Recognition: 2 theorem links
· Lean TheoremThinking Ahead: Prospection-Guided Retrieval of Memory with Language Models
Pith reviewed 2026-05-15 01:36 UTC · model grok-4.3
The pith
Prospection-guided retrieval uses imagined future steps to surface low-similarity memories that standard embedding search misses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
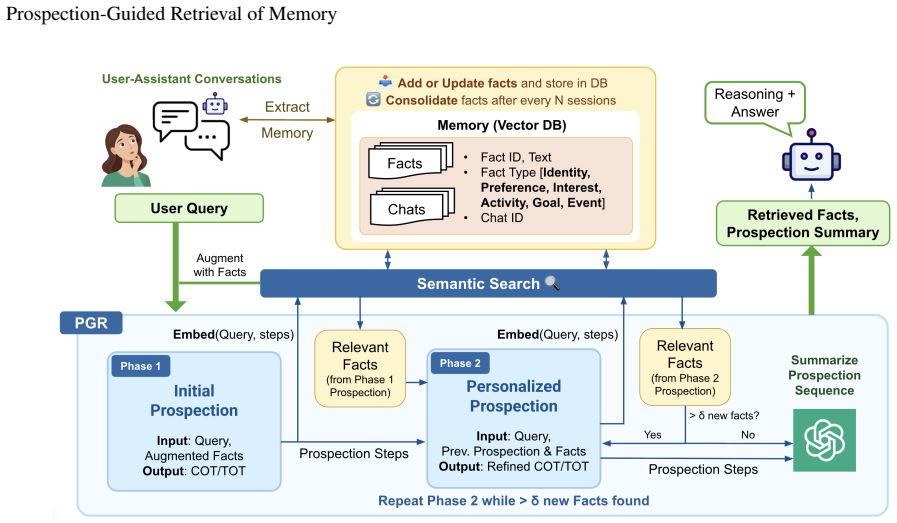
Prospection-Guided Retrieval decouples the retrieval process from the original query by expanding it into a short Tree-of-Thought or linear chain of plausible future steps and using those steps as retrieval probes. The facts returned by the probes are then fed back to ground and extend the prospection, allowing the system to reach memories that become relevant only after the simulation is anchored in the user's actual history.
What carries the argument
Prospection-Guided Retrieval (PGR) that generates Tree-of-Thought or linear prospection steps to serve as retrieval probes rather than relying on the query embedding alone.
If this is right
- Recall of low-similarity reference facts rises nearly threefold on the MemoryQuest benchmark relative to standard dense retrieval.
- Responses built from the retrieved memories are preferred by both LLM-as-judge and blinded human evaluators on 89-98 percent of queries.
- Iterative grounding of prospection in retrieved facts surfaces additional relevant memories beyond the initial probes.
- The gains hold across 1,625 queries spanning 185 user profiles drawn from three public datasets.
Where Pith is reading between the lines
- The same future-oriented probe strategy could be applied to recommendation or planning systems where current queries under-specify long-term user goals.
- Pairing PGR with graph-structured memory might reduce noise by constraining which prospection steps are allowed to query which memory clusters.
- Running PGR on continuously growing histories would test whether the method maintains precision without accumulating irrelevant probes over time.
Load-bearing premise
That language-model-generated prospection steps will consistently produce retrieval probes that surface the genuinely relevant low-similarity memories without flooding the context with noise or hallucinations.
What would settle it
A held-out set of queries in which none of the human-annotated reference facts are ever returned by any prospection-generated probe while still being missed by all similarity-based baselines.
Figures



read the original abstract
Long-horizon personalization requires dialogue assistants to retrieve user-specific facts from extended interaction histories. In practice, many relevant facts often have low semanticsimilarity to the query under dense retrieval. Standard Retrieval-Augmented Generation (RAG) and GraphRAG systems are still largely retrospective: they rely on embedding similarity to the query or on fixed graph traversals, so they often miss facts that matter for the user's needs but lie far from the query in embedding space. Inspired by prospection, the human ability to use imagined futures as cues for recall, we introduce Prospection-Guided Retrieval (PGR), which decouples retrieval from how memories are stored. Given a user query, PGR first expands the goal into a short Tree-of-Thought (ToT) or linear chain of plausible next steps, and uses these steps as retrieval probes rather than relying on the original query alone. The facts retrieved by these probes are then used to personalize the next round of prospection, enabling PGR to uncover additional memories that become relevant only after the simulation is grounded in the user's history. We also introduce MemoryQuest, a challenging multi-session benchmark in which each query is annotated with 3--5 dated reference facts subject to a low query-reference similarity constraint. Across 1,625 queries spanning 185 user profiles from 3 publicly available datasets, PGR-TOT substantially improves retrieval, including nearly 3x recall on MemoryQuest over the strongest baseline. In pairwise LLM-as-judge comparisons against baselines, PGR-generated responses are preferred on 89--98% of queries, with blinded human annotations on held-out subsets showing the same trend. Overall, the results demonstrate that explicit prospection yields large gains in long-horizon retrieval and response quality relative to similarity-only baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Prospection-Guided Retrieval (PGR), which expands a user query into Tree-of-Thought or linear prospection chains to generate retrieval probes that surface low-similarity user memories from long interaction histories. It presents the MemoryQuest benchmark (queries annotated with 3-5 low-similarity reference facts) and evaluates PGR-TOT on 1625 queries across 185 profiles from three public datasets, claiming nearly 3x recall gains over the strongest baseline plus 89-98% preference rates in LLM-as-judge and blinded human evaluations.
Significance. If the mechanism holds, PGR offers a concrete way to address the retrospective limitation of standard RAG and GraphRAG systems for long-horizon personalization. The scale of the evaluation, introduction of a challenging low-similarity benchmark, and alignment between automated and human preferences would constitute a useful empirical contribution to retrieval-augmented dialogue research.
major comments (3)
- [Results section (MemoryQuest evaluation)] Results section (MemoryQuest evaluation): the nearly 3x recall improvement is reported without precision, relevance, or noise metrics on the facts retrieved by the prospection probes themselves. This leaves open whether gains arise from genuinely relevant low-similarity memories or from probe-induced noise/hallucinations, which is load-bearing for the central claim.
- [§3 (Method) and §4 (Experiments)] §3 (Method) and §4 (Experiments): exact prompt templates for prospection generation, the strongest baseline implementation, and details of statistical significance testing are not fully specified, preventing independent verification of the reported recall and preference numbers.
- [§3.3 (Iterative grounding)] §3.3 (Iterative grounding): no ablation isolates the contribution of the iterative grounding step versus single-round prospection, so it is unclear whether the full pipeline is required for the observed gains or whether early noisy probes propagate errors.
minor comments (2)
- [Abstract] Abstract: the three source datasets and the exact 185-profile count should be named for immediate context.
- [Figures and tables] Figure captions and table headers: ensure consistent terminology between 'prospection steps,' 'retrieval probes,' and 'grounded facts' to avoid minor reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will incorporate revisions to improve clarity, reproducibility, and evidential support for our claims.
read point-by-point responses
-
Referee: Results section (MemoryQuest evaluation): the nearly 3x recall improvement is reported without precision, relevance, or noise metrics on the facts retrieved by the prospection probes themselves. This leaves open whether gains arise from genuinely relevant low-similarity memories or from probe-induced noise/hallucinations, which is load-bearing for the central claim.
Authors: We agree that additional metrics on the probe-retrieved facts would strengthen the central claim. In the revised manuscript we will add a new subsection in Results reporting precision@K and relevance scores (via LLM-as-judge and manual sampling) for facts surfaced by the prospection probes, together with a brief error analysis quantifying any noise or hallucinations. This will directly demonstrate that the recall gains derive from relevant low-similarity memories rather than spurious retrievals. revision: yes
-
Referee: §3 (Method) and §4 (Experiments): exact prompt templates for prospection generation, the strongest baseline implementation, and details of statistical significance testing are not fully specified, preventing independent verification of the reported recall and preference numbers.
Authors: We acknowledge the reproducibility concern. The revised version will include all exact prompt templates (for both Tree-of-Thought and linear prospection) in a dedicated appendix. We will also expand the baseline description with implementation details, hyperparameters, and adaptation steps for MemoryQuest. Finally, we will specify the statistical tests performed (paired Wilcoxon signed-rank tests with reported p-values and confidence intervals) for all recall and preference results. revision: yes
-
Referee: §3.3 (Iterative grounding): no ablation isolates the contribution of the iterative grounding step versus single-round prospection, so it is unclear whether the full pipeline is required for the observed gains or whether early noisy probes propagate errors.
Authors: We agree an ablation is needed to isolate the iterative component. We will add a new ablation experiment in §4 comparing single-round prospection (no grounding) against the full iterative PGR pipeline on the same MemoryQuest queries. The results will quantify incremental recall gains and include a qualitative check for error propagation from early probes, thereby clarifying whether iteration is essential. revision: yes
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper introduces Prospection-Guided Retrieval (PGR) as a method that generates ToT or linear prospection chains to create retrieval probes, then grounds them iteratively against user history. All reported gains (3x recall on MemoryQuest, 89-98% LLM-judge preference) are obtained via direct comparison against external baselines on held-out queries from three public datasets, plus blinded human annotations. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation or evaluation chain. The central results rest on observable retrieval metrics and preference judgments rather than any reduction to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can generate plausible next-step sequences that serve as effective retrieval probes for low-similarity memories
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PGR first expands the goal into a short Tree-of-Thought (ToT) or linear chain of plausible next steps, and uses these steps as retrieval probes... The facts retrieved by these probes are then used to personalize the next round of prospection
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
iterative Simulate→Retrieve→Refine loop
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Schacter, Roland G
Daniel L. Schacter, Roland G. Benoit, and Karl K. Szpunar. Episodic future thinking: Mechanisms and functions. Current Opinion in Behavioral Sciences, 17:41–50, 2017
2017
-
[2]
Wong, and Daniel L
Donna Rose Addis, Alana T. Wong, and Daniel L. Schacter. Remembering the past and imagining the future: Common and distinct neural substrates during event construction and elaboration.Neuropsychologia, 45(7):1363– 1377, 2007
2007
-
[3]
Retrieval augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. InInternational conference on machine learning, pages 3929–3938. PMLR, 2020. 9 Prospection-Guided Retrieval of Memory
2020
-
[4]
Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[5]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Beyond goldfish memory: Long-term open-domain conversation
Jing Xu, Arthur Szlam, and Jason Weston. Beyond goldfish memory: Long-term open-domain conversation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5180–5197, Dublin, Ireland, May 2022. Association for Computational Linguistics
2022
-
[7]
Longmemeval: Benchmarking chat assistants on long-term interactive memory, 2024
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory, 2024
2024
-
[8]
Leveraging passage retrieval with generative models for open domain question answering
Gautier Izacard and Edouard Grave. Leveraging passage retrieval with generative models for open domain question answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL), pages 874–880. Association for Computational Linguistics, 2021. (FiD: Fusion-in-Decoder approach)
2021
-
[9]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
2023
-
[10]
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822, 2023
2023
-
[11]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[12]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production- ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Vann, and Eleanor A
Demis Hassabis, Dharshan Kumaran, Seralynne D. Vann, and Eleanor A. Maguire. Patients with hippocampal amnesia cannot imagine new experiences.Proceedings of the National Academy of Sciences, 104(5):1726–1731, 2007
2007
-
[14]
Evaluat- ing very long-term conversational memory of llm agents, 2024
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluat- ing very long-term conversational memory of llm agents, 2024
2024
-
[15]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, et al. Personamem-v2: Towards personalized intelligence via learning implicit user personas and agentic memory.arXiv preprint arXiv:2512.06688, 2025
-
[16]
Toward multi-session personalized conversation: A large-scale dataset and hierarchical tree framework for implicit reasoning
Xintong Li, Jalend Bantupalli, Ria Dharmani, Yuwei Zhang, and Jingbo Shang. Toward multi-session personalized conversation: A large-scale dataset and hierarchical tree framework for implicit reasoning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 11493–11506. Association for Computational Linguist...
2025
-
[17]
PersonaLens: A benchmark for personalization evaluation in conversational AI assistants
Zheng Zhao, Clara Vania, Subhradeep Kayal, Naila Khan, Shay B Cohen, and Emine Yilmaz. PersonaLens: A benchmark for personalization evaluation in conversational AI assistants. In Wanxiang Che, Joyce Nabende, Eka- terina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 18023–18055, Vie...
2025
-
[18]
New embedding models and api updates
OpenAI. New embedding models and api updates. https://openai.com/index/ new-embedding-models-and-api-updates/, 2024. Refers to text-embedding-3-small. 10 Prospection-Guided Retrieval of Memory A Appendix A.1 PGR with Alternative Generation Models To assess whether PGR’s retrieval gains are robust to the choice of generation model, we run PGR-TOT with Deep...
2024
-
[19]
GPU overheating issue -- user plans to reduce overheating during gaming (2026-02-20)
2026
-
[20]
March trip funds locked -- user frames trip money as ’already spent’ (2026-02-23)
2026
-
[21]
Upcoming online course expenses constraining GPU/hardware budget (2026-03-03)
2026
-
[22]
how...”,
Backlog of unfinished games -- user committed to completing RDR2 before any new title (2026-03-01). 11 Prospection-Guided Retrieval of Memory Phase 1 — Initial TOT (initial, pre-retrieval) A1 Check the game’s release date and pre-order availability constraints: official announcement, platform compatibility, region restrictions +-- A2 Look up gameplay trai...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.