Recognition: unknown
Synthesizing the Expert: A Validated Multimodal Dataset for Trustworthy AI-Assisted Swimming Coaching
Pith reviewed 2026-05-14 19:25 UTC · model grok-4.3
The pith
A multi-agent LLM system generates a validated dataset of 1,864 triplets to serve as ground truth for trustworthy AI swimming coaching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
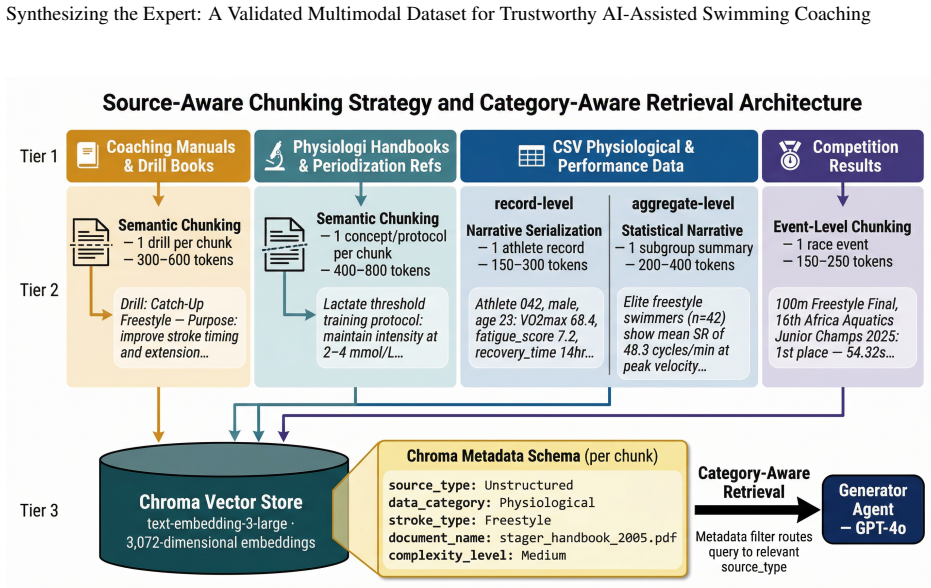
The authors build a multimodal knowledge base spanning physiological data, literature, kinematic sensor readings, and unstructured expertise, then apply a multi-agent LLM architecture to synthesize 1,864 validated Question-Context-Answer triplets from 1,914 initial drafts. Each triplet is evaluated against twelve internal physiological soundness rules to ensure fidelity, thereby creating a structured synthetic ground truth that functions as a foundational benchmark for trustworthy AI-assisted swimming coaching.
What carries the argument
Multi-agent LLM architecture that generates drafts from a four-dimensional multimodal knowledge base and filters them against twelve physiological soundness rules to produce validated triplets.
If this is right
- AI systems can draw on the triplets to deliver grounded advice on technique correction and training periodization.
- Real-time coaching applications gain a reference set that reduces reliance on scarce or restricted real-world data.
- Meta-agent frameworks for athletic profiling can be developed and tested using the structured triplets as input.
- The method lowers the cost and ethical hurdles of creating training material for sports-science AI.
- Future RAG systems in aquatics can use the dataset to improve output credibility and context awareness.
Where Pith is reading between the lines
- The same generative pipeline could be reused in other sports where biometric data collection is restricted.
- Developers might first validate new coaching models on the synthetic triplets before exposing them to live athletes.
- The dataset opens a route to compare LLM-generated advice against traditional coaching logs without needing fresh data collection.
- Scaling the approach to include video or wearable streams could further reduce dependence on manual expert annotation.
Load-bearing premise
Internal checks against the twelve soundness rules are sufficient to guarantee that the generated triplets remain physiologically accurate without comparison to real athlete performance outcomes.
What would settle it
Testing whether swimmers who follow advice derived from the triplets show measurable performance changes that match or contradict the synthetic answers would confirm or refute the dataset's accuracy.
Figures



read the original abstract
This research is primarily concerned with the critical problem of synthesizing a structured Retrieval-Augmented Generation (RAG) system for advanced AI applications in the domain of swimming. As the integration of Artificial Intelligence in sports science matures, its applications in swimming have become increasingly diverse, spanning from real-time technical coaching and talent scouting to comprehensive performance profiling and the dynamic personalization of training periodization. Within this landscape, RAG-based systems represent a pivotal advancement in Large Language Model (LLM) enhanced swimming analysis, as they allow for the grounding of generative outputs in authoritative domain knowledge, thereby ensuring the credibility of AI-generated advice, contextually and technically. Despite this potential, building robust RAG systems using only real-world aquatic data presents significant challenges, including ethical constraints regarding athlete biometrics, and the high cost of manual expert labeling. To address these barriers, we propose a novel generative framework that leverages a multimodal knowledge base gathered across four dimensions: physiological data, physiological literature, kinematic sensor data, and unstructured domain expertise. Our proposed framework utilizes a multi-agent LLM architecture to synthesize a high-fidelity dataset of 1,864 validated "Question-Context-Answer" triplets-drawn from 1,914 drafts evaluated against 12 physiological soundness rules. By providing a structured, synthetic ground truth, this work establishes a foundational benchmark for trustworthy AI in aquatics. The outcomes of this research promise to enhance the reliability of automated coaching and open a plethora of future directions in "Meta-Agent" development and athletic profiling, ultimately bridging the gap between raw data engineering and practical sports science application.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multi-agent LLM framework to synthesize a multimodal dataset of 1,864 Question-Context-Answer triplets for swimming coaching. Triplets are drawn from physiological data, literature, kinematic sensors, and domain expertise; 1,914 drafts are filtered via 12 internal physiological soundness rules to produce a synthetic ground-truth benchmark for trustworthy RAG-based AI coaching systems.
Significance. If the triplets prove physiologically accurate beyond the internal rules and the dataset is externally validated, the work could supply a reusable benchmark resource that addresses ethical and cost barriers to real athlete data in aquatics AI, enabling reproducible testing of coaching agents and meta-agent extensions.
major comments (3)
- [Abstract] Abstract: the claim that 1,864 triplets constitute a 'validated' ground truth after evaluation against 12 physiological soundness rules is unsupported because the rules are never enumerated, no quantitative fidelity metrics (e.g., pass rates, inter-rule agreement, or error distributions) are reported, and no comparison to real kinematic or performance data is shown.
- [Methods] Methods (multi-agent architecture description): the validation procedure reduces to an internal consistency check against rules defined inside the framework; without an external grounding step (e.g., blinded expert rating against observed athlete recordings or hold-out sensor metrics), the central claim that the triplets remain physiologically accurate cannot be evaluated.
- [Results] Results / Evaluation: no table or figure reports agreement between synthetic triplets and real-world swimming performance data (stroke mechanics, energy-system thresholds, injury-risk indicators), leaving the benchmark utility for trustworthy AI unproven.
minor comments (2)
- [Abstract] Abstract: the sentence 'open a plethora of future directions' is vague; replace with concrete examples such as specific meta-agent tasks or profiling metrics.
- [Introduction] Notation: ensure RAG and LLM are expanded on first use and that 'triplet' is defined consistently as Question-Context-Answer throughout.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that greater transparency is needed regarding the validation rules and metrics, and we will revise the manuscript to address these points while clarifying the synthetic nature of the benchmark. Point-by-point responses to the major comments are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 1,864 triplets constitute a 'validated' ground truth after evaluation against 12 physiological soundness rules is unsupported because the rules are never enumerated, no quantitative fidelity metrics (e.g., pass rates, inter-rule agreement, or error distributions) are reported, and no comparison to real kinematic or performance data is shown.
Authors: We agree that the abstract and main text do not enumerate the 12 rules or report quantitative metrics. In the revised manuscript, we will add a table in the Methods section explicitly listing all 12 physiological soundness rules, report the pass rate (1,864 out of 1,914 drafts), inter-rule agreement statistics where applicable, and error distributions. We will also include a brief discussion of how the rules are grounded in established swimming physiology literature to address the comparison aspect, while noting the intentional synthetic design. revision: yes
-
Referee: [Methods] Methods (multi-agent architecture description): the validation procedure reduces to an internal consistency check against rules defined inside the framework; without an external grounding step (e.g., blinded expert rating against observed athlete recordings or hold-out sensor metrics), the central claim that the triplets remain physiologically accurate cannot be evaluated.
Authors: The referee is correct that validation is internal. We will revise the Methods section to provide additional detail on how the multi-agent architecture and rules incorporate cross-verification and are derived from physiological literature and sensor inputs. We will add an explicit limitations paragraph acknowledging the lack of external blinded expert validation and position this as an avenue for future work to further strengthen trustworthiness claims. revision: partial
-
Referee: [Results] Results / Evaluation: no table or figure reports agreement between synthetic triplets and real-world swimming performance data (stroke mechanics, energy-system thresholds, injury-risk indicators), leaving the benchmark utility for trustworthy AI unproven.
Authors: We will add a new table in the Results section that quantitatively maps triplet elements to standard physiological benchmarks from the literature (e.g., stroke mechanics, energy-system thresholds). This will better demonstrate alignment with domain knowledge. Direct comparisons to specific real-world athlete recordings remain outside the current synthetic scope due to ethical and access constraints, but the added table will strengthen the benchmark utility argument. revision: partial
- Direct external validation via blinded expert ratings against observed athlete recordings or hold-out sensor metrics, which would require new data collection beyond the synthetic generation focus of this study.
Circularity Check
Internal 12-rule validation defines benchmark fidelity by construction
specific steps
-
self definitional
[Abstract]
"Our proposed framework utilizes a multi-agent LLM architecture to synthesize a high-fidelity dataset of 1,864 validated 'Question-Context-Answer' triplets-drawn from 1,914 drafts evaluated against 12 physiological soundness rules. By providing a structured, synthetic ground truth, this work establishes a foundational benchmark for trustworthy AI in aquatics."
The triplets receive the labels 'validated' and 'ground truth' exclusively because they satisfy 12 soundness rules defined within the same generative framework. The benchmark's claimed trustworthiness is therefore equivalent to the internal rules by construction, with no external physiological validation step provided to break the self-reference.
full rationale
The paper's central claim is that the 1,864 synthetic Q-C-A triplets constitute a validated ground-truth benchmark. This status is assigned solely by passing 12 physiological soundness rules created inside the multi-agent LLM framework. No external comparison to real kinematic data, athlete metrics, or blinded expert ratings is described, so the 'validated' and 'high-fidelity' properties reduce directly to the authors' internal consistency checks rather than independent physiological grounding. This is a clear self-definitional reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The twelve physiological soundness rules are sufficient to certify the accuracy of generated swimming-coaching advice.
invented entities (1)
-
Multi-agent LLM architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wearables in swimming for real-time feedback: A systematic review.Sensors, 22(10):3677, 2022
Jorge E Morais, João P Oliveira, Tatiana Sampaio, and Tiago M Barbosa. Wearables in swimming for real-time feedback: A systematic review.Sensors, 22(10):3677, 2022
work page 2022
-
[2]
Ryan Keating, Rodney Kennedy, and Carla McCabe. Longitudinal monitoring of load-velocity variables in preferred-stroke and front-crawl with national and international swimmers.Frontiers in Sports and Active Living, 7:1585319, 2025
work page 2025
-
[3]
Big data analytics framework for decision-making in sports performance optimization
Dan Cristian M˘anescu. Big data analytics framework for decision-making in sports performance optimization. Data, 10(7):116, 2025
work page 2025
-
[4]
Fabian Hammes, Alexander Hagg, Alexander Asteroth, and Daniel Link. Artificial intelligence in elite sports—a narrative review of success stories and challenges.Frontiers in sports and active living, 4:861466, 2022
work page 2022
-
[5]
Ting Xu and S Baghaei. Reshaping the future of sports with artificial intelligence: Challenges and opportunities in performance enhancement, fan engagement, and strategic decision-making.Engineering Applications of Artificial Intelligence, 142:109912, 2025
work page 2025
-
[6]
The game changer: How artificial intelligence is transforming sports performance and strategy
Andrea Pisaniello. The game changer: How artificial intelligence is transforming sports performance and strategy. Geopolitical, Social Security and Freedom Journal, 7(1):75–84, 2024
work page 2024
-
[7]
Ari Tri Fitrianto, Oddie Barnanda Rizky, Edi Rahmadi, and Asary Ramadhan. A systematic literature review of swimming performance prediction: methods, datasets, techniques and research trends.Retos, 67:482–497, 2025
work page 2025
-
[8]
Minal Patil, RH Goudar, and Geetabai S Hukkeri. Ai for swimming recommendation systems exploring the current landscape and research opportunities.Discover Applied Sciences, 2025
work page 2025
-
[9]
Luca Puce, Piotr ˙Zmijewski, Filippo Cotellessa, Cristina Schenone, Halil I Ceylan, Nicola L Bragazzi, and Carlo Trompetto. The role of artificial intelligence in sports training: opportunities, challenges and future applications for competitive swimming.Biology of Sport, 43(1):355–367, 2025
work page 2025
-
[10]
Jun Woo Kwon. Athlete data sovereignty: addressing the legal and policy gaps in sports technology.Frontiers in Sports and Active Living, 7:1742484, 2025
work page 2025
-
[11]
Zhengliang Wu. Personalized skill transfer optimization in swimming training through multi-agent reinforcement learning driven digital twin environments.Scientific Reports, 2026
work page 2026
-
[12]
HAO Kechun and Bin Wang. Retrieval-augmented generation in healthcare: A narrative review of methods, contributions, and future directions.Digital Medicine, 12(1):e25–00015, 2026
work page 2026
-
[13]
David J Bunnell, Mary J Bondy, Lucy M Fromtling, Emilie Ludeman, and Krishnaj Gourab. Bridging ai and healthcare: a scoping review of retrieval-augmented generation—ethics, bias, transparency, improvements, and applications.medRxiv, pages 2025–04, 2025
work page 2025
-
[14]
Felipe JJ Reis, Rafael Krasic Alaiti, Caio Sain Vallio, and Luiz Hespanhol. Artificial intelligence and machine learning approaches in sports: Concepts, applications, challenges, and future perspectives.Brazilian journal of physical therapy, 28(3):101083, 2024
work page 2024
-
[15]
Wenxi Li, Moran Liu, Jiaxin Liu, Baosheng Zhang, Tao Yu, Yuchen Guo, and Qionghai Dai. A review of artificial intelligence for sports: Technologies and applications.Intelligent Sports and Health, 1(3):113–126, 2025
work page 2025
-
[16]
Indrajeet Ghosh, Sreenivasan Ramasamy Ramamurthy, Avijoy Chakma, and Nirmalya Roy. Sports analytics review: Artificial intelligence applications, emerging technologies, and algorithmic perspective.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 13(5):e1496, 2023
work page 2023
-
[17]
Jordan Chipka, Chris Moyer, Clay Troyer, Tyler Fuelling, and Jeremy Hochstedler. Gridmind: A multi-agent nlp framework for unified, cross-modal nfl data insights.arXiv preprint arXiv:2504.08747, 2025
-
[18]
Wenbo Tian, Ruting Lin, Hongxian Zheng, Yaodong Yang, Geng Wu, Zihao Zhang, and Zhang Zhang. Sportsgpt: An llm-driven framework for interpretable sports motion assessment and training guidance.arXiv preprint arXiv:2512.14121, 2025. 1https://paper-banana.org/ 14 Synthesizing the Expert: A Validated Multimodal Dataset for Trustworthy AI-Assisted Swimming Coaching
-
[19]
Cristian Comendant. Large language model-based sport coaching system using retrieval-augmented generation and user models.BS thesis, 2024
work page 2024
-
[20]
John Warmenhoven, Franco M Impellizzeri, Ian Shrier, Andrew D Vigotsky, Lorenzo Lolli, Paolo Menaspà, Aaron J Coutts, Maurizio Fanchini, and Giles Hooker. Synthetic data for sharing and exploration in high- performance sport: Considerations for application: J. warmenhoven et al.Sports Medicine, 55(8):2019–2037, 2025
work page 2019
-
[21]
Satizábal, and Andres Perez-Uribe
Benoît Hohl, Héctor F. Satizábal, and Andres Perez-Uribe. Unveiling the potential of synthetic data in sports science: A comparative study of generative methods. InInternational Conference on Artificial Neural Networks, pages 162–175. Springer, 2024
work page 2024
-
[22]
Mauricio C Cordeiro, Ciaran O Cathain, Lorcan Daly, David T Kelly, and Thiago B Rodrigues. A synthetic data-driven machine learning approach for athlete performance attenuation prediction.Frontiers in sports and active living, 7:1607600, 2025. 15
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.