Recognition: unknown
Causality-Aware End-to-End Autonomous Driving via Ego-Centric Joint Scene Modeling
Pith reviewed 2026-05-14 18:21 UTC · model grok-4.3
The pith
CaAD models causal dependencies between the ego vehicle and surrounding agents inside a shared latent scene representation to produce more consistent closed-loop trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
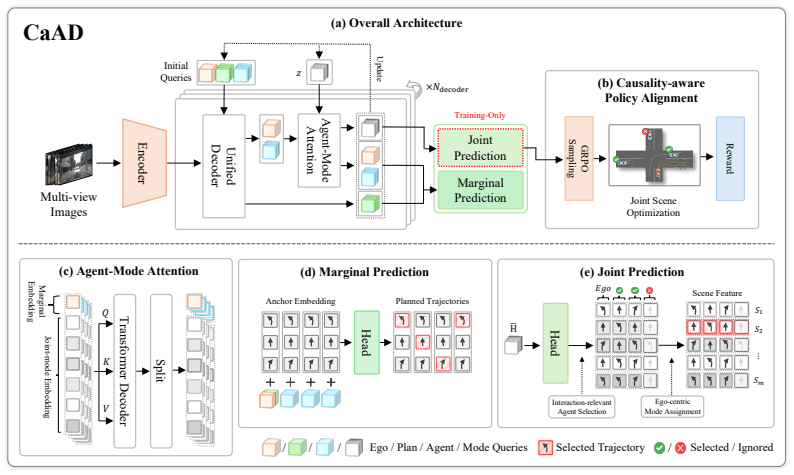
CaAD builds an ego-centric joint-causal modeling module on marginal prediction branches that learns causal dependencies between the ego vehicle and interaction-relevant agents inside a shared latent scene representation, then applies a causality-aware policy alignment stage that uses joint-mode embeddings to match the stochastic ego policy to planning-oriented closed-loop feedback computed from surrounding traffic and map context.
What carries the argument
ego-centric joint-causal modeling module that learns dependencies between ego and agents in a shared latent scene representation
If this is right
- Produces more consistent trajectory predictions in interaction-critical scenarios.
- Achieves a Driving Score of 87.53 and Success Rate of 71.81 on Bench2Drive.
- Records a PDMS of 91.1 on NAVSIM.
- Aligns the stochastic ego policy with closed-loop feedback from traffic and maps via joint-mode embeddings.
Where Pith is reading between the lines
- The same joint-causal structure could be tested on multi-agent coordination tasks outside driving.
- Joint-mode embeddings may allow uncertainty estimates to propagate more cleanly into planning decisions.
- Removing the alignment stage would isolate how much of the reported gain comes from causal modeling versus closed-loop feedback.
Load-bearing premise
The joint-causal module learns genuine causal relations rather than mere statistical correlations between ego actions and agent behaviors.
What would settle it
A controlled test in which surrounding agents are forced to respond differently to the same ego actions and the model is checked for whether trajectory consistency collapses relative to a correlation-only baseline.
Figures



read the original abstract
End-to-end autonomous driving, which bypasses traditional modular pipelines by directly predicting future trajectories from sensor inputs, has recently achieved substantial progress. However, existing methods often overlook the causal inter-dependencies in ego-vehicle planning, ignoring the reciprocal relations between the ego vehicle and surrounding agents. This causal oversight leads to inconsistent and unreliable trajectory predictions, especially in interaction-critical scenarios where ego decisions and neighboring agent behaviors must be reasoned about jointly. To address this limitation, we propose CaAD, a Causality-aware end-to-end Autonomous Driving framework that captures these dependencies within a shared latent scene representation. First, we propose a ego-centric joint-causal modeling module that builds on the marginal prediction branch, and learns causal dependencies between the ego vehicle and interaction-relevant agents. Second, we employ a causality-aware policy alignment stage implemented with joint-mode embeddings to align the stochastic ego policy with planning-oriented closed-loop feedback computed from surrounding traffic and map context. On the Bench2Drive and NAVSIM benchmarks, CaAD demonstrates strong closed-loop planning performance, achieving a Driving Score of 87.53 and Success Rate of 71.81 on Bench2Drive, and a PDMS of 91.1 on NAVSIM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CaAD, a causality-aware end-to-end autonomous driving framework that captures reciprocal dependencies between the ego vehicle and surrounding agents within a shared latent scene representation. It introduces an ego-centric joint-causal modeling module built on the marginal prediction branch and a subsequent causality-aware policy alignment stage that uses joint-mode embeddings to align the stochastic ego policy with closed-loop feedback from traffic and map context. The method is evaluated on Bench2Drive and NAVSIM, reporting a Driving Score of 87.53 and Success Rate of 71.81 on Bench2Drive together with a PDMS of 91.1 on NAVSIM.
Significance. If the joint-causal module and policy alignment demonstrably recover genuine causal structure rather than correlations, the framework could improve consistency of closed-loop trajectories in interaction-critical scenarios, addressing a recognized limitation of existing end-to-end planners that treat ego and agent behaviors independently.
major comments (2)
- [Abstract] Abstract: the reported benchmark gains (DS 87.53, SR 71.81 on Bench2Drive; PDMS 91.1 on NAVSIM) are presented without any description of baselines, ablation studies, statistical significance, error bars, or training/validation protocols for the causal modules, so it is impossible to determine whether the improvements are attributable to the claimed causality mechanisms.
- [§3 and §4] §3 (Ego-Centric Joint-Causal Modeling) and §4 (Causality-Aware Policy Alignment): no structural assumptions, interventions, counterfactual regularization, or identifiability constraints are stated that would enforce recovery of causal dependencies rather than observed correlations; in the absence of such constraints, performance gains on closed-loop benchmarks could arise from richer feature fusion alone, leaving the central causality claim unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported benchmark gains (DS 87.53, SR 71.81 on Bench2Drive; PDMS 91.1 on NAVSIM) are presented without any description of baselines, ablation studies, statistical significance, error bars, or training/validation protocols for the causal modules, so it is impossible to determine whether the improvements are attributable to the claimed causality mechanisms.
Authors: We agree that the abstract should provide more context on the evaluation. In the revised manuscript, we will expand the abstract to briefly reference the primary baselines, note the key ablation studies performed, and direct readers to Section 5 for full training/validation protocols, statistical significance tests, and error bars on the reported metrics. revision: yes
-
Referee: [§3 and §4] §3 (Ego-Centric Joint-Causal Modeling) and §4 (Causality-Aware Policy Alignment): no structural assumptions, interventions, counterfactual regularization, or identifiability constraints are stated that would enforce recovery of causal dependencies rather than observed correlations; in the absence of such constraints, performance gains on closed-loop benchmarks could arise from richer feature fusion alone, leaving the central causality claim unsupported.
Authors: We partially agree. The current text does not state explicit structural causal assumptions, interventions, or identifiability constraints. In the revision we will add a dedicated paragraph in §3 clarifying the modeling assumptions (including conditional independencies under the ego-centric view) and will include new ablation experiments in §5 that isolate the joint-mode alignment from generic feature fusion. We maintain that the closed-loop policy alignment provides consistency benefits beyond correlation capture, but acknowledge the need for clearer exposition. revision: partial
- Demonstrating recovery of genuine causal structure (rather than correlations) via interventions or counterfactual regularization, as the Bench2Drive and NAVSIM benchmarks do not contain interventional data and such experiments lie outside the current scope.
Circularity Check
No circularity in derivation chain; claims rest on external benchmarks
full rationale
The paper introduces CaAD via an ego-centric joint-causal modeling module and a causality-aware policy alignment stage using joint-mode embeddings, then reports closed-loop metrics (Driving Score 87.53, Success Rate 71.81 on Bench2Drive; PDMS 91.1 on NAVSIM). No equations, derivations, or fitted-parameter reductions appear in the provided text that would make any prediction equivalent to its inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the causal modeling. The performance numbers are external benchmark evaluations rather than internal self-predictions, so the central claims do not reduce to tautology or self-referential fitting.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal dependencies between the ego vehicle and surrounding agents can be learned from data within a shared latent scene representation
Reference graph
Works this paper leans on
-
[1]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[2]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. nuplan: A closed-loop ml-based planning bench- mark for autonomous vehicles.arXiv preprint arXiv:2106.11810, 2021
work page internal anchor Pith review arXiv 2021
-
[3]
Gri: General reinforced imitation and its application to vision-based autonomous driving.Robotics, 12(5):127, 2023
Raphael Chekroun, Marin Toromanoff, Sascha Hornauer, and Fabien Moutarde. Gri: General reinforced imitation and its application to vision-based autonomous driving.Robotics, 12(5):127, 2023
2023
-
[4]
End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
2024
-
[5]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Neat: Neural attention fields for end- to-end autonomous driving
Kashyap Chitta, Aditya Prakash, and Andreas Geiger. Neat: Neural attention fields for end- to-end autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15793–15803, 2021
2021
-
[7]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
2022
-
[8]
Parting with mis- conceptions about learning-based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with mis- conceptions about learning-based vehicle motion planning. InConference on Robot Learning, pages 1268–1281. PMLR, 2023
2023
-
[9]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024
2024
-
[10]
D’Souza, Samira Ebrahimi Kahou, Felix Heide, and Christopher Pal
Roger Girgis, Florian Golemo, Felipe Codevilla, Martin Weiss, Justin A. D’Souza, Samira Ebrahimi Kahou, Felix Heide, and Christopher Pal. Latent variable sequential set transformers for joint multi-agent motion prediction. InInternational Conference on Learning Representations, 2022
2022
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[13]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[14]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024. 10
2024
-
[16]
Xiaosong Jia, Junqi You, Zhiyuan Zhang, and Junchi Yan. Drivetransformer: Unified transformer for scalable end-to-end autonomous driving.arXiv preprint arXiv:2503.07656, 2025
-
[17]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
2023
-
[18]
Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, and Xinggang Wang. Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reasoning.arXiv preprint arXiv:2503.07608, 2025
-
[19]
Jungho Kim, Jiyong Oh, Seunghoon Yu, Hongjae Shin, Donghyuk Kwak, and Jun Won Choi. Safedrive: Fine-grained safety reasoning for end-to-end driving in a sparse world.arXiv preprint arXiv:2602.18887, 2026
-
[20]
Derun Li, Changye Li, Yue Wang, Jianwei Ren, Xin Wen, Pengxiang Li, Leimeng Xu, Kun Zhan, Peng Jia, Xianpeng Lang, et al. Learning personalized driving styles via reinforcement learning from human feedback.arXiv preprint arXiv:2503.10434, 2025
-
[21]
Kailin Li, Zhenxin Li, Shiyi Lan, Yuan Xie, Zhizhong Zhang, Jiayi Liu, Zuxuan Wu, Zhiding Yu, and Jose M Alvarez. Hydra-mdp++: Advancing end-to-end driving via expert-guided hydra-distillation.arXiv preprint arXiv:2503.12820, 2025
-
[22]
Think2drive: Efficient reinforcement learning by thinking with latent world model for autonomous driving (in carla-v2)
Qifeng Li, Xiaosong Jia, Shaobo Wang, and Junchi Yan. Think2drive: Efficient reinforcement learning by thinking with latent world model for autonomous driving (in carla-v2). InEuropean Conference on Computer Vision, pages 142–158. Springer, 2024
2024
-
[23]
arXiv preprint arXiv:2406.08481 (2024) 2, 4, 6, 10, 11, 13
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, and Tieniu Tan. Enhancing end-to-end autonomous driving with latent world model.arXiv preprint arXiv:2406.08481, 2024
-
[24]
arXiv preprint arXiv:2504.01941 (2025) 4, 10, 11, 13
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025
-
[25]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Hydra-next: Robust closed-loop driving with open-loop training.arXiv preprint arXiv:2503.12030, 2025
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zuxuan Wu, and Jose M Alvarez. Hydra-next: Robust closed-loop driving with open-loop training.arXiv preprint arXiv:2503.12030, 2025
-
[27]
Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[28]
Cirl: Controllable imitative rein- forcement learning for vision-based self-driving
Xiaodan Liang, Tairui Wang, Luona Yang, and Eric Xing. Cirl: Controllable imitative rein- forcement learning for vision-based self-driving. InProceedings of the European conference on computer vision (ECCV), pages 584–599, 2018
2018
-
[29]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[30]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar. Focal loss for dense object detection. InProceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
2017
-
[31]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation
Zhijian Liu, Haotian Tang, Alexander Amini, Xinyu Yang, Huizi Mao, Daniela L Rus, and Song Han. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In2023 IEEE international conference on robotics and automation (ICRA), pages 2774–2781. IEEE, 2023. 11
2023
-
[32]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios
Yiren Lu, Justin Fu, George Tucker, Xinlei Pan, Eli Bronstein, Rebecca Roelofs, Benjamin Sapp, Brandyn White, Aleksandra Faust, Shimon Whiteson, et al. Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driving scenarios. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7553–...
2023
-
[34]
JFP: Joint future prediction with interactive multi-agent modeling for autonomous driving
Wenjie Luo, Cheolho Park, Andre Cornman, Benjamin Sapp, and Dragomir Anguelov. JFP: Joint future prediction with interactive multi-agent modeling for autonomous driving. In Proceedings of The 7th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 1457–1467. PMLR, 2023
2023
-
[35]
Visiontrap: Vision-augmented trajectory prediction guided by textual descriptions
Seokha Moon, Hyun Woo, Hongbeen Park, Haeji Jung, Reza Mahjourian, Hyung-gun Chi, Hyerin Lim, Sangpil Kim, and Jinkyu Kim. Visiontrap: Vision-augmented trajectory prediction guided by textual descriptions. InEuropean Conference on Computer Vision, pages 361–379. Springer, 2024
2024
-
[36]
Nigamaa Nayakanti, Rami Al-Rfou, Aurick Zhou, Kratarth Goel, Khaled S Refaat, and Benjamin Sapp. Wayformer: Motion forecasting via simple & efficient attention networks.arXiv preprint arXiv:2207.05844, 2022
-
[37]
arXiv preprint arXiv:2106.08417 (2021)
Jiquan Ngiam, Benjamin Caine, Vijay Vasudevan, Zhengdong Zhang, Hao-Tien Lewis Chiang, Jeffrey Ling, Rebecca Roelofs, Alex Bewley, Chenxi Liu, Ashish Venugopal, et al. Scene transformer: A unified architecture for predicting multiple agent trajectories.arXiv preprint arXiv:2106.08417, 2021
-
[38]
Refaat, Rami Al-Rfou, and Benjamin Sapp
Ari Seff, Brian Cera, Dian Chen, Mason Ng, Aurick Zhou, Nigamaa Nayakanti, Khaled S. Refaat, Rami Al-Rfou, and Benjamin Sapp. MotionLM: Multi-agent motion forecasting as language modeling. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[39]
Shuyao Shang, Yuntao Chen, Yuqi Wang, Yingyan Li, and Zhaoxiang Zhang. Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving.arXiv preprint arXiv:2509.17940, 2025
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Motion transformer with global intention localization and local movement refinement
Shaoshuai Shi, Li Jiang, Dengxin Dai, and Bernt Schiele. Motion transformer with global intention localization and local movement refinement. InAdvances in Neural Information Processing Systems, 2022
2022
-
[42]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving
Ziying Song, Caiyan Jia, Lin Liu, Hongyu Pan, Yongchang Zhang, Junming Wang, Xingyu Zhang, Shaoqing Xu, Lei Yang, and Yadan Luo. Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22432–22441, 2025
2025
-
[43]
Ziying Song, Lin Liu, Hongyu Pan, Bencheng Liao, Mingzhe Guo, Lei Yang, Yongchang Zhang, Shaoqing Xu, Caiyan Jia, and Yadan Luo. Diver: Reinforced diffusion breaks imitation bottlenecks in end-to-end autonomous driving.arXiv preprint arXiv:2507.04049, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
M2i: From factored marginal to joint trajectory prediction for highly interactive environments
Qiao Sun, Xin Huang, Brian C Williams, Hang Zhao, et al. M2i: From factored marginal to joint trajectory prediction for highly interactive environments. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16116–16126, 2022
2022
-
[45]
Wenchao Sun, Xuewu Lin, Keyu Chen, Zixiang Pei, Xiang Li, Yining Shi, and Sifa Zheng. Sparsedrivev2: Scoring is all you need for end-to-end autonomous driving.arXiv preprint arXiv:2603.29163, 2026. 12
-
[46]
Sparsedrive: End-to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. Sparsedrive: End-to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801. IEEE, 2025
2025
-
[47]
Yingqi Tang, Zhuoran Xu, Zhaotie Meng, and Erkang Cheng. Hip-ad: Hierarchical and multi- granularity planning with deformable attention for autonomous driving in a single decoder. arXiv preprint arXiv:2503.08612, 2025
-
[48]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017
2017
-
[49]
RetroMotion: Retrocausal Motion Forecasting Models are Instructable
Royden Wagner, Omer Sahin Tas, Felix Hauser, Marlon Steiner, Dominik Strutz, Abhishek Vivekanandan, Carlos Fernandez, and Christoph Stiller. Retromotion: Retrocausal motion forecasting models are instructable.arXiv preprint arXiv:2505.20414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
arXiv preprint arXiv:2403.05489 , year=
Royden Wagner, Omer Sahin Tas, Marvin Klemp, and Carlos Fernandez. Jointmotion: joint self-supervision for joint motion prediction.arXiv preprint arXiv:2403.05489, 2024
-
[51]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Dia- mond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
-
[52]
Para-drive: Par- allelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Par- allelized architecture for real-time autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449–15458, 2024
2024
-
[53]
Goalflow: Goal-driven flow matching for multimodal trajectories generation in end- to-end autonomous driving
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal-driven flow matching for multimodal trajectories generation in end- to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025
2025
-
[54]
Second: Sparsely embedded convolutional detection.Sensors, 18(10), 2018
Yan Yan, Yuxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection.Sensors, 18(10), 2018
2018
-
[55]
Zhenjie Yang, Xiaosong Jia, Qifeng Li, Xue Yang, Maoqing Yao, and Junchi Yan. Raw2drive: Reinforcement learning with aligned world models for end-to-end autonomous driving (in carla v2).arXiv preprint arXiv:2505.16394, 2025
-
[56]
Center-based 3d object detection and track- ing
Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. Center-based 3d object detection and track- ing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11784–11793, 2021
2021
-
[57]
Zhenlong Yuan, Chengxuan Qian, Jing Tang, Rui Chen, Zijian Song, Lei Sun, Xiangxiang Chu, Yujun Cai, Dapeng Zhang, and Shuo Li. Autodrive-r2: Incentivizing reasoning and self- reflection capacity for vla model in autonomous driving.arXiv preprint arXiv:2509.01944, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
End-to-end interpretable neural motion planner
Wenyuan Zeng, Wenjie Luo, Simon Suo, Abbas Sadat, Bin Yang, Sergio Casas, and Raquel Urtasun. End-to-end interpretable neural motion planner. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8660–8669, 2019
2019
-
[59]
Bozhou Zhang, Nan Song, Jingyu Li, Xiatian Zhu, Jiankang Deng, and Li Zhang. Future-aware end-to-end driving: Bidirectional modeling of trajectory planning and scene evolution.arXiv preprint arXiv:2510.11092, 2025
-
[60]
Jinqing Zhang, Zehua Fu, Zelin Xu, Wenying Dai, Qingjie Liu, and Yunhong Wang. Resworld: Temporal residual world model for end-to-end autonomous driving.arXiv preprint arXiv:2602.10884, 2026
-
[61]
Genad: Gen- erative end-to-end autonomous driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. Genad: Gen- erative end-to-end autonomous driving. InEuropean Conference on Computer Vision, pages 87–104. Springer, 2024. 13
2024
-
[62]
World4drive: End-to-end autonomous driving via intention-aware physical latent world model
Yupeng Zheng, Pengxuan Yang, Zebin Xing, Qichao Zhang, Yuhang Zheng, Yinfeng Gao, Pengfei Li, Teng Zhang, Zhongpu Xia, Peng Jia, et al. World4drive: End-to-end autonomous driving via intention-aware physical latent world model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 28632–28642, 2025
2025
-
[63]
V oxelnet: End-to-end learning for point cloud based 3d object detection
Yin Zhou and Oncel Tuzel. V oxelnet: End-to-end learning for point cloud based 3d object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4490–4499, 2018
2018
-
[64]
Query-centric trajectory prediction
Zikang Zhou, Jianping Wang, Yung-Hui Li, and Yu-Kai Huang. Query-centric trajectory prediction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17863–17873, 2023
2023
-
[65]
Hidden biases of end-to-end driving datasets.arXiv preprint arXiv:2412.09602, 2024
Julian Zimmerlin, Jens Beißwenger, Bernhard Jaeger, Andreas Geiger, and Kashyap Chitta. Hidden biases of end-to-end driving datasets.arXiv preprint arXiv:2412.09602, 2024
-
[66]
Diffusiondrivev2: Reinforcement learning-constrained truncated diffusion modeling in end-to-end autonomous driving, 2025
Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yuehao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, and Xinggang Wang. Diffusiondrivev2: Reinforcement learning-constrained truncated diffusion modeling in end-to-end autonomous driving, 2025. 14 Appendix A Additional Related Work A.1 End-to-End Planning for Autonomous Driving End-to-end autonomous driving ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.