Recognition: no theorem link
Time Domain Near Memory Computing Engine
Pith reviewed 2026-05-15 01:53 UTC · model grok-4.3
The pith
A time-domain near-memory architecture performs low-precision MAC operations at 7.62 TOPS/W in a 4x4 prototype.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
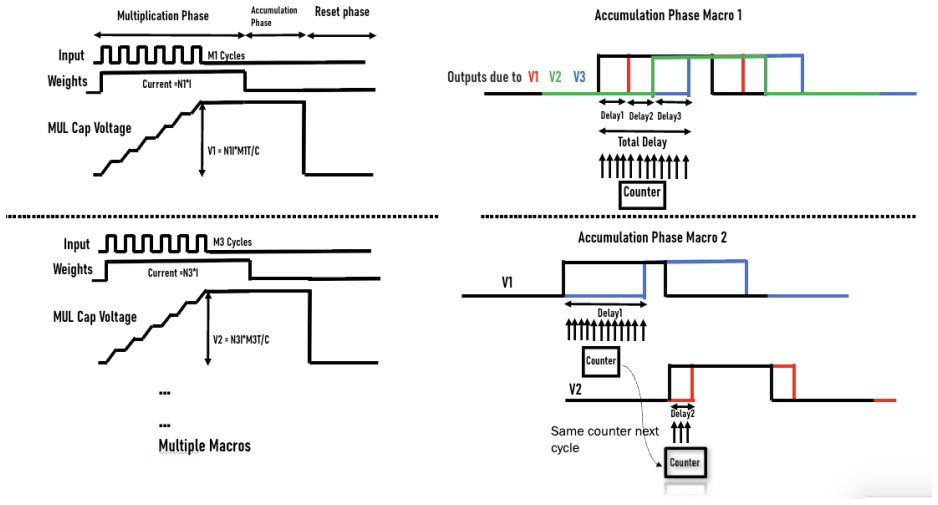
The central claim is that digital weight bits stored in SRAM are converted using a current-steering DAC and the digital input vector is encoded by an N-pulse generator, enabling multiplication in the time domain. Accumulation is realized through either a delay-cell-based architecture or a counter-based architecture. The N-pulse generator and counters are implemented via RTL synthesis for technology portability while the DAC remains analog. A fabricated 4x4 MAC prototype operates at 1 V supply, 40 MHz frequency, 42 uW power, and delivers 7.62 TOPS/W energy efficiency.
What carries the argument
The N-pulse generator that encodes the input vector together with the current-steering DAC to realize time-domain multiplication while keeping accumulation digital or semi-digital.
If this is right
- The hybrid approach reduces ADC and DAC overhead compared with conventional analog in-memory designs for low-precision workloads.
- RTL synthesis of the N-pulse generator and counters improves technology portability across process nodes.
- Counter-based accumulation offers improved scalability and design trade-offs relative to delay-cell accumulation.
- The digital-friendly interface allows direct integration with standard digital SRAM and control logic.
- Energy efficiency of 7.62 TOPS/W at 1 V demonstrates viability for edge AI MAC acceleration.
Where Pith is reading between the lines
- If linearity holds at scale, the architecture could be tiled into larger near-memory arrays for full neural-network layers with modest additional power cost.
- The time-domain encoding may extend to other low-precision operations such as activation functions or pooling if pulse widths can be modulated accordingly.
- Integration with existing digital SRAM macros in standard CMOS could lower the barrier for adopting near-memory acceleration in commercial SoCs.
- Further voltage scaling below 1 V or frequency increases above 40 MHz would test whether efficiency gains continue or saturate due to leakage and timing margins.
Load-bearing premise
The N-pulse generator and counter-based accumulation maintain sufficient linearity and scalability when extended beyond the 4x4 prototype without significant power or area penalties.
What would settle it
Fabrication and measurement of a larger array such as 16x16 showing whether energy efficiency stays above 7 TOPS/W and linearity holds at the same 1 V and 40 MHz conditions.
Figures








read the original abstract
The increasing computational demand of AI workloads has intensified the need for energy-efficient in-memory and near-memory computing architectures, particularly because data movement often consumes significantly more energy than computation itself. While fully digital architectures provide robust scalability and support higher-resolution computation, analog in-memory computing has demonstrated improved energy efficiency for low-precision workloads. However, its reliance on peripheral DACs and ADCs introduces additional power, area, and design overhead. To address these challenges, this work presents a time-domain near-memory computing architecture for low-precision multiply-and-accumulate (MAC) operations. In the proposed approach, digital weight bits stored in SRAM are converted using a current-steering DAC, while the digital input vector is encoded by an N-pulse generator. This enables multiplication to be performed in the time domain while maintaining a digital-friendly interface. Two accumulation schemes, a delay-cell-based architecture and a counter-based architecture, are investigated and compared in terms of design trade-offs, linearity, scalability, and power efficiency. To improve technology portability, the N-pulse generator and counters are implemented using RTL synthesis, while the current-steering DAC remains in the analog domain. A 4 x 4 MAC prototype is implemented with a 1 V supply, achieving an operating frequency of 40 MHz, power consumption of 42 uW, and energy efficiency of 7.62 TOPS/W.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a time-domain near-memory computing architecture for low-precision MAC operations. Digital weights from SRAM are converted via a current-steering DAC while inputs are encoded by an N-pulse generator, performing multiplication in the time domain. Two accumulation methods (delay-cell-based and counter-based) are compared for linearity, scalability, and efficiency. The N-pulse generator and counters are RTL-synthesized for portability. A 4x4 prototype at 1 V achieves 40 MHz operation, 42 μW power, and 7.62 TOPS/W energy efficiency.
Significance. If the measured efficiency holds under rigorous characterization, the hybrid time-domain approach offers a practical middle ground between fully digital and analog in-memory computing. It reduces DAC/ADC overhead while preserving digital-friendly interfaces and RTL portability, which could benefit low-precision AI edge accelerators where data movement dominates energy.
major comments (2)
- [Abstract / Prototype Results] Abstract and prototype results section: the central 7.62 TOPS/W efficiency figure is reported without error bars, a description of the power-measurement instrumentation, or baseline comparisons against prior digital or analog MAC designs; this leaves the quantitative claim only moderately supported for a 4x4 array.
- [Accumulation Architectures] § on accumulation schemes: the manuscript states that delay-cell and counter-based accumulators are investigated and compared, yet the 4x4 prototype results appear to reflect only one implementation; the trade-off data needed to support the claim that the counter-based version improves scalability are not shown.
minor comments (2)
- [Prototype Implementation] The operating frequency (40 MHz) and supply (1 V) are stated clearly, but the area of the 4x4 array and the breakdown of power between DAC, pulse generator, and accumulator are not tabulated; adding these would strengthen reproducibility.
- [Architecture] Notation for the N-pulse generator timing is introduced without an accompanying timing diagram or equation relating pulse count to input value; a small figure would clarify the time-domain multiplication.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Abstract / Prototype Results] Abstract and prototype results section: the central 7.62 TOPS/W efficiency figure is reported without error bars, a description of the power-measurement instrumentation, or baseline comparisons against prior digital or analog MAC designs; this leaves the quantitative claim only moderately supported for a 4x4 array.
Authors: We agree that additional context would strengthen the quantitative claim. In the revised manuscript we will add a description of the power-measurement instrumentation and setup used for the 4x4 prototype. We will also insert baseline comparisons to representative prior digital and analog MAC designs in the results section. Because the reported efficiency derives from a single prototype measurement, error bars from multiple samples are not available; we will explicitly note this limitation and discuss measurement conditions and variability sources. revision: partial
-
Referee: [Accumulation Architectures] § on accumulation schemes: the manuscript states that delay-cell and counter-based accumulators are investigated and compared, yet the 4x4 prototype results appear to reflect only one implementation; the trade-off data needed to support the claim that the counter-based version improves scalability are not shown.
Authors: The manuscript compares the two accumulation schemes via analysis and simulation, while the fabricated 4x4 prototype implements only the counter-based version to demonstrate improved scalability. We will revise the relevant section to clearly separate the simulated trade-off analysis from the measured prototype results. We will also add a table or figure presenting the key trade-off metrics (linearity, area, power, scalability) for both schemes to directly support the claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a hardware prototype whose key performance metrics (7.62 TOPS/W at 1 V, 40 MHz, 42 µW for the 4×4 array) are obtained from direct silicon measurements rather than from any closed-form derivation, fitted model, or self-referential equation. No load-bearing step reduces a claimed result to an input parameter by construction, and the architecture description relies on RTL synthesis and analog circuit implementation without invoking uniqueness theorems or prior self-citations as the sole justification. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current-steering DAC maintains acceptable linearity at 1 V supply in the target CMOS process.
Reference graph
Works this paper leans on
-
[1]
B. Murmann, ”Mixed-Signal Computing for Deep Neural Network Inference,” in IEEE Transactions on Very Large Scale Integra- tion (VLSI) Systems, vol. 29, no. 1, pp. 3-13, Jan. 2021, doi: 10.1109/TVLSI.2020.3020286
-
[2]
L. Jie, Micheal Flynn et al., ”An Overview of Noise-Shaping SAR ADC: From Fundamentals to the Frontier,” in IEEE Open Journal of the Solid-State Circuits Society, vol. 1, pp. 149-161, 2021, doi: 10.1109/OJSSCS.2021.3119910
-
[3]
Y . Zhang and Z. Zhu, ”Recent Advances and Trends in V oltage-Time Domain Hybrid ADCs,” in IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 69, no. 6, pp. 2575-2580, June 2022, doi: 10.1109/TCSII.2022.3169741
-
[4]
IEEE International Symposium on Circuits and Systems (ISCAS), 2025
Harshit Naman, Gourab Barik, Shreyas Sen, A Real-Time Memory-Less In-Sensor Time-Domain Convolution Processor with Programmable Ker- nel for Feature Extraction. IEEE International Symposium on Circuits and Systems (ISCAS), 2025
work page 2025
-
[5]
A 0.5-V Real-Time Computational CMOS Image Sensor With Programmable Kernel for Feature Extraction
Tzu-Hsiang Hsu, Yi-Ren Chen, Ren-Shuo, Chung-Chuan Lo, KeaTiong Tang, Meng-Fan Chang, and Chih-Cheng Hsieh. A 0.5-V Real-Time Computational CMOS Image Sensor With Programmable Kernel for Feature Extraction. IEEE Journal of Solid-State Circuits, 2021
work page 2021
-
[6]
A 2.5GHz, 7.7TOPS/W Switched-Capacitor Matrix Multiplier with Co-designed Local Memory in 40nm,
E. Lee and S. Wong, “A 2.5GHz, 7.7TOPS/W Switched-Capacitor Matrix Multiplier with Co-designed Local Memory in 40nm,” in ISSCC Dig.Tech. Papers, 2016
work page 2016
-
[7]
An 8-bit, 16 input, 3.2 pJ/Op switched-capacitor dot product circuit in 28-nm FDSOI CMOS,
D. Bankman and Boris, “An 8-bit, 16 input, 3.2 pJ/Op switched-capacitor dot product circuit in 28-nm FDSOI CMOS,” IEEE A-SSCC 2016
work page 2016
-
[8]
X. Wu, T. Siriburanon and R. B. Staszewski, ”Time-Domain Multiply- Accumulator using Digital-to-Time Multiplier for CNN Processors in 28-nm CMOS,” 2020 31st Irish Signals and Systems Conference (ISSC), Letterkenny, Ireland, 2020
work page 2020
-
[9]
TDPRO: Ultra-low power ECG processor with high pre- cision time-domain computing engine,
L Chang et al., “TDPRO: Ultra-low power ECG processor with high pre- cision time-domain computing engine,” in Proc. IEEE Int. Symp.Circuits Syst. (ISCAS), May 2022 ACKNOWLEDGMENT This project was completed to fulfill the course requirements of Advanced VLSI Design (CRN: ECE 69500 160). The authors would like to thank Prof. Sumeet Gupta for his guidance th...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.