Recognition: unknown
Training LLMs with Reinforcement Learning for Intent-Aware Personalized Question Answering
Pith reviewed 2026-05-14 20:54 UTC · model grok-4.3
The pith
Reinforcement learning trains LLMs to infer implicit user intent from single-turn questions and generate better-aligned personalized answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
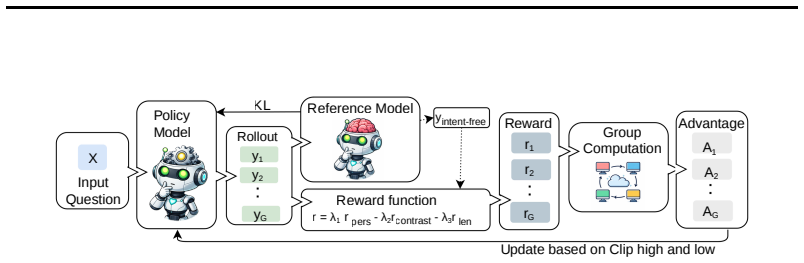
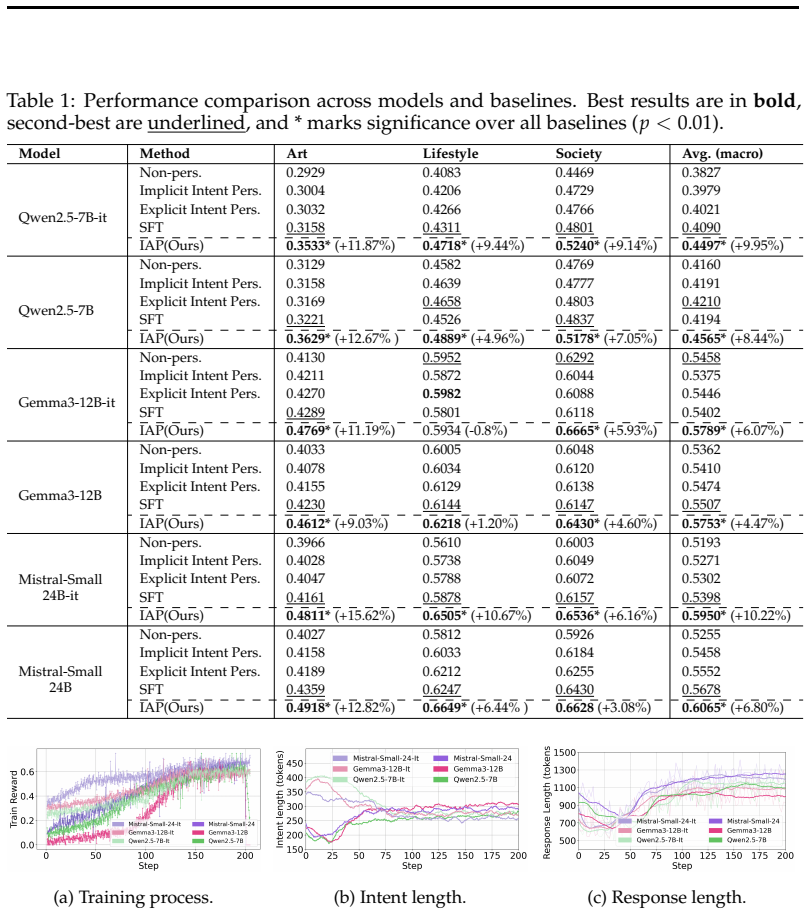
IAP is a reinforcement learning framework that trains models to infer implicit user intent directly from a single-turn question and incorporate it into thinking steps through a tag-based schema for generating personalized, intent-grounded answers. By optimizing intent-aware answer trajectories under a personalized reward function, IAP reinforces generation paths that make implicit user intent explicit and produce responses that better align with the user's underlying goal, yielding an average macro-score gain of around 7.5 percent over the strongest competitor on the LaMP-QA benchmark.
What carries the argument
The IAP reinforcement learning framework, which applies a tag-based schema to represent implicit intent inside the model's reasoning steps and optimizes trajectories with a personalized reward function.
If this is right
- Personalized answers become feasible in single-turn interactions that lack conversation history or stored user profiles.
- The same training approach produces gains across multiple base language models rather than being tied to one architecture.
- Explicitly rewarding intent alignment during reinforcement learning shifts the generation process toward user goals instead of surface-level query matching.
- Intent inference moves from an inference-time heuristic to an optimizable skill learned from reward signals.
Where Pith is reading between the lines
- Deployed systems might require less ongoing collection of personal data once intent inference is baked into the model weights.
- The same reward-driven intent modeling could transfer to other single-interaction tasks such as personalized summarization or recommendation.
- Combining the method with minimal optional history signals could be tested to measure further gains while keeping the core single-turn advantage.
Load-bearing premise
A tag-based schema combined with a personalized reward function can reliably infer implicit intent from single-turn questions and optimize generation paths without multi-turn context or user profiles.
What would settle it
Human preference ratings or alignment scores on a held-out set of single-turn questions containing deliberately ambiguous intents, where IAP outputs show no consistent advantage over non-intent-aware baselines.
Figures


read the original abstract
Effective personalized question answering (PQA) in language models requires grounding responses in the user's underlying intent, where intent refers to the implicit ``why'' behind a query beyond its explicit wording. However, existing approaches to intent-aware personalization rely on multi-turn conversational context or rich user profiles, and do not explicitly model user intent during the reasoning process. This limits their effectiveness in single-turn settings, where the user's latent goal must be inferred from minimal input and integrated into the thinking and reasoning process. To bridge this gap, we propose IAP (Intent-Aware Personalization), a reinforcement learning framework that trains models to infer implicit user intent directly from a single-turn question and incorporate it into thinking steps through a tag-based schema for generating personalized, intent-grounded answers. By optimizing intent-aware answer trajectories under a personalized reward function, IAP reinforces generation paths that make implicit user intent explicit and produce responses that better align with the user's underlying goal. Through experiments on the LaMP-QA benchmark across six models, IAP consistently outperforms all baselines, achieving an average macro-score gain of around 7.5\% over the strongest competitor, demonstrating that modeling implicit user intent within the training objective is a promising direction for PQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IAP, a reinforcement learning framework for training LLMs on intent-aware personalized question answering. It introduces a tag-based schema to infer implicit user intent directly from single-turn questions, incorporates these tags into reasoning trajectories, and optimizes them under a personalized reward function. Experiments on the LaMP-QA benchmark across six models report consistent outperformance, with an average macro-score gain of approximately 7.5% over the strongest baseline.
Significance. If the reward function operates independently of LaMP-QA metadata and the tag schema reliably elicits intent from minimal input, the work would provide a concrete demonstration that RL can reinforce intent-grounded generation paths in single-turn PQA. The multi-model evaluation strengthens the empirical case for explicit intent modeling within the training objective.
major comments (3)
- [Method] Method section (reward function definition): The personalized reward function is described only at a high level; its exact inputs, formulation, and dependence on single-turn question/tags versus any LaMP-QA annotations or labels are not specified. This detail is load-bearing for the central claim that the RL loop discovers intent without circular use of benchmark signals.
- [Experiments] Experiments section: The reported 7.5% average macro-score gain lacks accompanying details on run count, variance, statistical significance tests, or per-model breakdowns, preventing assessment of whether the outperformance is robust or sensitive to evaluation choices.
- [Training] Training procedure: Integration of the tag-based schema into the generation trajectory and the specific RL algorithm (e.g., PPO or variant) and reward scaling are not detailed enough to reproduce or verify that intent inference occurs from the question alone.
minor comments (1)
- [Evaluation] Clarify the precise definition and aggregation method for the 'macro-score' metric used in the main results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We have addressed each major comment point by point below and will incorporate the requested clarifications and details into the revised version.
read point-by-point responses
-
Referee: [Method] Method section (reward function definition): The personalized reward function is described only at a high level; its exact inputs, formulation, and dependence on single-turn question/tags versus any LaMP-QA annotations or labels are not specified. This detail is load-bearing for the central claim that the RL loop discovers intent without circular use of benchmark signals.
Authors: We agree that the reward function requires more precise specification to support the central claim. In the revised manuscript, we will expand the Method section to provide the exact mathematical formulation of the personalized reward function. The inputs will be explicitly defined as the single-turn question, the inferred intent tags, and the generated answer, with no dependence on LaMP-QA annotations or labels. This formulation ensures the RL optimization reinforces intent-grounded trajectories based solely on the query at hand. revision: yes
-
Referee: [Experiments] Experiments section: The reported 7.5% average macro-score gain lacks accompanying details on run count, variance, statistical significance tests, or per-model breakdowns, preventing assessment of whether the outperformance is robust or sensitive to evaluation choices.
Authors: We acknowledge the need for greater statistical rigor in reporting the results. The revised Experiments section will include the number of independent runs performed, standard deviations or variances across runs, results from statistical significance tests (such as paired t-tests against baselines), and complete per-model score breakdowns to allow readers to assess robustness. revision: yes
-
Referee: [Training] Training procedure: Integration of the tag-based schema into the generation trajectory and the specific RL algorithm (e.g., PPO or variant) and reward scaling are not detailed enough to reproduce or verify that intent inference occurs from the question alone.
Authors: We thank the referee for highlighting this reproducibility concern. In the revised manuscript, we will detail the training procedure by specifying how the tag-based schema is integrated into the generation trajectory (via explicit prefixing of inferred intent tags in the reasoning steps), the exact RL algorithm employed (PPO with its hyperparameters), and the reward scaling mechanism. These additions will confirm that intent inference is performed exclusively from the single-turn question. revision: yes
Circularity Check
No circularity: empirical RL optimization on external benchmark
full rationale
The derivation consists of defining a tag-based schema for intent inference, a personalized reward function, and RL training to optimize generation trajectories. The load-bearing claim is measured outperformance (7.5% macro-score gain) on the external LaMP-QA benchmark across six models. No equation reduces to its own input by construction, no fitted parameter is relabeled as a prediction, and no self-citation chain supplies the uniqueness or reward definition. The reward is computed from benchmark-aligned signals but remains an external optimization target rather than a self-referential loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- personalized reward function parameters
axioms (1)
- domain assumption Implicit user intent can be reliably inferred from single-turn questions alone
invented entities (1)
-
tag-based schema for intent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Second Conference on Language Modeling , year=
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning , author=. Second Conference on Language Modeling , year=
-
[2]
Yixin Ye and Zhen Huang and Yang Xiao and Ethan Chern and Shijie Xia and Pengfei Liu , booktitle=. 2025 , url=
work page 2025
-
[3]
Bowen Jin and Hansi Zeng and Zhenrui Yue and Jinsung Yoon and Sercan O Arik and Dong Wang and Hamed Zamani and Jiawei Han , booktitle=. Search-R1: Training. 2025 , url=
work page 2025
-
[4]
Zhang, Kepu and Xie, Guofu and Yu, Weijie and Xu, Mingyue and Tang, Xu and Li, Yaxin and Xu, Jun. Legal Mathematical Reasoning with LLM s: Procedural Alignment through Two-Stage Reinforcement Learning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.84
-
[5]
Beyond Guilt: Legal Judgment Prediction with Trichotomous Reasoning
Zhang, Kepu and Yang, Haoyue and Tang, Xu and Yu, Weijie and Xu, Jun. Beyond Guilt: Legal Judgment Prediction with Trichotomous Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.95
-
[6]
Towards Medical Complex Reasoning with LLM s through Medical Verifiable Problems
Chen, Junying and Cai, Zhenyang and Ji, Ke and Wang, Xidong and Liu, Wanlong and Wang, Rongsheng and Wang, Benyou. Towards Medical Complex Reasoning with LLM s through Medical Verifiable Problems. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.751
-
[7]
Transactions on Machine Learning Research , issn=
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
work page 2025
-
[8]
arXiv preprint arXiv:2502.14768 , year=
Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning , author=. arXiv preprint arXiv:2502.14768 , year=
-
[9]
Zhang, Kepu and Yu, Weijie and Sun, Zhongxiang and Xu, Jun , title =. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages =. 2025 , isbn =. doi:10.1145/3746252.3761120 , abstract =
-
[10]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
work page 2022
-
[11]
Proceedings of the 17th ACM Conference on Recommender Systems , pages =
Dai, Sunhao and Shao, Ninglu and Zhao, Haiyuan and Yu, Weijie and Si, Zihua and Xu, Chen and Sun, Zhongxiang and Zhang, Xiao and Xu, Jun , title =. Proceedings of the 17th ACM Conference on Recommender Systems , pages =. 2023 , isbn =. doi:10.1145/3604915.3610646 , abstract =
-
[12]
Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages =
Liu, Qijiong and Chen, Nuo and Sakai, Tetsuya and Wu, Xiao-Ming , title =. Proceedings of the 17th ACM International Conference on Web Search and Data Mining , pages =. 2024 , isbn =. doi:10.1145/3616855.3635845 , abstract =
-
[13]
Siyan Zhao and Mingyi Hong and Yang Liu and Devamanyu Hazarika and Kaixiang Lin , booktitle=. Do. 2025 , url=
work page 2025
-
[14]
arXiv preprint arXiv:2304.03153 , year=
Zero-shot next-item recommendation using large pretrained language models , author=. arXiv preprint arXiv:2304.03153 , year=
-
[15]
Wang, Jianling and Lu, Haokai and Liu, Yifan and Ma, He and Wang, Yueqi and Gu, Yang and Zhang, Shuzhou and Han, Ningren and Bi, Shuchao and Baugher, Lexi and Chi, Ed H. and Chen, Minmin , title =. Proceedings of the 18th ACM Conference on Recommender Systems , pages =. 2024 , isbn =. doi:10.1145/3640457.3688161 , abstract =
-
[16]
Salemi, Alireza and Zamani, Hamed , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , isbn =. doi:10.1145/3626772.3657957 , abstract =
-
[17]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =
Fan, Wenqi and Ding, Yujuan and Ning, Liangbo and Wang, Shijie and Li, Hengyun and Yin, Dawei and Chua, Tat-Seng and Li, Qing , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages =. 2024 , isbn =. doi:10.1145/3637528.3671470 , abstract =
-
[18]
Advances in Neural Information Processing Systems , volume=
Hydra: Model factorization framework for black-box llm personalization , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Salemi, Alireza and Kallumadi, Surya and Zamani, Hamed , title =. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages =. 2024 , isbn =. doi:10.1145/3626772.3657783 , abstract =
-
[20]
Zhang, Kepu and Shi, Teng and Yu, Weijie and Xu, Jun , title =. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages =. 2025 , isbn =. doi:10.1145/3746252.3760851 , abstract =
-
[21]
arXiv preprint arXiv:2509.19094 , year=
Pathways of Thoughts: Multi-Directional Thinking for Long-form Personalized Question Answering , author=. arXiv preprint arXiv:2509.19094 , year=
-
[22]
LLM s + Persona-Plug = Personalized LLM s
Liu, Jiongnan and Zhu, Yutao and Wang, Shuting and Wei, Xiaochi and Min, Erxue and Lu, Yu and Wang, Shuaiqiang and Yin, Dawei and Dou, Zhicheng. LLM s + Persona-Plug = Personalized LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.461
-
[23]
Few-shot Personalization of LLM s with Mis-aligned Responses
Kim, Jaehyung and Yang, Yiming. Few-shot Personalization of LLM s with Mis-aligned Responses. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.naacl-long.598
-
[24]
L a MP : When Large Language Models Meet Personalization
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed. L a MP : When Large Language Models Meet Personalization. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.399
-
[25]
S umm E dits: Measuring LLM Ability at Factual Reasoning Through The Lens of Summarization
Laban, Philippe and Kryscinski, Wojciech and Agarwal, Divyansh and Fabbri, Alexander and Xiong, Caiming and Joty, Shafiq and Wu, Chien-Sheng. S umm E dits: Measuring LLM Ability at Factual Reasoning Through The Lens of Summarization. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.600
-
[26]
Modeling Motivated Reasoning in Law: Evaluating Strategic Role Conditioning in LLM Summarization
Cho, Eunjung and Hoyle, Alexander and Hermstr. Modeling Motivated Reasoning in Law: Evaluating Strategic Role Conditioning in LLM Summarization. Proceedings of the Natural Legal Language Processing Workshop 2025. 2025. doi:10.18653/v1/2025.nllp-1.7
-
[27]
Bismay, Millennium and Dong, Xiangjue and Caverlee, James. R easoning R ec: Bridging Personalized Recommendations and Human-Interpretable Explanations through LLM Reasoning. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.454
-
[28]
Wang, Yan and Chu, Zhixuan and Ouyang, Xin and Wang, Simeng and Hao, Hongyan and Shen, Yue and Gu, Jinjie and Xue, Siqiao and Zhang, James and Cui, Qing and Li, Longfei and Zhou, Jun and Li, Sheng , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Inte...
-
[29]
Tsai, Alicia and Kraft, Adam and Jin, Long and Cai, Chenwei and Hosseini, Anahita and Xu, Taibai and Zhang, Zemin and Hong, Lichan and Chi, Ed H. and Yi, Xinyang. Leveraging LLM Reasoning Enhances Personalized Recommender Systems. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.780
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Rlpf: Reinforcement learning from prediction feedback for user summarization with llms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[31]
Sun, Chenkai and Yang, Ke and Gangi Reddy, Revanth and Fung, Yi and Chan, Hou Pong and Small, Kevin and Zhai, ChengXiang and Ji, Heng. Persona- DB : Efficient Large Language Model Personalization for Response Prediction with Collaborative Data Refinement. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[32]
L a MP - QA : A Benchmark for Personalized Long-form Question Answering
Salemi, Alireza and Zamani, Hamed. L a MP - QA : A Benchmark for Personalized Long-form Question Answering. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.60
-
[33]
Open- RAG : Enhanced Retrieval Augmented Reasoning with Open-Source Large Language Models
Islam, Shayekh Bin and Rahman, Md Asib and Hossain, K S M Tozammel and Hoque, Enamul and Joty, Shafiq and Parvez, Md Rizwan. Open- RAG : Enhanced Retrieval Augmented Reasoning with Open-Source Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.831
-
[34]
RARE : Retrieval-Augmented Reasoning Enhancement for Large Language Models
Tran, Hieu and Yao, Zonghai and Yang, Zhichao and Wang, Junda and Zhang, Yifan and Han, Shuo and Feiyun Ouyang and Yu, Hong. RARE : Retrieval-Augmented Reasoning Enhancement for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.896
-
[35]
arXiv preprint arXiv:2510.11483 , year=
Uncertainty Quantification for Retrieval-Augmented Reasoning , author=. arXiv preprint arXiv:2510.11483 , year=
-
[36]
Bowen Jin and Jinsung Yoon and Jiawei Han and Sercan O Arik , booktitle=. Long-Context. 2025 , url=
work page 2025
-
[37]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Unsupervised Dense Retrieval with Relevance-Aware Contrastive Pre-Training
Lei, Yibin and Ding, Liang and Cao, Yu and Zan, Changtong and Yates, Andrew and Tao, Dacheng. Unsupervised Dense Retrieval with Relevance-Aware Contrastive Pre-Training. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.695
-
[41]
IEEE Transactions on Big Data , year=
The faiss library , author=. IEEE Transactions on Big Data , year=
-
[42]
Ms marco: A human-generated machine reading comprehension dataset , author=
-
[43]
arXiv preprint arXiv:2407.11016 , year=
Longlamp: A benchmark for personalized long-form text generation , author=. arXiv preprint arXiv:2407.11016 , year=
-
[44]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Efficient Intent Detection with Dual Sentence Encoders
Casanueva, I \ n igo and Tem c inas, Tadas and Gerz, Daniela and Henderson, Matthew and Vuli \'c , Ivan. Efficient Intent Detection with Dual Sentence Encoders. Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI. 2020. doi:10.18653/v1/2020.nlp4convai-1.5
-
[46]
and Clarke, Christopher and Lee, Andrew and Hill, Parker and Kummerfeld, Jonathan K
Larson, Stefan and Mahendran, Anish and Peper, Joseph J. and Clarke, Christopher and Lee, Andrew and Hill, Parker and Kummerfeld, Jonathan K. and Leach, Kevin and Laurenzano, Michael A. and Tang, Lingjia and Mars, Jason. An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction. Proceedings of the 2019 Conference on Empirical Methods in ...
-
[47]
Snips voice platform: an embedded spoken language understanding system for private-by-design voice interfaces , author=. arXiv preprint arXiv:1805.10190 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling
Budzianowski, Pawe and Wen, Tsung-Hsien and Tseng, Bo-Hsiang and Casanueva, I \ n igo and Ultes, Stefan and Ramadan, Osman and Ga s i \'c , Milica. M ulti WOZ - A Large-Scale Multi-Domain W izard-of- O z Dataset for Task-Oriented Dialogue Modelling. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/...
-
[49]
Peskov, Denis and Clarke, Nancy and Krone, Jason and Fodor, Brigi and Zhang, Yi and Youssef, Adel and Diab, Mona. Multi-Domain Goal-Oriented Dialogues ( M ulti D o GO ): Strategies toward Curating and Annotating Large Scale Dialogue Data. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint...
-
[50]
Proceedings of the AAAI conference on artificial intelligence , volume=
Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[51]
Intent Mining from past conversations for Conversational Agent
Chatterjee, Ajay and Sengupta, Shubhashis. Intent Mining from past conversations for Conversational Agent. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.366
-
[52]
Zhang, Feng and Chen, Wei and Ding, Fei and Gao, Meng and Wang, Tengjiao and Yao, Jiahui and Zheng, Jiabin. From Discrimination to Generation: Low-Resource Intent Detection with Language Model Instruction Tuning. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.605
-
[53]
Askari, Arian and Petcu, Roxana and Meng, Chuan and Aliannejadi, Mohammad and Abolghasemi, Amin and Kanoulas, Evangelos and Verberne, Suzan. SOLID : Self-seeding and Multi-intent Self-instructing LLM s for Generating Intent-aware Information-Seeking Dialogs. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025....
-
[54]
A Survey on Multi-modal Intent Recognition: Recent Advances and New Frontiers
Zhu, Zhihong and Zhang, Fan and Zhang, Yunyan and Sun, Jinghan and Huang, Zhiqi and Long, Qingqing and Xing, Bowen and Wu, Xian. A Survey on Multi-modal Intent Recognition: Recent Advances and New Frontiers. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.823
-
[55]
C onv GQR : Generative Query Reformulation for Conversational Search
Mo, Fengran and Mao, Kelong and Zhu, Yutao and Wu, Yihong and Huang, Kaiyu and Nie, Jian-Yun. C onv GQR : Generative Query Reformulation for Conversational Search. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023.acl-long.274
-
[56]
arXiv preprint arXiv:2509.04472 , year=
RECAP: REwriting Conversations for Intent Understanding in Agentic Planning , author=. arXiv preprint arXiv:2509.04472 , year=
-
[57]
arXiv preprint arXiv:2509.10010 , year=
Multi-intent recognition in dialogue understanding: a comparison between smaller open-source LLMs , author=. arXiv preprint arXiv:2509.10010 , year=
-
[58]
Shujing Dong and Yuan Ling and Shunyan Luo and Shuyi Wang and Yarong Feng and Zongyi (Joe) Liu and Hongfei Li and Ayush Goyal and Bruce Ferry , title =. 2024 , url =
work page 2024
-
[59]
ECLM : Entity Level Language Model for Spoken Language Understanding with Chain of Intent
Yin, Shangjian and Huang, Peijie and Chen, JiaTian and Huang, Haojing and Xu, Yuhong. ECLM : Entity Level Language Model for Spoken Language Understanding with Chain of Intent. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1061
-
[60]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Intentqa: Context-aware video intent reasoning , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[61]
The Fourteenth International Conference on Learning Representations , year=
Improving Attributed Long-form Question Answering with Intent Awareness , author=. The Fourteenth International Conference on Learning Representations , year=
-
[62]
Shah, Chirag and White, Ryen and Andersen, Reid and Buscher, Georg and Counts, Scott and Das, Sarkar and Montazer, Ali and Manivannan, Sathish and Neville, Jennifer and Rangan, Nagu and Safavi, Tara and Suri, Siddharth and Wan, Mengting and Wang, Leijie and Yang, Longqi , title =. ACM Trans. Web , month = aug, articleno =. 2025 , issue_date =. doi:10.1145...
-
[63]
IPQA: A Benchmark for Core Intent Identification in Personalized Question Answering
IPQA: A Benchmark for Core Intent Identification in Personalized Question Answering , author=. arXiv preprint arXiv:2510.23536 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Amirizaniani, Maryam and Martin, Elias and Sivachenko, Maryna and Mashhadi, Afra and Shah, Chirag , title =. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =. 2024 , isbn =. doi:10.1145/3627673.3679832 , abstract =
-
[65]
Understanding Social Reasoning in Language Models with Language Models , author=. Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[66]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Huaisheng Zhu and Teng Xiao and Vasant G Honavar , booktitle=. 2025 , url=
work page 2025
-
[68]
Journal of artificial intelligence research , volume=
Reinforcement learning: A survey , author=. Journal of artificial intelligence research , volume=
-
[69]
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and YuYue and Weinan Dai and Tiantian Fan and Gaohong Liu and Juncai Liu and LingJun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Ru Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and ...
work page 2025
-
[70]
Amirizaniani, Maryam , title =. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages =. 2024 , isbn =. doi:10.1145/3627673.3680273 , abstract =
-
[71]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
work page 2004
-
[72]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[73]
Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining , pages =
Amirizaniani, Maryam and Sivachenko, Maryna and Lavergne, Adrian and Shah, Chirag and Mashhadi, Afra , title =. Proceedings of the Eighteenth ACM International Conference on Web Search and Data Mining , pages =. 2025 , isbn =. doi:10.1145/3701551.3703576 , abstract =
-
[74]
Amirizaniani, Maryam and Martin, Elias and Mashhadi, Afra and Shah, Chirag , title =. Proceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval (ICTIR) , pages =. 2025 , isbn =. doi:10.1145/3731120.3744598 , abstract =
-
[75]
Prakash, V. Jothi and Vijay, S. Arul Antran , title =. ACM Trans. Intell. Syst. Technol. , month = nov, articleno =. 2024 , issue_date =. doi:10.1145/3682064 , abstract =
-
[76]
Tong, Tong and Setchi, Rossitza and Hicks, Yulia , title =. 2022 , issue_date =. doi:10.1016/j.procs.2022.09.444 , journal =
-
[77]
arXiv preprint arXiv:2404.14415 , year=
Domain adaptation in intent classification systems: a review , author=. arXiv preprint arXiv:2404.14415 , year=
-
[78]
Hanlei Zhang and Xin Wang and Hua Xu and Qianrui Zhou and Kai Gao and Jianhua Su and jinyue Zhao and Wenrui Li and Yanting Chen , booktitle=. 2024 , url=
work page 2024
-
[79]
Zhang, Hanlei and Xu, Hua and Wang, Xin and Zhou, Qianrui and Zhao, Shaojie and Teng, Jiayan , title =. 2022 , booktitle =
work page 2022
-
[80]
Intent Detection in the Age of LLM s
Arora, Gaurav and Jain, Shreya and Merugu, Srujana. Intent Detection in the Age of LLM s. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2024. doi:10.18653/v1/2024.emnlp-industry.114
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.