Recognition: unknown
TruncProof: A Guardrail for LLM-based JSON Generation under Token-Length Constraints
Pith reviewed 2026-05-14 19:42 UTC · model grok-4.3
The pith
TruncProof uses an LL(1) parser to approximate the fewest tokens still needed for a valid JSON at every decoding step, letting the model finish inside a hard token budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TruncProof is a grammar-constrained generation procedure that, at every step, uses an LL(1) parser to compute the minimum additional tokens required to reach a complete, well-formed JSON; the decoder is then allowed to emit the next token only when the remaining budget is at least that minimum, thereby guaranteeing both syntactic validity and strict adherence to a preset token limit.
What carries the argument
LL(1) parser approximation of minimum completion tokens, which supplies a lower bound on the length of any legal suffix and is recomputed after each token to decide whether continuation is still safe.
If this is right
- Syntactically correct JSON is produced even when the token budget is only a few tokens above the minimum completion length.
- The same guardrail can be stacked on top of beam search, sampling, or other decoding strategies without losing their semantic gains.
- System crashes from malformed or over-length JSON outputs are prevented in downstream API or database integrations.
- The method works on standard text-to-JSON instruction benchmarks without requiring model retraining.
Where Pith is reading between the lines
- The same minimum-token lookahead could be applied to other context-free grammars such as XML schemas or simple programming-language fragments.
- Dynamic adjustment of the token budget mid-generation becomes feasible once the parser state tracks remaining depth.
- Combining the guardrail with retrieval-augmented generation might reduce both syntactic and factual errors in structured data tasks.
- Empirical measurement of how often the LL(1) bound is loose on real JSON schemas would quantify the headroom left for semantic choices.
Load-bearing premise
The LL(1) parser approximation of minimum completion tokens remains accurate enough across varied JSON structures and does not cause premature termination or invalid outputs when the grammar is complex.
What would settle it
Generate JSON under a token budget that is only one or two tokens larger than the LL(1)-computed minimum for a deeply nested schema; if the produced string is either truncated mid-object or contains a syntax error, the approximation has failed.
Figures



read the original abstract
The LLM-based generation of machine-readable outputs such as JSON has attracted significant attention for integration with external systems. However, existing approaches cannot strictly enforce the maximum number of tokens to be generated, leading to infinite generation or truncated outputs that cause a system malfunction. To address this limitation, we propose TruncProof, a novel grammar-constrained generation method that enables LLMs to produce grammatically valid JSONs while adhering to a predefined token limit. By leveraging the properties of LL(1) parsers, TruncProof efficiently approximates the minimum number of tokens required to complete a grammatically valid output at each decoding step. Experiments on the Text-to-JSON instruction tasks demonstrate that TruncProof successfully generates syntactically correct outputs even under strict token constraints. Furthermore, we show that TruncProof can be effectively combined with advanced decoding strategies, resulting in outputs that are not only grammatically valid but also semantically accurate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TruncProof, a grammar-constrained decoding method for LLM-based JSON generation that uses LL(1) parser lookahead to approximate the minimum tokens required for a syntactically valid completion at each step, thereby enforcing a strict token limit while avoiding invalid partial outputs. Experiments on text-to-JSON tasks are reported to show that the method produces correct JSON even under tight constraints and combines with other decoding strategies for semantic accuracy.
Significance. If the LL(1) approximation is shown to be reliably tight, TruncProof would address a practical gap in deploying LLMs for machine-readable output generation by preventing system malfunctions from truncated or malformed JSON. The method rests on standard parser theory with empirical testing rather than new parameters or fitted models, which is a strength, but the absence of quantitative metrics in the reported experiments limits evaluation of its robustness across varied JSON structures.
major comments (2)
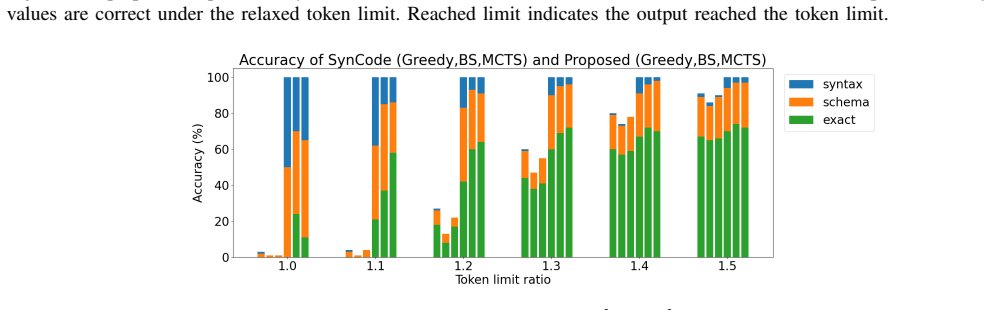
- [§4] §4 (Experiments): The abstract and experiments claim successful generation of syntactically correct outputs under token constraints, yet no quantitative metrics (e.g., validity rates, average token usage, error types), baseline comparisons, or error analysis are provided. This leaves the central empirical claim only moderately supported and makes it impossible to assess whether the guardrail consistently outperforms naive truncation.
- [§3.2] §3.2 (LL(1) approximation): The method relies on single-token lookahead to compute a lower bound on remaining tokens for valid completion. For JSON grammars with optional keys, variable-length arrays, or deep nesting, this bound may not be tight; the manuscript should include either a formal argument that the approximation never underestimates or an empirical stress test on complex schemas showing no premature termination into invalid partial JSON.
minor comments (2)
- [§3] The description of how the LL(1) parser is integrated into the decoder loop would benefit from a small pseudocode listing or explicit equation for the token-count update rule.
- [§4] Figure captions and axis labels in the experimental plots (if present) should explicitly state the token budget and JSON schema complexity used in each condition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the experiments section requires quantitative support and that the LL(1) approximation needs explicit justification for tightness. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The abstract and experiments claim successful generation of syntactically correct outputs under token constraints, yet no quantitative metrics (e.g., validity rates, average token usage, error types), baseline comparisons, or error analysis are provided. This leaves the central empirical claim only moderately supported and makes it impossible to assess whether the guardrail consistently outperforms naive truncation.
Authors: We agree that the current experiments provide only qualitative demonstrations of success. In the revised manuscript we will add quantitative metrics including JSON validity rates at varying token limits, average token usage relative to the limit, direct comparisons against naive truncation and other constrained decoding baselines, and a categorized error analysis of any remaining failures. These additions will allow readers to evaluate robustness and outperformance more rigorously. revision: yes
-
Referee: [§3.2] §3.2 (LL(1) approximation): The method relies on single-token lookahead to compute a lower bound on remaining tokens for valid completion. For JSON grammars with optional keys, variable-length arrays, or deep nesting, this bound may not be tight; the manuscript should include either a formal argument that the approximation never underestimates or an empirical stress test on complex schemas showing no premature termination into invalid partial JSON.
Authors: The LL(1) lookahead is intended to compute a conservative lower bound derived from the parser's FIRST sets, which by construction cannot underestimate the minimum tokens needed for a valid completion. However, the manuscript does not currently contain an explicit formal proof of this property or stress tests on complex schemas. In the revision we will add a short formal argument showing that the approximation is always a valid lower bound for the JSON grammar (leveraging standard LL(1) properties for context-free languages) and include empirical results on schemas containing optional keys, variable-length arrays, and deep nesting to confirm absence of premature invalid terminations. revision: yes
Circularity Check
No circularity: TruncProof relies on standard LL(1) parser theory and empirical validation
full rationale
The paper's core method approximates minimum completion tokens using established LL(1) parser lookahead properties to enforce token limits while ensuring JSON validity. This draws from external parser theory rather than any self-referential definition, fitted parameters renamed as predictions, or load-bearing self-citations. No equations or derivations reduce to the inputs by construction; the approach is tested empirically on Text-to-JSON tasks, providing independent falsifiability outside any internal fit. The derivation chain remains self-contained against standard benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LL(1) parsers can efficiently approximate the minimum number of tokens required to complete a grammatically valid JSON at each decoding step
Reference graph
Works this paper leans on
-
[1]
MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning,
K. Wang, H. Ren, A. Zhou, Z. Lu, S. Luo, W. Shi, R. Zhang, L. Song, M. Zhan, and H. Li, “MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=z8TW0ttBPp
work page 2024
-
[2]
Visual Programming: Compositional Visual Reasoning Without Training,
T. Gupta and A. Kembhavi, “Visual Programming: Compositional Visual Reasoning Without Training,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), June 2023, pp. 14 953–14 962
work page 2023
-
[3]
OpenAI, “Structured model outputs,” https://platform.openai.com/docs/guides/structured-outputs/json-mode (accessed December 2025)
work page 2025
-
[4]
Increase output consistency (JSON mode),
Anthropic, “Increase output consistency (JSON mode),” https://platform.claude.com/docs/en/test-and-evaluate/strengthen- guardrails/increase-consistency (accessed December 2025)
work page 2025
-
[5]
Google, “Structured Outputs,” https://ai.google.dev/gemini- api/docs/structured-output (accessed December 2025)
work page 2025
-
[6]
Model Context Protocol a Series of LF Projects, LLC., “Model context protocol,” https://modelcontextprotocol.io/ (Last Accessed 27 Jan 2026)
work page 2026
-
[7]
guidance-ai/guidance: A Guidance Language for Controlling Large Language Models
S. Lundberg, M. T. C. Ribeiroet al., “guidance-ai/guidance: A Guidance Language for Controlling Large Language Models.” 2023, https://github.com/guidance-ai/guidance
work page 2023
-
[8]
Efficient Guided Generation for Large Language Models
B. T. Willard and R. Louf, “Efficient Guided Generation for Large Language Models,” 2023, https://arxiv.org/abs/2307.09702
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
ggml-org/llama.cpp: LLM inference in C/C++
G. Gerganov, D. Devesaet al., “ggml-org/llama.cpp: LLM inference in C/C++.” 2023, https://github.com/ggml-org/llama.cpp
work page 2023
-
[10]
Guiding LLMs The Right Way: Fast, Non-Invasive Constrained Generation,
L. Beurer-Kellner, M. Fischer, and M. Vechev, “Guiding LLMs The Right Way: Fast, Non-Invasive Constrained Generation,” 2024, https://arxiv.org/abs/2403.06988
-
[11]
SynCode: LLM Generation with Grammar Augmentation,
S. Ugare, T. Suresh, H. Kang, S. Misailovic, and G. Singh, “SynCode: LLM Generation with Grammar Augmentation,” 2024, https://arxiv.org/abs/2403.01632
-
[12]
XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models,
Y . Dong, C. F. Ruan, Y . Cai, Z. Xu, Y . Zhao, R. Lai, and T. Chen, “XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models,” inEighth Conference on Machine Learning and Systems, 2025. [Online]. Available: https: //openreview.net/forum?id=rjQfX0YgDl
work page 2025
-
[13]
M. Moskal, H. Nori, H. Cooper, and L. Huynh, “guidance-ai/llguidance.” 2025, https://github.com/guidance-ai/llguidance
work page 2025
-
[14]
A. V . Aho and J. D. Ullman,The Theory of Parsing, Translation, and Compiling. USA: Prentice-Hall, Inc., 1972
work page 1972
-
[15]
Practical translators for lr(k) languages,
F. DeRemer, “Practical translators for lr(k) languages,” Ph.D. disserta- tion, Massachusetts Institute of Technology, 1969
work page 1969
-
[16]
Lark - A Parsing Toolkit for Python,
E. Shinan, “Lark - A Parsing Toolkit for Python,” 2017, https://github.com/lark-parser/lark
work page 2017
-
[17]
NousResearch, “JSON-Mode-Eval,” 2024, https://huggingface.co/datasets/NousResearch/json-mode-eval
work page 2024
-
[18]
Google, “Gemma,” 2024, https://www.kaggle.com/m/3301
work page 2024
-
[19]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V . Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V . Kerkez, M. Khabsa, I. Kloumann, A. Koren...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
PICARD: Parsing In- crementally for Constrained Auto-Regressive Decoding from Language Models,
T. Scholak, N. Schucher, and D. Bahdanau, “PICARD: Parsing In- crementally for Constrained Auto-Regressive Decoding from Language Models,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Nov. 2021, pp. 9895–9901
work page 2021
-
[21]
Prompting Is Programming: A Query Language for Large Language Models,
L. Beurer-Kellner, M. Fischer, and M. Vechev, “Prompting Is Programming: A Query Language for Large Language Models,” vol. 7, no. PLDI. Association for Computing Machinery (ACM), Jun. 2023, p. 1946–1969. [Online]. Available: http://dx.doi.org/10.1145/3591300
-
[22]
Flexible and efficient grammar- constrained decoding,
K. Park, T. Zhou, and L. D’Antoni, “Flexible and efficient grammar- constrained decoding,” inF orty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/ forum?id=L6CY AzpO1k
work page 2025
-
[23]
IterGen: Iterative Semantic-aware Structured LLM Generation with Backtracking,
S. Ugare, R. Gumaste, T. Suresh, G. Singh, and S. Misailovic, “IterGen: Iterative Semantic-aware Structured LLM Generation with Backtracking,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/ forum?id=ac93gRzxxV
work page 2025
-
[24]
Type-Aware Constraining for Code LLMs,
N. M ¨undler, J. He, H. Wang, K. Sen, D. Song, and M. Vechev, “Type-Aware Constraining for Code LLMs,” inICLR 2025 Third Workshop on Deep Learning for Code, 2025. [Online]. Available: https://openreview.net/forum?id=DNAapYMXkc
work page 2025
-
[25]
Correctness-Guaranteed Code Generation via Constrained Decoding,
L. Li, salar rahili, and Y . Zhao, “Correctness-Guaranteed Code Generation via Constrained Decoding,” inSecond Conference on Language Modeling, 2025. [Online]. Available: https://openreview.net/ forum?id=CYiXNIQegF
work page 2025
-
[26]
Grammar- Constrained Decoding for Structured NLP Tasks without Finetuning,
S. Geng, M. Josifoski, M. Peyrard, and R. West, “Grammar- Constrained Decoding for Structured NLP Tasks without Finetuning,” inThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. [Online]. Available: https://openreview.net/forum?id= KkHY1WGDII
work page 2023
-
[27]
Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search,
R. Coulom, “Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search,” inComputers and Games, 2006. [Online]. Available: https://api.semanticscholar.org/CorpusID:16724115
work page 2006
-
[28]
Machine Translation Decoding beyond Beam Search,
R. Leblond, J.-B. Alayrac, L. Sifre, M. Pislar, L. Jean-Baptiste, I. Antonoglou, K. Simonyan, and O. Vinyals, “Machine Translation Decoding beyond Beam Search,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Online and Punta Cana, Dominican Republic: Association for Computational Linguistics, Nov. 2021, pp. 8410–...
work page 2021
-
[29]
PPL-MCTS: Constrained Textual Generation Through Discriminator-Guided MCTS Decoding,
A. Chaffin, V . Claveau, and E. Kijak, “PPL-MCTS: Constrained Textual Generation Through Discriminator-Guided MCTS Decoding,” inProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Seattle, United States: Association for Computational Linguistics, Jul. 2022, pp. 295...
work page 2022
-
[30]
Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo,
J. Loula, B. LeBrun, L. Du, B. Lipkin, C. Pasti, G. Grand, T. Liu, Y . Emara, M. Freedman, J. Eisner, R. Cotterell, V . Mansinghka, A. K. Lew, T. Vieira, and T. J. O’Donnell, “Syntactic and Semantic Control of Large Language Models via Sequential Monte Carlo,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available...
work page 2025
-
[31]
Mastering the game of Go without human knowledge,
D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. baker, M. Lai, A. Bolton, Y . Chen, T. P. Lillicrap, F. Hui, L. Sifre, G. van den Driessche, T. Graepel, and D. Hassabis, “Mastering the game of Go without human knowledge,”Nature, vol. 550, pp. 354–359, 2017. [Online]. Available: https://api.semanticscholar.org/Corp...
work page 2017
-
[32]
K. Park, J. Wang, T. Berg-Kirkpatrick, N. Polikarpova, and L. D' Antoni, “Grammar-Aligned Decoding,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 24 547–24 568. [Online]. Available: https://proceedings.neurips.cc/pap...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.