Recognition: 2 theorem links
· Lean TheoremUncovering Symmetry Transfer in Large Language Models via Layer-Peeled Optimization
Pith reviewed 2026-05-14 20:07 UTC · model grok-4.3
The pith
Symmetries in next-token targets transfer exactly to circulant logit matrices and equiangular structures in LLM weights and embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Symmetries in the target next-token distributions transfer to the global minimizers of the layer-peeled model in a group-theoretic sense: cyclic-shift symmetries make the optimal logit matrix exactly circulant and the relevant Gram matrices circulant, while exchangeable targets under the symmetric group make the optimal output projection matrix a simplex equiangular tight frame, with the logit matrix and context embeddings inheriting the permutation symmetries.
What carries the argument
The constrained layer-peeled optimization program that optimizes the output projection matrix and last-layer context embeddings to minimize cross-entropy loss as a surrogate for full LLM training.
If this is right
- Optimal output projections form simplex equiangular tight frames when targets are exchangeable under the symmetric group.
- Context embeddings and logits inherit the exact permutation symmetries of the input data distribution.
- The reduction of the nonconvex factorized problem to a convex logit-level characterization allows exact proofs for the cyclic and permutation cases.
- Open-source LLMs exhibit these circulant and equiangular geometries without any explicit symmetry-promoting regularization.
Where Pith is reading between the lines
- This transfer mechanism may underlie LLMs' ability to handle calendar or periodic reasoning tasks without special architectural provisions.
- Fine-tuning on data that breaks cyclic symmetry could be tested by measuring how far the logit matrix deviates from circulant form.
- The same symmetry analysis might extend to other group actions that appear in language data, such as spatial or temporal invariances.
Load-bearing premise
The constrained layer-peeled optimization serves as an accurate surrogate for the behavior of actual large language model training.
What would settle it
Measure the logit matrix entries for a cyclic set such as days of the week in a trained LLM and check whether off-diagonal entries that should be identical under cyclic shift differ by more than a small numerical tolerance.
Figures








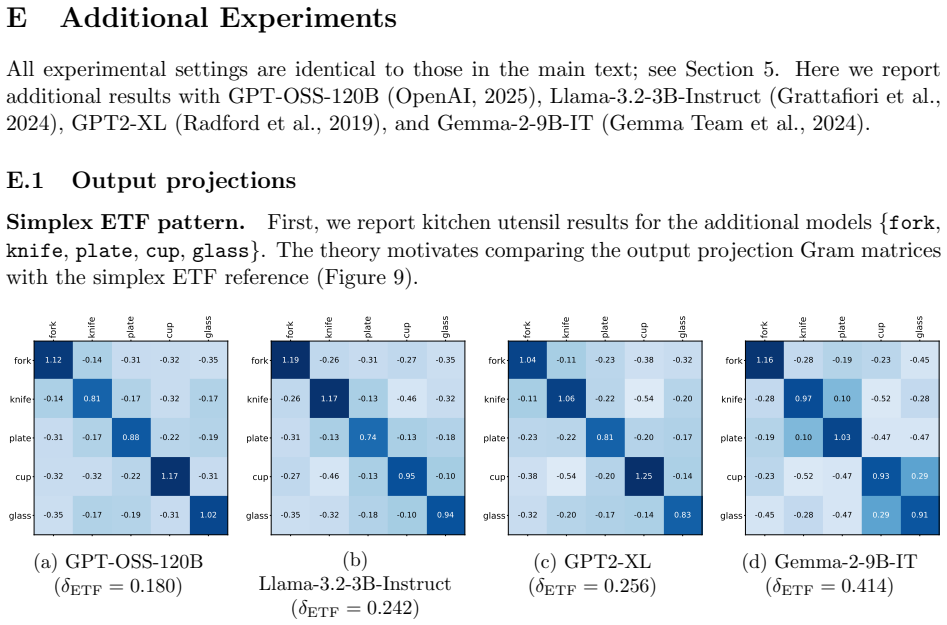













read the original abstract
Large language models (LLMs) are pretrained by minimizing the cross-entropy loss for next-token prediction. In this paper, we study whether this optimization strategy can induce geometric structure in the learned model weights and context embeddings. We approach this problem by analyzing a constrained layer-peeled optimization program, which serves as a mathematically tractable surrogate for LLMs by treating the output projection matrix and last-layer context embeddings as optimization variables. Our analysis of this nonconvex optimization program demonstrates that symmetries in the target next-token distributions are transferred to the global minimizers of the layer-peeled model in a precise group-theoretic sense. Specifically, we prove that when the target tokens exhibit a cyclic-shift symmetry (such as the seven days of the week or the twelve months of the year), the optimal logit matrix is exactly circulant, and the Gram matrices of both the output projections and the context embeddings form circulant geometries as well. Next, for exchangeable target distributions invariant under the symmetric group and, more generally, under two-transitive group actions, we show that the global optimal output projection matrix forms a simplex equiangular tight frame, while the optimal logit matrix and context embeddings inherit the permutation symmetries present in the input data. A key technical step is to reduce the constrained nonconvex factorized problem to an explicit logit-level convex characterization for cyclic symmetry and to a symmetry-based lower bound for permutation symmetry, together with a sharp characterization of the optimal factorization. Finally, we empirically demonstrate that open-source LLMs naturally exhibit symmetries consistent with our theoretical predictions, despite being trained without any explicit regularization promoting such geometric structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes a constrained layer-peeled optimization program as a surrogate for LLM pretraining under cross-entropy loss. It proves that cyclic-shift symmetries in target tokens induce exactly circulant optimal logit matrices and circulant Gram matrices for output projections and context embeddings; for exchangeable targets under symmetric-group or two-transitive actions, the optimal output projection is a simplex equiangular tight frame while logits and embeddings inherit the input permutation symmetries. The proofs reduce the nonconvex factorized program to a convex logit-level characterization (cyclic case) or symmetry-based lower bound (permutation case) with a sharp factorization characterization. Empirical checks on open-source LLMs confirm the predicted geometric structures appear without explicit regularization.
Significance. If the surrogate analysis holds and the empirical patterns are robust, the work supplies a group-theoretic mechanism explaining why certain geometric regularities emerge in LLM weights and embeddings from standard next-token training. The explicit convex reductions and the demonstration that real models exhibit the predicted circulant and ETF structures are concrete strengths that could guide future theoretical and architectural work on symmetry in transformers.
major comments (2)
- [§1] §1 and §2: the central claim that the optimization strategy induces geometric structure in LLMs rests on the layer-peeled surrogate treating W and H as free variables; no perturbation analysis, error bound, or lifting argument is supplied showing that the proven circulant or ETF properties survive when these quantities are instead outputs of the full transformer stack with gradients flowing through earlier layers.
- [§4.1] §4.1, Theorem 1: the reduction of the nonconvex program to an explicit logit-level convex characterization for cyclic symmetry is load-bearing for the exact-circulant claim, yet the manuscript does not verify that the optimal factorization recovered from the convex solution remains feasible and unique under the original nonconvex constraints when the target distribution is only approximately cyclic.
minor comments (2)
- [§3] Notation for the cyclic group action and the definition of circulant matrices could be introduced with a small concrete example (e.g., 7-day cycle) at the beginning of §3 to improve readability.
- [§5] The empirical section would benefit from a quantitative metric (e.g., Frobenius distance to the nearest circulant matrix) rather than qualitative visual inspection alone.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. The comments highlight important aspects of the surrogate model's scope and the robustness of the cyclic characterization. We address each major comment point by point below, indicating planned revisions to strengthen the presentation while preserving the core contributions.
read point-by-point responses
-
Referee: §1 and §2: the central claim that the optimization strategy induces geometric structure in LLMs rests on the layer-peeled surrogate treating W and H as free variables; no perturbation analysis, error bound, or lifting argument is supplied showing that the proven circulant or ETF properties survive when these quantities are instead outputs of the full transformer stack with gradients flowing through earlier layers.
Authors: We agree that the layer-peeled formulation is a deliberate surrogate that isolates the final-layer optimization under cross-entropy loss, treating the output projection and context embeddings as free variables. A rigorous perturbation or lifting analysis connecting the surrogate minimizers to the full transformer stack would indeed strengthen the transfer claim, but such an analysis lies outside the present scope because it would require controlling gradient flow through all preceding layers and attention mechanisms. In the revised manuscript we will expand the discussion in §2 to explicitly state the surrogate assumptions, their relation to standard LLM training, and the empirical evidence already provided in §5 that the predicted circulant and ETF structures appear in real open-source models. This addition clarifies the intended scope without overstating the theoretical reach. revision: partial
-
Referee: §4.1, Theorem 1: the reduction of the nonconvex program to an explicit logit-level convex characterization for cyclic symmetry is load-bearing for the exact-circulant claim, yet the manuscript does not verify that the optimal factorization recovered from the convex solution remains feasible and unique under the original nonconvex constraints when the target distribution is only approximately cyclic.
Authors: Theorem 1 establishes an exact convex reduction and sharp factorization characterization only for precisely cyclic target distributions. For approximately cyclic targets the exact circulant property is expected to degrade gracefully. To address the concern we will add a short numerical study (new paragraph in §4.1 together with an appendix figure) that perturbs the target distribution by small random shifts away from exact cyclicity, solves the convex logit-level program, recovers the factorization, and checks the residual violation of the original nonconvex constraints. The experiment will confirm that the recovered factors remain nearly feasible and that the circulant deviation scales with the perturbation size, thereby supporting robustness of the exact result. revision: yes
Circularity Check
No circularity: symmetry claims derived from explicit surrogate program and group theory
full rationale
The paper defines a constrained layer-peeled optimization program as a surrogate, then applies group theory and convex reduction techniques to prove that cyclic-shift symmetry in targets forces circulant structure in the optimal logit matrix and Gram matrices of W and H. The derivation chain consists of the stated nonconvex program, its reduction to logit-level convex characterization, and symmetry-based lower bounds; none of these steps reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations. Empirical checks on open-source LLMs are presented separately as validation and do not enter the proof. The central claims therefore remain independent of their inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The constrained layer-peeled optimization program is a valid surrogate for LLMs
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwhen the target tokens exhibit a cyclic-shift symmetry … the optimal logit matrix is exactly circulant, and the Gram matrices … form circulant geometries
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclearglobal optimal output projection matrix forms a simplex equiangular tight frame
Reference graph
Works this paper leans on
-
[1]
Expositiones Mathematicae , volume =
Carlsson, Marcus , title =. Expositiones Mathematicae , volume =. 2021 , doi =
2021
-
[2]
and Johnson, Charles R
Horn, Roger A. and Johnson, Charles R. , title =. 2012 , isbn =
2012
-
[3]
Serre, Jean-Pierre , title =. 1977 , publisher =. doi:10.1007/978-1-4684-9458-7 , isbn =
-
[4]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is All you Need , booktitle =. 2017 , publisher =
2017
-
[5]
Papyan, Vardan and Han, X. Y. and Donoho, David L. , title =. Proceedings of the National Academy of Sciences , volume =. 2020 , doi =
2020
-
[6]
, title =
Ji, Wenlong and Lu, Yiping and Zhang, Yiliang and Deng, Zhun and Su, Weijie J. , title =. International Conference on Learning Representations , year =
-
[7]
A Geometric Analysis of Neural Collapse with Unconstrained Features , volume =
Zhu, Zhihui and Ding, Tianyu and Zhou, Jinxin and Li, Xiao and You, Chong and Sulam, Jeremias and Qu, Qing , booktitle =. A Geometric Analysis of Neural Collapse with Unconstrained Features , volume =
-
[8]
OpenAI Technical Report , year=
Improving Language Understanding by Generative Pre-Training , author=. OpenAI Technical Report , year=
- [9]
-
[10]
First Conference on Language Modeling , year =
Zhao, Yize and Behnia, Tina and Vakilian, Vala and Thrampoulidis, Christos , title =. First Conference on Language Modeling , year =
-
[11]
The First Workshop on the Interplay of Model Behavior and Model Internals , year =
On the Geometry of Semantics in Next-token Prediction , author =. The First Workshop on the Interplay of Model Behavior and Model Internals , year =
-
[12]
and Parshall, Hans and Pi, Jianzong , title =
Mixon, Dustin G. and Parshall, Hans and Pi, Jianzong , title =. Sampling Theory, Signal Processing, and Data Analysis , volume =. 2022 , publisher =. doi:10.1007/s43670-022-00027-5 , issn =
-
[13]
, title =
Fang, Cong and He, Hangfeng and Long, Qi and Su, Weijie J. , title =. Proceedings of the National Academy of Sciences , volume =. 2021 , doi =
2021
-
[14]
2002 , month =
Fazel, Maryam , title =. 2002 , month =
2002
-
[15]
The Prevalence of Neural Collapse in Neural Multivariate Regression , booktitle =
Andriopoulos, George and Dong, Zixuan and Guo, Li and Zhao, Zifan and Ross, Keith , editor =. The Prevalence of Neural Collapse in Neural Multivariate Regression , booktitle =. 2024 , publisher =
2024
-
[16]
Imbalance Trouble: Revisiting Neural-Collapse Geometry , booktitle =
Thrampoulidis, Christos and Kini, Ganesh Ramachandra and Vakilian, Vala and Behnia, Tina , editor =. Imbalance Trouble: Revisiting Neural-Collapse Geometry , booktitle =. 2022 , publisher =
2022
-
[17]
, editor =
Rangamani, Akshay and Lindegaard, Marius and Galanti, Tomer and Poggio, Tomaso A. , editor =. Feature learning in deep classifiers through Intermediate Neural Collapse , booktitle =. 2023 , month =
2023
-
[18]
, title =
He, Hangfeng and Su, Weijie J. , title =. Proceedings of the National Academy of Sciences , volume =. 2023 , doi =
2023
-
[19]
Han, X. Y. and Papyan, Vardan and Donoho, David L. , title =. International Conference on Learning Representations , year =
-
[20]
On the Optimization Landscape of Neural Collapse under
Zhou, Jinxin and Li, Xiao and Ding, Tianyu and You, Chong and Qu, Qing and Zhu, Zhihui , editor =. On the Optimization Landscape of Neural Collapse under. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , month =
2022
-
[21]
Are All Losses Created Equal: A Neural Collapse Perspective , booktitle =
Zhou, Jinxin and You, Chong and Li, Xiao and Liu, Kangning and Liu, Sheng and Qu, Qing and Zhu, Zhihui , editor =. Are All Losses Created Equal: A Neural Collapse Perspective , booktitle =. 2022 , publisher =
2022
-
[22]
Neural Collapse in Deep Linear Networks: From Balanced to Imbalanced Data , booktitle =
Dang, Hien and Huu, Tho Tran and Osher, Stanley and Tran, Hung The and Ho, Nhat and Nguyen, Tan Minh , editor =. Neural Collapse in Deep Linear Networks: From Balanced to Imbalanced Data , booktitle =. 2023 , month =
2023
-
[23]
Neural Networks , volume =
Hornik, Kurt and Stinchcombe, Maxwell and White, Halbert , title =. Neural Networks , volume =. 1989 , doi =
1989
-
[24]
Linguistic Collapse: Neural Collapse in (Large) Language Models , booktitle =
Wu, Robert and Papyan, Vardan , editor =. Linguistic Collapse: Neural Collapse in (Large) Language Models , booktitle =. 2024 , publisher =
2024
-
[25]
He, Hangfeng and Su, Weijie J. , title =. Physical Review E , volume =. 2025 , month =. doi:10.1103/5rn3-49lc , numpages =
-
[26]
Wide Neural Networks Trained with Weight Decay Provably Exhibit Neural Collapse , booktitle =
Jacot, Arthur and S. Wide Neural Networks Trained with Weight Decay Provably Exhibit Neural Collapse , booktitle =
-
[27]
, title =
Garrod, Connall and Keating, Jonathan P. , title =. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year =
-
[28]
, editor =
Zaheer, Manzil and Kottur, Satwik and Ravanbakhsh, Siamak and Poczos, Barnabas and Salakhutdinov, Ruslan and Smola, Alexander J. , editor =. Deep Sets , booktitle =. 2017 , publisher =
2017
-
[29]
Group Equivariant Convolutional Networks , booktitle =
Cohen, Taco and Welling, Max , editor =. Group Equivariant Convolutional Networks , booktitle =. 2016 , month =
2016
-
[30]
International Conference on Learning Representations , year =
Sun, Zhiqing and Deng, Zhi-Hong and Nie, Jian-Yun and Tang, Jian , title =. International Conference on Learning Representations , year =
-
[31]
, title =
Strohmer, Thomas and Heath, Robert W. , title =. Applied and Computational Harmonic Analysis , volume =. 2003 , doi =
2003
-
[32]
and Furnas, George W
Deerwester, Scott and Dumais, Susan T. and Furnas, George W. and Landauer, Thomas K. and Harshman, Richard , title =. Journal of the American Society for Information Science , volume =. 1990 , doi =
1990
-
[33]
A Neural Probabilistic Language Model , journal =
Bengio, Yoshua and Ducharme, R. A Neural Probabilistic Language Model , journal =
-
[34]
and Dean, Jeff , editor =
Mikolov, Tomas and Sutskever, Ilya and Chen, Kai and Corrado, Greg S. and Dean, Jeff , editor =. Distributed Representations of Words and Phrases and their Compositionality , booktitle =. 2013 , publisher =
2013
-
[35]
Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (
Pennington, Jeffrey and Socher, Richard and Manning, Christopher , editor =. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (. 2014 , month =
2014
-
[36]
Neural Word Embedding as Implicit Matrix Factorization , booktitle =
Levy, Omer and Goldberg, Yoav , editor =. Neural Word Embedding as Implicit Matrix Factorization , booktitle =. 2014 , publisher =
2014
-
[37]
A Latent Variable Model Approach to
Arora, Sanjeev and Li, Yuanzhi and Liang, Yingyu and Ma, Tengyu and Risteski, Andrej , editor =. A Latent Variable Model Approach to. Transactions of the Association for Computational Linguistics , volume =. 2016 , publisher =
2016
-
[38]
The Linear Representation Hypothesis and the Geometry of Large Language Models , booktitle =
Park, Kiho and Choe, Yo Joong and Veitch, Victor , editor =. The Linear Representation Hypothesis and the Geometry of Large Language Models , booktitle =. 2024 , month =
2024
-
[39]
The Thirteenth International Conference on Learning Representations , year =
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author =. The Thirteenth International Conference on Learning Representations , year =
-
[40]
gpt-oss-120b & gpt-oss-20b Model Card
2025 , doi =. 2508.10925 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
and Wu, Tianyi and Wuttke, Daniel and Zhou-Zheng, Christian , title =
Peng, Bo and Zhang, Ruichong and Goldstein, Daniel and Alcaide, Eric and Du, Xingjian and Hou, Haowen and Lin, Jiaju and Liu, Jiaxing and Lu, Janna and Merrill, William and Song, Guangyu and Tan, Kaifeng and Utpala, Saiteja and Wilce, Nathan and Wind, Johan S. and Wu, Tianyi and Wuttke, Daniel and Zhou-Zheng, Christian , title =. Second Conference on Lang...
-
[42]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Renard Lavaud, L. Mistral. 2023 , doi =. 2310.06825 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
2019 , publisher =
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , title =. 2019 , publisher =
2019
-
[44]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and others , title =. 2024 , doi =. 2407.21783 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Gemma 2: Improving Open Language Models at a Practical Size
2024 , doi =. 2408.00118 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Extended Unconstrained Features Model for Exploring Deep Neural Collapse , booktitle =
Tirer, Tom and Bruna, Joan , editor =. Extended Unconstrained Features Model for Exploring Deep Neural Collapse , booktitle =. 2022 , month =
2022
-
[47]
Journal of Machine Learning Research , volume =
Diamond, Steven and Boyd, Stephen , title =. Journal of Machine Learning Research , volume =
-
[48]
How Contextual are Contextualized Word Representations? Comparing the Geometry of
Ethayarajh, Kawin , editor =. How Contextual are Contextualized Word Representations? Comparing the Geometry of. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =. 2019 , month =
2019
-
[49]
International Conference on Learning Representations , year =
Mu, Jiaqi and Viswanath, Pramod , title =. International Conference on Learning Representations , year =
-
[50]
2022 , eprint =
Elhage, Nelson and Hume, Tristan and Olsson, Catherine and Schiefer, Nicholas and Henighan, Tom and Kravec, Shauna and Hatfield-Dodds, Zac and Lasenby, Robert and Drain, Dawn and Chen, Carol and others , title =. 2022 , eprint =
2022
-
[51]
The Fourteenth International Conference on Learning Representations , year =
From Data Statistics to Feature Geometry: How Correlations Shape Superposition , author =. The Fourteenth International Conference on Learning Representations , year =
-
[52]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and others , title =. 2025 , doi =. 2310.01405 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Zhong, Zexuan and Wu, Zhengxuan and Manning, Christopher and Potts, Christopher and Chen, Danqi , editor =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , month =
2023
-
[54]
Advances in Neural Information Processing Systems , volume =
Belrose, Nora and Schneider-Joseph, David and Ravfogel, Shauli and Cotterell, Ryan and Raff, Edward and Biderman, Stella , editor =. Advances in Neural Information Processing Systems , volume =. 2023 , publisher =
2023
-
[55]
The Eleventh International Conference on Learning Representations , year =
Burns, Collin and Ye, Haotian and Klein, Dan and Steinhardt, Jacob , title =. The Eleventh International Conference on Learning Representations , year =
-
[56]
The Internal State of an
Azaria, Amos and Mitchell, Tom , editor =. The Internal State of an. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages =. 2023 , month =
2023
-
[57]
Journal of Control and Decision , volume =
Agrawal, Akshay and Verschueren, Robin and Diamond, Steven and Boyd, Stephen , title =. Journal of Control and Decision , volume =. 2018 , publisher =
2018
-
[58]
Implicit Optimization Bias of Next-token Prediction in Linear Models , booktitle =
Thrampoulidis, Christos , editor =. Implicit Optimization Bias of Next-token Prediction in Linear Models , booktitle =. 2024 , publisher =
2024
-
[59]
The Fourteenth International Conference on Learning Representations , year =
Sequences of Logits Reveal the Low Rank Structure of Language Models , author =. The Fourteenth International Conference on Learning Representations , year =
-
[60]
Lost in backpropagation: The lm head is a gradient bottleneck
Nathan Godey and Yoav Artzi , year =. Lost in Backpropagation: The. 2603.10145 , archivePrefix =
-
[61]
and Nava, Andres and Wyart, Matthieu and Bahri, Yasaman , title =
Karkada, Dhruva and Korchinski, Daniel J. and Nava, Andres and Wyart, Matthieu and Bahri, Yasaman , title =. 2026 , doi =. 2602.15029 , archivePrefix =
-
[62]
2025 , eprint =
The Origins of Representation Manifolds in Large Language Models , author =. 2025 , eprint =
2025
-
[63]
and Liao, Isaac and Gurnee, Wes and Tegmark, Max , title =
Engels, Joshua and Michaud, Eric J. and Liao, Isaac and Gurnee, Wes and Tegmark, Max , title =. The Thirteenth International Conference on Learning Representations , year =
-
[64]
Successor Heads: Recurring, Interpretable Attention Heads In The Wild , booktitle =
Gould, Rhys and Ong, Euan and Ogden, George and Conmy, Arthur , editor =. Successor Heads: Recurring, Interpretable Attention Heads In The Wild , booktitle =
-
[65]
The Eleventh International Conference on Learning Representations , year =
Nanda, Neel and Chan, Lawrence and Lieberum, Tom and Smith, Jess and Steinhardt, Jacob , title =. The Eleventh International Conference on Learning Representations , year =
-
[66]
A Toy Model of Universality: Reverse Engineering how Networks Learn Group Operations , booktitle =
Chughtai, Bilal and Chan, Lawrence and Nanda, Neel , editor =. A Toy Model of Universality: Reverse Engineering how Networks Learn Group Operations , booktitle =. 2023 , month =
2023
-
[67]
Transformer Circuits Thread , year =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and DasSarma, Nova and Drain, Dawn and Ganguli, Deep and Hatfield-Dodds, Zac and Hernandez, Danny and Jones, Andy and Kernion, Jackson and Lovitt, Liane and Ndousse, Kamal and Amodei, ...
-
[68]
Analyzing Transformers in Embedding Space , booktitle =
Dar, Guy and Geva, Mor and Gupta, Ankit and Berant, Jonathan , editor =. Analyzing Transformers in Embedding Space , booktitle =. 2023 , month = jul, publisher =
2023
-
[69]
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , booktitle =
Geva, Mor and Caciularu, Avi and Wang, Kevin and Goldberg, Yoav , editor =. Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , booktitle =. 2022 , month = dec, publisher =
2022
-
[70]
Transformer Feed-Forward Layers Are Key-Value Memories , booktitle =
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer , editor =. Transformer Feed-Forward Layers Are Key-Value Memories , booktitle =. 2021 , month = nov, publisher =
2021
-
[71]
How does
Hanna, Michael and Liu, Ollie and Variengien, Alexandre , editor =. How does. Advances in Neural Information Processing Systems , volume =. 2023 , publisher =
2023
-
[72]
2025 , eprint =
Belrose, Nora and Ostrovsky, Igor and McKinney, Lev and Furman, Zach and Smith, Logan and Halawi, Danny and Biderman, Stella and Steinhardt, Jacob , title =. 2025 , eprint =
2025
-
[73]
, title =
Guo, Li and Andriopoulos, George and Zhao, Zifan and Dong, Zixuan and Ling, Shuyang and Ross, Keith W. , title =. Transactions on Machine Learning Research , issn =
-
[74]
The Twelfth International Conference on Learning Representations , year =
Fisher, Quinn LeBlanc and Meng, Haoming and Papyan, Vardan , title =. The Twelfth International Conference on Learning Representations , year =
-
[75]
Burer, Samuel and Monteiro, Renato D. C. , title =. Mathematical Programming , volume =. 2003 , month = feb, day =
2003
-
[76]
Burer, Samuel and Monteiro, Renato D. C. , title =. Mathematical Programming , volume =. 2005 , month = jul, day =
2005
-
[77]
The non-convex
Boumal, Nicolas and Voroninski, Vlad and Bandeira, Afonso , editor =. The non-convex. Advances in Neural Information Processing Systems , volume =. 2016 , publisher =
2016
-
[78]
Rank Optimality for the
Waldspurger, Ir. Rank Optimality for the. SIAM Journal on Optimization , volume =. 2020 , doi =
2020
-
[79]
, title =
Recht, Benjamin and Fazel, Maryam and Parrilo, Pablo A. , title =. SIAM Review , volume =. 2010 , doi =
2010
-
[80]
IEEE Transactions on Information Theory , volume =
Sun, Ruoyu and Luo, Zhi-Quan , title =. IEEE Transactions on Information Theory , volume =. 2016 , keywords =
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.