Recognition: 2 theorem links
· Lean TheoremAction Emergence from Streaming Intent
Pith reviewed 2026-05-15 05:09 UTC · model grok-4.3
The pith
Streaming Intent lets an end-to-end driving model generate distinct, high-quality trajectories by deriving and steering with reasoned intent classes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
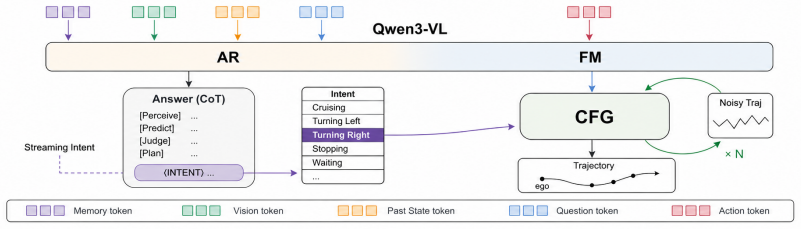
Streaming Intent is realized by autoregressively decoding a four-step chain-of-thought that causally derives an intent token from scene understanding; this token then conditions classifier-free guidance on a flow-matching action head that produces the final trajectory in two denoising steps. The mechanism keeps intent coherent both semantically across the reasoning steps and temporally across driving clips, enabling the model to output physically feasible, safety-compliant plans that vary qualitatively with the supplied intent class for any fixed scene.
What carries the argument
Streaming Intent, a dual-stream mechanism that derives intent tokens via autoregressive chain-of-thought from scene understanding and propagates them temporally across clips to steer a flow-matching action generator.
If this is right
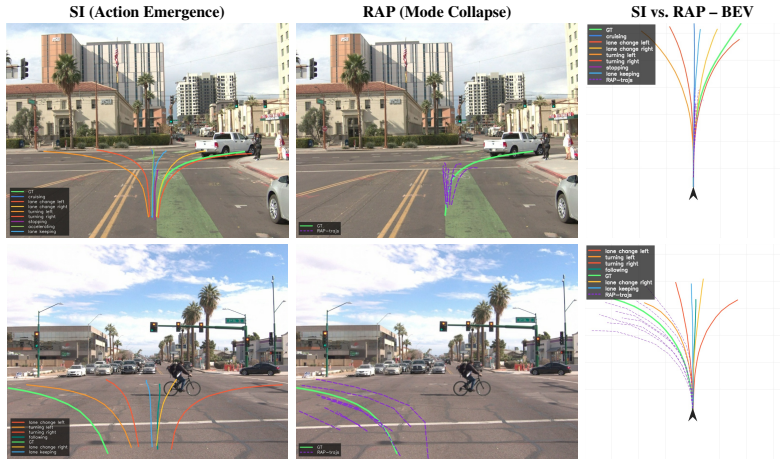
- For any fixed scene, changing the intent class at inference time yields qualitatively distinct yet high-quality trajectories without a pre-built bank or post-hoc selector.
- The flow-matching head requires only two denoising steps once conditioned by the intent token.
- Aggregate RFS scores reach 7.96 on Waymo validation and 7.74 on the test set.
- Action emergence becomes possible in arbitrary long-tail scenes through data-driven learning rather than interpolation of stored mappings.
Where Pith is reading between the lines
- The same streaming-intent structure could be tested on other embodied control tasks that require high-level specification without hand-engineered planners.
- If the chain-of-thought step generalizes, intent classes could serve as a lightweight interface for human overrides or safety overrides in deployed vehicles.
- Performance in rare long-tail scenes would be directly measurable by holding out specific traffic configurations and checking whether intent variation still produces appropriate plans.
Load-bearing premise
The autoregressive chain-of-thought step reliably extracts a semantically correct intent from the scene that then steers the action head into appropriate behavior.
What would settle it
In a fixed scene, supplying different intent classes produces trajectories that show no consistent qualitative differences matching the intent labels, or the trajectories violate safety or feasibility in long-tail traffic configurations.
Figures




read the original abstract
We formalize action emergence as a target capability for end-to-end autonomous driving: the ability to generate physically feasible, semantically appropriate, and safety-compliant actions in arbitrary, long-tail traffic scenes through scene-conditioned reasoning rather than retrieval or interpolation of learned scene-action mappings. We show that previous paradigms cannot deliver action emergence: autoregressive trajectory decoders collapse the inherently multimodal future into a single averaged output, while diffusion and flow-matching generators express multimodality but are not steerable by reasoned intent. We propose Streaming Intent as a concrete way to approach action emergence: a mechanism that makes driving intent (i) semantically streamed through a continuous chain-of-thought that causally derives the intent from scene understanding, and (ii) temporally streamed across clips so that intent commitments remain coherent along the driving horizon. We realize Streaming Intent in a VLA model we call SI (Streaming Intent). SI autoregressively decodes a four-step chain-of-thought and emits an intent token; the decoded intent then drives classifier-free guidance (CFG) on a flow-matching action head, requiring only two denoising steps to generate the final trajectory. On the Waymo End-to-End benchmark, SI achieves competitive aggregate performance, with an RFS score of 7.96 on the validation set and 7.74 on the test set. Beyond aggregate metrics, the model demonstrates -- to our knowledge for the first time in a fully end-to-end VLA -- intent-faithful controllability: for a fixed scene, varying the intent class at inference yields qualitatively distinct yet consistently high-quality plans, arising purely from data-driven learning without any pre-built trajectory bank or hand-coded post-hoc selector.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes action emergence for end-to-end autonomous driving and proposes Streaming Intent (SI), a VLA that autoregressively decodes a four-step chain-of-thought to produce an intent token; this token then conditions classifier-free guidance on a flow-matching action head (two denoising steps) to generate trajectories. It reports competitive RFS scores (7.96 validation, 7.74 test) on the Waymo End-to-End benchmark and claims, for the first time in a fully end-to-end VLA, intent-faithful controllability arising purely from data-driven learning without trajectory banks or hand-coded selectors.
Significance. If the causal link between the CoT-derived intent token and the observed controllability holds, the work would advance steerable multimodal planning in VLAs by addressing the averaging problem of autoregressive decoders and the lack of semantic steerability in diffusion/flow models. The data-driven formulation without pre-built components is a clear strength; however, the central controllability claim currently rests on unverified assumptions about the CoT's semantic fidelity.
major comments (2)
- [Abstract] Abstract and model description: the headline claim that four-step autoregressive CoT causally derives semantically appropriate intent (which then steers CFG to produce distinct high-quality plans) is load-bearing for the 'first time' controllability result, yet no ablation is reported that decouples the CoT output from the CFG mechanism or tests CoT semantic fidelity on long-tail scenes where scene understanding is uncertain; without this, controllability could be driven primarily by CFG rather than reasoned intent.
- [Experimental results] Experimental results: the reported RFS scores are aggregate and competitive, but the manuscript provides no per-scene breakdown, ablation on CoT step count, or verification that varying intent class at inference produces plans whose semantic distinctions are attributable to the CoT rather than the flow head alone.
minor comments (1)
- [Abstract] The 'to our knowledge for the first time' assertion would benefit from a more explicit comparison table against prior VLA and diffusion-based driving works to substantiate the novelty claim.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address the major concerns regarding the controllability claims and experimental validation below, and we commit to incorporating additional analyses in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract and model description: the headline claim that four-step autoregressive CoT causally derives semantically appropriate intent (which then steers CFG to produce distinct high-quality plans) is load-bearing for the 'first time' controllability result, yet no ablation is reported that decouples the CoT output from the CFG mechanism or tests CoT semantic fidelity on long-tail scenes where scene understanding is uncertain; without this, controllability could be driven primarily by CFG rather than reasoned intent.
Authors: We agree that demonstrating the causal contribution of the CoT-derived intent token is crucial for substantiating our claims. In the revised manuscript, we will add an ablation that decouples the CoT by using a non-reasoned intent token (e.g., derived from a direct classifier without the four-step chain) and show that this leads to diminished controllability and less semantically appropriate plans. We will also include an evaluation of CoT semantic fidelity on long-tail scenes by comparing the generated intent tokens against expert annotations for a set of challenging scenarios. This will clarify that the controllability arises from the reasoned intent rather than solely from the CFG mechanism. revision: yes
-
Referee: [Experimental results] Experimental results: the reported RFS scores are aggregate and competitive, but the manuscript provides no per-scene breakdown, ablation on CoT step count, or verification that varying intent class at inference produces plans whose semantic distinctions are attributable to the CoT rather than the flow head alone.
Authors: We acknowledge the value of more granular analysis. The revised version will include per-scene breakdowns for a selection of representative and long-tail scenes, highlighting variations in RFS and plan quality. We will also report an ablation on the CoT step count (comparing 2-step, 3-step, and 4-step variants) and its effect on overall performance and controllability. To verify attribution to the CoT, we will add quantitative verification, such as measuring the alignment between varied intent classes and the resulting plan semantics (e.g., via trajectory clustering or intent prediction accuracy from the generated plans), along with qualitative examples showing distinct behaviors like lane changes versus yielding. revision: yes
Circularity Check
No circularity: empirical controllability claim does not reduce to inputs by construction
full rationale
The paper presents Streaming Intent as an architectural mechanism (4-step autoregressive CoT producing an intent token that conditions CFG on a 2-step flow-matching head) and reports empirical results on Waymo benchmarks as evidence of intent-faithful controllability arising from data-driven learning. No equations, fitted parameters, or self-citations are shown that would make the output equivalent to the input by definition. The claim that controllability emerges without pre-built banks or hand-coded selectors is an empirical assertion about the trained model rather than a derivation that collapses to its own assumptions. Standard benchmark metrics and architectural descriptions do not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- CoT steps =
4
- denoising steps =
2
axioms (2)
- domain assumption Classifier-free guidance can steer the flow-matching action head using intent tokens
- domain assumption The chain-of-thought produces intent that is semantically streamed from scene understanding
invented entities (1)
-
Streaming Intent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SI autoregressively decodes a four-step chain-of-thought and emits an intent token; the decoded intent then drives classifier-free guidance (CFG) on a flow-matching action head
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
intent-faithful controllability arising purely from data-driven learning, without any pre-built trajectory bank
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[2]
Transactions on Machine Learning Research , year =
Emergent Abilities of Large Language Models , author =. Transactions on Machine Learning Research , year =
-
[3]
Xu, Runsheng and Lin, Hubert and Jeon, Wonseok and Feng, Hao and Zou, Yuliang and Sun, Liting and Gorman, John and Tolstaya, Ekaterina and Tang, Sarah and White, Brandyn and Sapp, Ben and Tan, Mingxing and Hwang, Jyh-Jing and Anguelov, Dragomir , year =. 2510.26125 , archivePrefix =
-
[4]
Zhou, Zewei and Cai, Tianhui and Zhao, Seth Z. and Zhang, Yun and Huang, Zhiyu and Zhou, Bolei and Ma, Jiaqi , year =. 2506.13757 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2506.11234 , year =
Poutine: Vision-Language-Trajectory Pre-Training and Reinforcement Learning Post-Training Enable Robust End-to-End Autonomous Driving , author =. arXiv preprint arXiv:2506.11234 , year =
-
[6]
Luo, Yuechen and Li, Fang and Xu, Shaoqing and Lai, Zhiyi and Yang, Lei and Chen, Qimao and Luo, Ziang and Xie, Zixun and Jiang, Shengyin and Liu, Jiaxin and Chen, Long and Wang, Bing and Yang, Zhi-xin , year =. 2509.13769 , archivePrefix =
-
[7]
Devil is in Narrow Policy: Unleashing Exploration in Driving
Chen, Canyu and Yang, Yuguang and Tan, Zhewen and Wang, Yizhi and Zhan, Ruiyi and Liu, Haiyan and Mao, Xuanyao and Bao, Jason and Tang, Xinyue and Yang, Linlin and Sun, Bingchuan and Wang, Yan and Zhang, Baochang , year =. Devil is in Narrow Policy: Unleashing Exploration in Driving. 2603.06049 , archivePrefix =
-
[8]
and Liu, Yu and Li, Hongsheng , booktitle =
Shao, Hao and Hu, Yuxuan and Wang, Letian and Song, Guanglu and Waslander, Steven L. and Liu, Yu and Li, Hongsheng , booktitle =
-
[9]
Tian, Xiaoyu and Gu, Junru and Li, Bailin and Liu, Yicheng and Wang, Yang and Zhao, Zhiyong and Zhan, Kun and Jia, Peng and Lang, Xianpeng and Zhao, Hang , journal =
-
[10]
Jiang, Bo and Chen, Shaoyu and Liao, Bencheng and Zhang, Xingyu and Yin, Wei and Zhang, Qian and Huang, Chang and Liu, Wenyu and Wang, Xinggang , journal =
-
[11]
European Conference on Computer Vision , pages =
Sima, Chonghao and Renz, Katrin and Chitta, Kashyap and Chen, Li and Zhang, Hanxue and Xie, Chengen and Bei. European Conference on Computer Vision , pages =. 2024 , organization =
work page 2024
-
[12]
Hwang, Jyh-Jing and Xu, Runsheng and Lin, Hubert and Hung, Wei-Chih and Ji, Jingwei and Choi, Kristy and Huang, Di and He, Tong and Covington, Paul and Sapp, Benjamin and others , journal =
-
[13]
Wang, Shihao and Yu, Zhiding and Jiang, Xiaohui and Lan, Shiyi and Shi, Min and Chang, Nadine and Kautz, Jan and Li, Ying and Alvarez, Jose M. , booktitle =
- [14]
-
[15]
Zeng, Shuang and Chang, Xinyuan and Xie, Mengwei and Liu, Xinran and Bai, Yifan and Pan, Zheng and Xu, Mu and Wei, Xing and Guo, Ning , journal =
-
[16]
Yuan, Zhenlong and Qian, Chengxuan and Tang, Jing and Chen, Rui and Song, Zijian and Sun, Lei and Chu, Xiangxiang and Cai, Yujun and Zhang, Dapeng and Li, Shuo , journal =
-
[17]
Renz, Katrin and Chen, Long and Arani, Elahe and Sinavski, Oleg , booktitle =
-
[18]
Li, Yingyan and Shang, Shuyao and Liu, Weisong and Zhan, Bing and Wang, Haochen and Wang, Yuqi and Chen, Yuntao and Wang, Xiaoman and An, Yasong and Tang, Chufeng and others , journal =
-
[19]
Wang, Yan and Luo, Wenjie and Bai, Junjie and Cao, Yulong and Che, Tong and Chen, Ke and Chen, Yuxiao and Diamond, Jenna and Ding, Yifan and Ding, Wenhao and others , journal =
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Planning-Oriented Autonomous Driving , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[21]
Jiang, Bo and Chen, Shaoyu and Xu, Qing and Liao, Bencheng and Chen, Jiajie and Zhou, Helong and Zhang, Qian and Liu, Wenyu and Huang, Chang and Wang, Xinggang , booktitle =
-
[22]
Chen, Shaoyu and Jiang, Bo and Gao, Hao and Liao, Bencheng and Xu, Qing and Zhang, Qian and Huang, Chang and Liu, Wenyu and Wang, Xinggang , journal =
-
[23]
Sun, Wenchao and Lin, Xuewu and Shi, Yining and Zhang, Chuang and Wu, Haoran and Zheng, Sifa , booktitle =. 2025 , organization =
work page 2025
-
[24]
Sun, Wenchao and Lin, Xuewu and Chen, Keyu and Pei, Zixiang and Li, Xiang and Shi, Yining and Zheng, Sifa , year =. 2603.29163 , archivePrefix =
-
[25]
Zheng, Wenzhao and Song, Ruiqi and Guo, Xianda and Zhang, Chenming and Chen, Long , booktitle =. 2024 , organization =
work page 2024
-
[26]
Weng, Xinshuo and Ivanovic, Boris and Wang, Yan and Wang, Yue and Pavone, Marco , booktitle =. 2024 , pages =
work page 2024
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving? , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[28]
Chitta, Kashyap and Prakash, Aditya and Jaeger, Bernhard and Yu, Zehao and Renz, Katrin and Geiger, Andreas , journal =. 2022 , publisher =
work page 2022
-
[29]
Feng, Lan and Gao, Yang and Zablocki, Eloi and Li, Quanyi and Li, Wuyang and Liu, Sichao and Cord, Matthieu and Alahi, Alexandre , journal =
-
[30]
Liao, Bencheng and Chen, Shaoyu and Yin, Haoran and Jiang, Bo and Wang, Cheng and Yan, Sixu and Zhang, Xinbang and Li, Xiangyu and Zhang, Ying and Zhang, Qian and others , booktitle =
-
[31]
Diffusion-Based Planning for Autonomous Driving with Flexible Guidance , author =. arXiv preprint arXiv:2501.15564 , year =
-
[32]
Xing, Zebin and Zhang, Xingyu and Hu, Yang and Jiang, Bo and He, Tong and Zhang, Qian and Long, Xiaoxiao and Yin, Wei , booktitle =
-
[33]
Xu, Yifang and Cui, Jiahao and Cai, Feipeng and Zhu, Zhihao and Shang, Hanlin and Luan, Shan and Xu, Mingwang and Zhang, Neng and Li, Yaoyi and Cai, Jia and Zhu, Siyu , year =. 2512.06112 , archivePrefix =
-
[34]
Li, Yongkang and Xiong, Kaixin and Guo, Xiangyu and Li, Fang and Yan, Sixu and Xu, Gangwei and Zhou, Lijun and Chen, Long and Sun, Haiyang and Wang, Bing and others , journal =
-
[35]
RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework
Gao, Hao and Chen, Shaoyu and Zhu, Yifan and Song, Yuehao and Liu, Wenyu and Zhang, Qian and Wang, Xinggang , year =. 2604.15308 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Chai, Yuning and Sapp, Benjamin and Bansal, Mayank and Anguelov, Dragomir , booktitle =
-
[37]
and Beijbom, Oscar and Wolff, Eric M
Phan-Minh, Tung and Grigore, Elena Corina and Boulton, Freddy A. and Beijbom, Oscar and Wolff, Eric M. , year =. 1911.10298 , archivePrefix =
-
[38]
Salzmann, Tim and Ivanovic, Boris and Chakravarty, Punarjay and Pavone, Marco , year =. 2001.03093 , archivePrefix =
-
[39]
Advances in Neural Information Processing Systems , year =
Motion Transformer with Global Intention Localization and Local Movement Refinement , author =. Advances in Neural Information Processing Systems , year =
-
[40]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan, Anthony and Brown, Noah and Carbajal, Justice and Chebotar, Yevgen and Chen, Xi and Choromanski, Krzysztof and Ding, Tianli and Driess, Danny and Dubey, Avinava and Finn, Chelsea and Florence, Pete and Fu, Chuyuan and Arenas, Montse Gonzalez and Gopalakrishnan, Keerthana and Han, Kehang and Hausman, Karol and Herzog, Alex and Hsu, Jasmine and Icht...
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, Moo Jin and Pertsch, Karl and Karamcheti, Siddharth and Xiao, Ted and Balakrishna, Ashwin and Nair, Suraj and Rafailov, Rafael and Foster, Ethan and Lam, Grace and Sanketi, Pannag and Vuong, Quan and Kollar, Thomas and Burchfiel, Benjamin and Tedrake, Russ and Sadigh, Dorsa and Levine, Sergey and Liang, Percy and Finn, Chelsea , year =. 2406.09246 , ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, Kevin and Brown, Noah and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and Groom, Lachy and Hausman, Karol and Ichter, Brian and Jakubczak, Szymon and Jones, Tim and Ke, Liyiming and Levine, Sergey and Li-Bell, Adrian and Mothukuri, Mohith and Nair, Suraj and Pertsch, Karl and Shi, Lucy Xiaoyang and Tanner,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Intelligence, Physical and Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael and Finn, Chelsea and Fusai, Niccolo and others , journal =
-
[44]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and others , journal =
-
[45]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and others , journal =
-
[46]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , year =. 2402.03300 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =
-
[48]
arXiv preprint arXiv:2411.04996 , year =
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models , author =. arXiv preprint arXiv:2411.04996 , year =
-
[49]
Emerging Properties in Unified Multimodal Pretraining
Emerging Properties in Unified Multimodal Pretraining , author =. arXiv preprint arXiv:2505.14683 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Advances in Neural Information Processing Systems , volume =
Denoising Diffusion Probabilistic Models , author =. Advances in Neural Information Processing Systems , volume =
- [51]
-
[52]
International Conference on Learning Representations , year =
Flow Matching for Generative Modeling , author =. International Conference on Learning Representations , year =
-
[53]
Forty-First International Conference on Machine Learning , year =
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author =. Forty-First International Conference on Machine Learning , year =
-
[54]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author =. arXiv preprint arXiv:2209.03003 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion , author =. 2023 , eprint =
work page 2023
- [56]
-
[57]
Alles, Marvin and Chen, Nutan and van der Smagt, Patrick and Cseke, Botond , year =. 2505.14139 , archivePrefix =
-
[58]
Zhang, Tonghe and Yu, Chao and Su, Sichang and Wang, Yu , year =. 2505.22094 , archivePrefix =
- [59]
-
[60]
Fine-Tuning Language Models from Human Preferences , author =. 2019 , eprint =
work page 2019
- [61]
-
[62]
Advances in Neural Information Processing Systems , year =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , year =
-
[63]
EFG: An Efficient, Flexible, and General deep learning framework that retains minimal , author=
-
[64]
arXiv preprint arXiv:2506.05883 , year=
HMVLM: Multistage reasoning-enhanced vision-language model for long-tailed driving scenarios , author=. arXiv preprint arXiv:2506.05883 , year=
-
[65]
arXiv preprint arXiv:2512.04459 , year=
dVLM-AD: Enhance diffusion vision-language-model for driving via controllable reasoning , author=. arXiv preprint arXiv:2512.04459 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.