Recognition: 2 theorem links
· Lean TheoremData-Augmented Game Starts for Accelerating Self-Play Exploration in Imperfect Information Games
Pith reviewed 2026-05-15 02:38 UTC · model grok-4.3
The pith
Data-Augmented Game Starts let regularized policy gradients reach lower exploitability under fixed budgets in long-horizon imperfect-information games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
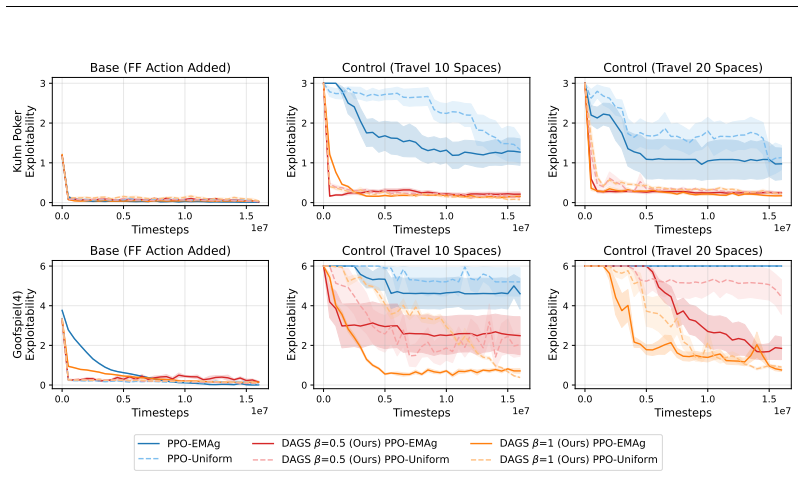
By initializing reinforcement-learning trajectories at states drawn from offline human demonstrations, regularized policy-gradient methods for two-player zero-sum imperfect-information games can allocate their fixed computational budget to strategically relevant subgames and thereby reach lower exploitability than methods that always start from the root state.
What carries the argument
Data-Augmented Game Starts (DAGS), which samples intermediate states from offline demonstration data to initialize self-play data collection and thereby directs exploration toward high-level strategic subgames.
If this is right
- Under fixed budgets DAGS yields lower exploitability in games whose exploration is otherwise prohibitively difficult.
- Altering the starting-state distribution can bias the equilibria found by self-play, but adding multi-task observation flags removes the bias.
- The released benchmark environments increase state count and exploration difficulty while preserving analytic exploitability measures.
Where Pith is reading between the lines
- The same starting-state augmentation could be applied to any self-play algorithm that already uses a regularized policy gradient update.
- If high-quality demonstration data are scarce, the method’s benefit will shrink unless the demonstrations are first filtered or augmented.
- The multi-task flag technique may generalize to other forms of distribution shift that arise when training on modified game trajectories.
Load-bearing premise
Offline demonstrations from skilled humans already contain good coverage of the high-level strategies that appear in equilibrium play.
What would settle it
An experiment in which DAGS produces higher exploitability than standard root-start self-play when both are run for the same number of gradient steps on one of the released benchmark games would falsify the central claim.
Figures



read the original abstract
Finding approximate equilibria for large-scale imperfect-information competitive games such as StarCraft, Dota, and CounterStrike remains computationally infeasible due to sparse rewards and challenging exploration over long horizons. In this paper, we propose a multi-agent starting-state sampling strategy designed to substantially accelerate online exploration in regularized policy-gradient game methods for two-player zero-sum (2p0s) games. Motivated by an assumption that offline demonstrations from skilled humans can provide good coverage of high-level strategies relevant to equilibrium play, we propose the initialization of reinforcement learning data collection at intermediate states sampled from offline data to facilitate exploration of strategically relevant subgames. Referring to this method as Data-Augmented Game Starts (DAGS), we perform experiments using synthetic datasets and analytically tractable, long-horizon control variants of two-player Kuhn Poker, Goofspiel, and a counterexample game designed to penalize biased beliefs over hidden information. Under fixed computational budgets, DAGS enables regularized policy gradient methods to achieve lower exploitability in games with significantly more challenging exploration. We show that augmenting starting state distributions when solving imperfect information games can lead to biased equilibria, and we provide a straightforward mitigation to this in the form of multi-task observation flags. Finally, we release a new set of benchmark environments that drastically increase exploration challenges and state counts in existing OpenSpiel games while keeping exploitability measurements analytically tractable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Data-Augmented Game Starts (DAGS), a starting-state sampling strategy that initializes RL data collection at intermediate states drawn from offline data to accelerate exploration for regularized policy-gradient methods in two-player zero-sum imperfect-information games. Motivated by the assumption that skilled-human demonstrations cover high-level equilibrium-relevant strategies, the authors evaluate DAGS on synthetic datasets and analytically tractable long-horizon variants of Kuhn Poker, Goofspiel, and a counterexample game. They claim lower exploitability under fixed computational budgets, introduce a multi-task observation-flag mitigation for biased equilibria, and release new benchmark environments that increase state counts and exploration difficulty while preserving analytic exploitability measures.
Significance. If the coverage assumption holds and the gains generalize beyond synthetic data, DAGS could offer a practical, low-overhead way to improve sample efficiency in large-scale imperfect-information settings with sparse rewards. The new benchmark suite is a concrete, reusable contribution that makes controlled study of exploration hardness feasible.
major comments (2)
- [Experiments] Experiments section: the central claim that DAGS yields lower exploitability under fixed budgets depends on offline data providing good coverage of equilibrium-relevant strategies. All reported results use only synthetic datasets and analytically tractable game variants; no experiments with actual human demonstrations are presented. Because synthetic data may already align with equilibrium paths, the observed improvements do not yet test the motivating coverage assumption.
- [Abstract] Abstract and §4: the abstract states that DAGS achieves lower exploitability but supplies no numerical values, confidence intervals, or description of how bias was quantified. Without these details it is impossible to judge the magnitude or statistical reliability of the reported gains.
minor comments (2)
- [Method] Clarify in §3 how the multi-task observation flags are implemented and whether they alter the policy-gradient objective.
- [Benchmarks] Add a short discussion of how the new benchmark environments differ in state-space size and horizon length from the original OpenSpiel versions.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each of the major points below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that DAGS yields lower exploitability under fixed budgets depends on offline data providing good coverage of equilibrium-relevant strategies. All reported results use only synthetic datasets and analytically tractable game variants; no experiments with actual human demonstrations are presented. Because synthetic data may already align with equilibrium paths, the observed improvements do not yet test the motivating coverage assumption.
Authors: We agree that testing with actual human demonstrations would provide stronger evidence for the coverage assumption. Our use of synthetic datasets was intentional to maintain analytical tractability for exploitability measurements in the new long-horizon benchmark environments. These datasets are constructed to include a diverse set of strategies, some of which align with equilibrium paths and others that do not, allowing us to isolate the effects of DAGS. Nevertheless, we acknowledge this limitation. In the revised version, we will expand the discussion in Section 5 to explicitly address the gap between synthetic and human data, and highlight how the released benchmarks can support future experiments with human demonstrations. revision: partial
-
Referee: [Abstract] Abstract and §4: the abstract states that DAGS achieves lower exploitability but supplies no numerical values, confidence intervals, or description of how bias was quantified. Without these details it is impossible to judge the magnitude or statistical reliability of the reported gains.
Authors: We appreciate this observation. The current abstract is intentionally high-level, but we agree that including specific results would improve clarity. In the revised manuscript, we will update the abstract to include representative numerical improvements in exploitability (e.g., percentage reductions under fixed budgets), mention the use of confidence intervals from multiple runs, and briefly describe the bias quantification via the multi-task flag approach. revision: yes
Circularity Check
No circularity; heuristic method with independent empirical validation
full rationale
The paper proposes DAGS as a sampling heuristic for starting states drawn from offline data, motivated by an external assumption on human demonstration coverage of equilibrium strategies. The central claim of lower exploitability under fixed budgets is supported by direct experiments on synthetic datasets in analytically tractable games (Kuhn Poker variants, Goofspiel, counterexample game). No equations, derivations, or self-citations reduce the claimed gains to fitted parameters defined by the result itself, nor to self-referential uniqueness theorems. The method and its bias-mitigation flag are presented as design choices with empirical outcomes, keeping the derivation chain self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Offline demonstrations from skilled humans can provide good coverage of high-level strategies relevant to equilibrium play.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DAGS augments self-play training with intermediate-state resets drawn from offline trajectories... ˜dβ0 = (1−β)d0 + β dD
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We provide a new set of benchmark games... analytically reducible to their base game, enabling exact exploitability calculation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tristan Maidment and JB Lanier and Chase McDonald and Nathan Tsang and Eugene Vinitsky and Roy Fox and Albert Wang and Wesley N. Kerr , title=. 2026 , note=
work page 2026
-
[2]
Exploration in Deep Reinforcement Learning: From Single-Agent to Multiagent Domain , volume=
Hao, Jianye and Yang, Tianpei and Tang, Hongyao and Bai, Chenjia and Liu, Jinyi and Meng, Zhaopeng and Liu, Peng and Wang, Zhen , year=. Exploration in Deep Reinforcement Learning: From Single-Agent to Multiagent Domain , volume=. IEEE Transactions on Neural Networks and Learning Systems , publisher=. doi:10.1109/tnnls.2023.3236361 , number=
-
[3]
Ecoffet, Adrien and Huizinga, Joost and Lehman, Joel and Stanley, Kenneth O and Clune, Jeff , journal =. 2021 , title =. doi:10.1038/s41586-020-03157-9 , pages =
- [4]
-
[5]
Intelligent Go-Explore: Standing on the Shoulders of Giant Foundation Models , author=. 2025 , eprint=
work page 2025
- [6]
-
[7]
Journal of Machine Learning Research , volume=
Curriculum learning for reinforcement learning domains: A framework and survey , author=. Journal of Machine Learning Research , volume=
-
[8]
MAESTRO: Open-Ended Environment Design for Multi-Agent Reinforcement Learning , author=. 2023 , eprint=
work page 2023
-
[9]
The Twelfth International Conference on Learning Representations , year=
Reverse Forward Curriculum Learning for Extreme Sample and Demo Efficiency , author=. The Twelfth International Conference on Learning Representations , year=
-
[10]
OpenSpiel: A Framework for Reinforcement Learning in Games , author=. 2020 , eprint=
work page 2020
-
[11]
Lazaric, Alessandro and Restelli, Marcello and Bonarini, Andrea , title =. 2008 , isbn =. doi:10.1145/1390156.1390225 , booktitle =
-
[12]
Taylor and Peter Stone , title =
Matthew E. Taylor and Peter Stone , title =. Journal of Machine Learning Research , year =
-
[13]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Transfer learning in deep reinforcement learning: A survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[14]
No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery , url =
Rutherford, Alex and Beukman, Michael and Willi, Timon and Lacerda, Bruno and Hawes, Nick and Foerster, Jakob , booktitle =. No Regrets: Investigating and Improving Regret Approximations for Curriculum Discovery , url =
-
[15]
Reinforcement Learning Conference , year=
An Optimisation Framework for Unsupervised Environment Design , author=. Reinforcement Learning Conference , year=
-
[16]
Proceedings of the 38th International Conference on Machine Learning , pages =
Prioritized Level Replay , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
work page 2021
-
[17]
Proceedings of the Thirty-Second Conference on Learning Theory , pages =
Vortices Instead of Equilibria in MinMax Optimization: Chaos and Butterfly Effects of Online Learning in Zero-Sum Games , author =. Proceedings of the Thirty-Second Conference on Learning Theory , pages =. 2019 , editor =
work page 2019
-
[18]
Multiplicative Weights Update with Constant Step-Size in Congestion Games: Convergence, Limit Cycles and Chaos , author=. 2017 , eprint=
work page 2017
-
[19]
Stochastic Multiplicative Weights Updates in Zero-Sum Games , author=. 2021 , eprint=
work page 2021
-
[20]
George W. Brown , Booktitle =. Iterative Solution of Games by Fictitious Play , Year =
-
[21]
Deep Reinforcement Learning from Self-Play in Imperfect-Information Games , author=. 2016 , eprint=
work page 2016
-
[22]
A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning , url =
Lanctot, Marc and Zambaldi, Vinicius and Gruslys, Audrunas and Lazaridou, Angeliki and Tuyls, Karl and Perolat, Julien and Silver, David and Graepel, Thore , booktitle =. A Unified Game-Theoretic Approach to Multiagent Reinforcement Learning , url =
-
[23]
Proceedings of the 20th international conference on machine learning (ICML-03) , pages=
Planning in the presence of cost functions controlled by an adversary , author=. Proceedings of the 20th international conference on machine learning (ICML-03) , pages=
- [24]
-
[25]
Wang and Pierre Baldi and Roy Fox , booktitle=
Stephen Marcus McAleer and John Banister Lanier and Kevin A. Wang and Pierre Baldi and Roy Fox , booktitle=. 2021 , url=
work page 2021
-
[26]
International Conference on Learning Representations , year=
Toward Optimal Policy Population Growth in Two-Player Zero-Sum Games , author=. International Conference on Learning Representations , year=
-
[27]
Reevaluating Policy Gradient Methods for Imperfect-Information Games , author=. 2025 , eprint=
work page 2025
-
[28]
The Eleventh International Conference on Learning Representations , year=
A Unified Approach to Reinforcement Learning, Quantal Response Equilibria, and Two-Player Zero-Sum Games , author=. The Eleventh International Conference on Learning Representations , year=
- [29]
-
[30]
Vinyals, Oriol and Babuschkin, Igor and Czarnecki, Wojciech M. and others , title =. Nature , volume =. 2019 , doi =
work page 2019
-
[31]
Dota 2 with Large Scale Deep Reinforcement Learning
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[32]
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
work page 2016
-
[33]
Combining Deep Reinforcement Learning and Search for Imperfect-Information Games , url =
Brown, Noam and Bakhtin, Anton and Lerer, Adam and Gong, Qucheng , booktitle =. Combining Deep Reinforcement Learning and Search for Imperfect-Information Games , url =
-
[34]
Proceedings of the 5th Conference on Robot Learning , pages =
Offline-to-Online Reinforcement Learning via Balanced Replay and Pessimistic Q-Ensemble , author =. Proceedings of the 5th Conference on Robot Learning , pages =. 2022 , editor =
work page 2022
-
[35]
Proceedings of the 40th International Conference on Machine Learning , pages =
Jump-Start Reinforcement Learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Google Research Football: A Novel Reinforcement Learning Environment , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2020 , month=. doi:10.1609/aaai.v34i04.5878 , abstractNote=
-
[37]
GitHub repository , howpublished =
Chase McDonald, Tristan Maidment , title =. GitHub repository , howpublished =. 2025 , publisher =
work page 2025
- [38]
- [39]
-
[40]
Zico Kolter and Gabriele Farina , year=
Samuel Sokota and Eugene Vinitsky and Hengyuan Hu and J. Zico Kolter and Gabriele Farina , year=. Superhuman. 2511.07312 , archivePrefix=
- [41]
-
[42]
Siqi Liu and Luke Marris and Daniel Hennes and Josh Merel and Nicolas Heess and Thore Graepel , booktitle=. Neu. 2022 , url=
work page 2022
-
[43]
Eric Steinberger and Adam Lerer and Noam Brown , year=. 2006.10410 , archivePrefix=
-
[44]
Conference on robot learning , pages=
Reverse curriculum generation for reinforcement learning , author=. Conference on robot learning , pages=. 2017 , organization=
work page 2017
- [45]
-
[46]
Learning Montezuma's Revenge from a Single Demonstration , author=. 2018 , eprint=
work page 2018
-
[47]
Neural replicator dynamics: Multiagent learning via hedging policy gradients , author=. Proceedings of the 19th international conference on autonomous agents and multiagent systems , pages=
-
[48]
The Eleventh International Conference on Learning Representations , year=
ESCHER: Eschewing Importance Sampling in Games by Computing a History Value Function to Estimate Regret , author=. The Eleventh International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.