Recognition: 2 theorem links
· Lean TheoremCRePE: Curved Ray Expectation Positional Encoding for Unified-Camera-Controlled Video Generation
Pith reviewed 2026-05-14 20:02 UTC · model grok-4.3
The pith
CRePE represents each image token as a depth-aware positional distribution along its source ray to support unified camera control under the Unified Camera Model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
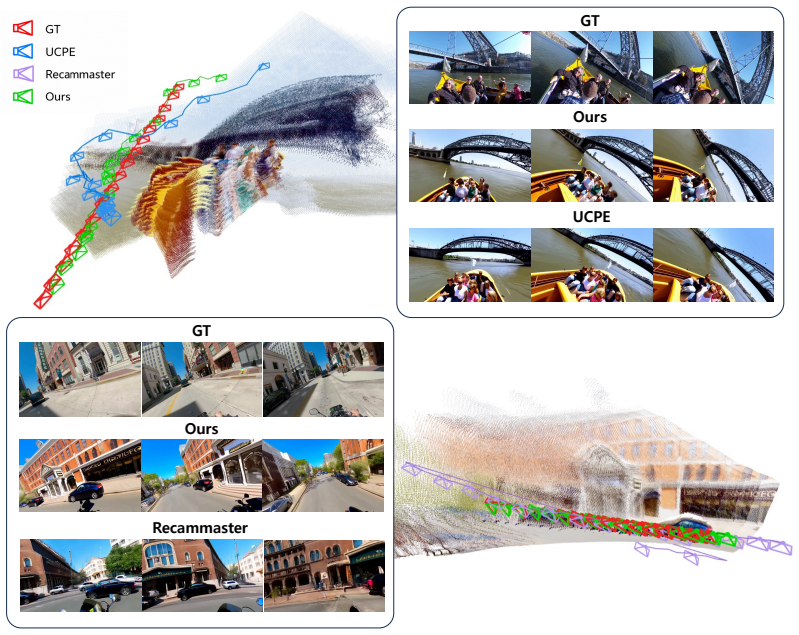
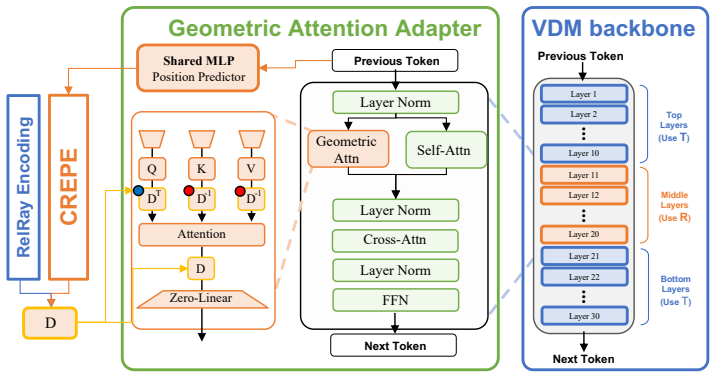
CRePE represents each image token as a depth-aware positional distribution along its source ray, providing a Unified Camera Model-compatible positional encoding that captures the projected-path geometry induced by wide-angle and fisheye cameras. It is implemented through a Geometric Attention Adapter added to frozen video DiTs, injecting token-wise scene-distance information into selected attention layers and stabilizing it with pseudo supervision from a monocular geometry foundation model. This design leads to more stable camera control and improves several geometry-aware and perceptual-quality metrics, while remaining competitive on video-quality metrics.
What carries the argument
Curved Ray Expectation Positional Encoding (CRePE) that models each token's position as the expectation of a depth distribution along its curved source ray under the Unified Camera Model.
If this is right
- More stable camera control for wide-angle and fisheye lenses compared to pinhole-only encodings.
- Improved scores on geometry-aware and perceptual-quality metrics while staying competitive on video quality.
- Better overall average rank than RayRoPE-style endpoint baselines in positional-encoding ablations.
- Additional support for external radial-map control and source-video motion transfer through Radial MixForcing.
Where Pith is reading between the lines
- The same ray-distribution pathway could let a single model train on footage from mixed or uncalibrated real-world cameras without lens-specific adapters.
- Self-supervised consistency losses computed across generated frames might eventually replace the external monocular pseudo-supervisor.
- The expectation formulation may permit direct differentiation through camera parameters to optimize trajectories at inference time.
Load-bearing premise
Pseudo-supervision from a monocular geometry foundation model is sufficient to stabilize the Geometric Attention Adapter without introducing systematic bias in the learned ray distributions.
What would settle it
Generating videos under known fisheye parameters on a synthetic scene with ground-truth ray paths and checking whether object trajectories and line projections match the expected curved geometry only when CRePE is used.
Figures





read the original abstract
Camera-conditioned video generation requires positional encoding that remains reliable under changes in camera motion, lens configuration, and scene structure. However, existing attention-level camera encodings either provide ray-only camera signals or rely on pinhole camera geometry, limiting their applicability to general camera control under the Unified Camera Model, including wide-angle and fisheye lenses. To address this limitation, we propose Curved Ray Expectation Positional Encoding (CRePE). CRePE represents each image token as a depth-aware positional distribution along its source ray, providing a Unified Camera Model-compatible positional encoding that captures the projected-path geometry induced by wide-angle and fisheye cameras. CRePE is implemented through a Geometric Attention Adapter added to frozen video DiTs, injecting token-wise scene-distance information into selected attention layers and stabilizing it with pseudo supervision from a monocular geometry foundation model. This design leads to more stable camera control and improves several geometry-aware and perceptual-quality metrics, while remaining competitive on video-quality metrics. Controlled positional-encoding ablations show a better overall average rank than a RayRoPE-style endpoint PE baseline, demonstrating the effectiveness of UCM-aware projected-path integration across diverse camera models. Furthermore, by extending the same positional-encoding pathway to external geometry control through Radial MixForcing, CRePE supports external radial-map control for scene-geometry-conditioned generation and source-video motion transfer beyond camera control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Curved Ray Expectation Positional Encoding (CRePE) to enable reliable camera control in video diffusion transformers under the Unified Camera Model (UCM), including wide-angle and fisheye lenses. Each image token is represented as a depth-aware positional distribution along its source ray; this is realized by adding a Geometric Attention Adapter to frozen DiTs, stabilized via pseudo-supervision from a monocular geometry foundation model. The method is claimed to improve geometry-aware and perceptual metrics while remaining competitive on video quality, outperforming a RayRoPE-style baseline in average rank across ablations, and to support external radial-map control via Radial MixForcing.
Significance. If the learned ray distributions accurately reflect UCM geometry without systematic bias from the pseudo-labels, the approach would provide a practical route to camera- and geometry-conditioned generation beyond pinhole assumptions, with potential impact on controllable video synthesis pipelines.
major comments (3)
- [Method (Geometric Attention Adapter)] Method section (Geometric Attention Adapter and pseudo-supervision): the central claim that CRePE supplies UCM-compatible curved-ray positional encodings rests on the assumption that monocular foundation-model depth labels supply unbiased expectations along actual distorted rays; no quantitative validation (e.g., comparison of learned distributions to ground-truth UCM ray paths on fisheye or wide-angle test data) is provided, leaving open the possibility that the encoding collapses to approximate pinhole behavior.
- [Experiments and Ablations] Experiments and ablations: metric gains and the reported better average rank versus the RayRoPE baseline are presented without error bars, standard deviations across runs, or statistical significance tests, so it is impossible to determine whether the observed improvements are reliable or merely within noise.
- [Abstract / Method] Abstract and method: the precise formulation of the depth-aware positional distribution (how the expectation is computed from the adapter output and integrated into attention) is not derived in sufficient detail to verify that it captures projected-path geometry rather than simply injecting scalar depth.
minor comments (2)
- [Notation] Notation for the ray-distribution parameters should be introduced once and used consistently; currently the distinction between the adapter output and the final positional encoding is unclear on first reading.
- [Tables] Tables reporting ablation ranks would benefit from explicit column headers indicating the exact metric being ranked and the number of camera/lens configurations evaluated.
Simulated Author's Rebuttal
We are grateful to the referee for the thorough and insightful comments, which have helped us identify areas for improvement in the manuscript. Below, we provide a point-by-point response to the major comments. We have made revisions to address each concern.
read point-by-point responses
-
Referee: Method section (Geometric Attention Adapter and pseudo-supervision): the central claim that CRePE supplies UCM-compatible curved-ray positional encodings rests on the assumption that monocular foundation-model depth labels supply unbiased expectations along actual distorted rays; no quantitative validation (e.g., comparison of learned distributions to ground-truth UCM ray paths on fisheye or wide-angle test data) is provided, leaving open the possibility that the encoding collapses to approximate pinhole behavior.
Authors: We thank the referee for highlighting this important aspect. The pseudo-supervision from the monocular geometry foundation model is designed to provide depth estimates that align with the actual ray paths under the UCM. However, we acknowledge the value of direct quantitative validation. In the revised manuscript, we will include a comparison of the learned distributions to ground-truth UCM ray paths on fisheye and wide-angle test data to confirm that the encodings do not collapse to pinhole behavior. revision: yes
-
Referee: Experiments and ablations: metric gains and the reported better average rank versus the RayRoPE baseline are presented without error bars, standard deviations across runs, or statistical significance tests, so it is impossible to determine whether the observed improvements are reliable or merely within noise.
Authors: We agree that including error bars, standard deviations, and statistical significance tests would strengthen the experimental results. We will rerun the key experiments with multiple random seeds and report the mean and standard deviation, along with p-values from appropriate statistical tests, in the revised manuscript. revision: yes
-
Referee: Abstract and method: the precise formulation of the depth-aware positional distribution (how the expectation is computed from the adapter output and integrated into attention) is not derived in sufficient detail to verify that it captures projected-path geometry rather than simply injecting scalar depth.
Authors: We appreciate this feedback on the clarity of the formulation. We will expand the Method section with a detailed derivation of the depth-aware positional distribution, explicitly describing how the expectation is computed from the Geometric Attention Adapter output and integrated into the attention mechanism to capture the projected-path geometry under the UCM, rather than merely injecting scalar depth values. revision: yes
Circularity Check
No circularity: new adapter and external pseudo-supervision keep derivation self-contained
full rationale
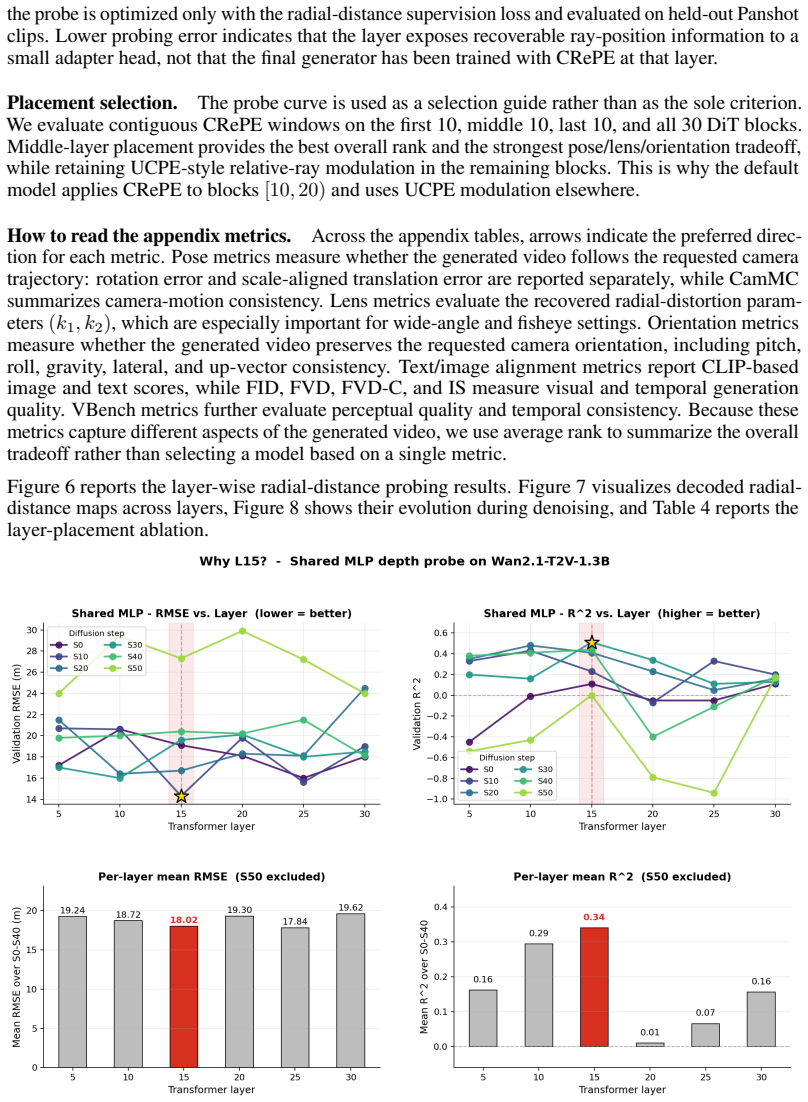
The paper defines CRePE as a depth-aware positional distribution along source rays under the Unified Camera Model, realized by adding a Geometric Attention Adapter to frozen video DiTs and stabilizing it via pseudo-depth labels from an external monocular geometry foundation model. No equation or central claim reduces by construction to a parameter fitted inside the paper, nor does any load-bearing step rely on a self-citation chain, imported uniqueness theorem, or ansatz smuggled from prior author work. Ablations compare against an external RayRoPE-style baseline, and the UCM compatibility follows directly from the ray-distribution construction rather than from re-labeling fitted quantities. The derivation therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- depth distribution parameters
axioms (1)
- domain assumption Unified Camera Model correctly captures lens-induced ray curvature for wide-angle and fisheye cases
invented entities (2)
-
Curved Ray Expectation Positional Encoding
no independent evidence
-
Geometric Attention Adapter
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.lean (SphereAdmitsCircleLinking, D=3)alexander_duality_circle_linking unclearUCM projection... curved projected-path integration... K=5 radial-distance breakpoints
Reference graph
Works this paper leans on
-
[1]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InICCV, 2025
work page 2025
-
[2]
Rayrope: Projective ray positional encoding for multi-view attention, 2026
Yu Wu, Minsik Jeon, Jen-Hao Rick Chang, Oncel Tuzel, and Shubham Tulsiani. Rayrope: Projective ray positional encoding for multi-view attention, 2026. URLhttps://arxiv.org/abs/2601.15275
-
[3]
Cheng Zhang, Boying Li, Meng Wei, Yan-Pei Cao, Camilo Cruz Gambardella, Dinh Phung, and Jianfei Cai. Unified camera positional encoding for controlled video generation.arXiv preprint arXiv:2512.07237, 2025
-
[4]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers, 2023. URL https: //arxiv.org/abs/2212.09748
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, and Di Zhang. Recammaster: Camera-controlled generative rendering from a single video, 2025. URLhttps://arxiv.org/abs/2503.11647
-
[7]
Yonosplat: You only need one model for feedforward 3d gaussian splatting
Botao Ye, Boqi Chen, Haofei Xu, Daniel Barath, and Marc Pollefeys. Yonosplat: You only need one model for feedforward 3d gaussian splatting. InThe F ourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=ImRhA9xmay
work page 2026
-
[8]
Cameractrl: Enabling camera control for text-to-video generation, 2025
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation, 2025. URL https://arxiv.org/abs/2404. 02101
work page 2025
-
[9]
Motionctrl: A unified and flexible motion controller for video generation, 2024
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation, 2024. URL https://arxiv. org/abs/2312.03641
-
[10]
Direct-a-video: Customized video generation with user-directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user-directed camera movement and object motion. InSpecial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, SIGGRAPH ’24, page 1–12. ACM, 2024. doi: 10.1145/3...
-
[11]
Zhang, Amy Lin, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, and Shubham Tulsiani
Jason Y . Zhang, Amy Lin, Moneish Kumar, Tzu-Hsuan Yang, Deva Ramanan, and Shubham Tulsiani. Cameras as rays: Pose estimation via ray diffusion, 2024. URL https://arxiv.org/abs/2402.14817
-
[12]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023. URLhttps://arxiv.org/abs/2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [13]
-
[14]
Gta: A geometry-aware attention mechanism for multi-view transformers, 2024
Takeru Miyato, Bernhard Jaeger, Max Welling, and Andreas Geiger. Gta: A geometry-aware attention mechanism for multi-view transformers, 2024. URLhttps://arxiv.org/abs/2310.10375
-
[15]
Cameras as relative positional encoding, 2025
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encoding, 2025. URLhttps://arxiv.org/abs/2507.10496
-
[16]
Vincent Sitzmann, Semon Rezchikov, William T. Freeman, Joshua B. Tenenbaum, and Fredo Durand. Light field networks: Neural scene representations with single-evaluation rendering, 2022. URL https: //arxiv.org/abs/2106.02634
-
[17]
Learning neural light fields with ray-space embedding networks, 2022
Benjamin Attal, Jia-Bin Huang, Michael Zollhoefer, Johannes Kopf, and Changil Kim. Learning neural light fields with ray-space embedding networks, 2022. URLhttps://arxiv.org/abs/2112.01523
-
[18]
Mehdi S. M. Sajjadi, Henning Meyer, Etienne Pot, Urs Bergmann, Klaus Greff, Noha Radwan, Suhani V ora, Mario Lucic, Daniel Duckworth, Alexey Dosovitskiy, Jakob Uszkoreit, Thomas Funkhouser, and Andrea Tagliasacchi. Scene representation transformer: Geometry-free novel view synthesis through set-latent scene representations, 2022. URLhttps://arxiv.org/abs/...
-
[19]
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srini- vasan, Jonathan T. Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models,
- [20]
-
[21]
Dust3r: Geometric 3d vision made easy, 2024
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy, 2024. URLhttps://arxiv.org/abs/2312.14132
-
[22]
Grounding image matching in 3d with mast3r, 2024
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r, 2024. URLhttps://arxiv.org/abs/2406.09756
-
[23]
Vggt: Visual geometry grounded transformer, 2025
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer, 2025. URLhttps://arxiv.org/abs/2503.11651
-
[24]
Unik3d: Universal camera monocular 3d estimation, 2025
Luigi Piccinelli, Christos Sakaridis, Mattia Segu, Yung-Hsu Yang, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unik3d: Universal camera monocular 3d estimation, 2025. URL https://arxiv.org/abs/2503. 16591. A Standard RoPE and UCM Details Rotary positional encoding (RoPE) [12] encodes a scalar positionxas a block-diagonal rotation ρD(x) = D/2M f=1 ρ2(ωf x), ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.