Recognition: 2 theorem links
· Lean TheoremPhyMotion: Structured 3D Motion Reward for Physics-Grounded Human Video Generation
Pith reviewed 2026-05-15 02:46 UTC · model grok-4.3
The pith
PhyMotion scores recovered 3D human meshes in a physics simulator to reward realistic motion in generated videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
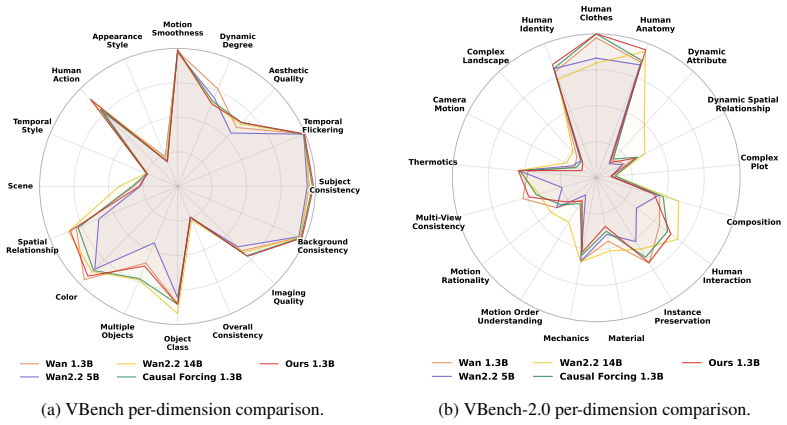
PhyMotion recovers SMPL meshes from generated videos, retargets them onto a humanoid in MuJoCo, and evaluates the resulting motion along kinematic plausibility, contact and balance consistency, and dynamic feasibility. Each axis supplies a continuous, interpretable score tied to a distinct physical property. The combined reward correlates more strongly with human judgments of realism than existing formulations and, when used for RL post-training, produces larger and more consistent motion improvements across generator architectures while preserving overall video quality.
What carries the argument
PhyMotion reward: structured scorer that retargets SMPL meshes from video into MuJoCo to compute separate kinematic, contact-balance, and dynamic feasibility scores.
If this is right
- Optimizing PhyMotion in RL post-training yields larger motion-realism gains than optimizing existing 2D perceptual rewards.
- The three scoring axes supply complementary signals that allow diagnosis of specific motion flaws.
- Improvements hold for both autoregressive and bidirectional video generators.
- Overall video quality remains intact with only modest extra training cost.
- Blind human raters show a +68 Elo gain in motion preference for PhyMotion-trained outputs.
Where Pith is reading between the lines
- Direct integration of similar physics-based rewards into the base training loop could reduce the need for separate post-training stages.
- Better 3D mesh recovery methods would raise the ceiling of what this reward can achieve.
- The same retarget-and-simulate approach could be tested on non-human articulated motion such as animals or robots.
- Explicit 3D physics modeling may become necessary for any generative model that aims at high-fidelity human movement.
Load-bearing premise
SMPL mesh recovery from generated videos is accurate enough and retargeting those meshes into MuJoCo faithfully reflects the physical violations that human viewers notice.
What would settle it
Generate videos containing deliberate physical errors such as floating bodies or impossible joint angles, then check whether PhyMotion consistently assigns them lower scores than matched realistic videos and whether optimizing it reduces those errors.
Figures







read the original abstract
Generating realistic human motion is a central yet unsolved challenge in video generation. While reinforcement learning (RL)-based post-training has driven recent gains in general video quality, extending it to human motion remains bottlenecked by a reward signal that cannot reliably score motion realism. Existing video rewards primarily rely on 2D perceptual signals, without explicitly modeling the 3D body state, contact, and dynamics underlying articulated human motion, and often assign high scores to videos with floating bodies or physically implausible movements. To address this, we propose PhyMotion, a structured, fine-grained motion reward that grounds recovered 3D human trajectories in a physics simulator and evaluates motion quality along multiple dimensions of physical feasibility. Concretely, we recover SMPL body meshes from generated videos, retarget them onto a humanoid in the MuJoCo physics simulator, and evaluate the resulting motion along three axes: kinematic plausibility, contact and balance consistency, and dynamic feasibility. Each component provides a continuous and interpretable signal tied to a specific aspect of motion quality, allowing the reward to capture which aspects of motion are physically correct or violated. Experiments show that PhyMotion achieves stronger correlation with human judgments than existing reward formulations. These gains carry over to RL-based post-training, where optimizing PhyMotion leads to larger and more consistent improvements than optimizing existing rewards, improving motion realism across both autoregressive and bidirectional video generators under both automatic metrics and blind human evaluation (+68 Elo gain). Ablations show that the three axes provide complementary supervision signals, while the reward preserves overall video generation quality with only modest training overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PhyMotion, a structured 3D motion reward for physics-grounded human video generation. It recovers SMPL body meshes from generated videos, retargets them onto a humanoid in MuJoCo, and evaluates the motion along three axes: kinematic plausibility, contact and balance consistency, and dynamic feasibility. Experiments claim stronger correlation with human judgments than existing 2D rewards, plus larger and more consistent RL post-training gains (+68 Elo) across autoregressive and bidirectional generators, with ablations showing complementary signals from the three axes.
Significance. If the SMPL recovery and retargeting steps are shown to be accurate, the work would provide a valuable advance by supplying interpretable, multi-axis physics signals that outperform 2D perceptual rewards for RL in human video generation. The reported human correlation gains, Elo improvements, and ablation results on complementary axes would be a substantive contribution to reward design for motion realism.
major comments (2)
- [Method section on 3D recovery and retargeting] The central claim that PhyMotion measures physical violations (rather than 3D consistency proxies) rests on SMPL recovery from generated videos and MuJoCo retargeting, yet no quantitative validation—such as pose/joint error rates on recovered vs. ground-truth trajectories or ablation on retargeting noise—is reported. This is load-bearing for the +68 Elo and human-preference results.
- [Experiments section (RL and human eval)] Experiments on RL gains and human evaluation report the +68 Elo improvement and stronger correlation, but lack controls or analysis showing that gains are driven by the physics axes rather than artifacts from SMPL estimation errors on artifact-laden generated frames.
minor comments (2)
- [Method] Clarify the exact definitions and weighting of the three reward axes in the method description for reproducibility.
- [Experiments] Add error bars or statistical significance tests to the Elo and correlation tables to support the cross-generator claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. The concerns about validation of the SMPL recovery and retargeting pipeline, as well as controls for potential estimation artifacts in the RL and human evaluation results, are well-taken and directly relevant to the strength of our claims. We address each point below and will revise the manuscript accordingly to provide the requested evidence.
read point-by-point responses
-
Referee: [Method section on 3D recovery and retargeting] The central claim that PhyMotion measures physical violations (rather than 3D consistency proxies) rests on SMPL recovery from generated videos and MuJoCo retargeting, yet no quantitative validation—such as pose/joint error rates on recovered vs. ground-truth trajectories or ablation on retargeting noise—is reported. This is load-bearing for the +68 Elo and human-preference results.
Authors: We agree that quantitative validation of the SMPL recovery accuracy and retargeting robustness is essential to confirm that PhyMotion evaluates genuine physical violations. The current manuscript relies on the downstream human correlation and RL gains as indirect evidence, but does not report direct error metrics. In the revised manuscript we will add: (1) pose and joint position error rates computed on a held-out set of videos with available ground-truth SMPL parameters from motion-capture datasets, and (2) an ablation that injects controlled Gaussian noise into the retargeted joint trajectories and measures the resulting change in reward scores and RL performance. These additions will directly substantiate the load-bearing steps for the reported +68 Elo and preference improvements. revision: yes
-
Referee: [Experiments section (RL and human eval)] Experiments on RL gains and human evaluation report the +68 Elo improvement and stronger correlation, but lack controls or analysis showing that gains are driven by the physics axes rather than artifacts from SMPL estimation errors on artifact-laden generated frames.
Authors: We acknowledge the need for explicit controls to rule out confounding from SMPL estimation errors on low-quality generated frames. The manuscript currently demonstrates complementary signals via axis ablations but does not isolate estimation noise. In the revision we will include: (1) a control experiment that applies the same RL pipeline using perturbed SMPL estimates (Gaussian noise added to recovered joints) and compares the resulting Elo gains against the original PhyMotion reward, and (2) a per-frame analysis correlating reward scores with known artifact types (e.g., floating bodies) versus clean frames. These controls will show that the observed improvements arise from the kinematic, contact, and dynamic physics signals rather than estimation artifacts. revision: yes
Circularity Check
No significant circularity in PhyMotion reward derivation
full rationale
The PhyMotion reward is defined directly from three explicit physics axes (kinematic plausibility, contact/balance, dynamic feasibility) computed in an external MuJoCo simulator after SMPL recovery and retargeting. No equation, parameter fit, or component reduces the final reward value to a fitted quantity derived from the same generated videos or human preference data used for evaluation. The reported gains (+68 Elo, stronger human correlation) are presented as outcomes of optimizing this independent simulator-based signal rather than any self-referential construction or self-citation chain. Self-citations, if present, are not load-bearing for the core reward definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SMPL body model accurately recovers 3D meshes from 2D video frames
- domain assumption MuJoCo humanoid simulation faithfully reproduces contact and dynamic constraints relevant to human perception
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
recover SMPL body meshes from generated videos, retarget them onto a humanoid in the MuJoCo physics simulator, and evaluate the resulting motion along three axes: kinematic plausibility, contact and balance consistency, and dynamic feasibility
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Rmotion(v) = 1/3 (Fkin(v) + Fcon(v) + Fdyn(v))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhaochong An, Orest Kupyn, Théo Uscidda, Andrea Colaco, Karan Ahuja, Serge Belongie, Mar Gonzalez-Franco, and Marta Tintore Gazulla. Vggrpo: Towards world-consistent video generation with 4d latent reward.arXiv preprint arXiv:2603.26599,
-
[2]
Hila Chefer, Uriel Singer, Amit Zohar, Yuval Kirstain, Adam Polyak, Yaniv Taigman, Lior Wolf, and Shelly Sheynin. VideoJAM: Joint appearance-motion representations for enhanced motion generation in video models.arXiv preprint arXiv:2502.02492,
-
[3]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Yu Gao, Haoyuan Guo, Tuyen Hoang, Weilin Huang, Lu Jiang, Fangyuan Kong, Huixia Li, Jiashi Li, Liang Li, Xiaojie Li, et al. Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DayaGuo,DejianYang,HaoweiZhang,JunxiaoSong,RuoyuZhang,RunxinXu,QihaoZhu,Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
GARDO: Reinforcing diffusion models without reward hacking
Haoran He, Yuxiao Ye, Jie Liu, Jiajun Liang, Zhiyong Wang, Ziyang Yuan, Xintao Wang, Hangyu Mao, Pengfei Wan, and Ling Pan. GARDO: Reinforcing diffusion models without reward hacking. arXiv preprint arXiv:2512.24138,
-
[6]
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra,ZiyanJiang,AaranArulraj,KaiWang,QuyDucDo,YuanshengNi,BohanLyu,Yaswanth Narsupalli, Rongqi Fan, Zhiheng Lyu, Yuchen Lin, and Wenhu Chen. VideoScore: Building automatic metrics to simulate fine-grained human feedback for video generation.arXiv preprint arXiv:2406.15252,
-
[7]
Planning with sketch-guided verification for physics-aware video generation
YidongHuang,ZunWang,HanLin,Dong-KiKim,ShayeganOmidshafiei,JaehongYoon,YueZhang, and Mohit Bansal. Planning with sketch-guided verification for physics-aware video generation. arXiv preprint arXiv:2511.17450,
-
[8]
Vbench++: Comprehensive and versatile benchmark suite for video generative models
ZiqiHuang,YinanHe,JiashuoYu,FanZhang,ChenyangSi,YumingJiang,YuanhanZhang,Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, YuQiao, andZiweiLiu. VBench: Comprehensivebenchmarksuiteforvideogenerativemodels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024a. Ziqi...
-
[9]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL.arXiv preprint arXiv:2505.05470, 2025a. Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, Xiaohong Liu, Fei Yang...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Yunhong Lu, Yanhong Zeng, Haobo Li, Hao Ouyang, Qiuyu Wang, Ka Leong Cheng, Jiapeng Zhu, Hengyuan Cao, Zhipeng Zhang, Xing Zhu, et al. Reward forcing: Efficient streaming video generation with rewarded distribution matching distillation.arXiv preprint arXiv:2512.04678,
-
[11]
ISBN 978-1-57735-887-9. doi: 10.1609/aaai.v38i5.28206. URLhttps://doi.org/10.1609/aaai.v38i5.28206. Yuhang Ma, Yunhao Shui, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. HPSv3: Towards wide- spectrum human preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV),
-
[12]
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363,
-
[13]
Ruizhi Shao, Youxin Pang, Zerong Zheng, Jingxiang Sun, and Yebin Liu. Human4DiT: Free-view human video generation with 4D diffusion transformer.arXiv preprint arXiv:2405.17405, 2024a. ZhihongShao,PeiyiWang,QihaoZhu,RunxinXu,JunxiaoSong,XiaoBi,HaoweiZhang,Mingchuan Zhang, YK Li, Yang Wu, et al. DeepSeekMath: Pushing the limits of mathematical reasoning in ...
-
[14]
Kaiyue Sun, Kaiyi Huang, Xian Liu, Yue Wu, Zihan Xu, Zhenguo Li, and Xihui Liu. T2V- CompBench: A comprehensive benchmark for compositional text-to-video generation.arXiv preprint arXiv:2407.14505,
-
[15]
Wan: Open and Advanced Large-Scale Video Generative Models
14 Team Wan, Ang Wang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
doi: 10.1109/IROS.2012.6386109. Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. FVD: A new metric for video generation. InICLR Workshop on Deep Generative Models for Highly Structured Data,
-
[17]
Aligning human motion generation with human perceptions.arXiv preprint arXiv:2407.02272, 2024a
Haoru Wang, Wentao Zhu, Luyi Miao, Yishu Xu, Feng Gao, Qi Tian, and Yizhou Wang. Aligning human motion generation with human perceptions.arXiv preprint arXiv:2407.02272, 2024a. TanWang,LinjieLi,KevinLin,YuanhaoZhai,Chung-ChingLin,ZhengyuanYang,HanwangZhang, Zicheng Liu, and Lijuan Wang. DisCo: Disentangled control for realistic human dance generation. InP...
-
[18]
ZunWang,HanLin,JaehongYoon,JaeminCho,YueZhang,andMohitBansal. Anchorweave: World- consistentvideogenerationwithretrievedlocalspatialmemories.arXivpreprintarXiv:2602.14941, 2026b. David A Winter.Biomechanics and motor control of human movement. John wiley & sons,
-
[19]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. VisionReward: Fine-grained multi-dimensional human preference learning for image and video generation.arXiv preprint arXiv:2412.21059, 2024a. Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi...
-
[20]
Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507, 2025
Peiyuan Zhang, Yongqi Chen, Runlong Su, Hangliang Ding, Ion Stoica, Zhengzhong Liu, and Hao Zhang. Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507,
-
[21]
Songchun Zhang, Zeyue Xue, Siming Fu, Jie Huang, Xianghao Kong, Yue Ma, Haoyang Huang, Nan Duan, and Anyi Rao. Astrolabe: Steering forward-process reinforcement learning for distilled autoregressive video models.arXiv preprint arXiv:2603.17051,
-
[22]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
15 Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
RealisDance: Equip controllable character animation with realistic hands
Jingkai Zhou, Benzhi Wang, Weihua Chen, Jingqi Bai, Dongyang Li, Aixi Zhang, Hao Xu, Mingyang Yang, and Fan Wang. RealisDance: Equip controllable character animation with realistic hands. arXiv preprint arXiv:2409.06202,
-
[24]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregressivediffusiondistillationdonerightforhigh-qualityreal-timeinteractivevideogeneration. arXiv preprint arXiv:2602.02214,
-
[25]
17 (a) Kinematic Errors A person stands still in a wide shot, repeatedly extending both arms forward and back ❌ Hands self-penetration A person lies and repeatedly opening and closing the top knee ❌ Extra arm A person lies and repeatedly opening and closing the top knee ❌ Impossible joint angle (b) Contact/Balance Errors A figure skater performs a Biellma...
work page 2026
-
[26]
We report the checkpoint at training step330
Unless otherwise specified, all experiments use the same configuration. We report the checkpoint at training step330. F Licenses for Existing Assets We show the licenses of all assets we use in Table 11 25 Table 11: Licenses of external assets, models, datasets, codebases, and evaluation tools used in this work. Asset / Method Website / Source License Wan...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.