Recognition: no theorem link
MetaMoE: Diversity-Aware Proxy Selection for Privacy-Preserving Mixture-of-Experts Unification
Pith reviewed 2026-05-15 02:21 UTC · model grok-4.3
The pith
MetaMoE unifies domain-specialized experts into a single MoE via diversity-aware public proxy selection that approximates private data distributions for router training and expert alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on computer vision and natural language processing benchmarks demonstrate that MetaMoE consistently outperforms recent privacy-preserving MoE unification methods.
Load-bearing premise
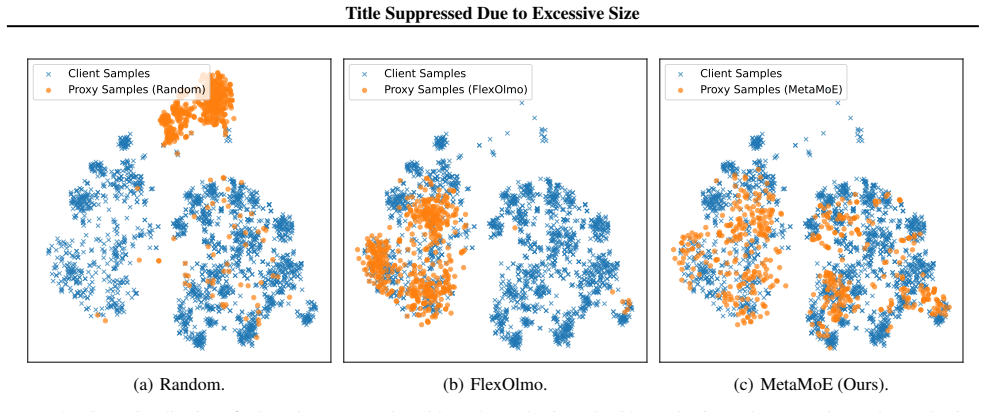
Public proxy data selected for domain relevance and diversity can sufficiently approximate inaccessible private data distributions to supervise router learning and expert alignment without introducing large distribution shift.
Figures




read the original abstract
Mixture-of-Experts (MoE) models scale capacity by combining specialized experts, but most existing approaches assume centralized access to training data. In practice, data are distributed across clients and cannot be shared due to privacy constraints, making unified MoE training challenging. We propose MetaMoE, a privacy-preserving framework that unifies independently trained, domain-specialized experts into a single MoE using public proxy data as surrogates for inaccessible private data. Central to MetaMoE is diversity-aware proxy selection, which selects client-domain-relevant and diverse samples from public data to effectively approximate private data distributions and supervise router learning. These proxies are further used to align expert training, improving expert coordination at unification time, while a context-aware router enhances expert selection across heterogeneous inputs. Experiments on computer vision and natural language processing benchmarks demonstrate that MetaMoE consistently outperforms recent privacy-preserving MoE unification methods. Code is available at https://github.com/ws-jiang/MetaMoE.
Editorial analysis
A structured set of objections, weighed in public.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mixture-of-LoRAs: An efficient multitask tuning for large language models
Feng, W., Hao, C., Zhang, Y ., Han, Y ., and Wang, H. Mixture-of-LoRAs: An efficient multitask tuning for large language models. Preprint arXiv:2403.03432,
-
[2]
Li, M., Gururangan, S., Dettmers, T., Lewis, M., Althoff, T., Smith, N. A., and Zettlemoyer, L. Branch-Train-Merge: Embarrassingly parallel training of expert language mod- els. Preprint arXiv:2208.03306,
-
[3]
Longpre, S., Hou, L., Vu, T., Webson, A., Chung, H. W., Tay, Y ., Zhou, D., Le, Q. V ., Zoph, B., Wei, J., and Roberts, A. Designing data and methods for effective instruction tuning. Preprint arXiv:2301.13688,
-
[4]
arXiv preprint arXiv:2408.07666 , year=
Yang, E., Shen, L., Guo, G., Wang, X., Cao, X., Zhang, J., and Tao, D. Model merging in LLMs, MLLMs, and be- yond: Methods, theories, applications and opportunities. Preprint arXiv:2408.07666,
-
[5]
12 Title Suppressed Due to Excessive Size A. Computation of Relevance Score Following FlexOlmo (Shi et al., 2025), we compute the relevance score g(x,D p) of a public sample x∈ D 0 with respect to a client dataset Dp by training a binary classifier to distinguish Dp from D0. Specifically, we construct a training set by labeling samples from Dp as positive...
work page 2025
-
[6]
matrix, incurring O(m3) time per evaluation. Over all n candidates and m greedy steps, the total cost for each greedy step scales asO(nm 3), which is infeasible when bothnandmare large. Cholesky Factorization.To avoid redundant recomputation, we exploit the Cholesky decomposition (Horn & Johnson, 1985). Suppose the current kernel submatrix admits a decomp...
work page 1985
-
[7]
13 Title Suppressed Due to Excessive Size Thus, the update reduces to solving a triangular system (for y) and computing a residual variance (for σ2). Both steps are efficient: solving a triangular system costs O(m), and computing a norm is linear in m as well. Hence, each iteration of greedy MAP inference only requires a total time of O(nm) for searching ...
work page 2012
-
[8]
Figure 5 shows randomly sampled examples from ImageNet
as the public dataset from which proxy samples are drawn. Figure 5 shows randomly sampled examples from ImageNet. (a) Pets. (b) Flowers. (c) EuroSAT. Figure 4.Sample images from the three client domains: Pets, Flowers, and EuroSAT. Figure 5.Sample images from ImageNet. D. Natural Language Processing Datasets The client-side NLP datasets comprise Commonsen...
work page 2019
-
[9]
Federated learning (FL) methods differ fundamentally from MetaMoE: they require exchanging large model states every round. This leads to substantial bandwidth and memory overhead and creates instability when client data are heterogeneous because divergent local updates must be averaged. MetaMoE eliminates synchronization entirely—each client fine-tunes it...
work page 2025
-
[10]
adopts a federated learning paradigm that requires repeated synchronization among clients—periodically exchanging model parameters for joint optimization. This approach incurs high communication and memory costs and often becomes unstable under heterogeneous client data, leading to degraded performance. In contrast, MetaMoE avoid exchanging model paramete...
work page 2024
-
[11]
Table 13.Cost–performance comparison on CV tasks. ViT-B/32 ViT-B/16 ACC Unify Time (s) Inference Speed (samples/s) ACC Unify Time (s) Inference Speed (samples/s) BTM 90.33 − 606 91.75 − 249 ModelSoup 74.20 5.72 1813 79.42 5.72 743 BTX 74.30 11.13 1758 81.20 19.72 715 FlexOlmo 92.92 11.93 1767 93.53 18.24 719 MetaMoE 94.52 12.15 1751 96.24 19.88 710 Table ...
work page 2014
-
[12]
through the routing mechanism. FlexOlmo initializes its domain-informed router using per-expert routing embeddings computed as the mean embedding overprivate data alone(Section 3.3.2 of Shi et al. (2025)). Concretely, FlexOlmo shares the vector µpriv = 1 N PN i=1 f(x i), which is the complete mean private embedding. In contrast, MetaMoE shares e= N N+m µp...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.