Recognition: unknown
RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework
Pith reviewed 2026-05-10 11:37 UTC · model grok-4.3
The pith
A diffusion generator paired with an RL discriminator reranks trajectories to cut closed-loop collisions by 56 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
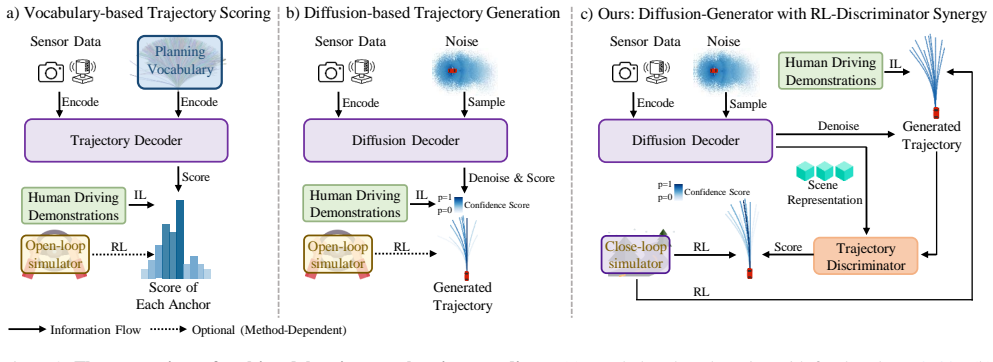
RAD-2 shows that a diffusion-based generator can produce trajectory candidates while an RL-optimized discriminator reranks them according to long-term driving quality, avoiding direct sparse reward application to the high-dimensional space and thereby improving optimization stability in closed-loop autonomous driving.
What carries the argument
The decoupled generator-discriminator architecture in which the discriminator uses reinforcement learning to score and rerank candidates from the diffusion generator.
If this is right
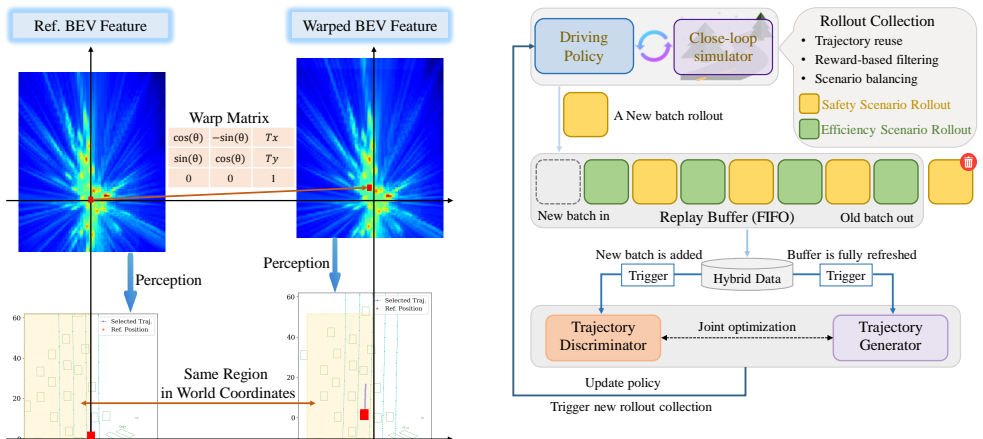
- On-policy generator optimization converts closed-loop feedback into structured signals that shift the generator toward higher-reward trajectory manifolds.
- Temporally consistent group relative policy optimization reduces credit-assignment problems when selecting among temporally coherent candidates.
- BEV-Warp simulation enables high-throughput closed-loop evaluation directly in feature space, supporting large-scale training.
- The same generator can be progressively improved without retraining the entire planner from scratch each time.
Where Pith is reading between the lines
- The separation of generation and evaluation may allow the same discriminator to be reused across different generators or even different driving domains.
- If the discriminator generalizes, it could provide a route to incorporate sparse real-world feedback without full trajectory-level reward engineering.
- The approach suggests that other multimodal planners facing credit assignment issues could adopt similar reranking stages.
Load-bearing premise
The RL discriminator can reliably judge long-term trajectory quality from closed-loop signals without creating new instabilities or requiring direct sparse rewards on the full trajectory space.
What would settle it
A side-by-side closed-loop test in which the same diffusion generator is run with and without the RL discriminator, measuring whether collision rates remain at least 50 percent lower when the discriminator is present.
Figures









read the original abstract
High-level autonomous driving requires motion planners capable of modeling multimodal future uncertainties while remaining robust in closed-loop interactions. Although diffusion-based planners are effective at modeling complex trajectory distributions, they often suffer from stochastic instabilities and the lack of corrective negative feedback when trained purely with imitation learning. To address these issues, we propose RAD-2, a unified generator-discriminator framework for closed-loop planning. Specifically, a diffusion-based generator is used to produce diverse trajectory candidates, while an RL-optimized discriminator reranks these candidates according to their long-term driving quality. This decoupled design avoids directly applying sparse scalar rewards to the full high-dimensional trajectory space, thereby improving optimization stability. To further enhance reinforcement learning, we introduce Temporally Consistent Group Relative Policy Optimization, which exploits temporal coherence to alleviate the credit assignment problem. In addition, we propose On-policy Generator Optimization, which converts closed-loop feedback into structured longitudinal optimization signals and progressively shifts the generator toward high-reward trajectory manifolds. To support efficient large-scale training, we introduce BEV-Warp, a high-throughput simulation environment that performs closed-loop evaluation directly in Bird's-Eye View feature space via spatial warping. RAD-2 reduces the collision rate by 56% compared with strong diffusion-based planners. Real-world deployment further demonstrates improved perceived safety and driving smoothness in complex urban traffic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RAD-2, a unified generator-discriminator framework for closed-loop motion planning in autonomous driving. A diffusion-based generator produces diverse trajectory candidates while an RL-optimized discriminator reranks them using long-term quality signals; this decoupling is intended to avoid instabilities from direct sparse rewards on high-dimensional trajectories. Additional contributions include Temporally Consistent Group Relative Policy Optimization (TCG-RPO) for credit assignment, On-policy Generator Optimization to shift the generator toward high-reward manifolds, and BEV-Warp for high-throughput closed-loop simulation in BEV feature space. The central empirical claim is a 56% collision-rate reduction relative to strong diffusion-based planners, with qualitative real-world improvements in safety and smoothness.
Significance. If the reported collision reduction and stability gains hold under rigorous evaluation, the generator-discriminator decoupling could meaningfully advance imitation-learning-based diffusion planners by incorporating corrective long-term feedback without direct high-dimensional reward application. TCG-RPO and BEV-Warp address practical scaling issues in RL for sequential trajectory decisions and large-scale training, respectively. These elements would be of interest to the motion-planning community if accompanied by reproducible experimental evidence.
major comments (2)
- [Abstract] Abstract (final sentence): The claim that RAD-2 'reduces the collision rate by 56% compared with strong diffusion-based planners' is presented without any reference to the experimental protocol, specific baselines, dataset splits, evaluation metrics, statistical significance, error bars, or ablation studies. Because this quantitative result is the primary evidence for the framework's effectiveness, its unsupported presentation is load-bearing for the central claim.
- [Abstract] Abstract (RL discriminator description): The assertion that the RL discriminator 'reranks these candidates according to their long-term driving quality' and 'avoids directly applying sparse scalar rewards to the full high-dimensional trajectory space' lacks any detail on reward design, how long-term signals are computed, or how instabilities are mitigated in practice. This is central to the claimed stability advantage and requires concrete specification.
minor comments (2)
- [Abstract] Abstract: The phrase 'strong diffusion-based planners' is undefined; the manuscript should explicitly name the comparison methods and their configurations.
- [Abstract] Abstract: Acronyms TCG-RPO and BEV-Warp are introduced without expansion on first use, which reduces immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing the strongest honest defense based on the content of the paper while indicating revisions where they improve clarity without misrepresenting our work.
read point-by-point responses
-
Referee: [Abstract] Abstract (final sentence): The claim that RAD-2 'reduces the collision rate by 56% compared with strong diffusion-based planners' is presented without any reference to the experimental protocol, specific baselines, dataset splits, evaluation metrics, statistical significance, error bars, or ablation studies. Because this quantitative result is the primary evidence for the framework's effectiveness, its unsupported presentation is load-bearing for the central claim.
Authors: We acknowledge that abstracts must remain concise, yet the referee is correct that the central quantitative claim benefits from additional context. The full manuscript details the experimental protocol, baselines (specific diffusion-based planners), dataset splits, evaluation metrics (primarily collision rate in closed-loop settings), statistical significance, error bars, and ablation studies in Sections 4 and 5, including tables with quantitative comparisons. To address the concern directly, we have revised the abstract's final sentence to: 'RAD-2 reduces the collision rate by 56% compared with strong diffusion-based planners in closed-loop evaluations, with full protocol, baselines, metrics, and ablations reported in the experiments.' This maintains brevity while explicitly directing readers to the supporting evidence. revision: yes
-
Referee: [Abstract] Abstract (RL discriminator description): The assertion that the RL discriminator 'reranks these candidates according to their long-term driving quality' and 'avoids directly applying sparse scalar rewards to the full high-dimensional trajectory space' lacks any detail on reward design, how long-term signals are computed, or how instabilities are mitigated in practice. This is central to the claimed stability advantage and requires concrete specification.
Authors: The abstract serves as a high-level overview, with the referee correctly noting that more specificity would strengthen the stability claim. The manuscript provides concrete details in Section 3.2 (RL Discriminator) and Section 3.3 (TCG-RPO): the reward design combines safety (collision penalties), comfort, and efficiency terms evaluated over multi-step closed-loop simulations; long-term signals are computed by rolling out trajectories in the BEV-Warp simulator; and instabilities are mitigated by the decoupled generator-discriminator structure plus temporally consistent group-relative optimization for credit assignment. We have revised the abstract to include a brief elaboration: 'an RL-optimized discriminator reranks these candidates according to their long-term driving quality, computed via simulated future trajectories, thereby avoiding direct application of sparse rewards to high-dimensional spaces.' Full mechanisms and mitigation strategies remain in the methods section. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an architectural framework combining a diffusion generator with an RL discriminator, plus new components (TCG-RPO for credit assignment, on-policy generator updates, and BEV-Warp simulation). These are presented as design choices with empirical validation via collision-rate reduction, not as a mathematical derivation that reduces to its own inputs by construction. No equations are shown that equate a claimed prediction or uniqueness result to a fitted parameter or self-citation. The central claim remains an empirical outcome of the decoupled generator-discriminator setup rather than a self-referential identity. The architecture is self-contained against external benchmarks and does not rely on load-bearing self-citations or ansatz smuggling for its core logic.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Action Emergence from Streaming Intent
Streaming Intent lets a VLA model derive driving intent via streamed chain-of-thought reasoning and use it to steer a flow-matching action head, yielding competitive Waymo scores plus intent-based trajectory control w...
-
CRAFT: Counterfactual-to-Interactive Reinforcement Fine-Tuning for Driving Policies
CRAFT is an on-policy RL fine-tuning framework that decomposes closed-loop policy gradients into a group-normalized counterfactual proxy plus residual correction from interaction events, achieving top closed-loop perf...
Reference graph
Works this paper leans on
-
[1]
Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan- guage models are few-shot learners.Advances in neural in- formation processing systems, 33:1877–1901, 2020. 3
1901
-
[2]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Reference Input Baseline Ours Start FrameKeyframe 1Keyframe 2 Ego Vehicle Ego Vehicle Ego Vehicle Ego Vehicle Ego Vehicle Ego Vehicle EP=0 EP=0.77 EP=1.01 EP=0 EP=0.75 EP=1.09 Figure 12.Qualitative comparison of driving efficiency in dynamic traffic.(1...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing.IEEE transactions on pattern analysis and machine in- telligence, 45(11):12878–12895, 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing.IEEE transactions on pattern analysis and machine in- telligence, 45(11):12878–12895, 2022. 1, 8, 10
2022
-
[4]
Carla: An open urban driv- ing simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Anto- nio Lopez, and Vladlen Koltun. Carla: An open urban driv- ing simulator. InConference on robot learning, pages 1–16. PMLR, 2017. 2, 3
2017
-
[5]
Lang Feng, Pengjie Gu, Bo An, and Gang Pan. Resisting stochastic risks in diffusion planners with the trajectory ag- gregation tree.arXiv preprint arXiv:2405.17879, 2024. 2
-
[6]
Minddrive: A vision-language-action model for autonomous driving via online reinforcement learning,
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Hongwei Xie, Bing Wang, Guang Chen, Dingkang Liang, and Xiang Bai. Minddrive: A vision-language-action model for autonomous driving via online reinforcement learning. arXiv preprint arXiv:2512.13636, 2025. 2
-
[7]
Hao Gao, Shaoyu Chen, Bo Jiang, Bencheng Liao, Yiang Shi, Xiaoyang Guo, Yuechuan Pu, Haoran Yin, Xiangyu Li, Xinbang Zhang, et al. Rad: Training an end-to-end driv- ing policy via large-scale 3dgs-based reinforcement learning. arXiv preprint arXiv:2502.13144, 2025. 2, 3, 8, 10
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning ca- pability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
ipad: Iterative proposal-centric end-to-end autonomous driving
Ke Guo, Haochen Liu, Xiaojun Wu, Jia Pan, and Chen Lv. ipad: Iterative proposal-centric end-to-end autonomous driv- ing.arXiv preprint arXiv:2505.15111, 2025. 3
-
[10]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 4
2020
-
[11]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gian- luca Corrado. Gaia-1: A generative world model for au- tonomous driving.arXiv preprint arXiv:2309.17080, 2023. 4
work page internal anchor Pith review arXiv 2023
-
[12]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023. 1
2023
-
[13]
Efficient deep reinforcement learning with imitative expert priors for au- tonomous driving.IEEE Transactions on Neural Networks and Learning Systems, 34(10):7391–7403, 2022
Zhiyu Huang, Jingda Wu, and Chen Lv. Efficient deep reinforcement learning with imitative expert priors for au- tonomous driving.IEEE Transactions on Neural Networks and Learning Systems, 34(10):7391–7403, 2022. 2, 3
2022
-
[14]
Spatial transformer networks.Advances in neural informa- tion processing systems, 28, 2015
Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spatial transformer networks.Advances in neural informa- tion processing systems, 28, 2015. 5
2015
-
[15]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richard- son, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Vad: Vectorized scene representa- tion for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representa- tion for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023. 1, 8, 10
2023
-
[17]
Bo Jiang, Shaoyu Chen, Bencheng Liao, Xingyu Zhang, Wei Yin, Qian Zhang, Chang Huang, Wenyu Liu, and Xing- gang Wang. Senna: Bridging large vision-language mod- els and end-to-end autonomous driving.arXiv preprint arXiv:2410.22313, 2024. 10
-
[18]
Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, and Xing- gang Wang. Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reason- ing.arXiv preprint arXiv:2503.07608, 2025. 3
-
[19]
Learning to drive in a day
Alex Kendall, Jeffrey Hawke, David Janz, Przemyslaw Mazur, Daniele Reda, John-Mark Allen, Vinh-Dieu Lam, Alex Bewley, and Amar Shah. Learning to drive in a day. In2019 international conference on robotics and automation (ICRA), pages 8248–8254. IEEE, 2019. 1
2019
-
[20]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[21]
Refining dif- fusion planner for reliable behavior synthesis by automatic detection of infeasible plans.Advances in Neural Informa- tion Processing Systems, 36:24223–24246, 2023
Kyowoon Lee, Seongun Kim, and Jaesik Choi. Refining dif- fusion planner for reliable behavior synthesis by automatic detection of infeasible plans.Advances in Neural Informa- tion Processing Systems, 36:24223–24246, 2023. 2
2023
-
[22]
Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review
Sergey Levine. Reinforcement learning and control as prob- abilistic inference: Tutorial and review.arXiv preprint arXiv:1805.00909, 2018. 3
work page internal anchor Pith review arXiv 2018
-
[23]
arXiv preprint arXiv:2510.18313 (2025)
Bohan Li, Zhuang Ma, Dalong Du, Baorui Peng, Zhujin Liang, Zhenqiang Liu, Chao Ma, Yueming Jin, Hao Zhao, Wenjun Zeng, et al. Omninwm: Omniscient driving naviga- tion world models.arXiv preprint arXiv:2510.18313, 2025. 2
-
[24]
Kailin Li, Zhenxin Li, Shiyi Lan, Yuan Xie, Zhizhong Zhang, Jiayi Liu, Zuxuan Wu, Zhiding Yu, and Jose M Alvarez. Hydra-mdp++: Advancing end-to-end driv- ing via expert-guided hydra-distillation.arXiv preprint arXiv:2503.12820, 2025. 1, 3
-
[25]
Reinforcement Learning with Action Chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Rein- forcement learning with action chunking.arXiv preprint arXiv:2507.07969, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[26]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[27]
Iterative linear quadratic regulator design for nonlinear biological movement systems
Weiwei Li and Emanuel Todorov. Iterative linear quadratic regulator design for nonlinear biological movement systems. InFirst International Conference on Informatics in Control, Automation and Robotics, pages 222–229. SciTePress, 2004. 5
2004
-
[28]
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online tra- jectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025. 4
-
[29]
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive frame- work for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025. 2, 3
-
[30]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi- target hydra-distillation.arXiv preprint arXiv:2406.06978,
work page internal anchor Pith review arXiv
-
[31]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chong- hao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 47(3):2020–2036,
2020
-
[32]
Ztrs: Zero-imitation end-to-end autonomous driving with trajectory scoring,
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Jingde Chen, Nadine Chang, Maying Shen, Jingyu Song, Zuxuan Wu, Shiyi Lan, et al. Ztrs: Zero-imitation end-to-end au- tonomous driving with trajectory scoring.arXiv preprint arXiv:2510.24108, 2025. 1
-
[33]
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Joshua Chen, Nadine Chang, Maying Shen, Zuxuan Wu, Shiyi Lan, and Jose M Alvarez. Generalized trajectory scor- ing for end-to-end multimodal planning.arXiv preprint arXiv:2506.06664, 2025. 3
-
[34]
Zhexi Lian, Haoran Wang, Xuerun Yan, Weimeng Lin, Xi- anhong Zhang, Yongyu Chen, and Jia Hu. Fine-tuning is not enough: A parallel framework for collaborative imita- tion and reinforcement learning in end-to-end autonomous driving.arXiv preprint arXiv:2603.13842, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Cirl: Controllable imitative reinforcement learning for vision-based self-driving
Xiaodan Liang, Tairui Wang, Luona Yang, and Eric Xing. Cirl: Controllable imitative reinforcement learning for vision-based self-driving. InProceedings of the European conference on computer vision (ECCV), pages 584–599,
-
[36]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025. 1, 2, 3
2025
-
[37]
Continuous control with deep reinforcement learning
Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971, 2015. 2
work page internal anchor Pith review arXiv 2015
-
[38]
Reinforced refinement with self-aware expansion for end-to-end autonomous driving,
Haochen Liu, Tianyu Li, Haohan Yang, Li Chen, Caojun Wang, Ke Guo, Haochen Tian, Hongchen Li, Hongyang Li, and Chen Lv. Reinforced refinement with self-aware ex- pansion for end-to-end autonomous driving.arXiv preprint arXiv:2506.09800, 2025. 2, 3
-
[39]
Imitation is not enough: Robustifying imitation with reinforcement learn- ing for challenging driving scenarios
Yiren Lu, Justin Fu, George Tucker, Xinlei Pan, Eli Bron- stein, Rebecca Roelofs, Benjamin Sapp, Brandyn White, Aleksandra Faust, Shimon Whiteson, et al. Imitation is not enough: Robustifying imitation with reinforcement learn- ing for challenging driving scenarios. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7...
2023
-
[40]
Recondreamer-rl: Enhancing reinforcement learning via diffusion-based scene reconstruction,
Chaojun Ni, Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Wenkang Qin, Xinze Chen, Guanghong Jia, Guan Huang, and Wenjun Mei. Recondreamer-rl: Enhancing rein- forcement learning via diffusion-based scene reconstruction. arXiv preprint arXiv:2508.08170, 2025. 2, 3
-
[41]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InEuropean conference on computer vision, pages 194–210. Springer, 2020. 4
2020
-
[42]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv preprint arXiv:1707.06347, 2017. 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Shuyao Shang, Yuntao Chen, Yuqi Wang, Yingyan Li, and Zhaoxiang Zhang. Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving.arXiv preprint arXiv:2509.17940, 2025. 3
-
[44]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Yuehao Song, Shaoyu Chen, Hao Gao, Yifan Zhu, Weixiang Yue, Jialv Zou, Bo Jiang, Zihao Lu, Yu Wang, Qian Zhang, et al. Senna-2: Aligning vlm and end-to-end driving policy for consistent decision making and planning.arXiv preprint arXiv:2603.11219, 2026. 8, 10
-
[46]
Wenchao Sun, Xuewu Lin, Keyu Chen, Zixiang Pei, Xiang Li, Yining Shi, and Sifa Zheng. Sparsedrivev2: Scoring is all you need for end-to-end autonomous driving.arXiv preprint arXiv:2603.29163, 2026. 3
-
[47]
Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14749–14759, 2024. 1
2024
-
[48]
Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14749–14759, 2024. 4
2024
-
[49]
Para-drive: Parallelized architecture for real- time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized architecture for real- time autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449–15458, 2024. 1
2024
-
[50]
DriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Tianze Xia, Yongkang Li, Lijun Zhou, Jingfeng Yao, Kaixin Xiong, Haiyang Sun, Bing Wang, Kun Ma, Guang Chen, Hangjun Ye, et al. Drivelaw: Unifying planning and video generation in a latent driving world.arXiv preprint arXiv:2512.23421, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
arXiv preprint arXiv:2511.20325 (2025)
Tianyi Yan, Tao Tang, Xingtai Gui, Yongkang Li, Jiasen Zhesng, Weiyao Huang, Lingdong Kong, Wencheng Han, Xia Zhou, Xueyang Zhang, et al. Ad-r1: Closed-loop rein- forcement learning for end-to-end autonomous driving with impartial world models.arXiv preprint arXiv:2511.20325, 2025
-
[52]
Worldrft: Latent world model planning with reinforcement fine-tuning for autonomous driving
Pengxuan Yang, Ben Lu, Zhongpu Xia, Chao Han, Yin- feng Gao, Teng Zhang, Kun Zhan, XianPeng Lang, Yupeng Zheng, and Qichao Zhang. Worldrft: Latent world model planning with reinforcement fine-tuning for autonomous driving. InProceedings of the AAAI Conference on Artifi- cial Intelligence, pages 11649–11657, 2026
2026
-
[53]
Pengxuan Yang, Yupeng Zheng, Deheng Qian, Zebin Xing, Qichao Zhang, Linbo Wang, Yichen Zhang, Shaoyu Guo, Zhongpu Xia, Qiang Chen, et al. Dreamerad: Efficient re- inforcement learning via latent world model for autonomous driving.arXiv preprint arXiv:2603.24587, 2026. 2
-
[54]
arXiv preprint arXiv:2506.06659 (2025)
Wenhao Yao, Zhenxin Li, Shiyi Lan, Zi Wang, Xinglong Sun, Jose M Alvarez, and Zuxuan Wu. Drivesuprim: To- wards precise trajectory selection for end-to-end planning. arXiv preprint arXiv:2506.06659, 2025. 3
-
[55]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gao- hong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Haichao Zhang, Wei Xu, and Haonan Yu. Generative plan- ning for temporally coordinated exploration in reinforcement learning.arXiv preprint arXiv:2201.09765, 2022. 6
-
[57]
Drivedreamer4d: World models are effective data machines for 4d driving scene rep- resentation
Guosheng Zhao, Chaojun Ni, Xiaofeng Wang, Zheng Zhu, Xueyang Zhang, Yida Wang, Guan Huang, Xinze Chen, Boyuan Wang, Youyi Zhang, et al. Drivedreamer4d: World models are effective data machines for 4d driving scene rep- resentation. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 12015–12026, 2025. 4
2025
-
[58]
Guosheng Zhao, Xiaofeng Wang, Chaojun Ni, Zheng Zhu, Wenkang Qin, Guan Huang, and Xingang Wang. Re- condreamer++: Harmonizing generative and reconstructive models for driving scene representation.arXiv preprint arXiv:2503.18438, 2025. 4
-
[59]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[60]
Genad: Generative end-to-end au- tonomous driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Generative end-to-end au- tonomous driving. InEuropean Conference on Computer Vision, pages 87–104. Springer, 2024. 8, 10
2024
-
[61]
arXiv preprint arXiv:2501.15564 , year =
Yinan Zheng, Ruiming Liang, Kexin Zheng, Jinliang Zheng, Liyuan Mao, Jianxiong Li, Weihao Gu, Rui Ai, Shengbo Eben Li, Xianyuan Zhan, et al. Diffusion-based planning for autonomous driving with flexible guidance. arXiv preprint arXiv:2501.15564, 2025. 1
-
[62]
Unleashing the potential of diffusion models for end-to-end autonomous driving
Yinan Zheng, Tianyi Tan, Bin Huang, Enguang Liu, Ruim- ing Liang, Jianlin Zhang, Jianwei Cui, Guang Chen, Kun Ma, Hangjun Ye, et al. Unleashing the potential of diffusion models for end-to-end autonomous driving.arXiv preprint arXiv:2602.22801, 2026. 2
- [63]
-
[64]
Hongyu Zhou, Longzhong Lin, Jiabao Wang, Yichong Lu, Dongfeng Bai, Bingbing Liu, Yue Wang, Andreas Geiger, and Yiyi Liao. Hugsim: A real-time, photo-realistic and closed-loop simulator for autonomous driving.arXiv preprint arXiv:2412.01718, 2024. 2
-
[65]
arXiv preprint arXiv:2010.09776 , year=
Ming Zhou, Jun Luo, Julian Villella, Yaodong Yang, David Rusu, Jiayu Miao, Weinan Zhang, Montgomery Alban, Iman Fadakar, Zheng Chen, et al. Smarts: Scalable multi-agent reinforcement learning training school for autonomous driv- ing.arXiv preprint arXiv:2010.09776, 2020. 3
-
[66]
Zewei Zhou, Tianhui Cai, Seth Z Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025. 2, 3
work page internal anchor Pith review arXiv 2025
-
[67]
Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yue- hao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, and Xing- gang Wang. Diffusiondrivev2: Reinforcement learning- constrained truncated diffusion modeling in end-to-end au- tonomous driving.arXiv preprint arXiv:2512.07745, 2025. 1, 3
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.