Recognition: 2 theorem links
· Lean TheoremQuery-Conditioned Test-Time Self-Training for Large Language Models
Pith reviewed 2026-05-15 05:50 UTC · model grok-4.3
The pith
Large language models can adapt their own parameters during inference by generating training examples directly from the input query.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
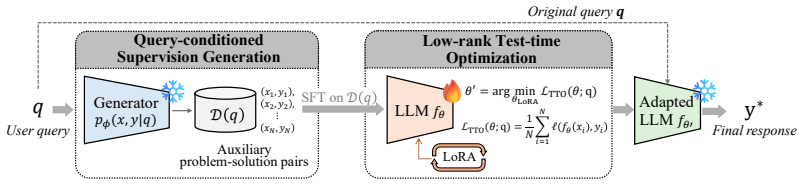
QueST generates query-conditioned problem-solution pairs from latent signals in the input query, uses those pairs as supervision for parameter-efficient fine-tuning during inference, and produces the final answer with the adapted model.
What carries the argument
Query-conditioned pair generation that supplies self-supervised examples for test-time parameter-efficient fine-tuning.
Load-bearing premise
The input query itself encodes latent signals sufficient for constructing structurally related problem-solution pairs.
What would settle it
On a benchmark query, the generated pairs produce no accuracy gain or a drop relative to the base model when the pairs lack structural alignment with the original query.
Figures






read the original abstract
Large language models (LLMs) are typically deployed with fixed parameters, and their performance is often improved by allocating more computation at inference time. While such test-time scaling can be effective, it cannot correct model misconceptions or adapt the model to the specific structure of an individual query. Test-time optimization addresses this limitation by enabling parameter updates during inference, but existing approaches either rely on external data or optimize generic self-supervised objectives that lack query-specific alignment. In this work, we propose Query-Conditioned Test-Time Self-Training (QueST), a framework that adapts model parameters during inference using supervision derived directly from the input query. Our key insight is that the input query itself encodes latent signals sufficient for constructing structurally related problem--solution pairs. Based on this, QueST generates such query-conditioned pairs and uses them as supervision for parameter-efficient fine-tuning at test time. The adapted model is then used to produce the final answer, enabling query-specific adaptation without any external data. Across seven mathematical reasoning benchmarks and the GPQA-Diamond scientific reasoning benchmark, QueST consistently outperforms strong test-time optimization baselines. These results demonstrate that query-conditioned self-training is an effective and practical paradigm for test-time adaptation in LLMs. Code is available at https://chssong.github.io/Query-Conditioned-TTST/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Query-Conditioned Test-Time Self-Training (QueST), which generates structurally related problem-solution pairs directly from an input query and uses them as supervision for parameter-efficient fine-tuning at test time. The adapted model then produces the final answer, enabling query-specific adaptation of LLMs without external data. Experiments show consistent outperformance over strong test-time optimization baselines on seven mathematical reasoning benchmarks and GPQA-Diamond.
Significance. If the central empirical claims hold after addressing validation gaps, the work would be significant for demonstrating a practical, data-free mechanism for query-specific test-time adaptation in LLMs. It directly addresses limitations of fixed-parameter models and generic self-supervised objectives by tying adaptation to query-derived supervision, with potential implications for reasoning tasks where external data is unavailable.
major comments (2)
- [Abstract and Experiments] The central empirical claim of consistent outperformance rests on the quality of query-conditioned pairs used for supervision, yet the manuscript provides no reported accuracy metrics, human evaluation, or ablation isolating pair-generation quality from the adaptation step (see abstract and experimental results). Without this, it remains unclear whether gains arise from genuine learning or other test-time mechanisms.
- [Method] The key assumption that the input query encodes latent signals sufficient for constructing accurate, transferable problem-solution pairs is load-bearing but untested against the risk of error reinforcement: when the base model errs on the query, generated pairs are likely to contain analogous mistakes that fine-tuning then entrenches (see method description and skeptic analysis of self-supervision).
minor comments (2)
- [Implementation Details] Clarify the exact prompting strategy and temperature settings used for pair generation to allow reproducibility.
- [Results] Add statistical significance tests (e.g., p-values or confidence intervals) for the reported benchmark improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating where revisions will be made to strengthen the empirical validation and discussion of assumptions.
read point-by-point responses
-
Referee: [Abstract and Experiments] The central empirical claim of consistent outperformance rests on the quality of query-conditioned pairs used for supervision, yet the manuscript provides no reported accuracy metrics, human evaluation, or ablation isolating pair-generation quality from the adaptation step (see abstract and experimental results). Without this, it remains unclear whether gains arise from genuine learning or other test-time mechanisms.
Authors: We agree that direct validation of pair quality would strengthen the central claims. The manuscript currently emphasizes end-to-end benchmark gains, but to isolate the contribution of the generated pairs, we will add an ablation comparing full QueST against a variant that performs adaptation without query-conditioned pairs (e.g., using generic self-supervision). We will also report automatic accuracy metrics for generated pairs on a held-out subset and include a small-scale human evaluation of pair correctness. These additions will clarify the source of improvements. revision: yes
-
Referee: [Method] The key assumption that the input query encodes latent signals sufficient for constructing accurate, transferable problem-solution pairs is load-bearing but untested against the risk of error reinforcement: when the base model errs on the query, generated pairs are likely to contain analogous mistakes that fine-tuning then entrenches (see method description and skeptic analysis of self-supervision).
Authors: This concern about error reinforcement is well-taken for any self-supervised test-time method. Our approach generates multiple diverse pairs per query to provide a richer supervision signal, which we expect to dilute isolated errors. Nevertheless, the manuscript does not include targeted analysis of this risk. In revision we will expand the method section with a dedicated discussion of potential error propagation and add an experiment analyzing adaptation outcomes specifically on queries where the base model initially produces incorrect answers, to quantify whether performance improves or degrades in those cases. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central proposal is a test-time adaptation procedure that generates query-conditioned problem-solution pairs from the input query and applies them as supervision for parameter-efficient fine-tuning before producing the final answer. This construction does not reduce any claimed prediction or result to its own inputs by definition, nor does it rely on fitted parameters renamed as predictions, self-citation load-bearing uniqueness theorems, or ansatz smuggling. The method is presented as an empirical framework whose effectiveness is evaluated against external benchmarks across multiple datasets, with no equations or derivations that collapse tautologically to the query itself. The approach remains self-contained and falsifiable through reported performance gains rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Input queries encode latent signals sufficient for constructing structurally related problem-solution pairs
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our key insight is that the input query itself encodes latent signals sufficient for constructing structurally related problem–solution pairs.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LTTO(θ;q) = 1/N Σ ℓ(fθ(xi), yi) … LoRA-based updates at test time
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Guhao Feng, Shengjie Luo, Kai Hua, Ge Zhang, Wenhao Huang, Di He, and Tianle Cai. In-place test-time training. InInternational Conference on Learning Representations (ICLR), 2026. URL https://arxiv.org/abs/2604.06169. Oral Presentation
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Test-time training on nearest neighbors for large language models
Moritz Hardt and Yu Sun. Test-time training on nearest neighbors for large language models. arXiv preprint arXiv:2305.18466, 2023
-
[6]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
work page 2024
-
[7]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[9]
Test-time learning for large language models.arXiv preprint arXiv:2505.20633, 2025
Jinwu Hu, Zhitian Zhang, Guohao Chen, Xutao Wen, Chao Shuai, Wei Luo, Bin Xiao, Yuan- qing Li, and Mingkui Tan. Test-time learning for large language models.arXiv preprint arXiv:2505.20633, 2025
-
[10]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Srinivasan Iyer, Xi Victoria Lin, Ramakanth Pasunuru, Todor Mihaylov, Daniel Simig, Ping Yu, Kurt Shuster, Tianlu Wang, Qing Liu, Punit Singh Koura, et al. Opt-iml: Scaling language model instruction meta learning through the lens of generalization.arXiv preprint arXiv:2212.12017, 2022
-
[12]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
work page 2022
-
[13]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
work page 2022
-
[14]
Yafu Li, Xuyang Hu, Xiaoye Qu, Linjie Li, and Yu Cheng. Test-time preference optimization: On-the-fly alignment via iterative textual feedback.arXiv preprint arXiv:2501.12895, 2025
-
[15]
Jian Liang, Ran He, and Tieniu Tan. A comprehensive survey on test-time adaptation under distribution shifts.International Journal of Computer Vision, 133(1):31–64, 2025. 10
work page 2025
-
[16]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
work page 2023
-
[17]
Spice: Self-play in corpus environments improves reasoning.arXiv, 2025
Bo Liu, Chuanyang Jin, Seungone Kim, Weizhe Yuan, Wenting Zhao, Ilia Kulikov, Xian Li, Sainbayar Sukhbaatar, Jack Lanchantin, and Jason Weston. Spice: Self-play in corpus environments improves reasoning.arXiv preprint arXiv:2510.24684, 2025
-
[18]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
work page 2023
-
[19]
MAA Invitational Competitions: American Invitational Mathematics Examination
Mathematical Association of America. MAA Invitational Competitions: American Invitational Mathematics Examination. https://maa.org/maa-invitational-competitions/, 2026. Accessed: 2026-05-05
work page 2026
-
[20]
American Mathematics Competitions
Mathematical Association of America. American Mathematics Competitions. https://maa. org/student-programs/amc/, 2026. Accessed: 2026-05-05
work page 2026
-
[21]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025
work page 2025
-
[22]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[23]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Minseok Seo, Mark Hamilton, and Changick Kim. Upsample anything: A simple and hard to beat baseline for feature upsampling.arXiv preprint arXiv:2511.16301, 2025
-
[25]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[26]
Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driess- che, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mas- tering the game of go with deep neural networks and tree search.nature, 529(7587):484–489, 2016
work page 2016
-
[27]
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play.Science, 362(6419):1140–1144, 2018
work page 2018
-
[28]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[30]
Learning to summarize with human feedback
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. Advances in neural information processing systems, 33:3008–3021, 2020. 11
work page 2020
-
[31]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
-
[33]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Yiming Wang, Pei Zhang, Siyuan Huang, Baosong Yang, Zhuosheng Zhang, Fei Huang, and Rui Wang. Sampling-efficient test-time scaling: Self-estimating the best-of-n sampling in early decoding.arXiv preprint arXiv:2503.01422, 2025
-
[35]
Self-instruct: Aligning language models with self-generated instruc- tions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
work page 2023
-
[36]
Zengzhi Wang, Fan Zhou, Xuefeng Li, and Pengfei Liu. Octothinker: Mid-training incentivizes reinforcement learning scaling.arXiv preprint arXiv:2506.20512, 2025
-
[37]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[40]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Cai Zhou, Zekai Wang, Menghua Wu, Qianyu Julie Zhu, Flora C Shi, Chenyu Wang, Ashia Wilson, Tommi Jaakkola, and Stephen Bates. Online reasoning calibration: Test-time training enables generalizable conformal llm reasoning.arXiv preprint arXiv:2604.01170, 2026
-
[42]
cos θ cannot be less than −1, so there must be a mistake
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InThe eleventh international conference on learning representations, 2022. 12 A Implementation Details A.1 Detailed Hyperparameters Table 4 reports the complete set of hyperparameters used in our Q...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.