Recognition: no theorem link
Are Compact Rationales Free? Measuring Tile Selection Headroom in Frozen WSI-MIL
Pith reviewed 2026-05-14 20:35 UTC · model grok-4.3
The pith
FOCI reveals that compact rationales for frozen WSI-MIL predictions depend on the choice of backbone aggregator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across three WSI benchmarks and seven MIL backbones, FOCI shows that compact rationales are selection-headroom dependent: transformer and multi-branch attention aggregators can admit compact rationales, near-minimal attention-pooling baselines enter a selection-saturation regime, and hard-selection backbones can conflict with an external readout. For TransMIL, FOCI reduces the Minimum Sufficient K tile count by 32-56% relative to CLS-proxy ranking, and ACMIL+FOCI attains the highest mean SHI of +0.465.
What carries the argument
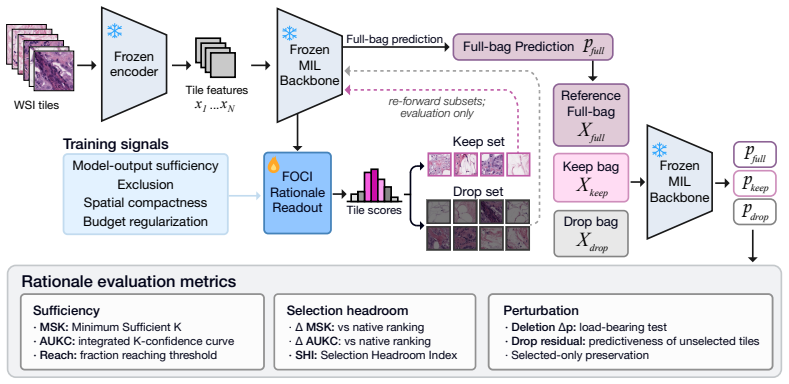
FOCI, a lightweight rationale-readout layer trained over a frozen MIL backbone with model-output sufficiency and exclusion objectives on keep/drop tile subsets.
Load-bearing premise
That the sufficiency and exclusion objectives produce tile subsets that are genuinely sufficient for the original model without introducing readout artifacts.
What would settle it
A direct test showing that, for a backbone with high reported SHI, the FOCI-selected minimal tiles fail to match the full-slide prediction accuracy while random same-sized subsets succeed.
Figures





read the original abstract
Whole-slide image (WSI) multiple instance learning (MIL) classifiers can achieve strong slide-level AUC while leaving the full-bag prediction opaque. Attention scores are widely reused as post-hoc explanations, but high attention can reflect aggregation preference rather than a compact, model-sufficient rationale. We study post-hoc rationale highlighting for frozen WSI-MIL: given a trained classifier, can its slide-level prediction be recovered from a compact, output-consistent tile subset without retraining the backbone? We instantiate this with Finding Optimal Contextual Instances (FOCI), a lightweight rationale-readout layer over a frozen MIL backbone. FOCI is trained with model-output sufficiency and exclusion objectives over keep/drop tile subsets, evaluated with an insertion-style Sequential Reveal Protocol (SRP) adapted to WSI-MIL, and summarized by the Selection Headroom Index (SHI). Across three WSI benchmarks and seven MIL backbones, FOCI reveals that compact rationales are selection-headroom dependent: transformer and multi-branch attention aggregators can admit compact rationales, near-minimal attention-pooling baselines enter a selection-saturation regime, and hard-selection backbones can conflict with an external readout. For TransMIL, relative to its documented CLS-proxy ranking, FOCI reduces the Minimum Sufficient K (MSK) tile count by 32-56% across benchmarks, while ACMIL+FOCI attains the highest mean SHI (+0.465). Deletion-based perturbation and selected-only downstream evaluation provide complementary checks. These results position FOCI as a model-level interpretability and audit layer: selected tiles are not claims of clinical or pathologist-level diagnostic sufficiency, but candidate rationales that offer a compact, reviewable view of when a frozen MIL prediction can be localized to a small output-consistent subset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FOCI, a lightweight rationale-readout layer trained on frozen WSI-MIL backbones using sufficiency and exclusion objectives over keep/drop tile subsets. It evaluates these via an adapted Sequential Reveal Protocol (SRP) and the Selection Headroom Index (SHI) across three benchmarks and seven MIL architectures, claiming architecture-dependent selection headroom: transformers admit compact rationales (e.g., 32-56% MSK reduction for TransMIL vs. CLS-proxy), attention-pooling baselines saturate, and hard-selection models conflict with external readouts, with ACMIL+FOCI yielding the highest mean SHI (+0.465). Complementary deletion perturbations and selected-only downstream checks are included.
Significance. If the central claims hold, this provides a practical model-level interpretability and audit tool for WSI-MIL, quantifying when slide-level predictions can be recovered from compact, output-consistent tile subsets without retraining. The multi-backbone, multi-benchmark scope plus deletion and downstream checks constitute a strength, offering a falsifiable protocol for distinguishing architectures by inherent selection headroom in computational pathology.
major comments (2)
- [FOCI training procedure (Section 3) and SRP evaluation (Section 4)] FOCI training procedure (Section 3) and SRP evaluation (Section 4): the joint optimization of FOCI on the exact keep/drop subsets later used in SRP creates a risk that MSK reductions (32-56% for TransMIL) and SHI gains (+0.465 for ACMIL) partly reflect objective-induced biases rather than intrinsic backbone headroom. While deletion checks and selected-only evaluation are noted as mitigations, no dedicated ablation on sensitivity to the keep/drop training procedure is reported; this is load-bearing for the architecture-dependent claim.
- [Experimental results (Section 5)] Experimental results (Section 5): the manuscript reports specific quantitative improvements (e.g., 32-56% MSK reductions, +0.465 SHI) but provides no details on statistical testing, error bars across runs, or sensitivity to FOCI hyperparameters and random seeds. This weakens confidence in the cross-architecture comparisons given the empirical protocol.
minor comments (2)
- [Abstract] Abstract: the three WSI benchmarks are referenced but not named; specifying them (e.g., CAMELYON16, TCGA-LUAD) would improve immediate readability.
- [Notation and definitions (Section 2-3)] Notation and definitions: SHI, MSK, and the precise formulation of the sufficiency/exclusion losses would benefit from an explicit notation table or expanded initial presentation to aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review, as well as the positive assessment of the work's significance. We address each major comment point-by-point below, with clarifications on the design choices and revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [FOCI training procedure (Section 3) and SRP evaluation (Section 4)] FOCI training procedure (Section 3) and SRP evaluation (Section 4): the joint optimization of FOCI on the exact keep/drop subsets later used in SRP creates a risk that MSK reductions (32-56% for TransMIL) and SHI gains (+0.465 for ACMIL) partly reflect objective-induced biases rather than intrinsic backbone headroom. While deletion checks and selected-only evaluation are noted as mitigations, no dedicated ablation on sensitivity to the keep/drop training procedure is reported; this is load-bearing for the architecture-dependent claim.
Authors: We appreciate the referee highlighting this potential circularity. The joint use of keep/drop subsets is by design: FOCI optimizes a readout to recover the frozen backbone's output from minimal sufficient subsets (sufficiency objective) while penalizing reliance on excluded tiles (exclusion objective), directly quantifying selection headroom. SRP then evaluates the resulting minimal K in an insertion-style protocol. The reported MSK reductions and SHI values thus measure how compactly each backbone's decision can be localized, rather than claiming independence from the readout. Deletion perturbations and selected-only downstream checks were included precisely as orthogonal validations that the subsets remain predictive outside the training distribution. Nevertheless, to further isolate any sensitivity, we have added a dedicated ablation in the revised Section 5 varying keep/drop sampling ratios, loss weighting, and subset generation strategies; the relative architecture ordering by SHI is preserved, supporting that the headroom differences are backbone-intrinsic. revision: yes
-
Referee: [Experimental results (Section 5)] Experimental results (Section 5): the manuscript reports specific quantitative improvements (e.g., 32-56% MSK reductions, +0.465 SHI) but provides no details on statistical testing, error bars across runs, or sensitivity to FOCI hyperparameters and random seeds. This weakens confidence in the cross-architecture comparisons given the empirical protocol.
Authors: We agree that explicit variability and statistical reporting are necessary to support the cross-architecture claims. The original manuscript focused on mean trends across benchmarks but omitted these details. In the revised version, we now report standard deviations over five independent random seeds for FOCI training, SRP evaluation, and hyperparameter sweeps (including sufficiency/exclusion loss coefficients and subset sampling temperature). We additionally include paired t-test p-values for key SHI and MSK differences between architectures, confirming statistical significance of the reported gaps (e.g., TransMIL vs. attention-pooling baselines). These additions appear in the updated Section 5 and supplementary material. revision: yes
Circularity Check
Empirical protocol with new objectives exhibits no reduction by construction
full rationale
The paper defines FOCI as a new lightweight readout trained on sufficiency/exclusion objectives over keep/drop subsets and evaluates via the newly introduced SRP and SHI metrics. No equations, self-citations, or claims reduce the reported MSK reductions (32-56%) or SHI gains (+0.465) to quantities that are tautologically equivalent to the training inputs. Complementary deletion checks and selected-only evaluation are presented as independent verifications. This is a standard empirical measurement setup on frozen backbones; the central claims about architecture-dependent headroom rest on observable performance differences rather than definitional loops or fitted-input predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hanna, Luke Geneslaw, Allen Miraflor, Vitor Werneck Krauss Silva, Klaus J
Gabriele Campanella, Matthew G. Hanna, Luke Geneslaw, Allen Miraflor, Vitor Werneck Krauss Silva, Klaus J. Busam, Edi Brogi, Victor E. Reuter, David S. Klimstra, and Thomas J. Fuchs. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature Medicine, 25(8):1301–1309, 2019
work page 2019
-
[2]
Attention-based deep multiple instance learning
Maximilian Ilse, Jakub Tomczak, and Max Welling. Attention-based deep multiple instance learning. In Proceedings of the 35th International Conference on Machine Learning, pages 2127–2136. PMLR, 2018
work page 2018
-
[3]
Ming Y Lu, Drew FK Williamson, Tiffany Y Chen, Richard J Chen, Matteo Barbieri, and Faisal Mahmood. Data-efficient and weakly supervised computational pathology on whole-slide images.Nature biomedical engineering, 5(6):555–570, 2021
work page 2021
-
[4]
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Andrew H Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, et al. Towards a general-purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
work page 2024
-
[5]
Deep learning for whole slide image analysis: an overview.Frontiers in medicine, 6:264, 2019
Neofytos Dimitriou, Ognjen Arandjelovi´c, and Peter D Caie. Deep learning for whole slide image analysis: an overview.Frontiers in medicine, 6:264, 2019
work page 2019
-
[6]
Michael Gadermayr and Maximilian Tschuchnig. Multiple instance learning for digital pathology: A review of the state-of-the-art, limitations & future potential.Computerized Medical Imaging and Graphics, 112:102337, 2024
work page 2024
-
[7]
Sofia Serrano and Noah A. Smith. Is attention interpretable? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2931–2951, Florence, Italy, July 2019. Association for Computational Linguistics
work page 2019
-
[8]
Danish Pruthi, Mansi Gupta, Bhuwan Dhingra, Graham Neubig, and Zachary C. Lipton. Learning to deceive with attention-based explanations. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4782–4793. Association for Computational Linguistics, July 2020
work page 2020
-
[9]
Martim Afonso, Praphulla MS Bhawsar, Monjoy Saha, Jonas S Almeida, and Arlindo L Oliveira. Multiple instance learning for wsi: A comparative analysis of attention-based approaches.Journal of Pathology Informatics, 15:100403, 2024
work page 2024
-
[10]
Interpretability of deep learning models: A survey of results
Supriyo Chakraborty, Richard Tomsett, Ramya Raghavendra, Daniel Harborne, Moustafa Alzantot, Fed- erico Cerutti, Mani Srivastava, Alun Preece, Simon Julier, Raghuveer M Rao, et al. Interpretability of deep learning models: A survey of results. In2017 IEEE smartworld, ubiquitous intelligence & computing, advanced & trusted computed, scalable computing & co...
work page 2017
-
[11]
Wenhui Zhu, Peijie Qiu, Xiwen Chen, Zhangsihao Yang, Aristeidis Sotiras, Abolfazl Razi, and Yalin Wang. How effective can dropout be in multiple instance learning ? InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[12]
The cancer genome atlas pan-cancer analysis project
John N Weinstein, Eric A Collisson, Gordon B Mills, Kenna R Shaw, Brad A Ozenberger, Kyle Ellrott, Ilya Shmulevich, Chris Sander, and Joshua M Stuart. The cancer genome atlas pan-cancer analysis project. Nature genetics, 45(10):1113–1120, 2013
work page 2013
-
[13]
Wouter Bulten, Kimmo Kartasalo, Po-Hsuan Cameron Chen, Peter Ström, Hans Pinckaers, Kunal Nagpal, Yuannan Cai, David F Steiner, Hester Van Boven, Robert Vink, et al. Artificial intelligence for diagnosis and gleason grading of prostate cancer: the panda challenge.Nature medicine, 28(1):154–163, 2022
work page 2022
-
[14]
Thomas G. Dietterich, Richard H. Lathrop, and Tomás Lozano-Pérez. Solving the multiple instance problem with axis-parallel rectangles.Artificial Intelligence, 89(1):31–71, 1997
work page 1997
-
[15]
Zhuchen Shao, Hao Bian, Yang Chen, Yifeng Wang, Jian Zhang, Xiangyang Ji, and Yongbing Zhang. Transmil: Transformer based correlated multiple instance learning for whole slide image classification. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 213...
work page 2021
-
[16]
Chen, Chengkuan Chen, Yicong Li, Tiffany Y
Richard J. Chen, Chengkuan Chen, Yicong Li, Tiffany Y . Chen, Andrew D. Trister, Rahul G. Krishnan, and Faisal Mahmood. Scaling vision transformers to gigapixel images via hierarchical self-supervised learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16144–16155, June 2022. 10
work page 2022
-
[17]
Wenhao Tang, Sheng Huang, Xiaoxian Zhang, Fengtao Zhou, Yi Zhang, and Bo Liu. Multiple instance learning framework with masked hard instance mining for whole slide image classification. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4078–4087, October 2023
work page 2023
-
[18]
Linghan Cai, Shenjin Huang, Ye Zhang, Jinpeng Lu, and Yongbing Zhang. Attrimil: Revisiting attention- based multiple instance learning for whole-slide pathological image classification from a perspective of instance attributes.Medical Image Analysis, 103:103631, 2025
work page 2025
-
[19]
Attention- challenging multiple instance learning for whole slide image classification
Yunlong Zhang, Honglin Li, Yunxuan Sun, Sunyi Zheng, Chenglu Zhu, and Lin Yang. Attention- challenging multiple instance learning for whole slide image classification. InEuropean conference on computer vision, pages 125–143. Springer, 2024
work page 2024
-
[20]
Ming Y . Lu, Bowen Chen, Drew F. K. Williamson, Richard J. Chen, Ivy Liang, Tong Ding, Guillaume Jaume, Igor Odintsov, Long Phi Le, Georg Gerber, Anil V . Parwani, Andrew Zhang, and Faisal Mahmood. A visual-language foundation model for computational pathology.Nature Medicine, 30(3):863–874, 2024
work page 2024
-
[21]
Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Sheng Wang, and Hoifung Poon
Hanwen Xu, Naoto Usuyama, Jaspreet Bagga, Sheng Zhang, Rajesh Rao, Tristan Naumann, Cliff Wong, Zelalem Gero, Javier González, Yu Gu, Yanbo Xu, Mu Wei, Wenhui Wang, Shuming Ma, Furu Wei, Jianwei Yang, Chunyuan Li, Jianfeng Gao, Jaylen Rosemon, Tucker Bower, Soohee Lee, Roshanthi Weerasinghe, Bill J. Wright, Ari Robicsek, Brian Piening, Carlo Bifulco, Shen...
work page 2024
-
[22]
Hongyi Wang, Luyang Luo, Fang Wang, Ruofeng Tong, Yen-Wei Chen, Hongjie Hu, Lanfen Lin, and Hao Chen. Rethinking multiple instance learning for whole slide image classification: A bag-level classifier is a good instance-level teacher.IEEE Transactions on Medical Imaging, 43(11):3964–3976, 2024
work page 2024
-
[23]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5338–5348. PMLR, 2020
work page 2020
-
[24]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017
work page 2017
-
[25]
Additive MIL: Intrinsically interpretable multiple instance learning for pathology
Syed Ashar Javed, Dinkar Juyal, Harshith Padigela, Amaro Taylor-Weiner, Limin Yu, and aaditya prakash. Additive MIL: Intrinsically interpretable multiple instance learning for pathology. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors,Advances in Neural Information Processing Systems, 2022
work page 2022
-
[26]
Saarthak Kapse, Pushpak Pati, Srijan Das, Jingwei Zhang, Chao Chen, Maria Vakalopoulou, Joel Saltz, Dimitris Samaras, Rajarsi R. Gupta, and Prateek Prasanna. SI-MIL: Taming deep MIL for self- interpretability in gigapixel histopathology. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11226–11237, 2024
work page 2024
-
[27]
Wojciech Samek, Alexander Binder, Grégoire Montavon, Sebastian Lapuschkin, and Klaus-Robert Müller. Evaluating the visualization of what a deep neural network has learned.IEEE Transactions on Neural Networks and Learning Systems, 28(11):2660–2673, 2017
work page 2017
-
[28]
xMIL: Insightful explanations for multiple instance learning in histopathology
Julius Hense, Mina Jamshidi Idaji, Oliver Eberle, Thomas Schnake, Jonas Dippel, Laure Ciernik, Oliver Buchstab, Andreas Mock, Frederick Klauschen, and Klaus Robert Müller. xMIL: Insightful explanations for multiple instance learning in histopathology. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
- [29]
-
[30]
Rationalizing neural predictions
Tao Lei, Regina Barzilay, and Tommi Jaakkola. Rationalizing neural predictions. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 107–117, Austin, Texas, November 2016. Association for Computational Linguistics
work page 2016
-
[31]
Interpretable neural predictions with differentiable binary variables
Jasmijn Bastings, Wilker Aziz, and Ivan Titov. Interpretable neural predictions with differentiable binary variables. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2963–2977, Florence, Italy, July 2019. Association for Computational Linguistics
work page 2019
-
[32]
Boosting explainability through selective rationalization in pre-trained language models
Libing Yuan, Shuaibo Hu, Kui Yu, and Le Wu. Boosting explainability through selective rationalization in pre-trained language models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .1, page 1867–1878, 2025. 11
work page 2025
-
[33]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[34]
Surat Teerapittayanon, Bradley McDanel, and H. T. Kung. BranchyNet: Fast inference via early exiting from deep neural networks. In2016 23rd International Conference on Pattern Recognition (ICPR), pages 2464–2469. IEEE, 2016
work page 2016
-
[35]
Rethinking cooperative rationalization: Introspec- tive extraction and complement control
Mo Yu, Shiyu Chang, Yang Zhang, and Tommi Jaakkola. Rethinking cooperative rationalization: Introspec- tive extraction and complement control. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 4094–4103, Hong Kong, China, ...
work page 2019
-
[36]
Estimating or propagating gradients through stochastic neurons for conditional computation, 2013
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation, 2013
work page 2013
-
[37]
Linfeng Ye, Shayan Mohajer Hamidi, Zhixiang Chi, Guang Li, Mert Pilanci, Takahiro Ogawa, Miki Haseyama, and Konstantinos N. Plataniotis. ASMIL: Attention-stabilized multiple instance learning for whole-slide imaging. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[38]
Reamil: Reasoning- and evidence-aware multiple instance learning for whole-slide histopathology
Hyun Do Jung, Jungwon Choi, and Hwiyoung Kim. Reamil: Reasoning- and evidence-aware multiple instance learning for whole-slide histopathology. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, pages 40–45, March 2026
work page 2026
-
[39]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. InInternational Conference on Learning Representations, 2017
work page 2017
-
[40]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In International Conference on Learning Representations, 2017
work page 2017
-
[41]
Vitali Petsiuk, Abir Das, and Kate Saenko. RISE: Randomized input sampling for explanation of black-box models. InBritish Machine Vision Conference (BMVC), 2018. A Qualitative Illustration This appendix shows where FOCI-selected tiles appear, in WSI context, relative to two attention/selection baselines on the same input bag. The figure is illustrative an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.