reading between the lines
- The same distraction principle could be tested on other multimodal models that accept images and produce text.
- Measuring how distractor uptake changes with model scale or fine-tuning might reveal when the signal weakens.
- Combining semantic distraction with other low-access query patterns could further improve separation.
Load-bearing premise
Member samples remain anchored to the original image semantics while non-member samples are more readily redirected toward the added distractor.
What would settle it
Running the same calibrated distractor on a fresh set of known member and non-member images and finding no reliable difference in either response stability or frequency of distractor uptake.
Figures



read the original abstract
Vision-language models (VLMs) are trained on large-scale image-text corpora that may contain private, copyrighted, or otherwise sensitive data, motivating membership inference as a tool for training-data auditing. This is especially challenging for deployed VLMs, where auditors typically observe only generated textual responses. Existing VLM membership inference attacks either rely on probability-level signals unavailable in such settings, or use mask-based semantic prediction tasks whose effectiveness depends on object-centric visual assumptions. To address these limitations, we propose DistractMIA, an output-only black-box framework based on semantic distraction. Rather than removing visual evidence, DistractMIA preserves the original image, inserts a known semantic distractor, and measures how generated responses change. This design is motivated by the intuition that member samples remain more anchored to the original image semantics, while non-member samples are more easily redirected toward the distractor. To make this signal reliable, DistractMIA calibrates distractor configurations on a reference set and derives membership scores from repeated textual generations, capturing response stability and distractor uptake without accessing logits, probabilities, or hidden states. Experiments across multiple VLMs and benchmarks show that DistractMIA consistently outperforms both output-only and stronger-access baselines. Its performance on a medical benchmark further demonstrates applicability beyond object-centric natural images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DistractMIA, an output-only black-box membership inference attack for vision-language models. It preserves the original image, inserts a known semantic distractor, and measures changes in generated textual responses to derive membership scores from response stability and distractor uptake after calibrating distractor configurations on a reference set. The central claim is that member samples remain more anchored to original semantics while non-members are more easily redirected, leading to consistent outperformance over output-only and stronger-access baselines across multiple VLMs and benchmarks, with additional validation on a medical dataset.
Significance. If the results hold after addressing calibration details, DistractMIA would provide a practical advance for auditing training data in deployed VLMs under strict black-box constraints, extending MIA beyond probability-based or object-centric methods to diverse domains including medical imaging.
major comments (2)
- Abstract: the claim that DistractMIA 'consistently outperforms both output-only and stronger-access baselines' is unsupported by any quantitative results, error bars, statistical tests, or reference-set calibration details in the provided text, so the central empirical claim cannot be evaluated.
- Abstract and method description: the framework is presented as purely output-only black-box, yet it requires calibrating distractor configurations on a reference set; no information is given on whether this set can be obtained without known membership labels, which is load-bearing for the auditing applicability claim since realistic black-box scenarios lack such labels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and methodological clarity. We address each major comment below and will revise the manuscript to improve transparency and support for the central claims.
read point-by-point responses
-
Referee: Abstract: the claim that DistractMIA 'consistently outperforms both output-only and stronger-access baselines' is unsupported by any quantitative results, error bars, statistical tests, or reference-set calibration details in the provided text, so the central empirical claim cannot be evaluated.
Authors: The abstract summarizes the main findings, while the full manuscript reports quantitative results in Section 4 (Experiments), including AUC and accuracy tables across VLMs and datasets, standard deviations from repeated runs with error bars, and statistical significance tests (e.g., paired t-tests) against baselines. Reference-set calibration details appear in Section 3.2. To make the abstract self-contained, we will revise it to include key quantitative highlights such as average AUC improvements and mention of error bars and tests. revision: yes
-
Referee: Abstract and method description: the framework is presented as purely output-only black-box, yet it requires calibrating distractor configurations on a reference set; no information is given on whether this set can be obtained without known membership labels, which is load-bearing for the auditing applicability claim since realistic black-box scenarios lack such labels.
Authors: The reference set is used solely for unsupervised calibration of distractor parameters and does not require membership labels. It is constructed from a small pool of unlabeled samples available to the auditor (e.g., public images or self-collected queries), with calibration performed by maximizing response variance and stability metrics that are label-agnostic. This design preserves the output-only black-box setting for auditing. We will add a dedicated paragraph in Section 3.2 explicitly describing the label-free reference set construction and its applicability to realistic scenarios. revision: yes
Circularity Check
Empirical calibration on reference set introduces dependency but membership score does not reduce to fitted input by construction
full rationale
The abstract and described method derive membership scores from measured changes in textual responses (stability and distractor uptake) after calibrating distractor configurations on a reference set. No equations, self-citations, or ansatzes are quoted that define the score in terms of itself or force the prediction to match the calibration inputs by construction. The core intuition about anchoring is presented as motivation rather than a load-bearing uniqueness theorem or renamed known result. This matches the reader's assessment of minor non-circular dependency, yielding a low score with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
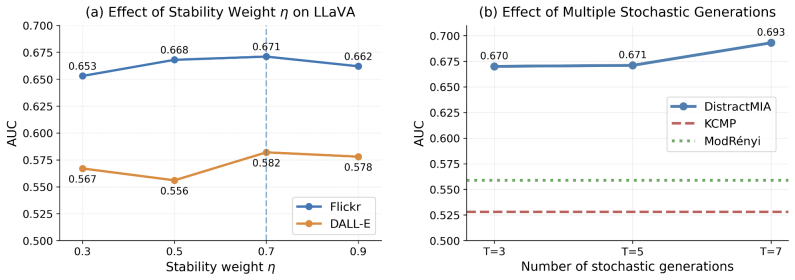
- distractor configuration
axioms (1)
- domain assumption Member samples remain more anchored to original image semantics than non-member samples when a distractor is added.
Reference graph
Works this paper leans on
-
[1]
Scaling up vision-language pre-training for image captioning
Xiaowei Hu, Zhe Gan, Jianfeng Wang, Zhengyuan Yang, Zicheng Liu, Yumao Lu, and Lijuan Wang. Scaling up vision-language pre-training for image captioning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17980–17989, 2022
work page 2022
-
[2]
Christel Chappuis, Valérie Zermatten, Sylvain Lobry, Bertrand Le Saux, and Devis Tuia. Prompt-rsvqa: Prompting visual context to a language model for remote sensing visual question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1372–1381, 2022
work page 2022
-
[3]
Jiannan Wu, Muyan Zhong, Sen Xing, Zeqiang Lai, Zhaoyang Liu, Zhe Chen, Wenhai Wang, Xizhou Zhu, Lewei Lu, Tong Lu, et al. Visionllm v2: An end-to-end generalist multimodal large language model for hundreds of vision-language tasks.Advances in Neural Information Processing Systems, 37:69925–69975, 2024
work page 2024
-
[4]
Zilun Zhang, Tiancheng Zhao, Yulong Guo, and Jianwei Yin. Rs5m and georsclip: A large- scale vision-language dataset and a large vision-language model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–23, 2024
work page 2024
-
[5]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
UK Judiciary. Getty images v. stability AI judgment. https://www.judiciary.uk/ wp-content/uploads/2025/11/Getty-Images-v-Stability-AI.pdf , 2025. Accessed: 2025
work page 2025
-
[7]
Google and the university of chicago are sued over data sharing.The New York Times, June 2019
Wakabayashi Daisuke. Google and the university of chicago are sued over data sharing.The New York Times, June 2019. URL https://www.nytimes.com/2019/06/26/technology/ google-university-chicago-data-sharing-lawsuit.html
work page 2019
-
[8]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017
work page 2017
-
[9]
Membership inference attacks from first principles
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. Membership inference attacks from first principles. In2022 IEEE symposium on security and privacy (SP), pages 1897–1914. IEEE, 2022
work page 1914
-
[10]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InThe Twelfth International Conference on Learning Representations. 10
-
[11]
Identifying pre-training data in llms: A neuron activation-based detection framework
Hongyi Tang, Zhihao Zhu, and Yi Yang. Identifying pre-training data in llms: A neuron activation-based detection framework. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18738–18751, 2025
work page 2025
-
[12]
Jinhua Yin, Peiru Yang, Chen Yang, Huili Wang, Zhiyang Hu, Shangguang Wang, Yongfeng Huang, and Tao Qi. Black-box membership inference attack for lvlms via prior knowledge- calibrated memory probing.arXiv preprint arXiv:2511.01952, 2025
-
[13]
Yutong Xie, Lin Gu, Tatsuya Harada, Jianpeng Zhang, Yong Xia, and Qi Wu. Rethinking masked image modelling for medical image representation.Medical Image Analysis, 98:103304, 2024
work page 2024
-
[14]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[15]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: En- hancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Zhan Li, Yongtao Wu, Yihang Chen, Francesco Tonin, Elias Abad Rocamora, and V olkan Cevher. Membership inference attacks against large vision-language models.Advances in Neural Information Processing Systems, 37:98645–98674, 2024
work page 2024
-
[18]
Hongsheng Hu, Zoran Salcic, Lichao Sun, Gillian Dobbie, Philip S Yu, and Xuyun Zhang. Membership inference attacks on machine learning: A survey.ACM Computing Surveys (CSUR), 54(11s):1–37, 2022
work page 2022
-
[19]
Ahmed Salem, Yang Zhang, Mathias Humbert, Pascal Berrang, Mario Fritz, and Michael Backes. Ml-leaks: Model and data independent membership inference attacks and defenses on machine learning models.arXiv preprint arXiv:1806.01246, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Luis Ibanez-Lissen, Lorena Gonzalez-Manzano, Jose Maria de Fuentes, Nicolas Anciaux, and Joaquin Garcia-Alfaro. Lumia: Linear probing for unimodal and multimodal membership inference attacks leveraging internal llm states. InEuropean Symposium on Research in Computer Security, pages 186–206. Springer, 2025
work page 2025
-
[21]
Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841, 2024
Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettle- moyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do membership inference attacks work on large language models?arXiv preprint arXiv:2402.07841, 2024
-
[22]
Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models.arXiv preprint arXiv:2310.16789, 2023
-
[23]
Image corruption-inspired membership inference attacks against large vision-language models
Zongyu Wu, Minhua Lin, Zhiwei Zhang, Fali Wang, Xianren Zhang, Xiang Zhang, and Suhang Wang. Image corruption-inspired membership inference attacks against large vision-language models. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7945–7957, 2026
work page 2026
-
[24]
Disha Makhija, Manoj Ghuhan Arivazhagan, Vinayshekhar Bannihatti Kumar, and Rashmi Gangadharaiah. Neural breadcrumbs: Membership inference attacks on llms through hidden state and attention pattern analysis. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5608–5620, 2026
work page 2026
-
[25]
Embedding attack project (work report).arXiv preprint arXiv:2401.13854, 2024
Jiameng Pu and Zafar Takhirov. Embedding attack project (work report).arXiv preprint arXiv:2401.13854, 2024
-
[26]
Systematic evaluation of privacy risks of machine learning models
Liwei Song and Prateek Mittal. Systematic evaluation of privacy risks of machine learning models. In30th USENIX security symposium (USENIX security 21), pages 2615–2632, 2021. 11
work page 2021
-
[27]
Yigitcan Kaya and Tudor Dumitras. When does data augmentation help with membership inference attacks? InInternational conference on machine learning, pages 5345–5355. PMLR, 2021
work page 2021
-
[28]
Pretraining data detection for large language models: A divergence-based calibration method
Weichao Zhang, Ruqing Zhang, Jiafeng Guo, Maarten de Rijke, Yixing Fan, and Xueqi Cheng. Pretraining data detection for large language models: A divergence-based calibration method. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5263–5274, 2024
work page 2024
-
[29]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[30]
Minigpt-4: En- hancing vision-language understanding with advanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: En- hancing vision-language understanding with advanced large language models. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[31]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[33]
Avi Schwarzschild, Zhili Feng, Pratyush Maini, Zachary Lipton, and J Zico Kolter. Rethinking llm memorization through the lens of adversarial compression.Advances in Neural Information Processing Systems, 37:56244–56267, 2024
work page 2024
-
[34]
Ronald J Williams. Simple statistical gradient-following algorithms for connectionist reinforce- ment learning.Machine learning, 8(3):229–256, 1992
work page 1992
-
[35]
Michael Duan, Anshuman Suri, Niloofar Mireshghallah, Sewon Min, Weijia Shi, Luke Zettle- moyer, Yulia Tsvetkov, Yejin Choi, David Evans, and Hannaneh Hajishirzi. Do membership inference attacks work on large language models? InFirst Conference on Language Modeling
-
[36]
Pmc-clip: Contrastive language-image pre-training using biomedical documents
Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-clip: Contrastive language-image pre-training using biomedical documents. In International Conference on Medical Image Computing and Computer-Assisted Intervention, pages 525–536. Springer, 2023
work page 2023
-
[37]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36: 28541–28564, 2023
work page 2023
-
[38]
Contextual-based image inpainting: Infer, match, and translate
Yuhang Song, Chao Yang, Zhe Lin, Xiaofeng Liu, Qin Huang, Hao Li, and C-C Jay Kuo. Contextual-based image inpainting: Infer, match, and translate. InProceedings of the European conference on computer vision (ECCV), pages 3–19, 2018
work page 2018
-
[39]
From complexity to perplexity.Scientific American, 272(6):104–109, 1995
John Horgan. From complexity to perplexity.Scientific American, 272(6):104–109, 1995
work page 1995
-
[40]
Hongbin Liu, Jinyuan Jia, Wenjie Qu, and Neil Zhenqiang Gong. Encodermi: Membership inference against pre-trained encoders in contrastive learning. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, pages 2081–2095, 2021. 12 Algorithm 1Semantic Distractor Configuration Search Require: Target VLM f, calibration pool C,...
work page 2021
-
[41]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.