Recognition: unknown
Inducing Overthink: Hierarchical Genetic Algorithm-based DoS Attack on Black-Box Large Language Reasoning Models
Pith reviewed 2026-05-14 18:24 UTC · model grok-4.3
The pith
A hierarchical genetic algorithm induces overthinking in black-box large reasoning models, increasing output length by up to 26.1 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By applying a hierarchical genetic algorithm to structured problem decompositions and optimizing for a fitness function that rewards longer responses and reflective markers, the method reliably induces overthinking behavior in state-of-the-art reasoning models, achieving output length increases of up to 26.1x on the MATH benchmark while outperforming simple baselines.
What carries the argument
Hierarchical genetic algorithm (HGA) operating on structured problem decompositions to optimize composite fitness for response length and overthinking markers.
If this is right
- The attack works with only black-box access to the models.
- Adversarial inputs generated on small proxy models transfer effectively to large LRMs.
- Output amplification leads to significant increases in inference latency and energy use.
- Overthinking represents a shared vulnerability across modern reasoning systems.
Where Pith is reading between the lines
- Similar optimization could target other unwanted behaviors like hallucination or inconsistency.
- System designers might counter this by implementing dynamic length limits or input validation checks.
- The vulnerability could extend to real-world applications where LRMs are used for complex decision making.
Load-bearing premise
That overthinking behavior is consistently measurable by output length and reflective markers and can be induced reliably via black-box optimization without model-specific adjustments.
What would settle it
Running the HGA on a new reasoning model and finding that the generated inputs produce output lengths comparable to or shorter than standard problem inputs.
Figures


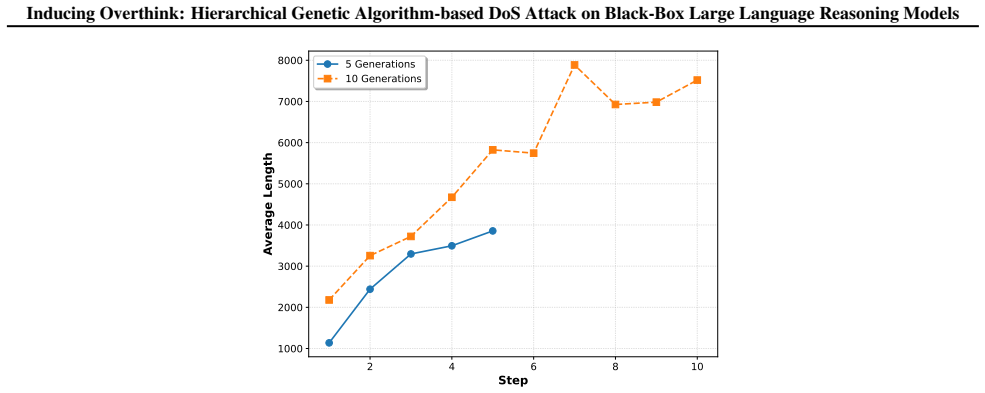
read the original abstract
Large Reasoning Models (LRMs) are increasingly integrated into systems requiring reliable multi-step inference, yet this growing dependence exposes new vulnerabilities related to computational availability. In particular, LRMs exhibit a tendency to "overthink", producing excessively long and redundant reasoning traces, when confronted with incomplete or logically inconsistent inputs. This behavior significantly increases inference latency and energy consumption, forming a potential vector for denial-of-service (DoS) style resource exhaustion. In this work, we investigate this attack surface and propose an automated black-box framework that induces overthinking in LRMs by systematically perturbing the logical structure of input problems. Our method employs a hierarchical genetic algorithm (HGA) operating on structured problem decompositions, and optimizes a composite fitness function designed to maximize both response length and reflective overthinking markers. Across four state-of-the-art reasoning models, the proposed method substantially amplifies output length, achieving up to a 26.1x increase on the MATH benchmark and consistently outperforming benign and manually crafted missing-premise baselines. We further demonstrate strong transferability, showing that adversarial inputs evolved using a small proxy model retain high effectiveness against large commercial LRMs. These findings highlight overthinking as a shared and exploitable vulnerability in modern reasoning systems, underscoring the need for more robust defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical genetic algorithm (HGA) operating on structured problem decompositions to induce overthinking in black-box large reasoning models (LRMs). By optimizing a composite fitness function on response length and reflective markers, the method perturbs logical structure of MATH-style problems and claims up to 26.1x output length amplification across four state-of-the-art models, outperforming benign and manually crafted missing-premise baselines, with demonstrated transferability from proxy to commercial LRMs.
Significance. If the central claims hold after addressing measurement and statistical concerns, the work identifies a practical black-box DoS vector against reasoning models via resource exhaustion. It extends adversarial ML literature from token-level attacks to structural perturbations that exploit overthinking, with transferability results strengthening real-world relevance. The absence of parameter fitting or self-referential axioms in the attack definition is a methodological strength.
major comments (3)
- [Abstract / Evaluation] Abstract and evaluation sections: the 26.1x length increase and consistent outperformance claims are reported without error bars, standard deviations, number of trials, or statistical tests (e.g., t-tests or Wilcoxon). This makes it impossible to determine whether the gains are robust or could arise from variance in model sampling.
- [Evaluation / Method] Evaluation / Method sections: response length plus reflective markers are used as the sole proxy for induced overthinking. Because HGA perturbations introduce logical inconsistencies or missing premises by design, longer outputs could result from the model struggling with ill-posed inputs rather than from self-reinforcing reflection loops; the missing-premise baseline mitigates but does not isolate this confound under black-box access.
- [Transferability experiments] Transferability experiments: while proxy-to-large-model transfer is reported as strong, no details are given on how many adversarial examples were tested, the exact similarity metric between proxy and target outputs, or whether the same fitness function was used without retuning.
minor comments (2)
- [Method] Notation for the hierarchical GA operators (crossover, mutation at different levels) should be formalized with pseudocode or explicit equations to allow reproduction.
- [Figures] Figure captions and axis labels for length distributions should explicitly state the number of samples per condition.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the presentation and analysis.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation sections: the 26.1x length increase and consistent outperformance claims are reported without error bars, standard deviations, number of trials, or statistical tests (e.g., t-tests or Wilcoxon). This makes it impossible to determine whether the gains are robust or could arise from variance in model sampling.
Authors: We agree that the reported results would benefit from explicit measures of variability and statistical validation. In the revised manuscript we will state that all experiments were repeated over 10 independent trials, report standard deviations alongside the 26.1x figure, add error bars to all relevant plots, and include Wilcoxon signed-rank tests with p-values comparing HGA against the baselines to establish statistical significance. revision: yes
-
Referee: [Evaluation / Method] Evaluation / Method sections: response length plus reflective markers are used as the sole proxy for induced overthinking. Because HGA perturbations introduce logical inconsistencies or missing premises by design, longer outputs could result from the model struggling with ill-posed inputs rather than from self-reinforcing reflection loops; the missing-premise baseline mitigates but does not isolate this confound under black-box access.
Authors: This is a fair observation about the interpretability of the proxy. While the missing-premise baseline was intended to control for simple ill-posedness, we acknowledge it does not fully disentangle the two mechanisms under black-box constraints. In the revision we will add a dedicated paragraph discussing this limitation, provide quantitative counts of specific reflective phrases (e.g., “let me reconsider”, “alternatively”) across conditions, and include representative reasoning traces to illustrate the self-reinforcing character of the longer outputs. revision: partial
-
Referee: [Transferability experiments] Transferability experiments: while proxy-to-large-model transfer is reported as strong, no details are given on how many adversarial examples were tested, the exact similarity metric between proxy and target outputs, or whether the same fitness function was used without retuning.
Authors: We apologize for the omitted details. The revised version will explicitly state that transferability was measured on 50 adversarial examples evolved on the proxy model, that output similarity was quantified via cosine similarity of sentence embeddings produced by a fixed embedding model, and that the identical fitness function (without any retuning or adaptation) was applied directly to the commercial target LRMs, as described in Section 4.3. revision: yes
Circularity Check
No circularity: empirical optimization with external fitness
full rationale
The paper describes an empirical black-box attack that applies a hierarchical genetic algorithm to perturb problem inputs, with a composite fitness function defined externally on measured output length and reflective markers. Results are reported as experimental observations (e.g., 26.1x length increase on MATH) against baselines, without any derivation, equation, or self-citation that reduces the central claim to a fitted parameter or self-referential definition. The method is self-contained against external benchmarks and does not invoke uniqueness theorems or rename known results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LRMs produce longer reasoning traces on logically incomplete or inconsistent inputs
Reference graph
Works this paper leans on
-
[1]
2021 IEEE Symposium on Security and Privacy (SP) , pages =
Sponge Examples: Energy-Latency Attacks on Neural Networks , author =. 2021 IEEE Symposium on Security and Privacy (SP) , pages =. 2021 , doi =
work page 2021
-
[2]
OverThink: Slowdown Attacks on Reasoning LLMs , author =. arXiv e-prints , year =
-
[3]
Do NOT Think That Much for 2+ 3=? On the Overthinking of o1-Like LLMs , author=. CoRR , year=
-
[4]
arXiv preprint arXiv:2504.06514 , year=
Missing Premise exacerbates Overthinking: Are Reasoning Models losing Critical Thinking Skill? , author=. arXiv preprint arXiv:2504.06514 , year=. 2504.06514 , archivePrefix=
-
[5]
arXiv preprint arXiv:2502.08235 , year =
Alejandro Cuadron and Dacheng Li and Wenjie Ma and Xingyao Wang and Yichuan Wang and Siyuan Zhuang and Shu Liu and Luis Gaspar Schroeder and Tian Xia and Huanzhi Mao and Nicholas Thumiger and Aditya Desai and Ion Stoica and Ana Klimovic and Graham Neubig and Joseph E. Gonzalez , title =. CoRR , volume =. 2025 , doi =. 2502.08235 , timestamp =
-
[6]
ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year =
Coercing LLMs to do and reveal (almost) anything , author =. ICLR 2024 Workshop on Secure and Trustworthy Large Language Models , year =
work page 2024
-
[7]
Yuanhe Zhang and Zhenhong Zhou and Wei Zhang and Xinyue Wang and Xiaojun Jia and Yang Liu and Sen Su , editor =. Crabs: Consuming Resource via Auto-generation for LLM-DoS Attack under Black-box Settings , booktitle =. 2025 , timestamp =
work page 2025
-
[8]
The Thirteenth International Conference on Learning Representations,
Jianshuo Dong and Ziyuan Zhang and Qingjie Zhang and Tianwei Zhang and Hao Wang and Hewu Li and Qi Li and Chao Zhang and Ke Xu and Han Qiu , title =. The Thirteenth International Conference on Learning Representations,. 2025 , timestamp =
work page 2025
-
[9]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and Transferable Adversarial Attacks on Aligned Language Models , author=. arXiv preprint arXiv:2307.15043 , year=. 2307.15043 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Internal Bias in Reasoning Models leads to Overthinking. 2025 , journal =. 2505.16448 , primaryClass =
- [11]
-
[12]
Large Language Models Market Size | Industry Report, 2030 , howpublished =. 2025 , address =
work page 2030
-
[13]
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , booktitle=. Auto
-
[14]
Crabs: Consuming Resource via Auto-generation for LLM-DoS Attack under Black-box Settings. arXiv e-prints , keywords =. doi:10.48550/arXiv.2412.13879 , archivePrefix =. 2412.13879 , primaryClass =
-
[15]
An Engorgio Prompt Makes Large Language Model Babble on , volume =
Dong, Jianshuo and Zhang, Ziyuan and Zhang, Qingjie and Zhang, Tianwei and Wang, Hao and Li, Hewu and Li, Qi and Zhang, Chao and Xu, Ke and Qiu, Han , booktitle =. An Engorgio Prompt Makes Large Language Model Babble on , volume =
-
[16]
The Twelfth International Conference on Learning Representations , year=
Inducing High Energy-Latency of Large Vision-Language Models with Verbose Images , author=. The Twelfth International Conference on Learning Representations , year=
-
[17]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models. arXiv e-prints , keywords =. doi:10.48550/arXiv.2302.13971 , archivePrefix =. 2302.13971 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971
-
[18]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
work page 2022
-
[19]
30th USENIX Security Symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX Security Symposium (USENIX Security 21) , pages=
-
[20]
Open O3: the most intelligent and powerful model to date, with full access to all tools , year =
-
[21]
Gemini 2.5 Flash: Best for fast performance on everyday tasks , year =
-
[22]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv e-prints , keywords =. doi:10.48550/arXiv.2501.12948 , archivePrefix =. 2501.12948 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948
-
[23]
Qwen3-Next-80B-A3B-Thinking: The power of scaling rl, October 2025
Qwen , howpublished =. Qwen3-Next-80B-A3B-Thinking: The power of scaling rl, October 2025. , year =
work page 2025
-
[24]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Are NLP Models really able to Solve Simple Math Word Problems?
Patel, Arkil and Bhattamishra, Satwik and Goyal, Navin. Are NLP Models really able to Solve Simple Math Word Problems?. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.168
-
[26]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[27]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Wang, Xinyi and Amayuelas, Alfonso and Zhang, Kexun and Pan, Liangming and Chen, Wenhu and Wang, William Yang , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[28]
Innate Reasoning is Not Enough: In-Context Learning Enhances Reasoning Large Language Models with Less Overthinking. arXiv e-prints , keywords =. doi:10.48550/arXiv.2503.19602 , archivePrefix =. 2503.19602 , primaryClass =
-
[29]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Lee, Harrison and Phatale, Samrat and Mansoor, Hassan and Mesnard, Thomas and Ferret, Johan and Lu, Kellie and Bishop, Colton and Hall, Ethan and Carbune, Victor and Rastogi, Abhinav and Prakash, Sushant , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[30]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv e-prints , keywords =. doi:10.48550/arXiv.2204.05862 , archivePrefix =. 2204.05862 , primaryClass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862
-
[31]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Gradient-based adversarial attacks against text transformers , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2021
-
[32]
arXiv preprint arXiv:2510.15965 , year=
One Token Embedding Is Enough to Deadlock Your Large Reasoning Model , author=. arXiv preprint arXiv:2510.15965 , year=
-
[33]
arXiv preprint arXiv:2508.19277 , year=
Pot: Inducing overthinking in llms via black-box iterative optimization , author=. arXiv preprint arXiv:2508.19277 , year=
-
[34]
arXiv preprint arXiv:2512.07086 , year=
ThinkTrap: Denial-of-Service Attacks against Black-box LLM Services via Infinite Thinking , author=. arXiv preprint arXiv:2512.07086 , year=
-
[35]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Explaining answers with entailment trees , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
work page 2021
-
[37]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.