Recognition: 2 theorem links
· Lean TheoremBiSpikCLM: A Spiking Language Model integrating Softmax-Free Spiking Attention and Spike-Aware Alignment Distillation
Pith reviewed 2026-05-15 07:06 UTC · model grok-4.3
The pith
BiSpikCLM creates the first fully binary spiking causal language model that avoids all floating-point matrix multiplications and softmax.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BiSpikCLM integrates Softmax-Free Spiking Attention to remove softmax and floating-point operations from autoregressive attention and applies Spike-Aware Alignment Distillation to align the binary spiking student with a standard ANN teacher across embeddings, attention maps, intermediate features, and output logits, thereby enabling the first fully binary spiking MatMul-free causal language model to attain competitive performance on natural language generation tasks at only 4.16 percent to 5.87 percent of conventional computational cost.
What carries the argument
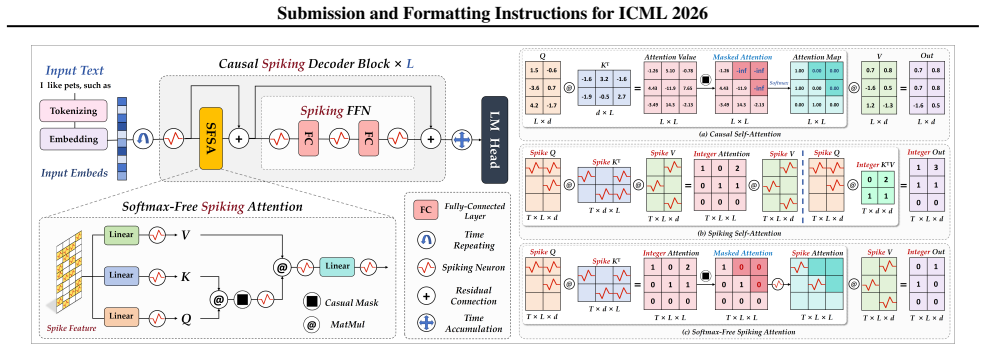
Softmax-Free Spiking Attention (SFSA), which performs attention using only binary spikes without softmax or floating-point arithmetic, and Spike-Aware Alignment Distillation (SpAD), which performs multi-component alignment between ANN teacher and SNN student to support efficient training.
If this is right
- The 1.3B-scale model reaches comparable performance after training on only 5.6 percent of the usual number of tokens.
- All intensive floating-point matrix multiplications and nonlinearities are eliminated from the inference path.
- Fully binary spike-driven language models become feasible without sacrificing autoregressive causal structure.
- Multi-level distillation offers a practical route for scaling brain-inspired spiking NLP architectures.
Where Pith is reading between the lines
- The same SFSA and SpAD combination could be applied to non-language sequence tasks such as time-series forecasting.
- If the efficiency ratio holds at larger scales, the models could run on neuromorphic chips with orders-of-magnitude lower energy per token.
- Binary spike representations may allow further hardware-level optimizations such as event-driven memory access that the paper does not explore.
- Combining the approach with additional compression methods could push the compute fraction even lower while preserving the fully spiking constraint.
Load-bearing premise
Spike-Aware Alignment Distillation can transfer knowledge from the floating-point ANN teacher to the binary SNN student across multiple layers without causing permanent capacity loss or requiring any floating-point operations during inference.
What would settle it
A BiSpikCLM model trained with the proposed SFSA and SpAD methods that exhibits substantially higher perplexity or lower generation quality on standard language-modeling benchmarks than a matched non-spiking baseline at identical scale would falsify the claim of competitive performance.
Figures










read the original abstract
Spiking Neural Networks (SNNs) offer promising energy-efficient alternatives to large language models (LLMs) due to their event-driven nature and ultra-low power consumption. However, to preserve capacity, most existing spiking LLMs still incur intensive floating-point matrix multiplication (MatMul) and nonlinearities, or training difficulties arising from the complex spatiotemporal dynamics. To address these challenges, we propose BiSpikCLM, the first fully binary spiking MatMul-free causal language model. BiSpikCLM introduces Softmax-Free Spiking Attention (SFSA), eliminating softmax and floating-point operations in autoregressive language modeling. For efficient training, we introduce Spike-Aware Alignment Distillation (SpAD), which aligns ANN teacher and SNN student across embeddings, attention maps, intermediate features, and output logits. SpAD framework allows BiSpikCLM to reach comparable performance to ANN counterparts using substantially fewer training tokens (e.g., only 5.6% of the tokens for the 1.3B model). As a result, BiSpikCLM achieves competitive performance at only 4.16% - 5.87% of the computational cost on natural language generation tasks. Our results highlight the feasibility and effectiveness of fully binary spike-driven LLMs and establish the distillation as a promising pathway for brain-inspired spiking NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BiSpikCLM as the first fully binary spiking MatMul-free causal language model. It introduces Softmax-Free Spiking Attention (SFSA) to eliminate softmax and floating-point operations during autoregressive language modeling, along with Spike-Aware Alignment Distillation (SpAD) to align an ANN teacher with an SNN student across embeddings, attention maps, intermediate features, and output logits. This enables training with substantially fewer tokens (e.g., only 5.6% for the 1.3B model) while claiming competitive performance on natural language generation tasks at 4.16%-5.87% of the computational cost of conventional models.
Significance. If the claims of strict binarity, MatMul-freeness at inference, and robust empirical performance are substantiated with proper controls, this would constitute a meaningful advance in energy-efficient spiking neural networks for language modeling. The distillation approach that achieves comparable results with minimal tokens is a clear strength and could inform scalable training of brain-inspired NLP systems.
major comments (2)
- [Abstract] Abstract: The central claim that BiSpikCLM is 'the first fully binary spiking MatMul-free causal language model' with competitive performance at 4.16%-5.87% computational cost rests on empirical results, yet the abstract supplies no error bars, ablation studies, or explicit verification that all operations remain strictly binary and MatMul-free throughout inference. This directly affects the soundness of the primary contribution.
- [SpAD description] SpAD framework (as described in abstract): Alignment of attention maps, intermediate features, and logits between ANN teacher and SNN student typically requires dense floating-point computations; the manuscript must explicitly show that no such operations (e.g., normalization, output projections, or spike-to-float conversions) are present in the student inference path, as any leakage would invalidate both the cost-reduction numbers and the 'fully binary MatMul-free' designation.
minor comments (2)
- [Abstract] Abstract: The computational-cost range (4.16%-5.87%) should reference specific tables or figures that break down the metric (FLOPs, energy, or spike counts) per task for reproducibility.
- [Abstract] Abstract: Clarify whether 'computational cost' refers to training or inference and provide the exact baseline models used for the percentage comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments have prompted us to strengthen the presentation of our empirical validations and to clarify the separation between training and inference paths. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that BiSpikCLM is 'the first fully binary spiking MatMul-free causal language model' with competitive performance at 4.16%-5.87% computational cost rests on empirical results, yet the abstract supplies no error bars, ablation studies, or explicit verification that all operations remain strictly binary and MatMul-free throughout inference. This directly affects the soundness of the primary contribution.
Authors: We agree that the abstract would benefit from additional context. In the revised version we have added a sentence referencing the error bars and standard deviations reported across our main results (Table 2, Figure 3) and the ablation studies in Section 4.3. We have also inserted a brief clause confirming that inference uses only binary spike operations with no floating-point MatMul or softmax, directing readers to the operation-count analysis and pseudocode in Section 3.2 that verify the strict binarity and MatMul-freeness. revision: yes
-
Referee: [SpAD description] SpAD framework (as described in abstract): Alignment of attention maps, intermediate features, and logits between ANN teacher and SNN student typically requires dense floating-point computations; the manuscript must explicitly show that no such operations (e.g., normalization, output projections, or spike-to-float conversions) are present in the student inference path, as any leakage would invalidate both the cost-reduction numbers and the 'fully binary MatMul-free' designation.
Authors: We thank the referee for highlighting this distinction. SpAD is applied solely during training to align the SNN student with the ANN teacher; the student inference path is completely decoupled and uses only the SFSA module with binary spikes. In the revised manuscript we have expanded Section 3.4 with a dedicated inference flowchart and pseudocode that explicitly show the absence of normalization, dense projections, or any spike-to-float conversion at inference time. All operations remain in the binary spike domain, thereby preserving the reported 4.16–5.87 % computational cost. revision: yes
Circularity Check
No significant circularity; claims rest on empirical measurements of novel components
full rationale
The paper introduces SFSA to eliminate softmax and FP MatMul in attention, and SpAD as a distillation procedure that aligns embeddings, attention maps, features, and logits. Performance numbers (4.16%-5.87% cost, competitive accuracy with 5.6% tokens) are presented as measured experimental outcomes on NLG tasks, not as quantities derived by construction from fitted parameters or self-referential definitions. No equation reduces the target result to its own inputs; the derivation chain consists of architectural proposals whose validity is checked externally via benchmarks rather than presupposed.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Spiking neurons can be trained to approximate continuous ANN activations via rate or temporal coding without loss of representational capacity when distillation is applied.
- domain assumption All matrix multiplications and nonlinearities can be replaced by binary spike operations while preserving autoregressive language modeling semantics.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Breath1024.leanperiod8 / flipAt512 echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
SFSA replaces softmax with spike-based dot products, causal masking, and spiking neuron activation (Eq. 1, Fig. 1, Alg. 1)
-
IndisputableMonolith/Foundation/ArrowOfTime.leanzAtStep / forward_accumulates unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Rate-MSE loss aligns time-averaged spike rates over T steps (Eq. 9, 13)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems, 33: 1877–1901,
work page 1901
-
[3]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advancing residual learning towards powerful deep spiking neural networks
Hu, Y ., Wu, Y ., Deng, L., and Li, G. Advancing residual learning towards powerful deep spiking neural networks. arXiv preprint arXiv:2112.08954, 7:7,
-
[6]
Tinybert: Distilling bert for natural language understanding.arXiv preprint arXiv:1909.10351,
Jiao, X., Yin, Y ., Shang, L., Jiang, X., Chen, X., Li, L., Wang, F., and Liu, Q. Tinybert: Distilling bert for natural language understanding.arXiv preprint arXiv:1909.10351,
-
[7]
K., Pandey, T., Bha- gat, A., and Rish, I
Kaushal, A., Vaidhya, T., Mondal, A. K., Pandey, T., Bha- gat, A., and Rish, I. Spectra: Surprising effectiveness of pretraining ternary language models at scale.arXiv preprint arXiv:2407.12327,
-
[8]
Kundu, S., Datta, G., Pedram, M., and Beerel, P. A. Spike- thrift: Towards energy-efficient deep spiking neural net- works by limiting spiking activity via attention-guided compression. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pp. 3953– 3962, 2021a. 9 Submission and Formatting Instructions for ICML 2026 Kundu, S....
work page 2026
-
[9]
Lv, C., Li, T., Xu, J., Gu, C., Ling, Z., Zhang, C., Zheng, X., and Huang, X. Spikebert: A language spikformer learned from bert with knowledge distillation.arXiv preprint arXiv:2308.15122,
-
[10]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Mihaylov, T., Clark, P., Khot, T., and Sabharwal, A. Can a suit of armor conduct electricity? a new dataset for open book question answering.arXiv preprint arXiv:1809.02789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Sanh, V ., Debut, L., Chaumond, J., and Wolf, T. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108,
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[12]
Shao, W., Chen, M., Zhang, Z., Xu, P., Zhao, L., Li, Z., Zhang, K., Gao, P., Qiao, Y ., and Luo, P. Omniquant: Omnidirectionally calibrated quantization for large lan- guage models.arXiv preprint arXiv:2308.13137,
-
[13]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., et al. Llama: Open and efficient foundation lan- guage models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
10 Submission and Formatting Instructions for ICML 2026 Tropp, J. A. et al. An introduction to matrix concentra- tion inequalities.Foundations and Trends® in Machine Learning, 8(1-2):1–230,
work page 2026
-
[15]
HEAD-QA: A Healthcare Dataset for Complex Reasoning
Vilares, D. and G´omez-Rodr´ıguez, C. Head-qa: A health- care dataset for complex reasoning.arXiv preprint arXiv:1906.04701,
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[16]
Bitnet: Scaling 1- bit transformers for large language models.arXiv preprint arXiv:2310.11453,
Wang, H., Ma, S., Dong, L., Huang, S., Wang, H., Ma, L., Yang, F., Wang, R., Wu, Y ., and Wei, F. Bitnet: Scaling 1- bit transformers for large language models.arXiv preprint arXiv:2310.11453,
-
[17]
A., Xiao, S., Zhang, W., Du, L., Zhang, Z., Li, G., and Zhang, J
Xing, X., Gao, B., Liu, Z., Clifton, D. A., Xiao, S., Zhang, W., Du, L., Zhang, Z., Li, G., and Zhang, J. Spikellm: Scaling up spiking neural network to large language mod- els via saliency-based spiking. InThe Thirteenth Interna- tional Conference on Learning Representations, 2024a. Xing, X., Zhang, Z., Ni, Z., Xiao, S., Ju, Y ., Fan, S., Wang, Y ., Zhan...
-
[18]
HellaSwag: Can a Machine Really Finish Your Sentence?
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., and Choi, Y . Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[19]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V ., et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Zhou, C., Yu, L., Zhou, Z., Ma, Z., Zhang, H., Zhou, H., and Tian, Y . Spikingformer: Spike-driven residual learn- ing for transformer-based spiking neural network.arXiv preprint arXiv:2304.11954,
-
[21]
Spikformer: When spiking neural network meets transformer.arXiv preprint arXiv:2209.15425,
Zhou, Z., Zhu, Y ., He, C., Wang, Y ., Yan, S., Tian, Y ., and Yuan, L. Spikformer: When spiking neural network meets transformer.arXiv preprint arXiv:2209.15425,
- [22]
-
[23]
Use of LLMs In this work, we used Large Language Models (LLMs) in a limited and auxiliary capacity
11 Submission and Formatting Instructions for ICML 2026 A. Use of LLMs In this work, we used Large Language Models (LLMs) in a limited and auxiliary capacity. Specifically, LLMs were employed for retrieval and discovery of related literature on Spiking Neural Networks (SNNs), neuromorphic computing, and energy-efficient large language models. This assiste...
work page 2026
-
[24]
We setP5 i=1 λi = 1 to keep the overall loss scale stable across experiments. The weights are selected based on preliminary sweeps: placing more emphasis on token-level attention/output alignment improves convergence and accuracy, whereas assigning too much weight to auxiliary terms can hurt training stability. Inference Time StepsTo investigate the trade...
work page 2024
-
[25]
Assume the pre-synaptic input is uniformly bounded, i.e., ∥Xt∥ ≤Mfor allt
Let ∥ · ∥ denote any norm that satisfies (i) the triangle inequality and (ii) positive homogeneity (e.g., ℓ2 norm for vectors or Frobenius norm for matrices). Assume the pre-synaptic input is uniformly bounded, i.e., ∥Xt∥ ≤Mfor allt. 18 Submission and Formatting Instructions for ICML 2026 Lemma E.1(Uniform bound one t).Under the above assumptions andβ∈(0,...
work page 2026
-
[26]
under different inference time steps. In each figure, rows correspond to the selected layers, while columns represent discrete inference time steps. Within each subplot, the horizontal axis indicates token positions and the vertical axis indexes neurons (or channels) within the corresponding layer; color intensity encodes the firing magnitude, 25 Submissi...
work page 2026
-
[27]
While quantized ANNs like Shao et al. (2023), Wang et al. (2023), and Kaushal et al. (2024) may exhibit a marginal edge in accuracy, we emphasize that these represent fundamentally different methodological paradigms. Therefore, the primary contribution of our work is not to surpass quantization methods in accuracy, but to pioneer and validate a new, energ...
work page 2023
-
[28]
This stable convergence behavior across different training scales demonstrates the robustness of our proposed BiSpikCLM architecture and the effectiveness of the SFSA mechanism in facilitating the optimization of spike-based language models. Figure 11.Training loss curves for the BiSpikCLM-1.3B model, comparing the 10B and 25B token training regimes. The ...
work page 2026
-
[29]
The firing rate (sparsity) is shown in parentheses
Table 11.Perplexity (PPL) on WikiText-2 with varying context lengths and firing thresholds. The firing rate (sparsity) is shown in parentheses. Model Params (B) Firing Threshold Context Length 512 1024 2048 4096 8192 OPT 1.300 - 16.26 13.58 11.13 - - Llama-3.2 1.200 - 12.93 10.96 9.76 9.02 8.54 BiSpikCLM 1.300 0.70 36.72 (0.184) 32.49 (0.183) 29.34 (0.181...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.