Recognition: unknown
FPGA-Accelerated Lock Management and Transaction Processing: Architecture, Optimization, and Design Space Exploration
Pith reviewed 2026-05-14 18:39 UTC · model grok-4.3
The pith
Hardware lock agents on FPGA eliminate DRAM accesses to deliver up to 51 times the transaction throughput of CPU baselines in OLTP systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors propose hardware-accelerated lock management and transaction processing for database systems. They design a low-latency lock agent optimized for acquiring and releasing requests, together with a scalable transaction agent that executes the full transaction lifecycle. By integrating lock tables directly into the FPGA hardware, the design removes the DRAM access overhead that limits CPU-based systems. On the TPC-C benchmark this yields up to 51X higher transaction throughput than the CPU baseline.
What carries the argument
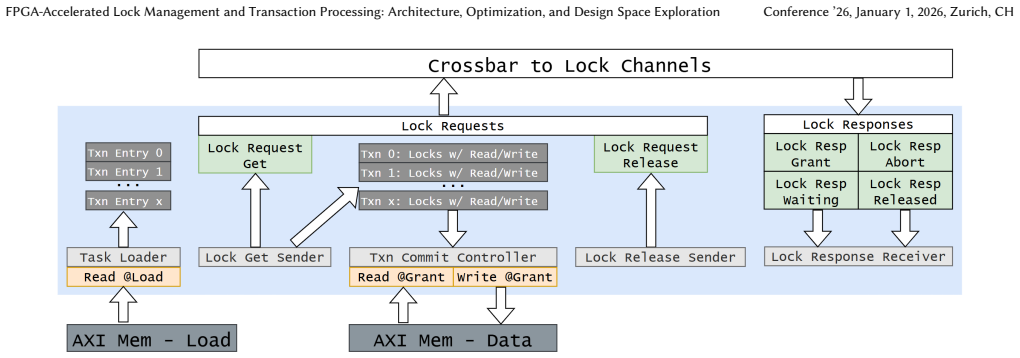
FPGA-integrated lock agent with on-chip lock tables that store lock details locally to avoid DRAM fetches for cold locks.
Load-bearing premise
The FPGA design sustains the reported throughput at scale without new bottlenecks in interconnect, memory hierarchy, or transaction coordination outside the lock agent.
What would settle it
Measuring whether throughput continues to scale linearly on larger TPC-C workloads or plateaus once FPGA memory bandwidth or interconnect saturates.
Figures







read the original abstract
Online Transaction Processing (OLTP) is a classic application with a growing business. CPU-based OLTP has low lock serving efficiency. The main reason is that most locks are cold, and the lock agent must issue frequent memory accesses to retrieve the lock details to determine whether to grant it. This motivates us to propose dedicated hardware-based lock agents with integrated lock tables to remove the DRAM access overhead. In this paper, we propose hardware-accelerated lock management and transaction processing for database systems. First, we propose a low-latency lock agent optimized for both lock acquiring and releasing requests. Second, we design a scalable transaction agent that executes the full transaction lifecycle. We present the architecture, optimizations, and design-space exploration of the proposed lock management and transaction processing system. The experiment results show up to 51X higher transaction throughput over the CPU baseline on the TPC-C benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FPGA-accelerated lock management and transaction processing for OLTP databases. It introduces a low-latency lock agent with an integrated on-chip lock table to eliminate DRAM accesses for cold locks, paired with a scalable transaction agent that handles the full transaction lifecycle. The work details the architecture, optimizations, and design-space exploration, claiming up to 51X higher transaction throughput versus a CPU baseline on the TPC-C benchmark.
Significance. If the performance results hold under scrutiny, the approach demonstrates that dedicated hardware lock agents can remove a key memory-access bottleneck in OLTP, enabling substantially higher throughput on FPGAs and providing a concrete path for hardware acceleration of transaction processing.
major comments (2)
- [Abstract and experimental evaluation] Abstract and experimental evaluation: the 51X TPC-C throughput claim is presented without specifying the CPU baseline configuration (core count, memory hierarchy, lock implementation), measurement methodology, or error bars/variance across runs, leaving the central performance result only moderately supported.
- [Design-space exploration and architecture sections] Design-space exploration and architecture sections: the analysis focuses on per-agent latency and resource usage but provides no quantification of on-chip lock-table occupancy, inter-agent queue depths, or arbitration contention when warehouse count or concurrency is scaled by an order of magnitude, which is required to substantiate that the reported speedup is sustainable.
minor comments (1)
- [Figures and tables] Figure captions and tables would benefit from explicit units and normalization (e.g., throughput in tx/s, resource counts as percentages of device capacity) to improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to provide the requested details and analysis.
read point-by-point responses
-
Referee: [Abstract and experimental evaluation] Abstract and experimental evaluation: the 51X TPC-C throughput claim is presented without specifying the CPU baseline configuration (core count, memory hierarchy, lock implementation), measurement methodology, or error bars/variance across runs, leaving the central performance result only moderately supported.
Authors: We agree that the abstract and experimental evaluation section should include these details to strengthen the central claim. In the revised manuscript we will specify the CPU baseline (core count, memory hierarchy, and lock implementation), describe the measurement methodology, and report error bars or variance across runs. revision: yes
-
Referee: [Design-space exploration and architecture sections] Design-space exploration and architecture sections: the analysis focuses on per-agent latency and resource usage but provides no quantification of on-chip lock-table occupancy, inter-agent queue depths, or arbitration contention when warehouse count or concurrency is scaled by an order of magnitude, which is required to substantiate that the reported speedup is sustainable.
Authors: We acknowledge the need for explicit scalability quantification. We will extend the design-space exploration sections to report on-chip lock-table occupancy, inter-agent queue depths, and arbitration contention at warehouse counts and concurrency levels scaled by an order of magnitude. revision: yes
Circularity Check
No circularity: throughput claims rest on direct FPGA-vs-CPU experiments
full rationale
The paper presents an FPGA architecture for lock management and transaction processing, with integrated on-chip lock tables to eliminate DRAM accesses. The central result (up to 51X TPC-C throughput) is obtained by running the implemented design against a CPU baseline on the same benchmark. No equations, fitted parameters, or self-citations are used to derive the speedup; the number is measured directly from hardware execution. The design-space exploration reports resource usage and latency but does not substitute for the empirical comparison. No self-definitional loops, renamed known results, or load-bearing self-citations appear in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude Barthels, Ingo Müller, Konstantin Taranov, Gustavo Alonso, and Torsten Hoefler. 2019. Strong consistency is not hard to get: Two-Phase Locking and Two-Phase Commit on Thousands of Cores.Proceedings of the VLDB Endowment 12, 13 (2019), 2325–2338
work page 2019
-
[2]
Hal Berenson, Phil Bernstein, Jim Gray, Jim Melton, Elizabeth O’Neil, and Patrick O’Neil. 1995. A critique of ANSI SQL isolation levels. InProceedings of the 1995 ACM SIGMOD International Conference on Management of Data (SIGMOD ’95)
work page 1995
-
[3]
Bernstein, Vassos Hadzilacos, and Nathan Goodman
Philip A. Bernstein, Vassos Hadzilacos, and Nathan Goodman. 1987.Concurrency Control and Recovery in Database Systems. Addison-Wesley
work page 1987
-
[4]
Wei Cao, Feifei Li, Gui Huang, Jianghang Lou, Jianwei Zhao, Dengcheng He, Mengshi Sun, Yingqiang Zhang, Sheng Wang, Xueqiang Wu, et al. 2022. Polardb- x: An elastic distributed relational database for cloud-native applications. In2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 2859–2872
work page 2022
-
[5]
Wei Cao, Yang Liu, Zhushi Cheng, Ning Zheng, Wei Li, Wenjie Wu, Linqiang Ouyang, Peng Wang, Yijing Wang, Ray Kuan, Zhenjun Liu, Feng Zhu, and Tong Zhang. 2020. POLARDB meets computational storage: efficiently support ana- lytical workloads in cloud-native relational database. InProceedings of the 18th USENIX Conference on File and Storage Technologies (FAST’20)
work page 2020
-
[6]
Monica Chiosa, Fabio Maschi, Ingo Müller, Gustavo Alonso, and Norman May
-
[7]
Proceedings of the VLDB Endowment(2022)
Hardware acceleration of compression and encryption in SAP HANA. Proceedings of the VLDB Endowment(2022)
work page 2022
-
[8]
James C Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, Jeffrey John Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, et al. 2013. Spanner: Google’s globally distributed database. ACM Transactions on Computer Systems (TOCS)31, 3 (2013), 1–22
work page 2013
-
[9]
Jonas Dann, Daniel Ritter, and Holger Fröning. 2023. Non-relational Databases on FPGAs: Survey, Design Decisions, Challenges.ACM Comput. Surv.55, 11, Article 225 (Feb. 2023), 37 pages. doi:10.1145/3568990
-
[10]
Jian Fang, Yvo TB Mulder, Jan Hidders, Jinho Lee, and H Peter Hofstee. 2020. In-memory database acceleration on FPGAs: a survey.The VLDB Journal29, 1 (2020), 33–59
work page 2020
-
[11]
Yuanwei Fang, Chen Zou, and Andrew A. Chien. 2019. Accelerating raw data analysis with the ACCORDA software and hardware architecture.Proceedings of the VLDB Endowment(2019)
work page 2019
-
[12]
Jian Gao, Youyou Lu, Minhui Xie, Qing Wang, and Jiwu Shu. 2023. CITRON: distributed range lock management with one-sided RDMA. InProceedings of the 21st USENIX Conference on File and Storage Technologies (FAST’23)
work page 2023
-
[13]
1992.Transaction processing: concepts and techniques
James Gray and Andreas Reuter. 1992.Transaction processing: concepts and techniques. Morgan Kaufmann Publishers
work page 1992
-
[14]
J. N. Gray, R. A. Lorie, and G. R. Putzolu. 1975. Granularity of Locks in a Shared Data Base. InProceedings of the 1st International Conference on Very Large Data Bases (VLDB ’75). ACM, New York, NY, USA, 428–451. doi:10.1145/1282480. 1282513
-
[15]
Gui Huang, Xuntao Cheng, Jianying Wang, Yujie Wang, Dengcheng He, Tieying Zhang, Feifei Li, Sheng Wang, Wei Cao, and Qiang Li. 2019. X-Engine: An Optimized Storage Engine for Large-scale E-commerce Transaction Processing. InProceedings of the 2019 International Conference on Management of Data
work page 2019
-
[16]
Yoon, Jeong-Uk Kang, Sangyeun Cho, Daniel D
Insoon Jo, Duck-Ho Bae, Andre S. Yoon, Jeong-Uk Kang, Sangyeun Cho, Daniel D. G. Lee, and Jaeheon Jeong. 2016. YourSQL: a high-performance database system leveraging in-storage computing.Proceedings of the VLDB Endowment (2016)
work page 2016
-
[17]
Martin Kiefer, Ilias Poulakis, Eleni Tzirita Zacharatou, and Volker Markl. 2023. Optimistic Data Parallelism for FPGA-Accelerated Sketching.Proceedings of the VLDB Endowment(2023)
work page 2023
-
[18]
Dario Korolija, Timothy Roscoe, and Gustavo Alonso. 2020. Do OS abstractions make sense on FPGAs?. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, 991–1010. https://www. usenix.org/conference/osdi20/presentation/roscoe
work page 2020
-
[19]
Jordan Leggett, John McGlone, Suleyman Demirsoy, Christian Faerber, and Vadim Pelyushenko. 2025. Accelerating In-memory Database Functionality with FPGAs. ACM Trans. Reconfigurable Technol. Syst.18, 1, Article 13 (Jan. 2025), 23 pages. doi:10.1145/3706113
-
[20]
Ke Liu, Haonan Tong, Zhongxiang Sun, Zhixin Ren, Guangkui Huang, Hongyin Zhu, Luyang Liu, Qunyang Lin, and Chuang Zhang. 2024. Integrating FPGA- based hardware acceleration with relational databases.Parallel Comput.119 (2024), 103064
work page 2024
-
[21]
Alec Lu, Jahanvi Narendra Agrawal, and Zhenman Fang. 2024. Sql2fpga: Auto- mated acceleration of sql query processing on modern cpu-fpga platforms.ACM Transactions on Reconfigurable Technology and Systems17, 3 (2024), 1–28
work page 2024
-
[22]
Thomas Neumann, Tobias Mühlbauer, and Alfons Kemper. 2015. Fast serializ- able multi-version concurrency control for main-memory database systems. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. 677–689
work page 2015
-
[23]
Pedro Ramalhete, Andreia Correia, and Pascal Felber. 2023. 2plsf: Two-phase locking with starvation-freedom. InProceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 39–51
work page 2023
-
[24]
Benjamin Ramhorst, Dario Korolija, Maximilian Jakob Heer, Jonas Dann, Luhao Liu, and Gustavo Alonso. 2025. Coyote v2: Raising the Level of Abstraction for Data Center FPGAs. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles(Lotte Hotel World, Seoul, Republic of Korea) (SOSP ’25). Association for Computing Machinery, New York, ...
-
[25]
Kun Ren, Alexander Thomson, and Daniel J Abadi. 2015. VLL: a lock manager redesign for main memory database systems.The VLDB Journal24, 5 (2015), 681–705
work page 2015
-
[26]
Aman Sinha, Shih-Chen Lo, and Bo-Cheng Lai. 2025. Multi-dimensional Range Joins on HBM-enabled FPGAs. In2025 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 1–5
work page 2025
-
[27]
2003.Verilator: the fastest Verilog/SystemVerilog simulator
Wilson Snyder. 2003.Verilator: the fastest Verilog/SystemVerilog simulator. https: //github.com/verilator/verilator
work page 2003
-
[28]
Bharat Sukhwani, Hong Min, Mathew Thoennes, Parijat Dube, Balakrishna Iyer, Bernard Brezzo, Donna Dillenberger, and Sameh Asaad. 2012. Database analytics acceleration using FPGAs. InProceedings of the 21st International Conference on Parallel Architectures and Compilation Techniques(Minneapolis, Minnesota, USA) (PACT ’12). Association for Computing Machin...
-
[29]
2018.SpinalHDL: Spinal Hardware Description Language
SpinalHDL Team. 2018.SpinalHDL: Spinal Hardware Description Language. https: //github.com/SpinalHDL/SpinalHDL
work page 2018
-
[30]
Alexander Thomasian. 1993. Two-phase locking performance and its thrashing behavior.ACM Transactions on Database Systems (TODS)18, 4 (1993), 579–625
work page 1993
-
[31]
Boyu Tian, Jiamin Huang, Barzan Mozafari, and Grant Schoenebeck. 2018. Contention-aware lock scheduling for transactional databases.Proceedings of the VLDB Endowment11, 5 (2018), 648–662
work page 2018
-
[32]
Louis Woods, Jens Teubner, and Gustavo Alonso. 2013. Less watts, more perfor- mance: an intelligent storage engine for data appliances. InProceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD’13
work page 2013
-
[33]
Yingjun Wu, Joy Arulraj, Jiexi Lin, Ran Xian, and Andrew Pavlo. 2017. An em- pirical evaluation of in-memory multi-version concurrency control.Proceedings of the VLDB Endowment10, 7 (2017), 781–792
work page 2017
-
[34]
Dong Young Yoon, Mosharaf Chowdhury, and Barzan Mozafari. 2018. Distributed Lock Management with RDMA: Decentralization without Starvation. InProceed- ings of the 2018 International Conference on Management of Data (SIGMOD ’18)
work page 2018
-
[35]
Xiangyao Yu, George Bezerra, Andrew Pavlo, Srinivas Devadas, and Michael Stonebraker. 2014. Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores. InProceedings of the VLDB Endowment
work page 2014
-
[36]
Erfan Zamanian, Carsten Binnig, Tim Kraska, and Tim Harris. 2017. The End of a Myth: Distributed Transaction Can Scale.Proceedings of the VLDB Endow. (2017)
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.