Recognition: 2 theorem links
· Lean TheoremSToRe3D: Sparse Token Relevance in ViTs for Efficient Multi-View 3D Object Detection
Pith reviewed 2026-05-15 05:11 UTC · model grok-4.3
The pith
SToRe3D prunes ViT tokens and 3D queries via mutual relevance heads to reach 3x faster multi-view detection with only marginal accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
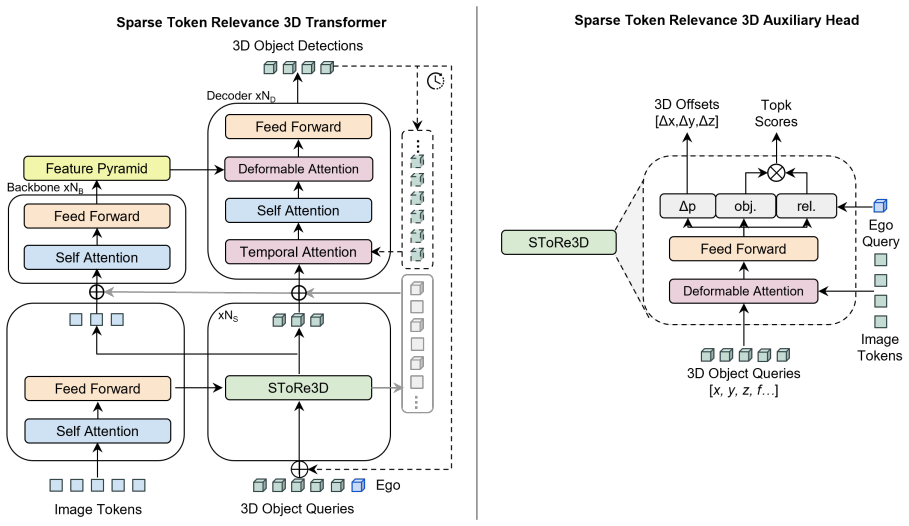
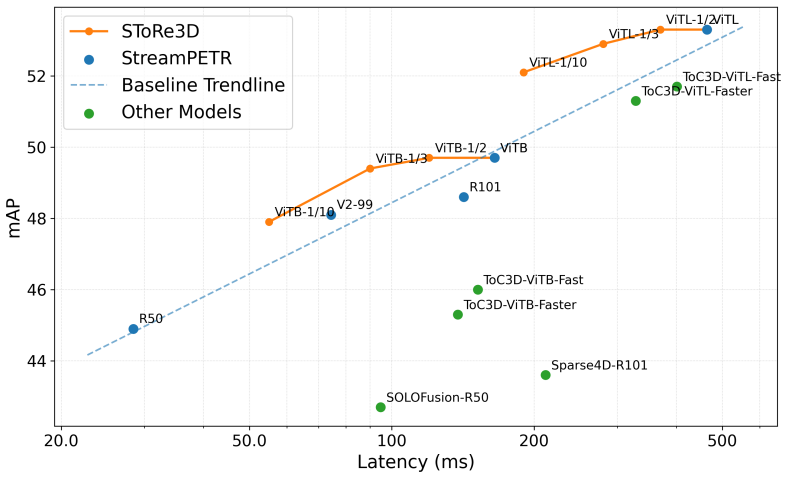
SToRe3D is a relevance-aligned sparsity framework that jointly selects 2D image tokens and 3D object queries through mutual 2D-3D relevance heads, stores the filtered features for reactivation, and thereby reduces inference latency by up to 3x on nuScenes with only marginal accuracy loss.
What carries the argument
Mutual 2D-3D relevance heads that score and retain driving-critical tokens and queries while storing the remainder for reactivation.
If this is right
- Large-scale ViT backbones become viable for real-time 3D detection in autonomous driving stacks.
- Accuracy on agents that matter for downstream planning remains essentially intact.
- Sparsity now covers both image tokens and 3D queries rather than image tokens alone.
- Stored features allow selective reactivation without full re-computation of earlier layers.
Where Pith is reading between the lines
- The same mutual-relevance idea could extend to multi-task settings such as 3D segmentation or tracking within the same forward pass.
- Memory bandwidth for storing filtered features may become the next bottleneck once compute is reduced.
- Scene-adaptive thresholds for the relevance heads could further reduce latency in low-complexity driving environments.
- The approach suggests a general route for adding controllable sparsity to any transformer that mixes 2D and 3D representations.
Load-bearing premise
The relevance heads correctly identify which tokens and queries are critical for detection accuracy across varying scenes and do not introduce reactivation overhead that offsets the speed gain.
What would settle it
Running the model on a nuScenes scene where a pedestrian or vehicle critical to planning is missed after pruning, with the same scene correctly detected by the dense baseline, would disprove the accuracy claim.
Figures







read the original abstract
Vision Transformers (ViTs) enable strong multi-view 3D detection but are limited by high inference latency from dense token and query processing across multiple views and large 3D regions. Existing sparsity methods, designed mainly for 2D vision, prune or merge image tokens but do not extend to full-model sparsity or address 3D object queries. We introduce SToRe3D, a relevance-aligned sparsity framework that jointly selects 2D image tokens and 3D object queries while storing filtered features for reactivation. Mutual 2D-3D relevance heads allocate compute to driving-critical content and preserve other embeddings. Evaluated on nuScenes and our new nuScenes-Relevance benchmark, SToRe3D achieves up to 3x faster inference with marginal accuracy loss, establishing real-time large-scale ViT-based 3D detection while maintaining accuracy on planning-critical agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SToRe3D, a relevance-aligned sparsity framework for Vision Transformers in multi-view 3D object detection. It jointly selects 2D image tokens and 3D object queries via mutual relevance heads, stores filtered features for reactivation, and reports up to 3x faster inference with marginal accuracy loss on nuScenes and a new nuScenes-Relevance benchmark while preserving accuracy on planning-critical agents.
Significance. If the net speedup holds after reactivation costs and accuracy is maintained for critical agents, the work would address a key deployment barrier for large ViT models in real-time 3D detection for autonomous driving, enabling more scalable multi-view processing.
major comments (2)
- [Abstract] Abstract: the claim of up to 3x faster inference with marginal accuracy loss lacks any isolated timing breakdown for reactivation memory access or recomputation relative to the dense baseline, which is load-bearing for the central efficiency claim given that filtered features are explicitly stored.
- [Method] Method section: no derivation or quantitative analysis is provided showing that the mutual 2D-3D relevance heads reliably preserve accuracy on planning-critical agents across varying scene conditions, leaving the accuracy-preservation assertion ungrounded.
minor comments (2)
- The new nuScenes-Relevance benchmark is referenced but its construction, scene selection criteria, and evaluation protocol are not described, hindering reproducibility.
- Notation for relevance scores, token storage, and reactivation should be formalized with equations to clarify the sparsity mechanism.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments below and plan to incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of up to 3x faster inference with marginal accuracy loss lacks any isolated timing breakdown for reactivation memory access or recomputation relative to the dense baseline, which is load-bearing for the central efficiency claim given that filtered features are explicitly stored.
Authors: We thank the referee for highlighting this important point. Our reported up to 3x speedups are based on end-to-end inference timings that encompass the costs of storing filtered features and their reactivation during inference. Nevertheless, to make the efficiency claims more robust and transparent, we will include a detailed isolated timing breakdown in the revised manuscript, explicitly comparing the reactivation memory access and recomputation overheads against the dense baseline. revision: yes
-
Referee: [Method] Method section: no derivation or quantitative analysis is provided showing that the mutual 2D-3D relevance heads reliably preserve accuracy on planning-critical agents across varying scene conditions, leaving the accuracy-preservation assertion ungrounded.
Authors: We agree that additional analysis would strengthen the claim. The manuscript presents results on the nuScenes-Relevance benchmark designed to evaluate performance on planning-critical agents, showing marginal loss. In the revision, we will add a derivation of how the mutual relevance heads prioritize critical content and provide quantitative analysis across varying scene conditions to better ground the accuracy-preservation assertion. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces SToRe3D as a new relevance-aligned sparsity framework for ViT-based multi-view 3D detection, jointly selecting 2D tokens and 3D queries while storing filtered features. No equations, derivations, or load-bearing steps reduce claimed speedups or accuracy to fitted parameters by construction, self-referential definitions, or self-citation chains. Claims rest on empirical evaluation on nuScenes and a new benchmark rather than internal renaming or ansatz smuggling. The framework is externally motivated by limitations of prior 2D sparsity methods and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SToRe3D applies joint, hierarchical sparsity to both image tokens and 3D object queries... store-reactivate form of sparsity that avoids irreversible pruning.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
relevance supervised by future interaction corridor... planning-aligned variant rplan
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel De Jong, Yury Zemlyanskiy, Federico Lebr ´on, and Sumit Sanghai. Gqa: Training generalized multi-query transformer models from multi-head checkpoints.arXiv preprint arXiv:2305.13245,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Token merging: Your vit but faster
Daniel Bolya and Judy Hoffman. Token merging: Your vit but faster. InICLR, 2023. 1, 2
work page 2023
-
[3]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020. 1, 6
work page 2020
-
[4]
End- to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End- to-end object detection with transformers. InEuropean con- ference on computer vision, pages 213–229. Springer, 2020. 1
work page 2020
-
[5]
Pointbev: A sparse approach for bev predictions
Loick Chambon, Eloi Zablocki, Micka¨el Chen, Florent Bar- toccioni, Patrick P ´erez, and Matthieu Cord. Pointbev: A sparse approach for bev predictions. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 15195–15204, 2024. 2
work page 2024
-
[6]
Brian Cheong, Letian Wang, Sandro Papais, and Steven L. Waslander. Scatr: Mitigating new instance suppression in lidar-based tracking-by-attention via second chance as- signment and track query dropout. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 3330–3339, 2026. 3
work page 2026
-
[7]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Do- han, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[8]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R´e. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022. 2
work page 2022
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
Eva-02: A visual representation for neon genesis.Image and Vision Computing, 149:105171,
Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xin- long Wang, and Yue Cao. Eva-02: A visual representation for neon genesis.Image and Vision Computing, 149:105171,
-
[11]
Adaptive token sampling for efficient vision transformers
Mohsen Fayyaz, Soroush Abbasi Koohpayegani, Farnoush Rezaei Jafari, Sunando Sengupta, Hamid Reza Vaezi Joze, Eric Sommerlade, Hamed Pirsiavash, and J¨urgen Gall. Adaptive token sampling for efficient vision transformers. InEuropean conference on computer vision, pages 396–414. Springer, 2022. 2
work page 2022
-
[12]
Levit: a vision transformer in convnet’s clothing for faster inference
Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Herv ´e J ´egou, and Matthijs Douze. Levit: a vision transformer in convnet’s clothing for faster inference. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 12259–12269,
-
[13]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 6
work page 2016
-
[14]
Salience detr: Enhancing detection transformer with hierarchical salience filtering refinement
Xiuquan Hou, Meiqin Liu, Senlin Zhang, Ping Wei, and Badong Chen. Salience detr: Enhancing detection transformer with hierarchical salience filtering refinement. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17574–17583, 2024. 2
work page 2024
-
[15]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17853–17862, 2023. 3
work page 2023
-
[16]
Token cropr: Faster vision transformers for quite a few tasks
Zhen Huang, Ming Xu, Wenqi Zhang, Zhouhan Lin, and Dejing Dou. Token cropr: Faster vision transformers for quite a few tasks. InCVPR, 2025. 1, 2, 3
work page 2025
-
[17]
Categorical Reparameterization with Gumbel-Softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax.arXiv preprint arXiv:1611.01144, 2016. 4
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
Cornernet: Detecting objects as paired keypoints
Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. InProceedings of the European conference on computer vision (ECCV), pages 734–750, 2018. 5
work page 2018
-
[19]
Dong Hoon Lee and Seunghoon Hong. Learning to merge tokens via decoupled embedding for efficient vision trans- formers.Advances in Neural Information Processing Systems, 37:54079–54104, 2024. 2
work page 2024
-
[20]
Multi-criteria token fusion with one-step-ahead attention for efficient vision transformers
Sanghyeok Lee, Joonmyung Choi, and Hyunwoo J Kim. Multi-criteria token fusion with one-step-ahead attention for efficient vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15741–15750, 2024. 2
work page 2024
-
[21]
An energy and gpu-computation efficient backbone network for real-time object detection
Youngwan Lee, Joong-won Hwang, Sangrok Lee, Yuseok Bae, and Jongyoul Park. An energy and gpu-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 0–0, 2019. 6
work page 2019
-
[22]
Chengxi Li, Stanley H Chan, and Yi-Ting Chen. Who make drivers stop? towards driver-centric risk assessment: Risk object identification via causal inference. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10711–10718. IEEE, 2020. 3
work page 2020
-
[23]
Chengxi Li, Stanley H Chan, and Yi-Ting Chen. Droid: Driver-centric risk object identification.IEEE transactions on pattern analysis and machine intelligence, 45(11):13683– 13698, 2023. 3
work page 2023
-
[24]
Dn-detr: Accelerate detr training by introducing query denoising
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by introducing query denoising. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13619– 13627, 2022. 2
work page 2022
-
[25]
Savit: Structure- aware vision transformer pruning via collaborative optimiza- tion
Rui Li, Yu Wang, Tianyu Xu, and Dahua Lin. Savit: Structure- aware vision transformer pruning via collaborative optimiza- tion. InNeurIPS, 2022. 2
work page 2022
-
[26]
Exploring plain vision transformer backbones for object de- tection
Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object de- tection. InEuropean conference on computer vision, pages 280–296. Springer, 2022. 3
work page 2022
-
[27]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learn- ing bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. InEuropean conference on computer vision, pages 1–18. Springer, 2022. 2, 3, 7
work page 2022
-
[28]
Not all patches are what you need: Expediting vision transformers via token reorganizations
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie. Not all patches are what you need: Expediting vision transformers via token reorganizations. arXiv preprint arXiv:2202.07800, 2022. 2
-
[29]
Focal Loss for Dense Object Detection
T Lin. Focal loss for dense object detection.arXiv preprint arXiv:1708.02002, 2017. 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Sparse4d v2: Recurrent temporal fusion with sparse model.arXiv preprint arXiv:2305.14018, 2023
Xuewu Lin, Tianwei Lin, Zixiang Pei, Lichao Huang, and Zhizhong Su. Sparse4d v2: Recurrent temporal fusion with sparse model.arXiv preprint arXiv:2305.14018, 2023. 2, 3, 7
-
[31]
Sparsebev: High-performance sparse 3d ob- ject detection from multi-camera videos
Haisong Liu, Yao Teng, Tao Lu, Haiguang Wang, and Limin Wang. Sparsebev: High-performance sparse 3d ob- ject detection from multi-camera videos. InProceedings of the IEEE/CVF international conference on computer vision, pages 18580–18590, 2023. 2, 7
work page 2023
-
[32]
Dab-detr: Dynamic anchor boxes are better queries for detr,
Shilong Liu, Feng Li, Hao Zhang, Xiao Yang, Xianbiao Qi, Hang Su, Jun Zhu, and Lei Zhang. Dab-detr: Dynamic anchor boxes are better queries for detr.arXiv preprint arXiv:2201.12329, 2022. 2
-
[33]
Petr: Position embedding transformation for multi-view 3d object detection
Yingfei Liu, Tiancai Wang, Xiangyu Zhang, and Jian Sun. Petr: Position embedding transformation for multi-view 3d object detection. InEuropean Conference on Computer Vi- sion, pages 531–548. Springer, 2022. 2
work page 2022
-
[34]
Revisiting token pruning for object detection and instance segmentation
Yifei Liu, Mathias Gehrig, Nico Messikommer, Marco Can- nici, and Davide Scaramuzza. Revisiting token pruning for object detection and instance segmentation. InProceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, pages 2658–2668, 2024. 1, 2, 3
work page 2024
-
[35]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 2, 3
work page 2021
-
[36]
Sachin Mehta and Mohammad Rastegari. Mobilevit: light- weight, general-purpose, and mobile-friendly vision trans- former.arXiv preprint arXiv:2110.02178, 2021. 2
-
[37]
Adavit: Adaptive vision transformers for efficient image recognition
Lingchen Meng, Hengduo Li, Bor-Chun Chen, Shiyi Lan, Zuxuan Wu, Yu-Gang Jiang, and Ser-Nam Lim. Adavit: Adaptive vision transformers for efficient image recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12309–12318, 2022. 2
work page 2022
-
[38]
Are sixteen heads really better than one?Advances in neural information processing systems, 32, 2019
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one?Advances in neural information processing systems, 32, 2019. 2
work page 2019
-
[39]
Swtrack: Multiple hypothesis sliding window 3d multi-object track- ing
Sandro Papais, Robert Ren, and Steven Waslander. Swtrack: Multiple hypothesis sliding window 3d multi-object track- ing. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4939–4945. IEEE, 2024. 3
work page 2024
-
[40]
Foresight: Multi-view streaming joint object detection and trajectory forecasting
Sandro Papais, Letian Wang, Brian Cheong, and Steven L Waslander. Foresight: Multi-view streaming joint object detection and trajectory forecasting. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25474–25484, 2025. 3
work page 2025
-
[41]
Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection
Jinhyung Park, Chenfeng Xu, Shijia Yang, Kurt Keutzer, Kris M Kitani, Masayoshi Tomizuka, and Wei Zhan. Time will tell: New outlooks and a baseline for temporal multi-view 3d object detection. InThe Eleventh International Conference on Learning Representations, 2022. 7
work page 2022
-
[42]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d
Jonah Philion and Sanja Fidler. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIV 16, pages 194–210. Springer, 2020. 2
work page 2020
-
[43]
Dynamicvit: Efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Bing Liu, Jiwen Lu, and Jie Zhou. Dynamicvit: Efficient vision transformers with dynamic token sparsification. InNeurIPS, 2021. 1, 2, 8
work page 2021
-
[44]
Byungseok Roh, JaeWoong Shin, Wuhyun Shin, and Saehoon Kim. Sparse detr: Efficient end-to-end object detection with learnable sparsity.arXiv preprint arXiv:2111.14330, 2021. 1, 2, 3
-
[45]
Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova
Michael S. Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova. Tokenlearner: What can 8 learned tokens do for images and videos? InNeurIPS, 2021. 2
work page 2021
-
[46]
Sparsedrive: End-to-end au- tonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Hao- ran Wu, and Sifa Zheng. Sparsedrive: End-to-end au- tonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801. IEEE, 2025. 3
work page 2025
-
[47]
Patch slimming for efficient vision transformers
Yehui Tang, Kai Han, Yunhe Wang, Chang Xu, Jianyuan Guo, Chao Xu, and Dacheng Tao. Patch slimming for efficient vision transformers. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 12165–12174, 2022. 2
work page 2022
-
[48]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Elena V oita, David Talbot, Fedor Moiseev, Rico Sennrich, and Ivan Titov. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned.arXiv preprint arXiv:1905.09418, 2019. 2
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[49]
Letian Wang, Marc-Antoine Lavoie, Sandro Papais, Barza Nisar, Yuxiao Chen, Wenhao Ding, Boris Ivanovic, Hao Shao, Abulikemu Abuduweili, Evan Cook, Yang Zhou, Peter Karkus, Jiachen Li, Changliu Liu, Marco Pavone, and Steven Waslander. Trends in motion prediction toward deployable and generalizable autonomy: A revisit and perspectives, 2025. 1
work page 2025
-
[50]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020. 2
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[51]
Shihao Wang, Xiaohui Jiang, and Ying Li. Focal-petr: Em- bracing foreground for efficient multi-camera 3d object detec- tion.IEEE Transactions on Intelligent Vehicles, 9(1):1481– 1489, 2023. 2, 3, 5, 6
work page 2023
-
[52]
Exploring object-centric temporal modeling for efficient multi-view 3d object detection
Shihao Wang, Yingfei Liu, Tiancai Wang, Ying Li, and Xi- angyu Zhang. Exploring object-centric temporal modeling for efficient multi-view 3d object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3621–3631, 2023. 2, 3, 6, 7, 8, 1
work page 2023
-
[53]
Detr3d: 3d object detection from multi-view images via 3d-to-2d queries
Yue Wang, Vitor Campagnolo Guizilini, Tianyuan Zhang, Yilun Wang, Hang Zhao, and Justin Solomon. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. InConference on Robot Learning, pages 180–191. PMLR,
-
[54]
Perceive, attend, and drive: Learn- ing spatial attention for safe self-driving
Bob Wei, Mengye Ren, Wenyuan Zeng, Ming Liang, Bin Yang, and Raquel Urtasun. Perceive, attend, and drive: Learn- ing spatial attention for safe self-driving. In2021 IEEE In- ternational Conference on Robotics and Automation (ICRA), pages 4875–4881. IEEE, 2021. 3
work page 2021
-
[55]
Evo-vit: Slow-fast token evolution for dynamic vision transformer
Yifan Xu, Chenglin Zhang, Zhuliang Zhang, and Dacheng Tao. Evo-vit: Slow-fast token evolution for dynamic vision transformer. InAAAI, 2022. 2
work page 2022
-
[56]
X-pruner: explainable pruning for vision trans- formers
Zhiqiang Xu, Yifan Wang, Pan Zhou, Zehuan Yuan, and Mingkui Tan. X-pruner: explainable pruning for vision trans- formers. InCVPR, 2023. 2
work page 2023
-
[57]
Token fusion: Bridging the gap between token pruning and token merging
Zhiqiang Xu, Pan Zhou, and Mingkui Tan. Token fusion: Bridging the gap between token pruning and token merging. InWACV, 2024. 2
work page 2024
-
[58]
Efficient detr: improving end-to-end object detector with dense prior
Zhuyu Yao, Jiangbo Ai, Boxun Li, and Chi Zhang. Efficient detr: improving end-to-end object detector with dense prior. arXiv preprint arXiv:2104.01318, 2021. 2
-
[59]
Spvit: Enabling faster vision transformers via latency-aware soft token pruning
Zhaoyang Yao, Kai Han, Yunhe Wang, Chunjing Xu, and Chang Xu. Spvit: Enabling faster vision transformers via latency-aware soft token pruning. InECCV, 2022. 2
work page 2022
-
[60]
Synergistic patch pruning for vision trans- former
Huan Yu, Mingbao Zhang, Yulun Wang, Kai Yang, Kai Han, and Yunhe Wang. Synergistic patch pruning for vision trans- former. InICLR, 2024. 2
work page 2024
-
[61]
Make your vit- based multi-view 3d detectors faster via token compression
Dingyuan Zhang, Dingkang Liang, Zichang Tan, Xiaoqing Ye, Cheng Zhang, Jingdong Wang, and Xiang Bai. Make your vit- based multi-view 3d detectors faster via token compression. InEuropean Conference on Computer Vision, pages 56–72. Springer, 2024. 1, 2, 3, 7, 8
work page 2024
-
[62]
Towards efficient use of multi-scale features in transformer-based object detectors
Gongjie Zhang, Zhipeng Luo, Zichen Tian, Jingyi Zhang, Xiaoqin Zhang, and Shijian Lu. Towards efficient use of multi-scale features in transformer-based object detectors. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6206–6216, 2023. 2
work page 2023
-
[63]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[64]
Detrs beat yolos on real-time object detection
Yian Zhao, Wenyu Lv, Shangliang Xu, Jinman Wei, Guanzhong Wang, Qingqing Dang, Yi Liu, and Jie Chen. Detrs beat yolos on real-time object detection. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16965–16974, 2024. 2
work page 2024
-
[65]
Less is more: Focus attention for efficient detr
Dehua Zheng, Wenhui Dong, Hailin Hu, Xinghao Chen, and Yunhe Wang. Less is more: Focus attention for efficient detr. InProceedings of the IEEE/CVF international conference on computer vision, pages 6674–6683, 2023. 1, 2
work page 2023
-
[66]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable trans- formers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 2, 3 SToRe3D: Sparse Token Relevance in ViTs for Efficient Multi-View 3D Object Detection Supplementary Material
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[67]
Backbones are ViT-based, and we evaluate both medium and large variants
Implementation Details We follow standard multi-view 3D detection settings on nuScenes using 6 cameras, synchronized frames, and known camera intrinsics and extrinsics. Backbones are ViT-based, and we evaluate both medium and large variants. There is no encoder after the backbone, and the decoder follows a DETR-style design with multi-scale features. We m...
-
[68]
Profiling Analysis We now analyze latency sensitivity to image tokens and object queries in isolation. Starting from the dense baseline with 900 object queries and 127,500 image tokens across all camera views, we systematically subsample each axis. We reduce the number of object queries by 50% and 90%, and measure the resulting latency of the ViT-L backbo...
-
[69]
Additional Metrics For the planning-relevance metrics introduced in the main paper, an agent is labeled relevant if the closest distance dC between its swept corridor and the ego vehicle’s swept corridor is below a buffer threshold dRM . To choose dRM , we first compute the empirical distribution of the closest ego–agent distances dC across the entire nuS...
-
[70]
Additional Qualitative Results Figure 9 provides additional qualitative comparisons be- tween SToRe3D and the baseline StreamPETR model. We highlight three representative cases where highly relevant objects are missed by the baseline ResNet-50 model but de- tected by our similar-latency variant SToRe3D-1/10-ViT-B. In all three scenes, the highlighted obje...
-
[71]
First, our evaluation is restricted to the nuScenes dataset and camera-only multi-view 3D detection
Limitations and Future Work While SToRe3D achieves strong accuracy–latency trade-offs, it has several limitations. First, our evaluation is restricted to the nuScenes dataset and camera-only multi-view 3D detection. The relevance heads and pruning schedules are (a) Front view of an oncoming car that is missed by the baseline detector but correctly detecte...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.