Recognition: unknown
LLMs as Implicit Imputers: Uncertainty Should Scale with Missing Information
Pith reviewed 2026-05-14 17:53 UTC · model grok-4.3
The pith
LLMs should increase uncertainty as context is removed, with entropy scaling like in multiple imputation while confidence does not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
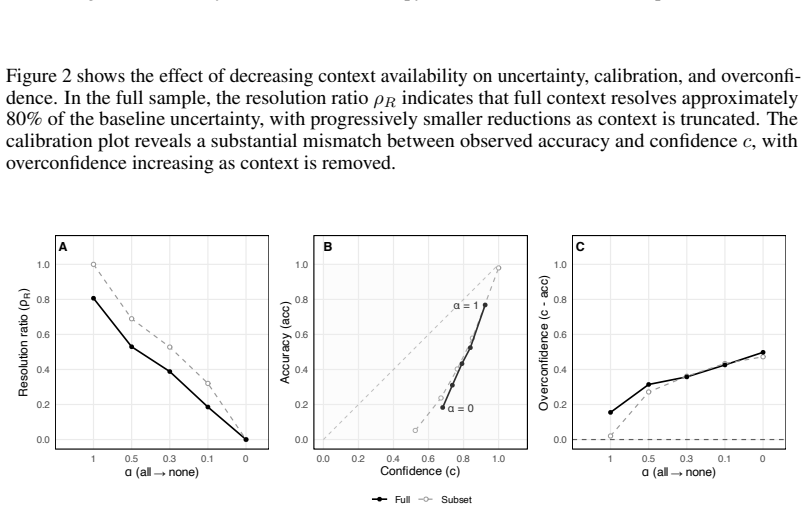
The paper claims that entropy computed from repeated LLM samples increases steadily as context segments are removed from SQuAD questions, satisfying the multiple-imputation requirement that uncertainty must scale with missing information. Sampling-based confidence fails this test because it remains elevated while accuracy collapses. The introduced diagnostic ρ_R(α) quantifies the proportion of baseline uncertainty resolved by context level α and requires only repeated sampling with and without context.
What carries the argument
Response entropy from repeated sampling, which serves as the black-box uncertainty measure required to scale directly with the quantity of missing context.
If this is right
- Entropy becomes the preferred black-box uncertainty signal for LLMs operating under incomplete context.
- The diagnostic ρ_R(α) enables direct measurement of how much any given context level reduces uncertainty without external labels.
- Model deployments can flag answers as unreliable when entropy rises above thresholds tied to observed missingness.
- Accuracy-uncertainty correlations improve when entropy replaces confidence across all context availability levels.
Where Pith is reading between the lines
- Models could be trained with explicit objectives that penalize low entropy under high missingness to improve calibration.
- The same scaling test could be applied to summarization or code generation tasks where partial documents are supplied.
- Systems might request additional context automatically once entropy exceeds a level calibrated on controlled removals.
Load-bearing premise
Controlled removal of context segments from SQuAD questions serves as a representative proxy for the missing information LLMs encounter in open-ended real-world use.
What would settle it
An experiment that removes known fractions of context from SQuAD-style questions and finds that entropy stays flat or falls while accuracy drops.
Figures


read the original abstract
Large language models (LLMs) are increasingly deployed in settings where the available context is incomplete or degraded. We argue that an LLM generating answers under incomplete context can be viewed as an implicit imputer, and evaluated against a criterion from the multiple imputation (MI) literature: uncertainty should scale with the amount of missing information. We assess this criterion on SQuAD, using a controlled framework in which context availability is varied across five levels. We evaluate two answer-level uncertainty measures that can be estimated from repeated sampling: sampling-based confidence (empirical mode frequency) and response entropy. Confidence fails to reflect increasing missingness: it remains high even as accuracy collapses. Entropy, by contrast, increases with context removal, consistent with the MI analogy, and explains substantially more variance in accuracy than confidence across all evidence levels (quadratic $R^2$ gap up to 0.057). We further introduce a black-box diagnostic $\rho_R(\alpha)$ that estimates the proportion of baseline uncertainty resolved by context level $\alpha$, requiring only repeated sampling with and without context. These results suggest that entropy is a more responsive black-box uncertainty measure than confidence under incomplete context.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper conducts an empirical study on the external SQuAD dataset by systematically varying context availability across five levels and computing sampling-based confidence and response entropy from repeated LLM generations. It directly measures how these uncertainty statistics relate to accuracy and missingness, reporting R² differences without any fitted parameters, self-referential equations, or load-bearing self-citations that reduce the central claims to inputs by construction. The MI analogy serves only as interpretive framing, not as a mathematical derivation that collapses into prior work by the same authors. All reported relationships (entropy scaling with context removal, quadratic R² gap) are obtained from observable data and repeated sampling, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Uncertainty should scale with the amount of missing information
Reference graph
Works this paper leans on
-
[1]
Bartlett, J. W. and Seaman, S. R. and White, I. R. and Carpenter, J. R. , title =. Statistical Methods in Medical Research , volume =. 2015 , location =
2015
-
[2]
International Conference on Machine Learning , pages=
On calibration of modern neural networks , author=. International Conference on Machine Learning , pages=. 2017 , organization=
2017
-
[3]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
and Zhang, J
Rajpurkar, P. and Zhang, J. and Lopyrev, K. and Liang, P. , booktitle =. 2016 , publisher =
2016
-
[5]
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. arXiv preprint arXiv:2302.09664 , year=. 2302.09664 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[7]
Little, R. J. A. and Rubin, D. B. , Edition =. Statistical Analysis with Missing Data , Year =
-
[8]
2024 , eprint=
Position: Bayesian Deep Learning is Needed in the Age of Large-Scale AI , author=. 2024 , eprint=
2024
-
[9]
Rubin, D. B. , title =
-
[10]
Taubenfeld, A. and Sheffer, T. and Ofek, E. and Feder, A. and Goldstein, A. and Gekhman, Z. and Yona, G. Confidence Improves Self-Consistency in LLM s. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1030
-
[11]
2018 , url =
Flexible Imputation of Missing Data , publisher =. 2018 , url =
2018
-
[12]
2024 , eprint=
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.