Recognition: 2 theorem links
· Lean TheoremCHAL: Council of Hierarchical Agentic Language
Pith reviewed 2026-05-14 19:54 UTC · model grok-4.3
The pith
CHAL reframes multi-agent LLM debate as structured belief optimization over domains where any position remains open to defeat by better reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CHAL is the first framework to treat multi-agent debate as structured belief optimization over defeasible domains. Each agent maintains a CHAL Belief Schema, a graph-structured belief representation with a Bayesian-inspired architecture that performs belief revision through a gradient-informed dynamic mechanism. Meta-cognitive value systems spanning epistemology, logic, and ethics are elevated to configurable hyperparameters that govern agent reasoning and adjudication outcomes, producing auditable belief artifacts.
What carries the argument
CHAL Belief Schema (CBS): a graph-structured belief representation with Bayesian-inspired architecture that facilitates belief revision by treating the strength of a thesis as a differentiable objective and applying gradient-informed updates.
If this is right
- The adjudicator's value system directly controls the overall trajectory of beliefs in latent space.
- Greater council diversity produces measurable refinement in every participant's final beliefs.
- The framework applies across broad fields without task-specific redesign.
- The produced belief artifacts enable dedicated evaluation suites for defeasible argumentation.
Where Pith is reading between the lines
- The auditable schemas could support human oversight mechanisms that inspect or override specific belief edges rather than entire model outputs.
- Extending the same graph machinery to legal or policy domains would turn debate into a traceable process of incremental position defeat.
- If the gradient updates prove stable, similar schemas might be added to single-agent systems to improve calibration on open-ended questions.
Load-bearing premise
Large language models can reliably maintain graph-structured belief schemas and execute gradient-informed revisions on them while treating meta-cognitive value systems as stable hyperparameters that do not introduce inconsistencies or coherence loss.
What would settle it
Run a multi-round CHAL debate on a complex defeasible topic and observe whether the belief graphs remain coherent and the updates stay consistent with the chosen value hyperparameters, or whether contradictions and drift appear after a few rounds.
Figures







read the original abstract
Multi-agent debate has emerged as a promising approach for improving LLM reasoning on ground-truth tasks, yet current methodologies face certain structural limitations: debate tends to induce a martingale over belief trajectories, majority voting accounts for most observed gains, and LLMs exhibit confidence escalation rather than calibration across rounds. We argue that the genuine value of debate, and dialectic systems as a whole, lies not in ground-truth tasks but in defeasible domains, where every position can in principle be defeated by better reasoning. We present the Council of Hierarchical Agentic Language (CHAL), a multi-agent dialectic framework that treats defeasible argumentation as an engine for belief optimization. Each agent maintains a CHAL Belief Schema (CBS), a graph-structured belief representation with a Bayesian-inspired architecture, that facilitates belief revision through a gradient-informed dynamic mechanism by leveraging the strength of the belief's thesis as a differentiable objective. Meta-cognitive value systems spanning epistemology, logic, and ethics are elevated to configurable hyperparameters governing agent reasoning and adjudication outcomes. We provide a series of ablation experiments that demonstrate systematic and interpretable effects: the adjudicator's value system determines the debate's overall trajectories in latent belief space, council diversity refines beliefs for all participants, and the framework generalizes across broad fields. CHAL is, to our knowledge, the first framework to treat multi-agent debate as structured belief optimization over defeasible domains. Further, the auditable belief artifacts it produces establish the foundation for dedicated evaluation suites for defeasible argumentation, with broader implications for building AI systems whose reasoning and value commitments are transparent, aligned, and subject to human oversight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CHAL, a multi-agent dialectic framework for defeasible domains that models debate as structured belief optimization. Each agent maintains a graph-structured CHAL Belief Schema (CBS) with Bayesian-inspired architecture; belief revision uses a gradient-informed mechanism with thesis strength as the objective, while meta-cognitive value systems (epistemology, logic, ethics) act as configurable hyperparameters. Ablation experiments are reported to show systematic effects on latent belief trajectories, belief refinement via council diversity, and generalization across fields, with auditable artifacts enabling new evaluation suites.
Significance. If the gradient-informed revision and hyperparameter mechanisms can be realized without coherence loss, CHAL would provide a concrete architecture for moving multi-agent debate beyond martingale trajectories and confidence escalation, producing transparent, revisable belief graphs with potential value for alignment and oversight in open-ended reasoning tasks.
major comments (3)
- [Abstract and §3] Abstract and §3 (CHAL Belief Schema): the gradient-informed dynamic mechanism is described as using 'belief thesis strength as a differentiable objective,' yet no equations, pseudocode, or approximation procedure is supplied for how gradients are computed or applied when the underlying model is an LLM; this is load-bearing for the central claim of structured optimization.
- [§4] §4 (Ablation experiments): the text asserts 'systematic and interpretable effects' from varying the adjudicator's value system and council diversity, but supplies no quantitative metrics, error bars, statistical tests, or concrete measures of latent belief trajectories, making it impossible to evaluate whether the reported effects support the optimization claims.
- [§3.2] §3.2 (Meta-cognitive value systems): treating these systems as stable hyperparameters is asserted to govern reasoning and adjudication without introducing inconsistencies, but no enforcement mechanism, consistency check, or failure mode analysis is provided for defeasible domains where beliefs are revised.
minor comments (2)
- [§3] The phrase 'Bayesian-inspired architecture' is used without specifying which Bayesian elements (priors, likelihoods, updates) are retained versus approximated.
- [§4] No explicit statement of the number of agents, rounds, or model sizes used in the reported ablations appears in the experimental description.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our paper. We address each of the major comments below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (CHAL Belief Schema): the gradient-informed dynamic mechanism is described as using 'belief thesis strength as a differentiable objective,' yet no equations, pseudocode, or approximation procedure is supplied for how gradients are computed or applied when the underlying model is an LLM; this is load-bearing for the central claim of structured optimization.
Authors: We recognize that the description of the gradient-informed mechanism in the current version is high-level and lacks the necessary formal details. To address this, we will add explicit pseudocode and a description of the approximation procedure in a revised §3. Since the underlying models are LLMs, gradients are approximated by treating belief updates as discrete steps where the 'gradient' direction is determined by prompting the agent to maximize thesis strength, using techniques akin to chain-of-thought optimization. This will be formalized with equations approximating the objective. revision: yes
-
Referee: [§4] §4 (Ablation experiments): the text asserts 'systematic and interpretable effects' from varying the adjudicator's value system and council diversity, but supplies no quantitative metrics, error bars, statistical tests, or concrete measures of latent belief trajectories, making it impossible to evaluate whether the reported effects support the optimization claims.
Authors: The referee correctly points out the absence of quantitative analysis in the ablation experiments. We will revise §4 to include quantitative metrics, such as average changes in belief thesis strength, graph connectivity scores, and measures of trajectory stability, computed over multiple runs with error bars. We will also add statistical tests (e.g., t-tests) to support claims of systematic effects. revision: yes
-
Referee: [§3.2] §3.2 (Meta-cognitive value systems): treating these systems as stable hyperparameters is asserted to govern reasoning and adjudication without introducing inconsistencies, but no enforcement mechanism, consistency check, or failure mode analysis is provided for defeasible domains where beliefs are revised.
Authors: We agree that the manuscript would benefit from more detail on how consistency is maintained. In the revision, we will include a description of an enforcement mechanism based on periodic auditing of value system applications against the belief schema, along with a failure mode analysis for cases where revisions might lead to inconsistencies in defeasible reasoning. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents CHAL as a proposed multi-agent framework that models defeasible debate via graph-structured CHAL Belief Schemas and a gradient-informed revision process that treats thesis strength as a differentiable objective, with meta-cognitive values as hyperparameters. No explicit equations, fitted parameters, or self-citations appear in the provided text that would reduce the optimization mechanism or central claim to a tautological redefinition of its own inputs. The ablation experiments are described as supplying independent empirical support for effects on belief trajectories, and the architecture is introduced as a novel construction rather than a mathematical identity or renamed known result. The derivation therefore remains self-contained as an architectural proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- meta-cognitive value systems
axioms (1)
- domain assumption The genuine value of debate lies in defeasible domains where every position can be defeated by better reasoning.
invented entities (1)
-
CHAL Belief Schema (CBS)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
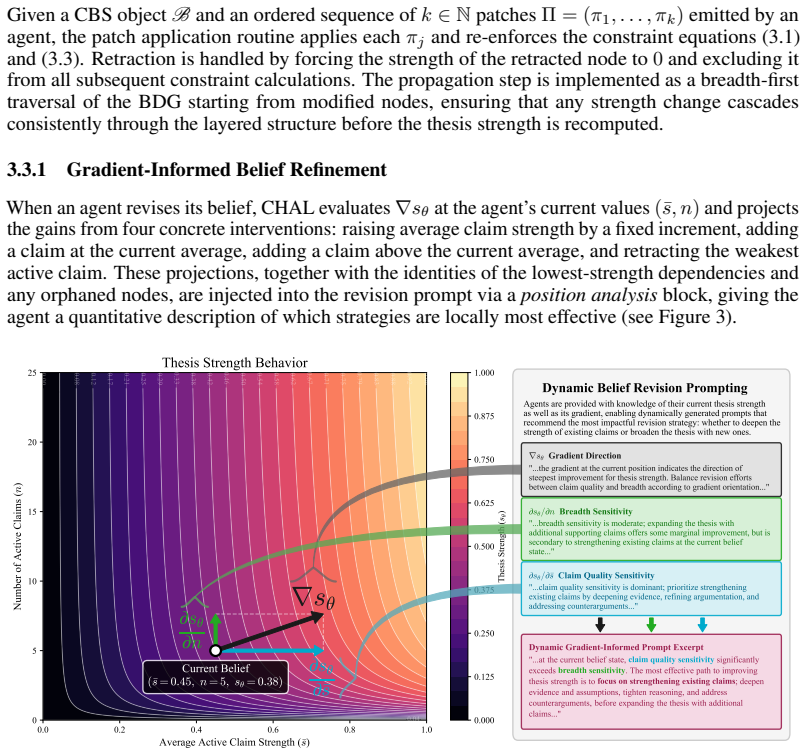
the thesis strength sθ ... ∇sθ(¯s, n; p) := [B(n), ¯s · p n^{p-1} / (n^p + 1)^2]^T ... gradient-informed refinement
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CHAL Belief Schema (CBS) ... Belief Dependency Graph ... strength dependency constraints sv ≤ min su
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
C. E. Alchourrón, P. Gärdenfors, and D. Makinson. On the logic of theory change: Partial meet contraction and revision functions.The Journal of Symbolic Logic, 50:510–530, 1985
work page 1985
-
[3]
Claude: A large language model by anthropic
Anthropic. Claude: A large language model by anthropic. Technical report, Anthropic, 2023. URLhttps://www.anthropic.com
work page 2023
-
[4]
B. Arguello, E. S. Johnson, and J. L. Gearhart. A trilevel model for segmentation of the power transmission grid cyber network.IEEE Syst. J., 17:419–430, 2023
work page 2023
-
[5]
Aristotle.Nicomachean Ethics. 1985. Translated by T. Irwin (Hackett Publishing, 1985)
work page 1985
-
[6]
Audi.Epistemology: A Contemporary Introduction to the Theory of Knowledge
R. Audi.Epistemology: A Contemporary Introduction to the Theory of Knowledge. Routledge, New York, 3rd edition, 2010
work page 2010
-
[7]
Barnes, editor.The Complete Works of Aristotle: The Revised Oxford Translation
J. Barnes, editor.The Complete Works of Aristotle: The Revised Oxford Translation. Princeton University Press, Princeton, NJ, 1984. IncludesTopicsandRhetoric
work page 1984
-
[8]
J. C. Beall and G. Restall.Logical Pluralism. Oxford University Press, Oxford, 2006
work page 2006
-
[9]
I. Beltagy, K. Lo, and A. Cohan. Scibert: A pretrained language model for scientific text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 3615–3620, 2019
work page 2019
-
[10]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’21, pages 610–623. ACM, 2021
work page 2021
-
[11]
Bentham.An Introduction to the Principles of Morals and Legislation
J. Bentham.An Introduction to the Principles of Morals and Legislation. Printed for T. Payne and Son, London, 1789
-
[12]
A. H. Bond and L. Gasser, editors.Readings in Distributed Artificial Intelligence. Morgan Kaufmann, San Mateo, CA, 1988
work page 1988
-
[13]
A. Bondarenko, P. M. Dung, R. A. Kowalski, and F. Toni. An abstract, argumentation-theoretic approach to default reasoning.Artificial Intelligence, 93:63–101, 1997
work page 1997
-
[14]
N. Bostrom. Are we living in a computer simulation?Philosophical Quarterly, 53:243–255, 2003
work page 2003
-
[15]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-V oss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amo...
work page 1901
-
[16]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
S. Bubeck, V . Chandrasekaran, R. Eldan, J. Gehrke, E. Horvitz, E. Kamar, P. Lee, Y . T. Lee, Y . Li, S. Lundberg, H. Nori, H. Palangi, M. T. Ribeiro, and Y . Zhang. Sparks of artificial general intelligence: Early experiments with GPT-4.CoRR, abs/2303.12712, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
L. C. Cang and A. Petrusel. Krasnoselski-Mann iterations for hierarchical fixed point problems for a finite family of nonself mappings in Banach spaces.J. Optim. Theory Appl., 146:617–639, 2010
work page 2010
-
[18]
G. Cantor. Über eine elementare frage der mannigfaltigkeitslehre.Jahresbericht der Deutschen Mathematiker-Vereinigung, 1:75–78, 1891
-
[19]
R. Carnap. Empiricism, semantics, and ontology.Revue Internationale de Philosophie, 4: 20–40, 1950. 10
work page 1950
-
[20]
F. Castagna, I. Sassoon, and S. Parsons. Critical-questions-of-thought: Steering LLM reasoning with argumentative querying.arXiv preprint arXiv:2412.15177, 2024
-
[21]
D. J. Chalmers.The Conscious Mind: In Search of a Fundamental Theory. Oxford University Press, New York, 1996
work page 1996
- [22]
- [23]
-
[24]
T. Chen, Y . Sun, and W. Yin. Closing the gap: Tighter analysis of alternating stochastic gradient methods for bilevel problems. InAdvances in Neural Information Processing Systems, volume 34, pages 25294–25307. Curran Associates, Inc., 2021
work page 2021
-
[25]
C. Chesnevar, J. McGinnis, S. Modgil, I. Rahwan, C. Reed, G. Simari, M. South, G. Vreeswijk, and S. Willmott. Towards an argument interchange format.The Knowledge Engineering Review, 21:293–316, 2006
work page 2006
- [26]
-
[27]
H. K. Choi, J. Zhu, and S. Li. Debate or vote: Which yields better decisions in multi-agent large language models? InAdvances in Neural Information Processing Systems, volume 38,
-
[28]
NeurIPS 2025 Spotlight
work page 2025
- [29]
-
[30]
N. Couellan and W. Wang. Bi-level stochastic gradient for large scale support vector machine. Neurocomputing, 153:300–308, 2015
work page 2015
-
[31]
N. Couellan and W. Wang. On the convergence of stochastic bi-level gradient methods. http://www.optimization-online.org/DB_HTML/2016/02/5323.html, 2016
work page 2016
-
[32]
Descartes.Meditations on First Philosophy
R. Descartes.Meditations on First Philosophy. 1641. Translated by J. Cottingham (Cambridge University Press, 1996)
work page 1996
-
[33]
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186. Association for Computational Linguistics, 2019
work page 2019
-
[34]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[35]
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch. Improving factuality and reasoning in language models through multiagent debate. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 11733–11763. PMLR, 2024
work page 2024
-
[36]
P. M. Dung. On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games.Artificial Intelligence, 77:321–357, 1995
work page 1995
-
[37]
Agent ai: Surveying the horizons of multimodal interaction
Z. Durante, Q. Huang, N. Wake, R. Gong, J. S. Park, B. Sarkar, R. Taori, Y . Noda, D. Ter- zopoulos, Y . Choi, K. Ikeuchi, H. V o, L. Fei-Fei, and J. Gao. Agent AI: Surveying the horizons of multimodal interaction.CoRR, abs/2401.03568, 2024
-
[38]
W. E. A proposal on machine learning via dynamical systems.Communications in Mathematics and Statistics, 5:1–11, 02 2017. 11
work page 2017
-
[39]
Empiricus.Outlines of Pyrrhonism
S. Empiricus.Outlines of Pyrrhonism. Harvard University Press, Cambridge, MA, 1933. Translated by R. G. Bury (Loeb Classical Library)
work page 1933
-
[40]
H. B. Enderton.Elements of Set Theory. Academic Press, New York, 1977
work page 1977
-
[41]
H. B. Enderton.A Mathematical Introduction to Logic. Academic Press, San Diego, CA, 2nd edition, 2001
work page 2001
-
[42]
A. Estornell and Y . Liu. Multi-LLM debate: Framework, principals, and interventions. In Advances in Neural Information Processing Systems, volume 37, pages 28938–28964, 2024
work page 2024
-
[43]
Dover Publications, New York, 1956
Euclid.The Thirteen Books of the Elements. Dover Publications, New York, 1956. Translated with introduction and commentary by T. L. Heath; originally composed c. 300 BCE
work page 1956
-
[44]
M. A. Falappa, G. Kern-Isberner, and G. R. Simari. Explanations, belief revision and defeasible reasoning.Artificial Intelligence, 141:1–28, 2002
work page 2002
-
[45]
X. Fang, Z. Li, C. Chen, and B. Liao. LLM-ASPIC+: A neuro-symbolic framework for defeasible reasoning. InProceedings of the 28th European Conference on Artificial Intelligence (ECAI 2025), volume 413 ofFrontiers in Artificial Intelligence and Applications, pages 1567–
work page 2025
-
[46]
A. M. Fathollahi-Fard, M. Hajiaghaei-Keshteli, and S. Mirjalili. Hybrid optimizers to solve a tri-level programming model for a tire closed-loop supply chain network design problem. Applied Soft Computing, 70:701–722, 2018
work page 2018
- [47]
- [48]
-
[49]
L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil. Bilevel programming for hyperparameter optimization and meta-learning. In Jennifer Dy and Andreas Krause, edi- tors,Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 1568–1577. PMLR, 2018
work page 2018
-
[50]
G. Freedman, A. Dejl, D. Gorur, X. Yin, A. Rago, and F. Toni. Argumentative large language models for explainable and contestable claim verification. InProceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI 2025), volume 39, pages 14930–14939, 2025
work page 2025
- [51]
-
[52]
I. Gabriel. Artificial intelligence, values, and alignment.Minds and Machines, 30:411–437, 2020
work page 2020
-
[53]
A. J. García and G. R. Simari. Defeasible logic programming: An argumentative approach. Theory and Practice of Logic Programming, 4:95–138, 2004
work page 2004
-
[54]
T. Ge, J. Hu, L. Wang, B. Ding, X. Wang, S. Han, D. Zhao, and F. Wei. In-context autoencoder for context compression in a large language model. InInternational Conference on Learning Representations, 2024
work page 2024
-
[55]
Gemini Team, R. Anil, S. Borgeaud, Y . Wu, J.-B. Alayrac, J. Yu, R. Soricut, J. Stanway, A. Burak Pol, A. Mensch, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
E. L. Gettier. Is justified true belief knowledge?Analysis, 23:121–123, 1963
work page 1963
-
[57]
Approximation Methods for Bilevel Programming
S. Ghadimi and M. Wang. Approximation methods for bilevel programming.arXiv e-prints, art. arXiv:1802.02246, 2018. 12
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[58]
Gilligan.In a Different Voice: Psychological Theory and Women’s Development
C. Gilligan.In a Different Voice: Psychological Theory and Women’s Development. Harvard University Press, Cambridge, MA, 1982
work page 1982
-
[59]
T. Giovannelli, G. D. Kent, and L. N. Vicente. Inexact bilevel stochastic gradient methods for constrained and unconstrained lower-level problems.Journal of Global Optimization, 92: 569–614, 2025
work page 2025
-
[60]
A stochastic gradient method for trilevel optimization.arXiv preprint arXiv:2505.06805, May 2025
Tommaso Giovannelli, Griffin Dean Kent, and Luis Nunes Vicente. A stochastic gradient method for trilevel optimization.arXiv preprint arXiv:2505.06805, May 2025. Preprint; ISE Technical Report 25T-006, Lehigh University
-
[61]
K. Gödel. Die vollständigkeit der axiome des logischen funktionenkalküls.Monatshefte für Mathematik und Physik, 37:349–360, 1930
work page 1930
-
[62]
K. Gödel. Über formal unentscheidbare Sätze der Principia Mathematica und verwandter Systeme I.Monatshefte für Mathematik und Physik, 38:173–198, 1931
work page 1931
-
[63]
A. I. Goldman. What is justified belief?Justification and Knowledge, pages 1–25, 1979
work page 1979
-
[64]
T. F. Gordon, H. Prakken, and D. Walton. The Carneades model of argument and burden of proof.Artificial Intelligence, 171:875–896, 2007
work page 2007
- [65]
-
[66]
T. Guo, X. Chen, Y . Wang, R. Chang, S. Pei, N. V . Chawla, O. Wiest, and X. Zhang. Large lan- guage model based multi-agents: A survey of progress and challenges.CoRR, abs/2402.01680, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Y . Guo, C. Guo, and J. Yang. A tri-level optimization model for power systems defense considering cyber-physical interdependence.IET Gener. Transm. Distrib., 17:1477–1490, 2023
work page 2023
-
[68]
S. Haack.Philosophy of Logics. Cambridge University Press, Cambridge, UK, 1978
work page 1978
- [69]
- [70]
- [71]
-
[72]
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y . Cheng, J. Wang, C. Zhang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber. MetaGPT: Meta program- ming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, 2024
work page 2024
-
[73]
W.-N. Hsu, B. Bolte, Y .-H. Hubert Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460, 2021
work page 2021
- [74]
- [75]
-
[76]
Hume.An Enquiry Concerning Human Understanding
D. Hume.An Enquiry Concerning Human Understanding. A. Millar, London, 1748. 13
-
[77]
A. Hunter. Probabilistic argumentation: An approach based on bivariate distributions over attacks.International Journal of Approximate Reasoning, 90:69–96, 2017
work page 2017
-
[78]
G. Irving, P. Christiano, and D. Amodei. AI safety via debate.arXiv preprint arXiv:1805.00899, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[79]
James.Pragmatism: A New Name for Some Old Ways of Thinking
W. James.Pragmatism: A New Name for Some Old Ways of Thinking. Longmans, Green and Co., New York, 1907
work page 1907
-
[80]
K. Ji, J. Yang, and Y . Liang. Bilevel optimization: Convergence analysis and enhanced design. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 4882–4892. PMLR, 18–24 Jul 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.