Recognition: unknown
Code Review Agent Benchmark
Pith reviewed 2026-05-15 00:17 UTC · model grok-4.3
The pith
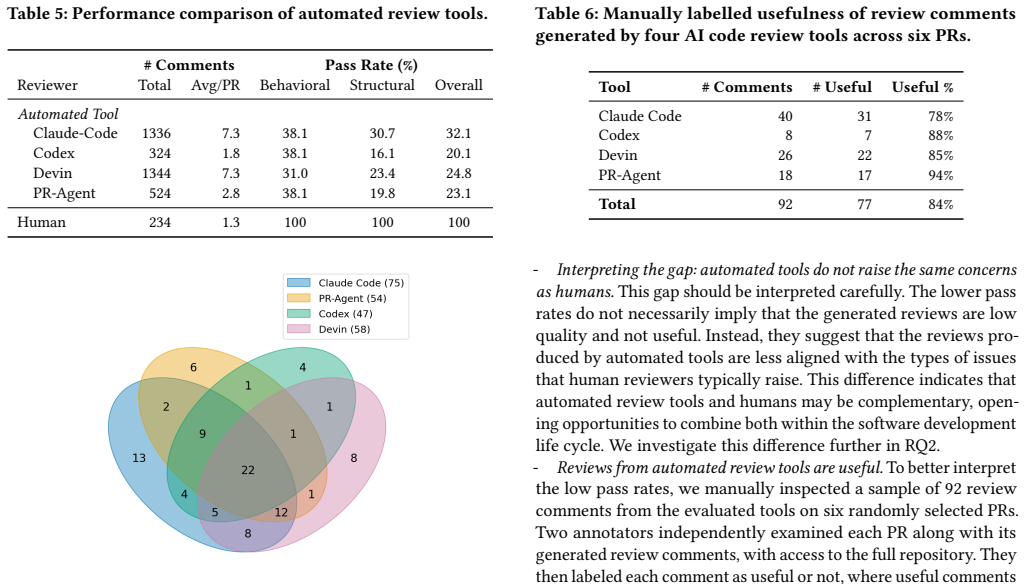
Existing code review agents solve only around 40% of tasks in the c-CRAB benchmark built from human reviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The c-CRAB dataset, built by generating tests from human reviews of pull requests, shows that current code review agents solve only around 40% of its tasks while often focusing on different aspects than humans, which indicates both a performance gap for future work and opportunities for human-agent collaboration in code review.
What carries the argument
c-CRAB benchmark, which turns human pull-request reviews into tests that score whether an agent's generated review catches the same issues.
If this is right
- Future agents can target the remaining 60% of tasks to narrow the performance gap.
- Complementary focus areas between agents and humans enable hybrid review processes.
- The generated tests function as an independent quality gate for any agent review.
- Combining review agents with code-generation and test-generation agents could create end-to-end automated quality pipelines.
Where Pith is reading between the lines
- The benchmark could be expanded to more languages and project scales to test broader applicability.
- Hybrid human-agent systems might reduce reviewer workload while maintaining higher coverage than either alone.
- Standardized benchmarks like this one could accelerate development of reliable AI tools for large-scale software maintenance.
Load-bearing premise
Tests derived from human reviews of pull requests give a reliable and complete measure of review quality.
What would settle it
A new agent that passes substantially more than 40% of c-CRAB tasks, or evidence that agent and human review differences lead to conflicting rather than additive results on actual codebases.
Figures






read the original abstract
Software engineering agents have shown significant promise in writing code. As AI agents permeate code writing, and generate huge volumes of code automatically -- the matter of code quality comes front and centre. As the automatically generated code gets integrated into huge code-bases -- the issue of code review and broadly quality assurance becomes important. In this paper, we take a fresh look at the problem and curate a code review dataset for AI agents to work with. Our dataset called c-CRAB (pronounced see-crab) can evaluate agents for code review tasks. Specifically given a pull-request (which could be coming from code generation agents or humans), if a code review agent produces a review, our evaluation framework can asses the reviewing capability of the code review agents. Our evaluation framework is used to evaluate the state of the art today -- the open-source PR-agent, as well as commercial code review agents from Devin, Claude Code, and Codex. Our c-CRAB dataset is systematically constructed from human reviews -- given a human review of a pull request instance we generate corresponding tests to evaluate the code review agent generated reviews. Such a benchmark construction gives us several insights. Firstly, the existing review agents taken together can solve only around 40% of the c-CRAB tasks, indicating the potential to close this gap by future research. Secondly, we observe that the agent reviews often consider different aspects from the human reviews -- indicating the potential for human-agent collaboration for code review that could be deployed in future software teams. Last but not the least, the agent generated tests from our data-set act as a held out test-suite and hence quality gate for agent generated reviews. What this will mean for future collaboration of code generation agents, test generation agents and code review agents -- remains to be investigated.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces c-CRAB, a benchmark dataset for code review agents constructed systematically from human pull-request reviews. Tests are generated from human comments to evaluate agent-generated reviews, with evaluations of the open-source PR-agent and commercial agents from Devin, Claude Code, and Codex. Key results include an aggregate solve rate of around 40% and the observation that agent reviews often address different aspects than human reviews, suggesting potential for human-agent collaboration.
Significance. If the test-generation and evaluation framework is valid, this provides a timely empirical benchmark quantifying current limitations in AI code review agents amid rising volumes of auto-generated code. The 40% solve rate and complementarity finding offer concrete guidance for closing gaps and designing hybrid workflows, while the held-out test-suite framing supplies a practical quality gate for integrated agent systems.
major comments (1)
- [Dataset Construction] The translation from human review comments to evaluation tests is central to the benchmark's reliability (see dataset construction description). The manuscript should specify the exact mapping rules or provide concrete examples of test generation to demonstrate that the tests faithfully capture review quality without introducing artifacts or coverage gaps.
minor comments (2)
- Add a table with per-agent solve rates and task counts to support the aggregate 40% claim and enable direct comparison.
- Include version numbers or access dates for the commercial agents (Devin, Claude Code, Codex) to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive recommendation of minor revision and for the constructive comment on dataset construction. We address the point below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Dataset Construction] The translation from human review comments to evaluation tests is central to the benchmark's reliability (see dataset construction description). The manuscript should specify the exact mapping rules or provide concrete examples of test generation to demonstrate that the tests faithfully capture review quality without introducing artifacts or coverage gaps.
Authors: We agree that concrete examples are essential to demonstrate the fidelity of the test-generation process. In the revised manuscript we will add a new subsection (with accompanying examples) that walks through the mapping from specific human review comments to the corresponding evaluation tests. For instance, a human comment flagging a missing input validation will be shown to generate a test that checks whether an agent review identifies the missing check and suggests an appropriate fix. These examples will be drawn directly from the c-CRAB construction pipeline and will illustrate that the tests preserve the semantic intent of the original human comments without introducing extraneous artifacts or systematic coverage gaps. We believe this addition will fully address the concern while keeping the paper concise. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper whose central claims follow directly from dataset construction and agent evaluation. The c-CRAB tasks are generated from human PR reviews via systematic test creation; the ~40% solve rate and observed differences in review focus are measured outcomes on that held-out suite. No equations, parameter fitting, self-referential predictions, or load-bearing self-citations appear in the derivation chain. The evaluation logic is self-contained once the human-review-to-test mapping is granted, with no reduction of results to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human reviews of pull requests constitute a reliable gold standard for assessing code review quality.
invented entities (1)
-
c-CRAB dataset
no independent evidence
Forward citations
Cited by 1 Pith paper
-
SWE-Cycle: Benchmarking Code Agents across the Complete Issue Resolution Cycle
SWE-Cycle benchmark shows sharp drops in code agent success rates from isolated tasks to full autonomous issue resolution, highlighting cross-phase dependency issues.
Reference graph
Works this paper leans on
-
[1]
Maria Antoniak and David Mimno. 2018. Evaluating the Stability of Embedding- based Word Similarities.Trans. Assoc. Comput. Linguistics6 (2018), 107–119
2018
- [2]
-
[3]
Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu
Ahmed E. Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu. 2025. Agentic Software Engineering: Foundational Pillars and a Research Roadmap.CoRRabs/2509.06216 (2025)
- [4]
- [5]
- [6]
-
[7]
Wei Li, Xin Zhang, Zhongxin Guo, Shaoguang Mao, Wen Luo, Guangyue Peng, Yangyu Huang, Houfeng Wang, and Scarlett Li. 2025. FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation. InACL (1). Association for Computational Linguistics, 17160–17176
2025
-
[8]
Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svyatkovskiy, Shengyu Fu, and Neel Sundare- san. 2022. Automating code review activities by large-scale pre-training. In ESEC/SIGSOFT FSE. ACM, 1035–1047
2022
-
[9]
Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. InText Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://aclanthology.org/W04-1013/
2004
-
[10]
Junyi Lu, Xiaojia Li, Zihan Hua, Lei Yu, Shiqi Cheng, Li Yang, Fengjun Zhang, and Chun Zuo. 2025. DeepCRCEval: Revisiting the Evaluation of Code Review Comment Generation. InFASE (Lecture Notes in Computer Science, Vol. 15693). Springer, 43–64
2025
-
[11]
Zhang, Sebas- tian Baltes, and Christoph Treude
Jai Lal Lulla, Seyedmoein Mohsenimofidi, Matthias Galster, Jie M. Zhang, Sebas- tian Baltes, and Christoph Treude. 2026. On the Impact of AGENTS.md Files on the Efficiency of AI Coding Agents.CoRRabs/2601.20404 (2026). arXiv:2601.20404 doi:10.48550/ARXIV.2601.20404
-
[12]
Atharva Naik, Marcus Alenius, Daniel Fried, and Carolyn P. Rosé. 2025. CRScore: Grounding Automated Evaluation of Code Review Comments in Code Claims and Smells. InNAACL (Long Papers). Association for Computational Linguistics, 9049–9076
2025
-
[13]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a Method for Automatic Evaluation of Machine Translation. InACL. ACL, 311–318
2002
- [14]
- [15]
-
[16]
Maja Popovic. 2015. chrF: character n-gram F-score for automatic MT evaluation. InWMT@EMNLP. The Association for Computer Linguistics, 392–395
2015
- [17]
-
[18]
Agentic Much? Adoption of Coding Agents on GitHub
Romain Robbes, Théo Matricon, Thomas Degueule, André C. Hora, and Stefano Zacchiroli. 2026. Agentic Much? Adoption of Coding Agents on GitHub.CoRR abs/2601.18341 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush Vosoughi. 2025. Judging the Judges: A Systematic Study of Position Bias in LLM-as-a-Judge. InIJCNLP-AACL (long papers). The Asian Federation of Natural Language Processing and The Association for Computational Linguistics, 292– 314
2025
-
[20]
Bissyandé
Xunzhu Tang, Kisub Kim, Yewei Song, Cedric Lothritz, Bei Li, Saad Ezzini, Haoye Tian, Jacques Klein, and Tegawendé F. Bissyandé. 2024. CodeAgent: Autonomous Communicative Agents for Code Review. InEMNLP. Association for Computa- tional Linguistics, 11279–11313
2024
-
[21]
Chakkrit Kla Tantithamthavorn, Yaotian Zou, Andy Wong, Michael Gupta, Zhe Wang, Mike Buller, Ryan Jiang, Matthew Watson, Minwoo Jeong, Kun Chen, and Ming Wu. 2026. RovoDev Code Reviewer: A Large-Scale Online Evaluation of LLM-based Code Review Automation at Atlassian.CoRRabs/2601.01129 (2026)
-
[22]
Aman Singh Thakur, Kartik Choudhary, Venkat Srinik Ramayapally, Sankaran Vaidyanathan, and Dieuwke Hupkes. 2024. Judging the Judges: Evaluating Alignment and Vulnerabilities in LLMs-as-Judges.CoRRabs/2406.12624 (2024). arXiv:2406.12624 doi:10.48550/ARXIV.2406.12624
-
[23]
Rosalia Tufano, Simone Masiero, Antonio Mastropaolo, Luca Pascarella, Denys Poshyvanyk, and Gabriele Bavota. 2022. Using Pre-Trained Models to Boost Code Review Automation. InICSE. ACM, 2291–2302
2022
-
[24]
Rosalia Tufano, Luca Pascarella, Michele Tufano, Denys Poshyvanyk, and Gabriele Bavota. 2021. Towards Automating Code Review Activities. InICSE. IEEE, 163–174
2021
-
[25]
Chengxing Xie, Bowen Li, Chang Gao, He Du, Wai Lam, Difan Zou, and Kai Chen
-
[26]
InACL (Findings) (Findings of ACL, Vol
SWE-Fixer: Training Open-Source LLMs for Effective and Efficient GitHub Issue Resolution. InACL (Findings) (Findings of ACL, Vol. ACL 2025). Association for Computational Linguistics, 1123–1139
2025
-
[27]
2026.How We Built a Real-World Bench- mark for AI Code Review
Tomer Yanay and Bar Fingerman. 2026.How We Built a Real-World Bench- mark for AI Code Review. https://www.qodo.ai/blog/how-we-built-a-real-world- benchmark-for-ai-code-review/ Qodo blog post
2026
- [28]
-
[29]
Lei Zhang, Yongda Yu, Minghui Yu, Xinxin Guo, Zhengqi Zhuang, Guoping Rong, Dong Shao, Haifeng Shen, Hongyu Kuang, Zhengfeng Li, Boge Wang, Guoan Zhang, Bangyu Xiang, and Xiaobin Xu. 2026. AACR-Bench: Evaluating Automatic Code Review with Holistic Repository-Level Context. arXiv:2601.19494 [cs.SE] https://arxiv.org/abs/2601.19494
-
[30]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InISSTA. ACM, 1592–1604
2024
-
[31]
Qixing Zhou, Jiacheng Zhang, Haiyang Wang, Rui Hao, Jiahe Wang, Minghao Han, Yuxue Yang, Shuzhe Wu, Feiyang Pan, Lue Fan, Dandan Tu, and Zhaoxiang Zhang. 2026. FeatureBench: Benchmarking Agentic Coding for Complex Feature Development. arXiv:2602.10975 [cs.SE] https://arxiv.org/abs/2602.10975 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.